






索引在计算机中的位置
一般来说,索引本身也很大,不可能全部存储在内存中,一般以文件形式存储在磁盘上,索引检索需要磁盘I/O操作。判断一种数据结构作为索引的优劣主要是看在查询过程中的磁盘IO渐进复杂度,一个好的索引应该是尽量减少磁盘IO操作次数。
为什么使用B+树
1、B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
2、B+树空间利用率更高
因为B+树的内部节点(非叶子节点,也称索引节点)不存储数据,只存储索引值,相比较B树来说,B+树一个节点可存储更多的索引值,使得整颗B+树变得更矮,减少I/O次数,磁盘读写代价更低,I/O读写次数是影响索引检索效率的最大因素;
3、B+树查询效率更加稳定
因为在B+树中,顺序检索比较明显,随机检索时,由于B+树所有的 data 域(结点中存储数据元素的部分)都在根节点,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径相同,导致每一个关键字的查询效率基本相同,时间复杂度固定为 O(log n);而B树搜索有可能会在非叶子节点结束,约靠近根节点的记录查找时间越短,其性能等价于在关键字全集内做一次二分查找,查询时间复杂度不固定,与 key 在树中的位置有关,最好情况为O(1);
4、 B+树范围查询性能更优
因为B+树的叶子节点使用了指针顺序(链表)从小到大地连接在一起,B+树叶节点两两相连可大大增加区间访问性,只要遍历叶子节点就可以实现整棵树的遍历,而B树的叶子节点是相互独立的,每个节点 key(索引)和 data 在一起,则无法查找区间;
【根据空间局部性原理:如果一个存储器的某个位置被访问,那么将它附近的位置也会被访问】
若访问节点 key为 50,则 key 为 55、60、62 的节点将来也可能被访问,可利用磁盘预读原理提前将这些数据读入内存,减少了磁盘 IO 的次数。当然B+树也能够很好的完成范围查询,比如同时也会查询 key 值在 50-70 之间的节点。
5、B+树增删文件(节点)时,效率更高
因为B+树的叶子节点包含了所有关键字,并以有序的链表结构存储。
说明:InnoDB的一棵B+树可以存放多少行数据?约2千万。
B树【Balance --- “多路平衡查找树”,任意节点的子树的高度差都小于等于1】
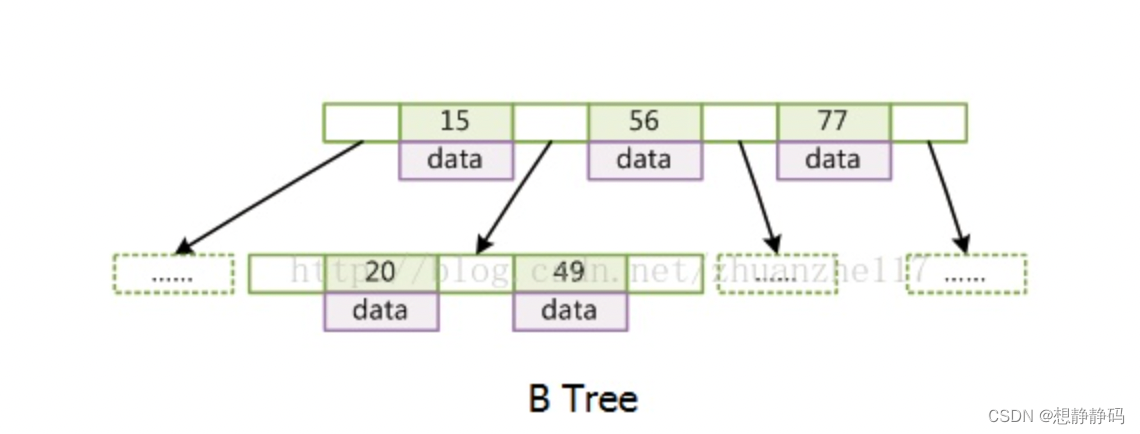
B树有如下特点:
1、每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null;
2、任何一个关键字出现且只出现在一个结点中;
3、搜索有可能在非叶子结点结束(最好情况是O(1)就能找到数据);
4、在关键字全集内做一次查找,性能逼近二分查找。
B+树【B树的改进版, 让内部节点(非叶子节点)只作索引使用,叶子节点包含了这棵树的所有键值,叶子节点不存储指针】
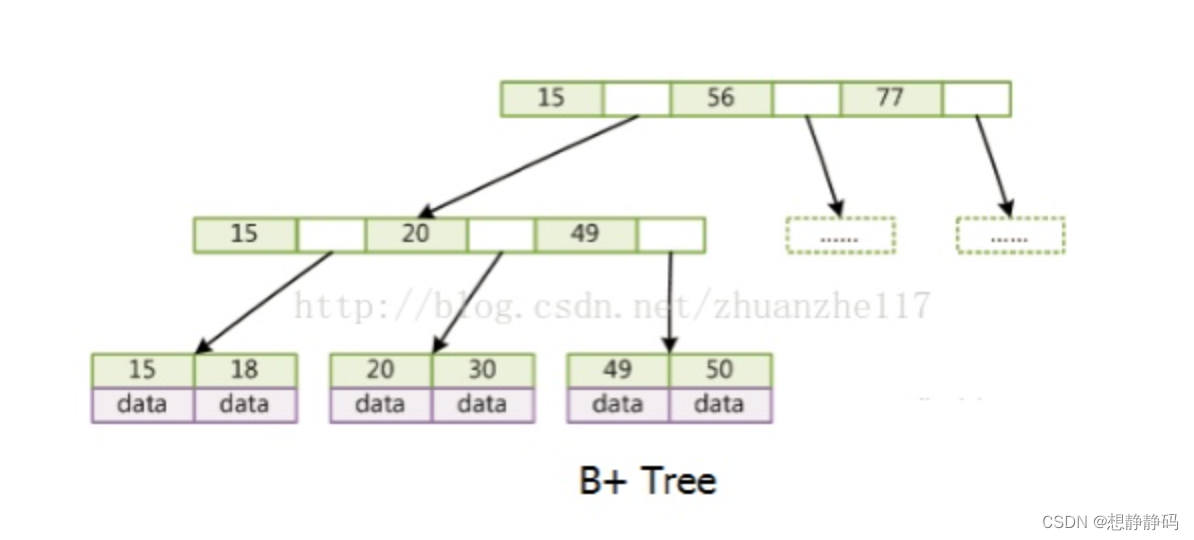
B+树有如下特点:
1、只有叶子节点存储data,包含了这棵树的所有键值,叶子节点不存储指针。(非叶子节点都只是存储索引值,没有实际的数据,并非真正的data);
2、增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构---B+树。
区别
1)B+树的data只存储在叶子节点上,B树的所有节点都存储了key和data
B+树的非叶节点不存储data,这样一个节点就可以存储更多的索引值,可以使得树更矮(高度更小),所以IO操作次数更少。
2)B+树的所有叶结点构成一个有序链表,可以按照关键码排序的次序来有序遍历全部记录
由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历,相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
















 2036
2036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











