







一、索引类型
索引根据底层实现可分为B-Tree索引和哈希索引,大部分时候我们使用的都是B-Tree索引,因为它良好的性能和特性更适合于构建高并发系统。
根据索引的存储方式来划分,索引可以分为聚簇索引和非聚簇索引。聚簇索引的特点是叶子节点包含了完整的记录行,而非聚簇索引的叶子节点只有所以字段和主键ID。
根据聚簇索引和非聚簇索引还能继续下分还能分为普通索引、覆盖索引、唯一索引以及联合索引等。
二、聚簇索引和非聚簇索引
聚簇索引也叫聚集索引,它实际上并不是一种单独的索引类型,而是一种数据存储方式,聚簇索引的叶子节点保存了一行记录的所有列信息。也就是说,聚簇索引的叶子节点中,包含了一个完整的记录行。
非聚簇索引也叫辅助索引、普通索引,它的叶子节点只包含一个主键值,通过非聚簇索引查找记录要先找到主键,然后通过主键再到聚簇索引中找到对应的记录行,这个过程被称为回表。
例如一个包含了用户姓名和年龄的的数据表,假设主键是用户ID,聚簇索引的结构为(橙色的代表id,绿色是指向子节点的指针):
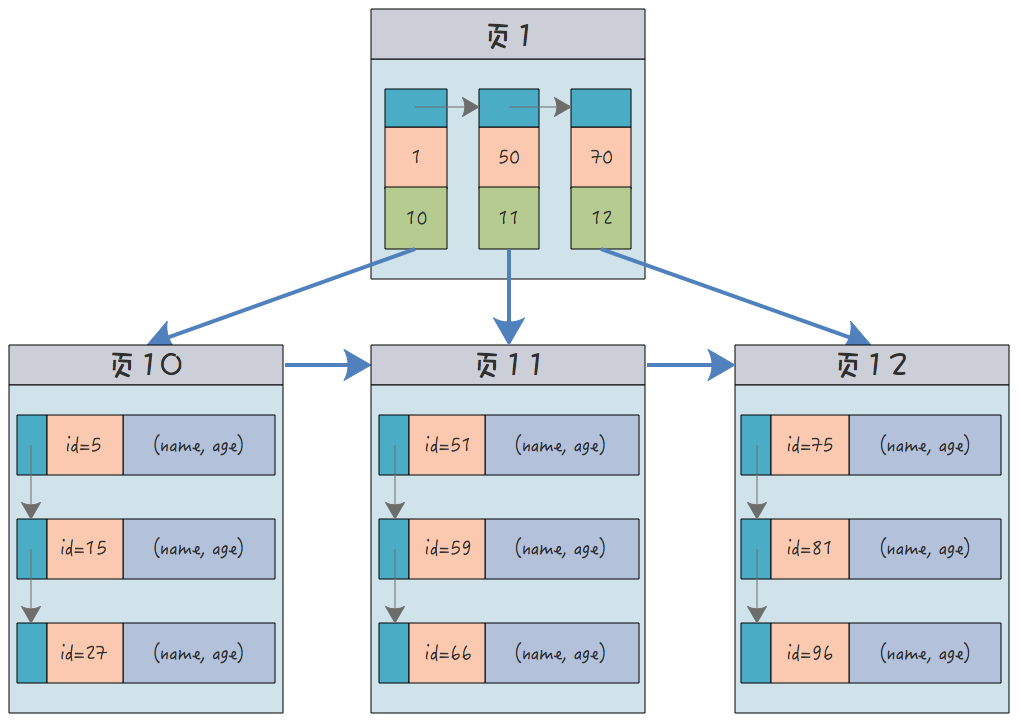
叶子节点中,为了突出记录,把(id, name, age)区分开来了,实际上是连在一起的,它们是构成一条记录的整体。
而一个非聚簇索引(以age为索引)的结构是:

它的叶子节点中,不包含整个记录的完整信息,除了age字段本身以外,只包含当前记录的主键id。如果想要获取整行记录数据还需要再通过id号到聚簇索引中回表查询。
InnoDB中,每个表必须有一个聚簇索引,默认是根据主键建立的。如果表中没有主键,InnoDB会选择一个合适的列作为聚簇索引,如果找不到合适的列,会使用一列隐藏的列DB_ROW_ID作为聚簇索引。
三、覆盖索引
非聚簇索引中因为不含有完整的数据信息,查找完整的数据记录需要回表,所以一次查询操作实际上要做两次索引查询。而如果所有的索引查询都要经过两次才能查到,那么肯定会引起效率下降,毕竟能少查一次就少查一次。
以上面的age索引为例,它是一个非聚簇索引,如果我想通过年龄查询用户的id,执行了下面一条语句:
| 1 | select id from userinfo where age = 10; |
这种情况是否还有必要去回表?因为我只需要id的值,通过age这个索引就已经能拿到id了,如果还去回表一次不就做了无用的操作了吗?实际上确实是不需要的。索引查询中,如果辅助索引已经能够得到查询的所有信息了,就无需再回表,这个就是覆盖索引。
四、联合索引
联合索引指的是同时对多列创建的索引,创建联合索引后,叶子节点会同时包含每个索引列的值,并且同时根据多列排序,这个排序和我们所理解的字典序类似。
例如对同时对上面的姓名和年龄创建的索引结构:

(name, age)都是简写,想不出十几个名字。。。。。
每个叶子节点同时保存了所有的索引列,除此之外,还是只包含了主键id。
最左前缀匹配原则
当对多列创建索引后,并不是只要包含了创建索引的列就能使用索引,索引的使用要遵循最左前缀匹配原则。
假设对列(A, B, C)创建索引,那么只有以下场景能使用索引:
- 对列(A, B, C)/(A, C)或者(A, B)进行查询会匹配索引,对(C, A)或者(B, C)来说不能使用索引。
- 通配符只能使用LIKE 'val%'形式,不能使用LIKE '%VAL%',后者会导致全表扫描。
- 索引列不能进行运算,例如WHERE A + 1 = 5这种场景会导致索引失效。
- 索引列不能包含范围值查询,如LIKE/BETWEEN/>/<等都会导致后面的列无法匹配索引。
- 索引列不能包含有NULL值。
索引下推
新版本的MySQL(5.6以上)中引入了索引下推的机制:可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
例如针对上面表中的(name, age)做联合索引,正常情况下的查询逻辑:
- 通过name找到对应的主键ID
- 根据id记录的列匹配age条件
这种做法会导致很多不必要的回表,例如表中存在(张三, 10)和(张三, 15)两条记录,此刻要查询(张三, 20)的记录。查询时先通过张三定位到所有符合条件的主键ID,然后在聚簇索引中遍历满足条件的行,看是否有符合age = 20的记录。实际情况是没有满足条件的记录的,这个回表过程也相当于是在做无用之功。
索引下推的主要功能就是改善这一点,在联合索引中,先通过姓名和年龄过滤掉不用回表的记录,然后再回表查询索引,减少回表次数。
五、唯一索引
唯一索引是一种不允许具有相同索引值的索引,系统在创建该索引时检查是否有重复的键值,每次对更新或增加记录时都会检查这一点。主键索引就是唯一索引。
六、常见的二级索引:
HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。
-
MapReduce方案
-
ITHBASE(Indexed-Transanctional HBase)方案
-
IHBASE(Index HBase)方案
-
Hbase Coprocessor(协处理器)方案
-
Solr+hbase方案
-
CCIndex(complementalclustering index)方案
二级索引的种类
1、创建单列索引
2、同时创建多个单列索引
3、创建联合索引(最多同时支持3个列)
4、只根据rowkey创建索引单表建立二级索引
1.首先disable ‘表名’
2.然后修改表
alter 'LogTable',METHOD=>'table_att','coprocessor'=>'hdfs:///写好的Hbase协处理器(coprocessor)的jar包名|类的绝对路径名|1001'
3. enable '表名'二级索引的设计思路

二级索引的本质就是建立各列值与行键之间的映射关系
如上图1,当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)
其查询步骤如下:
1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1
2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











