







在开始阅读这篇文章时,我们首先要有以下四个问题:
什么是原码,反码和补码?
整形数据在内存中存的又是什么?
数据在内存中存储的顺序又是怎样的?
怎样判断机器的存储顺序?
首先:
-
什么是原码,反码,补码?
我们知道计算机在存储数据时,均是以二进制表示形式存储的。那么先来了解下它们的概念:
原码:就是我们看到一个整数时,直接写出它的二进制表示形式。
反码:就是符号位不变,其它位按位取反得到的二进制序列。
补码:就是在反码的二进制序列上加一后得到的。
在学习C语言时,我们都知道不同的数据类型在内存中所占的空间是不同的,如图:

注意:上面的数字是以 字节 为单位的。
接下来我们就以 int 为例子:
如图:

我在上面的代码定义了一个 int 型的变量 a ,并给它赋了个 -1 进去,上面已经把 -1 的原码,反码和补码写了出来,然后我们进行调试:

从这里我们可以看到确实在内存中为 a 开辟了一块空间,并在里面放了 8 个 f ,这里1个 f 表示 4 个 比特位。
也就是说:ff 就是一个字节,恰巧我们知道,一个 int 存放的就是 4 个字节的内容,与这里完美吻合。
然后我们就要弄清楚这里的 ff ff ff ff 到底存的是原码,反码,还是补码。
这里的一个f 是16进制数表示 1111 ,那么 ff ff ff ff 就是 11111111 11111111 11111111 11111111 这样的一串二进制数,看到这儿,上面图片中 -1 的补码与这一串二进制数 一模一样,所以我们知道,在内存中存储数据,存的是数据的 补码。
注意:正数和无符号数的原码,反码,补码相同,也就是说当我们知道了原码,那么它的反码和补码我们也就知道了。
在计算机中用补码存储数据,还有一个原因:
计算机的CPU上只有加法器,比如:
计算 1 - 1,这时计算就会把它看成 1 + (-1),这时就会成为一个加法
这里如果用原码相加的话:(int型)
0000 0000 0000 0000 0000 0000 0000 0001 — 1
1000 0000 0000 0000 0000 0000 0000 0001 — -1
1000 0000 0000 0000 0000 0000 0000 0010 — -2 (原码相加后的结果)
这明显不对!!!
那么使用补码:
0000 0000 0000 0000 0000 0000 0000 0001 — 1 的补码
1111 1111 1111 1111 1111 1111 1111 1111 — -1 的补码
0000 0000 0000 0000 0000 0000 0000 0000 — 相加后的结果为0:进位溢出了1
这时结果完全正确!!!
下面我们需要了解什么是无符号数,什么是有符号数?
平常我们写的像下面这些基本上都是有符号数:
int a = 0;
short b = 0;
long c = 0;
long long d = 0;这些都是有符号的 int ,那么无符号的数我们要使用时,需要怎样定义?
unsigned int a = 0;
unsigned short b = 0;
unsigned long c = 0;
unsigned long long d = 0;如上图定义就行。
注意:char 这个类型直接这样写:
char a = 0;在有的编译器上表示的是 —— unsigned char ,所以 char 到底是有符号还是无符号,全跟编译器有关。
接下来,我们就来了解一下无符号的数在内存中和有符号的数有哪些不同。
- 相同点:存的都是补码,并且和正数一样,原码、反码、补码相同
- 不同点:所存储的数据范围不一样,比如:(int不好演示,这里用char)

上面这段代码,我分别定义了一个 unsigned char ——a ,和一个 char —— b,并为它们赋值了255,结果打印时,无符号的正常打印,有符号的就只打印了 -1。

弄清楚为什么打印 255 和 -1 后,我们也就知道 :
有符号 char 的范围:-128 — 127
unsigned char 的范围:0 — 255
注意:当有符号的 char 遇到 1000 0000 这个二进制序列时,由于它求不了补码,所以一律都是当作 -128 来看的。
说打这里,我们也就了解了有符号的 char 和 unsigned char 在内存中存储的是什么,并且有什么不同之处,最后我们来了解一下
-
数据在内存中存储的顺序是怎样的?
我们可以想象一下,数据存储模式如果没有规定,那么这就会出现一个问题,你按照自己的方式把数据放到内存中,当想要拿出来时,怎么拿出来?
所以现在就规定了两种存储模式:小端字节序存储模式 和 大端字节序存储模式
我们用以下代码测试:
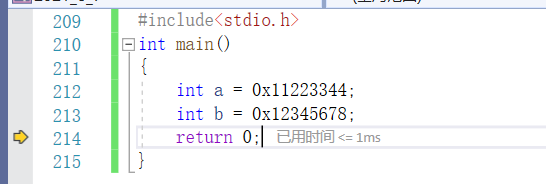
进入调试,打开 内存 和 监视 窗口:

输入 &a 和 &b 时,就会出现上面这幅图。这时我们就能看到,当我把 0x11223344 和 0x12345678 赋值给 a 和 b 时,在内存中确实存放了这两个数,并且由于这两个16进制数所占的空间刚好是4个字节的大小,所以 int a 和 int b 刚好可以存下。 
注意:在这里我们需要知道 上面两个值哪里是低位,哪儿是高位,并且要知道在内存中哪儿是低地址,哪儿是高地址。然后才能探讨数据存储模式。

由于是16进制数,所以很好判断。

弄清楚了这些,下面在来看上面调试的图片:
![]()
![]()
也就是说,计算机把数据的高位放到了高地址处,低位放到了低地址处。看第二幅图还看不出来,但第一幅图为什么 7 和 8 ,5 和 6, 3 和 4, 1 和 2 都是从左往右,而整体的的却是从右往左,也就是从高地址到低地址?
这是因为我们在讨论数据的存储时,是以字节为单位的,上面的数据是16进制,也就是每两位是一个字节(8个比特位)。
我们把这种模式称为:小端字节序存储模式
那么什么是大端字节序存储模式呢?
顾名思义 —— 把数据低位字节的内容存放到内存的高地址处,把高位字节的内容放到内存的低地址处。
我们知道以上内容后,我们能不能知道自己的机器是什么模式呢?
我们可以写这样一段代码:
#include<stdio.h>
int check(void) //函数不需要参数。
{
int a = 1;
char* p = (char*)&a; //用一个 char* 的指针指向a的地址。
return (*p); //返回 char* 指针解引用一个字节的内容。
}
int main()
{
int ret = check(); //自定义函数,返回1时——小端字节序存储
if (ret) // 返回0时——大端字节序存储
{
printf("小端字节序存储!\n");
}
else
{
printf("大端字节序存储!\n");
}
return 0;
}有兴趣的小伙伴们,可以去试试!
最后,刚开始的几个问题,相信大家已经在文章中找到答案了,这里就不多加赘述了。















 1700
1700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









