







贡献
以往的VLN解决范式强调的是代理在严格未见的环境中一次性完成导航的能力。但是在一些特定的场景中,如家用机器人,基本上是在一个一致不变的环境中持续得进行导航工作,随着其执行更多的指令,代理应该能够逐渐熟悉这个环境,从而在这个环境中导航的性能越来越高。
本文就提出了一个新的任务General Scene Adaptation for VLN(GSA-VLN)来解决上述的问题,使得代理在特定场景中执行导航指令的同时,能够适应该场景并随着时间推移提升性能。此外,论文还提出了一个新的数据集GSA-R2R,用于评估代理在分布内和分布外环境中的适应能力,并设计了一个三阶段指令编排流程,利用LLMs来丰富指令的多样性和风格,来更好反映现实世界中用户指令的多样性。
方法
一、概述
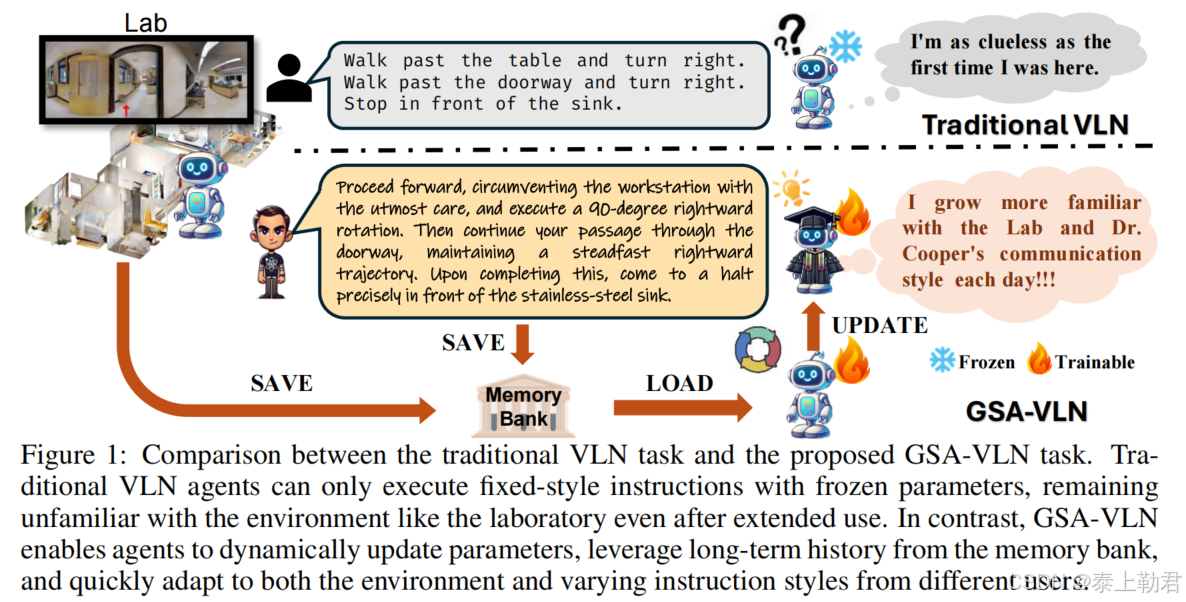
如图1所示,在本文提出的任务GSA-VLN中,智能体需要保持长期记忆并且不断更新模型的参数以便在特定场景中执行导航指令的同时提升性能。相当于智能体记住了这个环境并且模型越来越拟合这个环境(在此任务设定中,代理是家用机器人,无需强调其对未知环境的泛化能力,但是它也需要能够对其他不同的未知环境有足够的适应能力)。
提出的数据集GSA-R2R,在Matterport3D(用于评估的建筑少于30个)的基础上融入了Habitat-Matterport3D的建筑物。然后将住宅归为ID(分布内),并将非住宅类的建筑(如电影院和商店)归为OOD(分布外),形成150个用于评估的建筑。指令的多样性也很重要,而在特定环境中的指令的风格一般是一致的,反映了个人的说话习惯或与在建筑中的角色相关的专业语言。这在以往的任务中被忽视了。设计了一个三阶段的流程来获得指令-轨迹对。首先使用训练好的speaker模型产生有噪音的指令,然后经过VLMs路径可视化来细化,最后用LLMs让其形成不同的特点(针对不同个性的人和特定建筑内相关的人)。最终,每个环境有600条多种说话风格的指令。
提出 Graph-Retained DUET(GR-DUET)方法,不断更新每个环境的整体拓扑图,以在训练和评估中保存历史信息。
还得关注的是,这篇文献和之前的 Iterative VLN (IVLN)任务设置相似但又有所不同。
二、GSA-VLN 任务
与传统VLN任务不同,GSA-VLN引入了一个环境特定的记忆库(memory bank),用于存储代理在该环境中执行的所有历史信息,包括视觉观察、指令、选择的动作和轨迹路径。代理可以利用这个记忆库来适应当前工作环境,从而提升性能。
在环境中执行若干条指令后,这个记忆库会保存这几次的上述的历史信息。因此之后代理就可以在记忆库中检索之前的长期历史作为先验知识来辅助导航。虽然可能会有导航错误的情况,但是这些数据都可用来进行无监督训练来更新模型的参数。但是在进行无监督学习之前该代理应该能足够通用。
三、GSA-R2R数据集

- 环境
具体而言,作者们从OpenStreetMap网站收集并手动提炼了187种建筑类型。对于每个环境,使用GPT-4根据三种类型的图像提示预测建筑类型,包括:建筑物概览、每层楼的俯视图和通过使用谱聚类在图节点上选择的全景图。对于非住宅类别的建筑,进行手动验证并纠正预测,且应用两条过滤规则:排除R2R训练集中的环境(以便现有VLN模型可以直接使用该数据集进行评估)、移除潜在路径少于600条的环境(确保该环境有足够数量的路径)。
总的来说,识别了来自19种不同类型的75座非住宅建筑,其中70座来自HM3D,5座来自MP3D。
- 指令
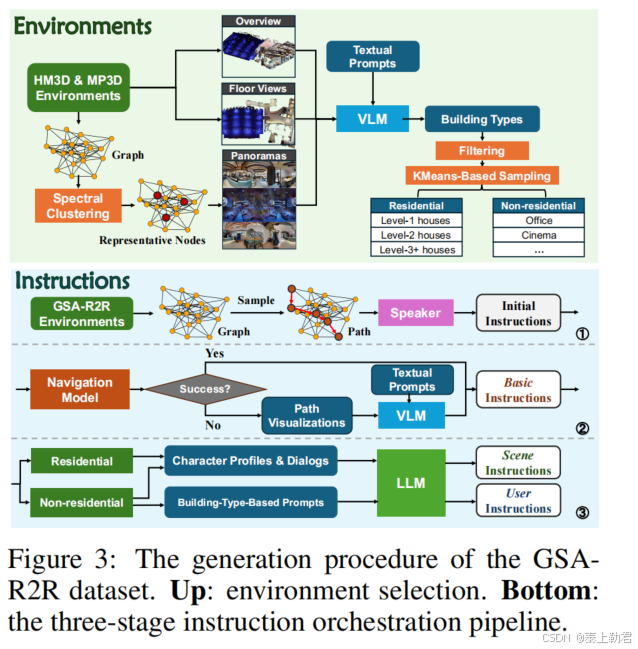
通过三阶段的指令编排流程来为抽取的路径生成三种类型的指令。
第一阶段:使用在R2R上训练的EnvDrop speaker生成初始指令。然而,其中一些指令包含噪声和不准确之处,需要进一步优化。
第二阶段:利用一个在150个环境的未选择路径上训练的导航模型,通过成功执行作为指令可行性的指标,识别不正确的指令。对于失败的指令,利用GPT-4检测轨迹与指令之间的不匹配,并使用专门的路径可视化提示进行纠正,从而生成精炼的“基础”指令。
第三阶段:进一步改写基础指令,以反映不同的说话风格。对于非住宅建筑,使用LLM根据场景类型选择潜在的用户身份,并将指令改写为“场景”风格。还通过模拟电视系列剧的特定角色,使用他们的角色档案和对话来为所有场景创建“用户”风格。此外,从SummScreen数据集中选择了五个具有多样化说话风格的角色来生成指令,其中包括由于缺乏实际儿童角色而产生的通用儿童说话风格。
- 数据集的分割
分割的命名格式为“Val/Test-R/N-Basic/Scene/User”,其中“R”表示住宅,“N”表示非住宅场景。排除了验证集中的已见分割,因为适应之前训练过的环境是没有必要的。因此,GSA-R2R中的所有环境都是未见的。
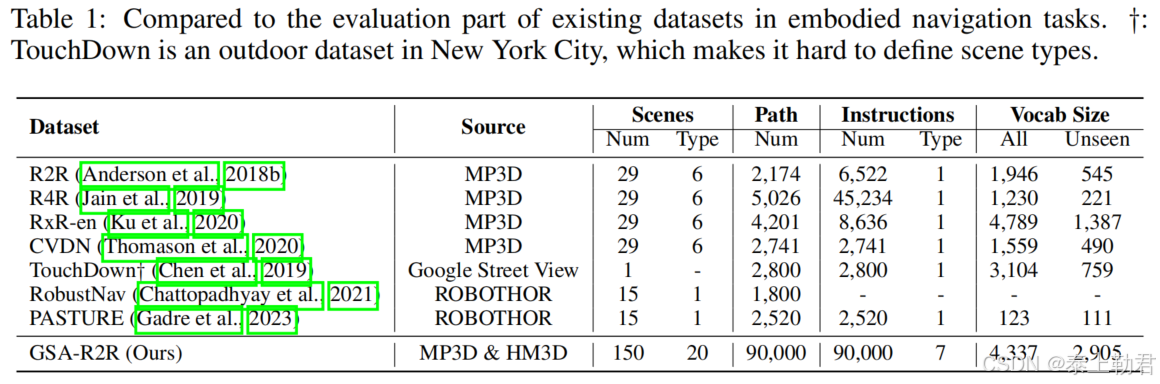
表一的结果表明GSA-R2R具有最多且最具多样性的场景、路径和指令。
四、GR-DUET方法
引入基于记忆的全局拓扑图,以替代扩展的历史嵌入,从而在跨回合中保留更丰富的节点信息。维护一个全局图 G g G_g Gg 来整合多个回合的信息,而非每个回合单独构建图。
在推理阶段,不再为每个回合分别维护图 { G 1 , G 2 , ⋯ , G m } \{G_1, G_2, \cdots, G_m\} {G1,G2,⋯,Gm},而是维护一个全局图 G g G_g Gg,用于持续更新拓扑地图。每个节点包括空间位置坐标和对应的视觉观察信息。在回合 k k k 开始时,利用记忆库中的数据构建全局图: G g = G 1 , G 2 , ⋯ , G k − 1 G_g={G_1,G_2,⋯,G_{k−1}} Gg=G1,G2,⋯,Gk−1,即包含所有之前回合中访问过的节点。所有节点在每个新回合开始时会重置“已访问”状态,从而确保智能体只选择未访问的节点作为下一步目标。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









