







#1、数据库(MySQL)
1)环境搭建(软件安装)
2)介绍数据库基本常识
3)简单的查询语句
1、数据库的概念
1、数据库的英文单词: DataBase 简称为:DB
2、什么是数据库?
1)存储数据的仓库
2)本质是一个文件系统,该文件系统需要安装在电脑上(服务器)
3)MySQL Server 数据库管理软件:DBMS
3、数据库的语句 (SQL 语句 结构查询语言)
1)它是数据库的一种操作规范
2)通用的数据库语言操作规范
3)特殊的规范(不同的数据库的种类)
4、SQL 语句分类(重要)
1)数据库查询语句:DQL
2)数据库定义语句:DDL
3)数据库操作语句:DML
4)数据库控制语句:DCL
5)数据库事务控制(TCL)(处理 TPL)语句
5、MySQL 语句
1)每条语句以分号结束
2)在 SQL 语句中不区分大小写,关键字(官方定义好的一些单词意思)
3)注释
通用的方式
–空格 – 单行注释
/* 多行注释 */
MySQL 特有的注释方式
# 单行注释
#数据库查询语句:DQL (重要)
#1、简单查询语句
#表:用于存储数据的基本结构,也是我们查看的数据结构
emp 表
empno 员工编号
ename 员工姓名
job 职位
mgr 员工主管的编号
hiredate 入职日期
sal 薪资(月薪)
comm 奖金
deptno 部门编号
格式:
select 列名 from 表名
select ename from emp;
方式一:
select empno, ename, job, mgr,
hiredate, sal, comm, deptno
from emp;
方式二:
select * from emp; #推荐使用
#注意:
#1、列名与列名用逗号分隔,最后一列不需要逗号
#2、* 代表一张表中的全部数据
#3、方式一效率略快于方式二
2、指定列名进行查询
select empno, ename from emp;
#3、列别名
select empno 员工编号 from emp;#不推荐
select empno as 员工编号 from emp;#推荐使用 格式清晰
select empno as e, ename as a, job as j from emp;
2、简单的查询语句
#格式:select … from…
#符合英语体系的语法格式
#执行顺序:from—select
select 列名 1(属性名), 列名 2...列名 n from 表名;
select * from emp;
清除重复值 distinct
#查询指定列并且不出现重复值
#查询所有的部门编号(我只需要查询 10 20 30)
select distinct deptno from emp;
#注意:将 distinct 放在 select 与第一个列名之间的位置
select job, distinct deptno from emp;#语法 错
#记录数各列无法对应
select distinct deptno, job from emp;
#distinct 控制后面两列
查询的结果数据参与运算
#它并不是改变表中的数据,只不过是将查询到的结果重新运算,再显示出来
#查询员工姓名和员工的年薪
select ename, sal*12 as 年薪 from emp;
#查询员工姓名,月薪,
#奖金(格式显示为员工的奖金是 XXX),
#员工的年收入(别名年收入)
select ename, sal, concat('员工的奖金是',comm),
sal*12 as 年收入
from emp;
concat() 字符连接函数
#函数:官方给我们实现一些基本的功能
#单引号包含的结构叫做字符串(中文、英文、数字)
#NULL 空值 (没有值)
#注意:
#1)字符串如果与空值(null)拼接,没有任何效果的
#2)如果 null 值参与数值运算,则结果一定是 null 值
#查询每个员工的年收入(月薪 + 奖金)*12
select ename, (sal + ifnull(comm, 0))*12 as 年收入
from emp;
#ifnull ifnull(exp1, exp2)
#如果 exp1 是 null,则使用 exp2 的值
条件查询
#作用:就是限制我们查询的数据结果
#实际应用:登录
#页面(登录) 输入用户名、密码
#通过网络发送给后台 java 程序
#给数据库(问有没有这个用户)
#格式:select 列名 from 表名 where 条件;
#执行顺序:from—select—where ?
#从表中取出每一条数据,满足条件的数据就返回显示,
#不满足的不显示
基本比较运算符(< > = >= <= ) (<> != 不等于)
#查询在 10 号部门工作的员工信息
select *
from emp
where deptno = 10;
#练习:
#查询月薪不高于 1600 的员工信息
select * from emp
where sal <= 1600;
#查询不在 20 号部门工作的员工信息
select * from emp
where deptno <> 20;#推荐使用
select * from emp
where deptno != 20;
查询条件中 并且(and) 或(or) 关系
#1)and
#查询在 10 号部门工作,并且月薪高于 2000,并且职位是 manager 的员工信息
select * from emp
where deptno = 10 and sal > 2000 and job = 'manager';
#注意:mysql 下数据值不区分大小写,但是有些数据库中的值是区分大小写(Oracle)
#2) or
#查询在 10 号部门工作或者工资高于 2000 的员工信息
select * from emp
where deptno = 10 or sal > 2000;
#3) and 和 or 一起使用(注意优先级)
#and 的优先级要比 or 高,and 优先执行
#查询在 10 号部门工作或者工资高于 2000 并且职位是 manager 的员工信息
select * from emp
where deptno = 10 or sal > 2000 and job = 'manager';
#注入漏洞(早期的游戏盗号) 应用的就是 or 与 and 的优先级
select * from user
where username = '哈哈' and password = '123456';
select * from user
where username = '哈哈' and password = ''
or username = '哈哈' and 1=1;
#练习:
#1、查询 dept 表中的部门编号和工作地点
select deptno, loc from dept;
#2、查询 emp 表中员工的姓名,年收入、入职日期
select ename, (sal + ifnull(comm, 0))*12 as 年收入, hiredate
from emp;
#3、查询 emp 表中,所有的职位是 clerk 的员工信息
select * from emp
where job = 'clerk';
#4、查询 emp 表中,月薪在 1000 到 2000 之间的员工信息
select *
from emp
where sal >= 1000 and sal <= 2000;
#5、查询 emp 表中主管编号是 7902,7698,7788 的员工姓名,主管编号
select ename, mgr
from emp
where mgr = 7902 or mgr = 7698 or mgr = 7788;
#6、查询 emp 表中,月薪在 3000 以上或 10000 以下的员工信息
select *
from emp
where sal > 3000 or sal < 10000;
#7、查询 emp 表中,没有奖金的员工信息
select *
from emp
where comm = 0 or comm = null;
数值非 0
#数据库中的逻辑类型:null 真值 假值(额外需要记一下)
= 两侧一定要数据类型要统一
select *
from emp
where ifnull(comm, 0) = 0;
select ifnull(comm, 0) from emp;
特殊比较运算符
#1)格式:
#列名 between 下限 and 上限 表示一个区间范围,包含两个端点(包头包尾)
#相当于大于等于多少并且小于等于多少
select *
from emp
where sal between 1000 and 2000;
select *
from emp
where sal between 2000 and 1000;
#语法正确,逻辑是错的
#可以比较其他的数据类型
#文字类型(字符类型、字符串)
#数值 (使用较多)
#日期/时间(使用较多)
#查询 emp 中,在 1982 年入职员工信息
select *
from emp
where hiredate between '1982-01-01' and '1982-12-31';
#会将字符串的时间形式自动转换为日期类型
#按照英文字母顺序查询
select * from emp
where ename between 'A' and 'C';
in 表示多个值的可能性 等价于 条件 1 or 条件 2 or …
#格式:
#列名 in(值 1,值 2,值 3…)
select ename, mgr
from emp
where mgr in(7902,7698,7788);
like… 像… 重要 模糊查询
#格式:列 like 通配符格式
通配符
% 匹配任意个字符
_ 匹配一个字符
% 匹配任意个字符 _匹配一个字符(作用是控制位置,比如第二个位置是M开头的姓名)
#查询所有名字首字母是 B 的员工信息
select * from emp where ename like 'M%'
#查询姓名的第二个位置是M开头的人
SELECT * FROM EMP WHERE ENAME LIKE '_M%'
#查询名字倒数第二个字符是 T 的员工信息
select * from emp where ename like '%T_'
通配符 用escape ''关键字 指明字符,
那么被指明字符后面的符号将表示为本身的含义
#查询名字中开头字母是 MAN_的员工信息
select * from emp where ename like 'MAN/_%' escape '/';
升序(默认) 降序
单列排序 多列就是在第一次的基础再排序’,'连接 ifnull 可以排除null
#查询所有 10 号部门的员工信息,按照月薪升序排列 推荐使用,条理清晰
select * from emp where deptno = 10 order by sal asc;
降序
select * from emp where deptno = 10 order by sal desc;
#查询员工姓名、年收入、按照年收入升序排序(采用别名进行排序)
select ename, (sal + ifnull(comm, 0))*12 as 年收入 from emp order by 年收入 asc;
注意where中不能出现列的别名 原因就是sql语句执行顺序的原因,先执行的where,select之后执行
#sql语句的执行顺序
from where select order by
多列排序 排序的条件用"," 隔开
#查询员工的信息,按照部门编号升序,月薪降序进行排列
select * from emp order by deptno asc, sal desc;
限制记录的行数,limit 起始位置
长度 注意:其实位置是在0开始
#实际应用,分页查询
select * from emp limit 5, 2;
字符串函数
1、大小写转换函数
#upper(str) 将字符串中小写转为大写
select upper('hEllo'), UPPER('哈哈') from dual;
大写转小写
select LOWER('heLLo') from dual;
2、substring截取函数
包头不包尾 (str,start,length),start起始位置是在1开始的
select substring('123456', 4,1) from dual;
3、字符串查找函数
#instr(str, str1) string(字符串)#在 str 中寻找 str1 字符串,
#返回 str1 在 str 中的位置(第一个子字符串的位置)
#如果没有找到返回的结果是 0
select INSTR('str','s') from dual;
4、字符串拼接函数
#concat(str1, str2, …)
select concat('大傻', ename) from emp;
5、字符串替换函数
#replace(str1, str2, str3)
#在 str1 的字符串中,使用 str3 来替换全部的 str2
6、字符串补齐函数
位置从1开始
#左侧补齐lpad(‘str1’,2,‘str2’) ,右 rpad
select LPAD('hello',9,'*')
取出前后空格函数
中间的空格是不会去除的
#trim()
select TRIM(' a sf ') from dual;
日期函数
1、实际应用较多使用 now
select NOW() from dual;
2、timediff()、datediff()
#timediff(exp1,exp2)
#返回的是两个时间 exp1 和 exp2 的相差的时间数
#datediff(exp1,exp2)
#返回的是两个日期 exp1 和 exp2 的相差的时间天数
select DATEDIFF('2021-07-12','2021-01-01') from dual;
select timediff('10:31:00', '8:29:00') from dual;
#emp 中所有员工如果至今都未辞职,那么计算他们的司龄
select DATEDIFF(CURDATE(), hiredate) / 365 from emp;
3、date_add(date, interval exp type)
:日期加上一个时间间隔值
4、date_sub(date, interval exp type)
:日期减去一个时间间隔值
#date:基础日期时间
#exp:追加数值
#type:追加日期时间的类型 month, year
#假设公司试用期 6 个月,计算 emp 中员工的转正时间
select ename, DATE_ADD(hiredate,Interval 6 month) from emp;
5、substring
#查询 81 年入职的员工姓名,入职日期
select ename, hiredate from emp where SUBSTRING(hiredate,1,4) = 1981;
时间格式化函数
#date_format(date, format)
#time_format(time, format)
#format 格式话格式 % 中国式的
select DATE_FORMAT(NOW(),'%Y年%m月%d日') from dual;
根据时间段查询数据库

多行函数
求和 sum()
#查询emp表中,所有月薪的总和
select SUM(sal) from emp;
求平均值函数 avg()
#计算emp表中平均月薪
select AVG(sal) from emp;
求最大值函数 最小值min()
#max()
select MAX(sal) from emp;
计数函数 统计个数 count() 参数
distinct 去重
#emp表中一共有多少个员工
select COUNT(*) from emp;
select COUNT(distinct deptno) from emp;
groub by 根据…分组
#查询每个部门的平均工资及其部门编号
select AVG(sal), deptno from emp group by deptno;
注意:只有在groub by中出现的列才能写在select中 除非被聚合函数修饰( avg()等 )
多次分组
先以部门分组,在此基础上再以职位分组,
#计算平均月薪(每个部门中的每种职位的平均月薪)
select AVG(sal), deptno, job from emp group by deptno, job;
#查询每个部门的不同职位的平均工资,
#按照部门编号的升序排序
select AVG(sal), deptno, job from emp group by deptno, job order by deptno asc;
#执行顺序:from...where...group by...select...order by
#书写顺序:select...from...where...group by...order by
having
#查询平均月薪高于 2500 的部门编号和其平均月薪
select deptno, AVG(sal) from emp where AVG(sal) > 2500 group by deptno; #错误 where中不能出现多行函数
#所以出现新的技术点 having 和where的区别就是可以使用多行函数 作用就是处理多行函数的筛选
select deptno,AVG(sal) from emp group by deptno having AVG(sal) > 2500;
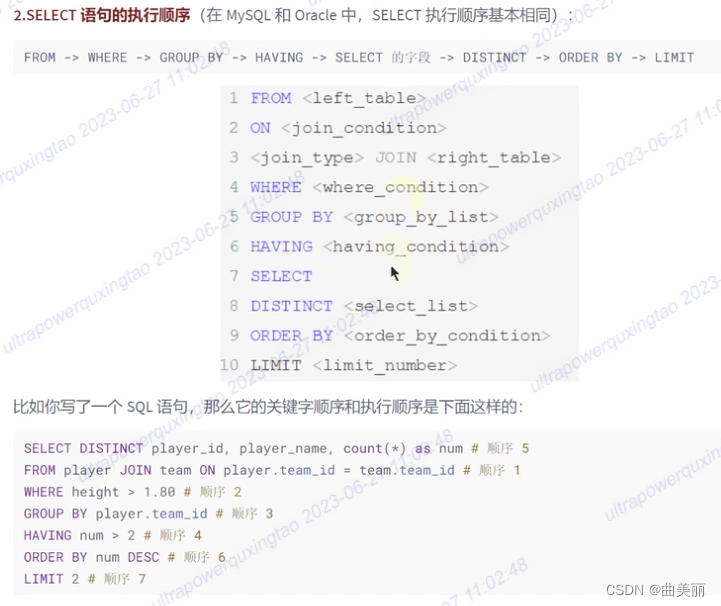
执行顺序(重要)
#执行顺序 from...where...group by...having...select...order by
#书写顺序 select...from...where...group by...having...order by
#查询平均月薪在 2000-2500 之间的部门编号和其平均工资
select deptno, AVG(sal) from emp group by deptno having AVG(sal) between 2000 and 2500;
3、多表连接查询(查询难点)
#多表查询基础——笛卡尔积
#A{a,b,c} B{1,2,3,4}
#A * B = {a1,a2,a3,a4,b1,b2…}
#笛卡尔积 + 条件查询
select * from emp, dept;
#基本写法
1、等值连接
#找意义相同的两列作为连接多个表的条件
#(一张表的最后一列与另一个张表的第一列)
#查询员工的姓名、员工所在部门名称
select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno;
#练习:查询月薪高于 1500 的员工姓名和部门名称
select e.ename,d.dname from emp e, dept d where e.deptno = d.deptno and sal > 1500;
2、不等值连接
#只要不是等号的连接方式
#查询员工的姓名,月薪和工资的级别
select e.ename, e.sal, s.grade from emp e, salgrade s where e.sal between s.losal and s.hisal;
SQL99 写法 join…on(…)
#格式:
#表 A left/right [outer] join 表 B on(连接条件) where 筛选条件
1、等值连接
select e.ename, d.dname from emp e join dept d on e.deptno = d.deptno where sal > 1500;
2、不等值连接
select e.ename, e.sal, s.grade from emp e join salgrade s on(e.sal between s.losal and s.hisal);
3、外连接 分为左外连接和右外连接
#作用 实现多表连接后,将某张表中独有的部分拿出来
#查询员工姓名,部门名称包括没有部门的员工 左外连接
select e.ename, d.dname from emp e left join dept d on e.deptno = d.deptno;
#右连接
select e.ename, d.dname from dept d right join emp e on d.deptno = e.deptno;
4、全连接(MySQL)
#查询员工姓名,部门名称包括没有部门的员工,没有员工的部门
select e.ename, d.dname from emp e full join dept d on e.deptno = d.deptno;
4、子查询
#按照结构分为单行单列子查询(常用)
#查询和 scott 同一个部门的其他员工信息
select *
from emp
where deptno = (select deptno from emp where ename = 'scott')
and ename <> 'scott';
#练习:
#查询与 scott 同部门,同经理的其他员工信息
select *
from emp
where (deptno, mgr) = (select deptno, mgr from emp where ename = 'scott')
and ename <> 'scott'
单行多列子查询(不常用,了解)
select *
from emp
where deptno = (select deptno
from emp
where ename = 'scott')
and mgr = (select mgr
from emp
where ename = 'scott')
and ename <> 'scott';
#SQL 语句中尽量减少 select 的个数
#推荐写法(考试容易考察的点)
select *
from emp
where (deptno,mgr) = (select deptno,mgr
from emp
where ename = 'scott')
and ename <> 'scott';
多行子查询
#多行单列子查询(不常用,了解)
#查询与 scott 或 king 同一个部门的员工信息
select *
from emp
where deptno in (select deptno
from emp
where ename in('scott','king')
);
#多行多列子查询(基本看不到的)
##按照语句
where 子查询(最重要)
#查询比 scott 月薪高的员工信息
select *
from emp
where sal > (select sal from emp where ename = 'scott');
from 子查询(重要, 万能查询)
select *
from emp e ,(select deptno, dname from dept) d
where e.deptno = d.deptno;
#查询员工姓名,部门名称,员工的月薪和其所在部门的平均月薪(重要)
#分为两步:
#1)查询部门的平均月薪,部门名称
select d.dname,avg(sal)
from emp e, dept d
where e.deptno = d.deptno
group by d.dname;
select d.dname,avg(sal)
from emp e join dept d
on e.deptno = d.deptno
group by d.dname;
#2)将上述的查询结构想象成一张"表",与 emp 做连接
select e.ename, t.dname, e.sal, t.avgsal
from emp e join (select d.dname, avg(sal) as avgsal, d.deptno
from emp e join dept d
on e.deptno = d.deptno
group by d.dname, d.deptno) t
on e.deptno = t.deptno;
#查询员工姓名,职位,月薪,及其同职位最高和最低的月薪
#1、先查询职位,及其同职位最高和最低的月薪
select e2.job, MAX(sal), MIN(sal)
from emp e2
group by e2.job;
#2、组合
select e1.ename, t.job, t.maxsal, t.minsal
from emp e1 join (select e2.job, MAX(sal) as maxsal, MIN(sal) as minsal
from emp e2
group by e2.job) t
on e1.job = t.job;
#查询月薪比自己职位的平均月薪高的员工信息
#1、根据职位查询平均月薪
select AVG(sal)
from emp
group by job;
#2、注意 e.*
select e.*
from emp e join (select job, AVG(sal) as avgsal
from emp
group by job) t
on e.job = t.job
where e.sal > t.avgsal
#查询月薪比自己职位的平均月薪高的员工信息
#1) 职位、平均月薪
select job, avg(sal)
from emp
group by job;
#2)用 1)结果与 emp
select e.*
from emp e, (select job, avg(sal) as avgsal
from emp
group by job) t
where e.job = t.job
and e.sal > t.avgsal;
having 子查询(不常用)
#查询部门平均月薪高于 MARTIN 的部门编号
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > (select sal
from emp
where ename = 'MARTIN');
#扩展的(可以不记)
#select 子查询(基本不用)
#查询部门编号,部门名称,
#部门所在地,各个部门人数,
#各个部门的平均月薪
select * from dept;
select deptno, dname, loc,
(select count(*)
from emp e
where e.deptno = d.deptno
group by deptno),
(select avg(sal)
from emp e
where e.deptno = d.deptno
group by deptno)
from dept d;
#先主查询先查询出一条数据,利用其中的某个值
#将其给子查询,子查询利用该值查询一个新的结果值,
#该新的结果值被主查询再使用
#每一条需要查询的数据都是按照从外到内,再从内到外
#的方式查询出来的
#相关子查询————数据库开发人员使用的
any all(理解)
#查询比 Jennifer 月薪高的员工信息 同名字中大于最大值
select *
from employees e
where e.salary > any(select salary
from employees
where first_name = 'Jennifer');
5、DDL 数据库定义语句
#既然是定义语句就不设计到数据,而是操作表和列
#需要记住的:
int:基本的整数类型
bigint:大整数类型
double:双精度浮点型(小数精度高 小数点之后位数)
varchar(4):可变长度字符串类型
char(4):固定长度字符串
DATE:日期类型
TIMESTAMP:时间戳类型(作用用于记录操作数据的时间)
创建表 create 是创建一个表结构 没有数据
#create table 表名 (列名1 数据类型1, 列名2 数据类型2,);
create table student_table(id int, name varchar(4), age int);
修改表 update
#1、修改表名 alter table 表名 rename to 新表名;
alter table student_table rename to stu_table;
添加表的列 (结构)
alter table 表名 add 列名 数据类型;
alter table stu_table add sex varchar(4);
修改列名称 类型
#alter table 表名 change 列名 新列名 新数据类型
#改类型
#alter table 表名 modify 列名 新数据类型
alter table stu_table change sex grade int;
alter table stu_table modify grade varchar(2);
删除列
# alter table 表名 drop 列名
alter table stu_table drop grade;
删除 delete
#删除表 if exists 如果有该表就删除
#drop table 表名
drop table if exists stu_table;
6、DML (Java 语句关于数据库的控制操作)
增(插入) insert into
#insert into 表名(列名1,列名2,列名3) values(值1,值2,值3);
#insert into 表名 values(值1,值2,值3);
##2、 删除数据
#格式:
delete from 表名 [where 条件];# 不推荐使用
#注意:where 条件必须存在,否则将删除全表数据
delete from student_table where id = 1;
oracle语法
DELETE FROM SCM_PROJECT WHERE ID = 202110181528
#一条一条的删除数据
SET SQL_SAFE_UPDATES = 0;#关闭 mysql 的保护模式
#删除的表中的数据,表的结构还在
#推荐使用
truncate table 表名;
#效率更高,先删除表,再创建一张一样的表
删除(delete、truncate、drop)之间区别(非常重要)
#delete:是 DML 语句,删除表中数据,表结构还在,
#数据可恢复的,因为会记录每条数据的日志。
#truncate:是 DDL 语句,清空表中数据,
#表结构也在(先删表(有数据),再见一个新表),效率要有 delete 高,
#数据是不可恢复的(有日志,但是日志记录的操作过程)
#drop:是 DDL 语句,直接删除表和数据,表结构都没有了。
修改数据
#update 表名 set 列名1 = 值1,列名2 = 值2 【where】
#where条件必须存在,否则会将该列的全部记录都修改为一样的数据
update stu_table set age = 12, sex = '男' where id = 1;
复制表
#两种方式:create table emp1 select * from emp;
#复制的是表数据+结构
create table emp2 like emp;
#复制的只是表的结构
实战中碰到的数据去重
delete from scm_input_waste_book
where (id,rowid) in
(select t.id,min(rowid) from scm_input_waste_book t group by t.id having count(1) > 1)
7、约束
(给表的结构加一种条件,限制数据的录入)
#注意:约束是属于表的结构的一部分
#分类
#1、主键约束 primary key
#2、非空约束 not null
#3、唯一约束 unique
#4、外键约束 foreign key
非空约束
#要求值不能为空值,这样可以避免空值的录入
create table stu(
id int,
name varchar(20) not null -- name 该列的值不能为空
);
insert into stu(id, name) values(1, 'haha');
insert into stu values(1, null);
#创建表后,添加非空约束
alter table stu modify name varchar(20) not null;
#注意:如果表中已有空值,则非空约束无法添加
delete from stu where id = 1;
#删除 name 的非空约束(修改:将约束修改掉)
alter table stu modify name varchar(20);
唯一约束 unique 值不能重复
#创建表添加唯一约束
create table stu(
id int,
name varchar(20) unique -- name 不能出现重复名
);
insert into stu values(1, null);
insert into stu values(2, null);
#注意:唯一限制的数据的真实值不能重复,但是空值除外
#null 是可以重复的
#创建表后,添加唯一约束
alter table stu modify name varchar(20) unique;
#删除 name 的唯一约束
alter table stu drop index name;
主键约束 primary key
#创建表添加主键约束
create table stu(
id int primary key,-- 添加主键约束
name varchar(20)
);
#注意:
#1、特点:非空并且唯一
#2、一张表只能有一个列(属性、字段)是主键,
#但是可以有两个列组成的联合主键(不是两个列分别设置主键)
#3、主键是表中记录的唯一标识
#删除主键约束
alter table stu drop primary key;
#创建表后添加主键约束
alter table stu modify id int primary key;
自增(有的人说是约束,有的人说不是)
#1、概念:如果某一列是数值类型,使用自增(auto_increment)
#自动实现数值的增长,一般用于主键的编号自动增长
在这里插入代码片
insert into stu(id, name) values(1, 'haha');
insert into stu(name) values('haha');
#但是主键的编号往往使用 int 类型,目的就是为了实现自增
#自增的目的:
#注册 QQ 号
#号码其实就是主键
#我们用其他的基本信息实现注册,系统会给我们返回一个号码
#删除自增
alter table stu modify id int;
#后添加自增
alter table stu modify id int auto_increment;
外键约束 foreign key
#让表和表之间产生关系,从而保证数据的正确性
#创建表添加外键
create table 表名(
...
-- deptno
constraint 外键名称 foreign key(外键列名称)
references 主表名称(主表列名称)
);
#删除外键
alter table 表名 drop foreign key 外键名字;
alter table emp drop foreign key fk_deptno;
#创建后添加外键
alter table 表名 add constraint 外键名字
foreign key(外键列名字) references 主表名字(主表列名字);
alter table emp add constraint fk_deptno
foreign key(deptno) references dept(deptno);
8、事务处理
#事务
#一系列将要发生或者正在发生的连续操作
#实际操作:实时银行转账
#转 500
#汇款人 2000 收款人 1000
#修改自己数据 修改自己数据 同时发生
#实质就是两个 sql update 同时执行
#多个 DML 语句就是事务的处理
事务特性(重要)
#1、原子性:组成事务的 DML 语句是不可分割的整体
#2、一致性:这些 DML 语句要么同时完成,要么同时不完成
#3、隔离性:不同事务之间不能互相影响
#4、持久性:事务被提交(commit)后,结果存入数据库(变更我们认为有效)
#一旦数据改变后就一直存在
#mysql 事务处理默认的是自动提交
set autocommit = off;#设置关闭自动提交
流程:
#事务操作,分为自动事务(默认)和手动事务
#1) 开启事务(告诉数据库我接下来的操作,不要直接写入数据库,
#先存到事务日志中)
start transaction; #开启事务
#2) 减少 Charies 账户余额 ,减少 1000
update bank_account set money = money - 1000
where id = 1;
#3) 增加 Gavin 账户余额 ,增加 1000
update bank_account set money = money + 1000
where id = 2;
select * from bank_account;
#事务的操作:提交和回滚
commit; #提交
rollback;#回滚(撤销)
#黑屏界面(命令行:字符,没有图形)
use mydata; #选中数据库
create table mm(
sex enum('男' , '女')
);
#枚举型 sex 要么是男要么是女
#default ‘男’
#default 默认值
#通过前台页面做限制
#<input type = "radio"/>
视图(了解) view
#视图核心操作——查询
#是一种有结构(有行和列),但是没有结果(结构中不是真实的
#存放数据的位置)的虚拟表。
#可以将视图看做是表的快捷方式,所以视图中的数据来源表
select *
from emp, dept
where emp.deptno = dept.deptno;
select * from emp;
#创建视图
#create view 视图名 as select 语句;
#select 语句 普通查询、多表查询、子查询等
create or replace view emp_view as
select emp.*, dept.dname, dept.loc
from emp, dept
where emp.deptno = dept.deptno;
#replace 替换 可以后续继续修改视图的结构
select * from emp_view
where deptno = 10;
#分类:单表视图、多表视图
#索引(了解)
#类似于目录,方便查询、定位文件,
#降低了插入操作和删除操作的效率
#查询与(增、删)在效率上是对立
#三种方式实现索引
1、创建表的时候建立索引
2、在已经存在的建表语句后创建索引
create table 表名(
列...
...
#追加索引
);
3、使用 alter table 语句创建索引
create table 表名(
列...
...
);
追加索引
#针对索引都是数据库自动实现的,不需要我们手动实现
权限(了解)
#创建用户
create user '用户名'@'主机名' identified by '密码';
#用户名:创建的用户名
#主机名: 如果我们想登陆本地的数据库服务器
#localhost(本地主机) 远程主机是 ip 值,
#任意数据库可以使用通配符%
#创建 user1 用户,只能在本地主机登录 mysql,要求密码是 123
create user 'user1'@'localhost' identified by '123';
#给用户授权
#格式:
#grant 权限 1,权限 2,... on 数据库名.表名 to '用户名'@'主机名'
#grant...on...to 授权
#要求:给 user1 用户分配对 mydata 数据库操作权限:创建表、
#修改表、插入记录、更新记录、查询
grant create, alter,insert, update, select on mydata.*
to 'user1'@'localhost';
#撤销授权
#revoke 权限 1,权限 2,... on 数据库名.表名 from '用户名'@'主机名'
revoke all on mydata.* from 'user1'@'localhost';
#revoke...on...fro
练习题
employess表 练习
#1.查询每个岗位的平均工资,最高工资和最低工资
select AVG(salary), MAX(salary), MIN(salary) from employees group by job_id;
#2.查询月薪高于 8000 的员工,按照岗位查询平均工资
select AVG(salary) from employees where salary > 8000 group by job_id;
#3.查询各部门,各个经理负责的员工的平均工资(员工工资和经理和部门对应)
select department_id, manager_id, AVG(salary) from employees group by department_id, manager_id;
#4.查询平均工资高于 8000 的岗位 id 和平均工资
select job_id, AVG(salary) from employees group by job_id having AVG(salary) > 8000;
#5.查询司龄高于 20 年的员工的平均工资
select AVG(salary) from employees where datediff(curdate(), hire_date) / 365 > 20;
#6.查询 1995 年之前入职员工的最高工资和最低工资
select MAX(salary), MIN(salary) from employees where substring(hire_date, 1, 4) > 1995;
#7.查询各个部门的部门 id 和部门人数
select department_id, COUNT(*) from employees group by department_id;
#8.查询各个部门部门 id 和月薪的总和
select department_id, SUM(salary) from employees group by department_id;
#9.查询在 1992-1993 年间入职员工平均工资
select AVG(salary) from employees where hire_date between '1992-01-01' and '1993-12-31';
#10.查询在 1990 年入职的员工的平均年收入
select AVG((salary+salary*IFNULL(commission_pct,0))*12) from employees where substring(hire_date, 1, 4) = 1990;
select avg((salary + salary*ifnull(commission_pct,0))*12) from employees where hire_date between '1990-01-01' and '1990-12-31';
#2、处理习题
#1.查询 Nancy Greenberg 的员工信息
select * from employees where first_name = 'Nancy' and last_name = 'Greenberg';
select * from employees where CONCAT(first_name," ",last_name) = 'Nancy Greenberg';
#2.查询职位是 AD_VP,并在 1990 年之前入职的员工
select * from employees where job_id = 'AD_VP' and hire_date < '1990-01-01';
#3.查询月薪在 10000-20000 期间、部门是 90 号的员工信息
select * from employees where salary between 10000 and 20000 and department_id = 90;
#4.查询司龄高于 20 年员工信息,按其月薪升序排序
select * from employees where datediff(curdate(), hire_date) / 365 > 20 order by salary asc;
#5.查询年收入高于 25 万的员工信息
select * from employees where salary*(1+ifnull(commission_pct, 0))*12 > 250000;
#6.查询职位以’SA’开头的所有员工
select * from employees where job_id like 'SA%'
#7.查询上司是 145,146,147,149 的所有员工
select * from employees where manager_id in(145,146,147,149);
#9.查询不属于任何部门的员工信息
select * from employees where department_id is null;
#10.查询本月的倒数第三天的日期 本月最后一天:last_day()
select date_format(LAST_DAY(CURDATE()) -2, '%Y-%m-%d') from dual;
#11.查询 employees(员工表)入职日期在 1992 年之后的员工
select * from employees where hire_date > '1992-12-31';
#12.查询员工姓名,入职日期,入职日期的格式是”XXXX 年 XX 月 XX 日”
select first_name, last_name, date_format(hire_date,'%Y年%m月%d日') from employees;
重要:实战中的思路打通
内连接:
含义表述:只有一个表匹配另一个表连接条件的数据才会查出来。比如员工表一条记录没有部门id,那么员工和部门表关联这条记录不会查出来。反过来如果一个部门的记录没有人,那么这个记录也不会查出来。
多表等值连接时,如果表e记录中有连接条件为空,那么这张表不会查出来,因为表d中的记录没有符合表e这条记录的条件。比如表e中107条记录中有一条记录deptno为空,那么查询会查不出来这条。所以会查106条记录。
select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno;

join 等同于 inner join .inner可省略(外连接的outer也可省略)

自连接:

外连接:
左外连接:包含两表公共部分和左表多的。
右外连接:包含两表公共部分和右表多的。
全外连接:包含两表公共部分和左表多的和右表多的。


注意:员工表有一个员工有奖金但是没有部门,不用外连接会查不到这个员工。还有个问题是需要关联部门地址表时需要用部门表关联,但是员工都没有部门更没有部门的地址了。所以关联部门地址时也要用外连接。
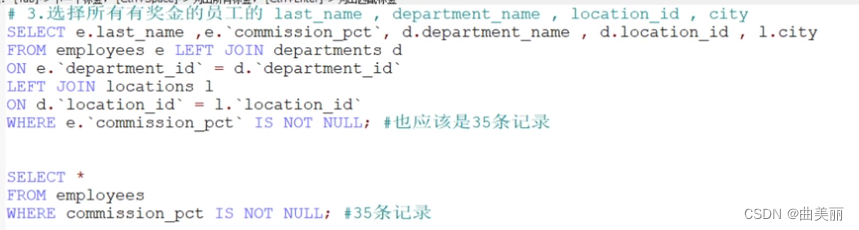
注意:多表查时,如果查其中一个表的所有数据时就用外连接。

mysql不支持全连接。
union补充全连接
员工表和部门表:内连接106条(共同的数据)。
员工表独有的1条(员工没部门的数据),部门表独有16条(部门没员工的数据)。

用UNION ALL语句需保证无重复,保证无重复我们可以使用下面的多表连接图中的组合实现两个sql连接后无重复。
如这两个组合
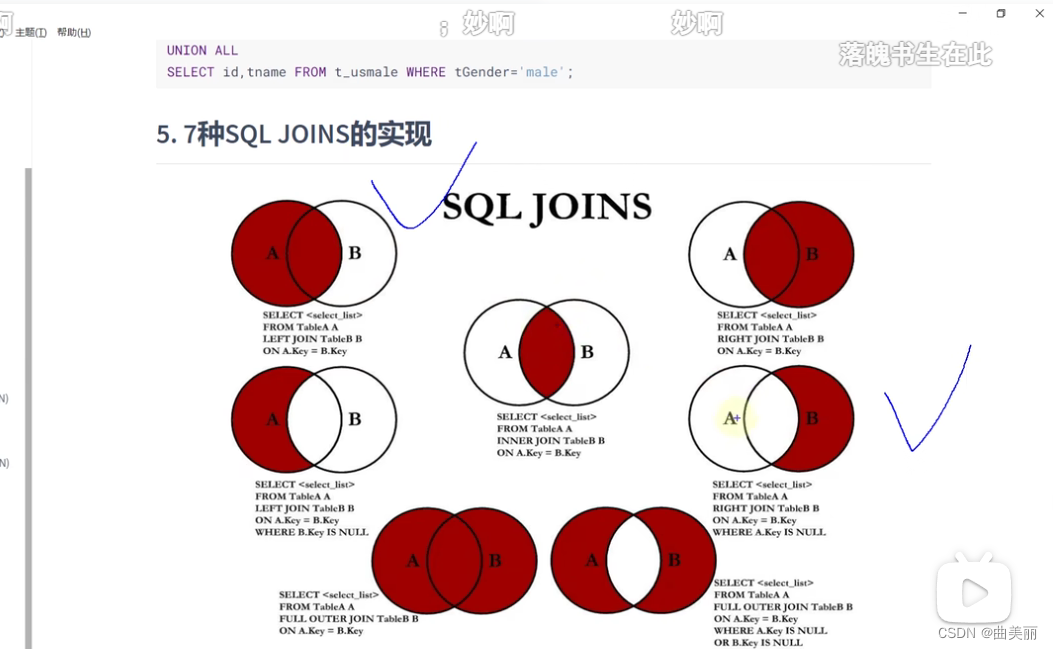

总结:
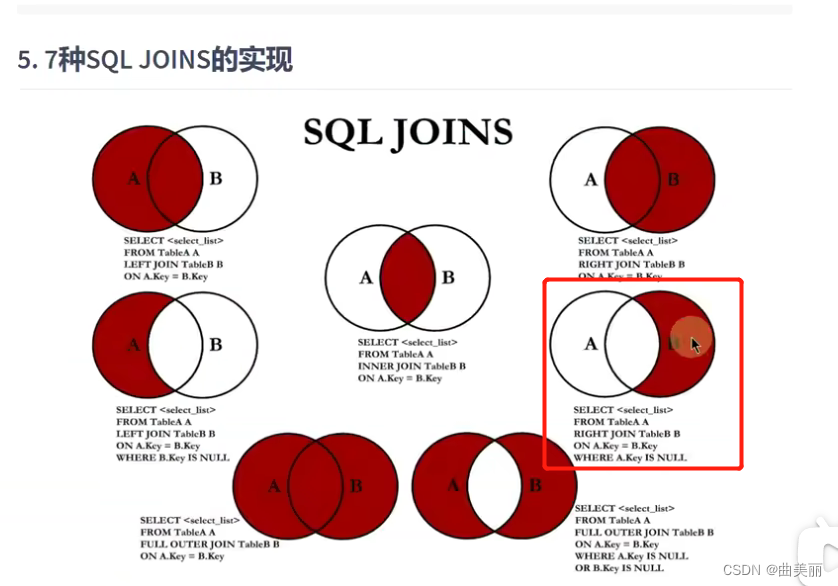
多表连接图:

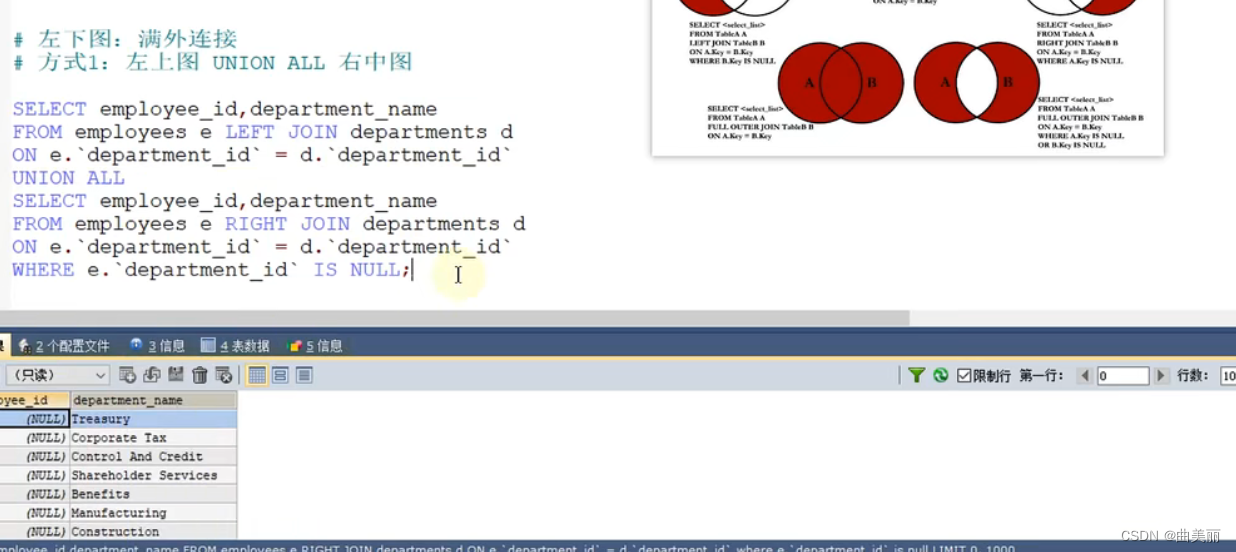

重要练习题


group by分组:
分组的意思是分小组,数据层面上来说,也就是一个组需要聚合成一行展现出来。比如按部门编号分组,那么50号部门的数据为一行,60号也为一行。
注意:为什么除了group by的字段和聚合函数的字段,不能在分组语句中查询出来。
分好组后,查询组内的员工编码字段是不能展现出来的,比如查询50号部门下的员工编号,主要问题就是50号部门下有多个员工,但是按组需要聚合成一行展现,那么展现50号部门的哪个员工编号呢。所以这是不能实现的。

having

如果分组后,如果过滤条件中出现聚合函数时,过滤条件需要用having过滤,而不能使用where.
错误示范:

修正后:

实例:

注意:where和having的区别
过滤条件没有聚合函数一定要生命在where中,因为效率很快。
书写顺序:

执行顺序:

注意:select的列别名只能在order by中使用不能在where中使用,因为where的执行顺序在select之前。
子查询:一次查询不能得到想要的结果

多行子查询

in:
查询每个部门员工工资最低的员工编号和名字

all:

any:
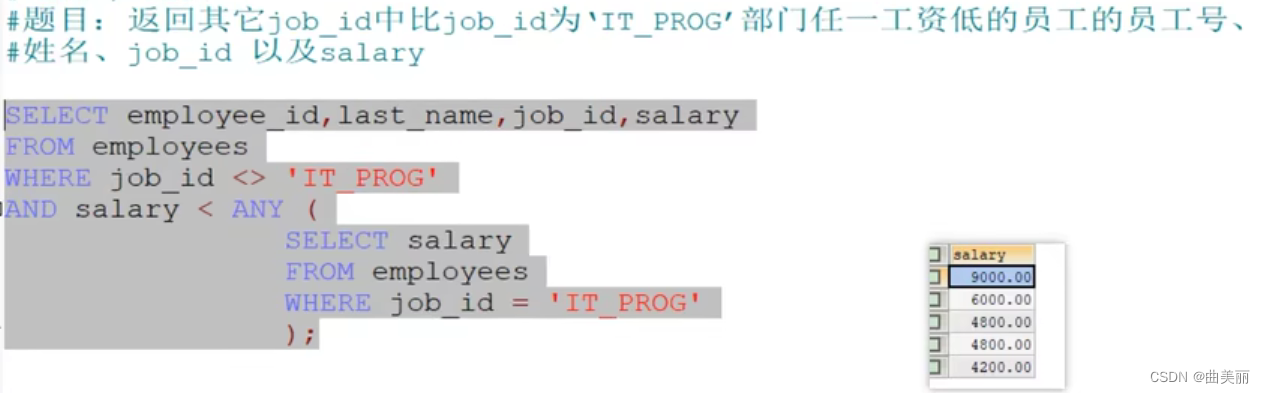


空值问题:内查询有空值问题导致查询不任何到数据
这是正常查询:查询公司管理者
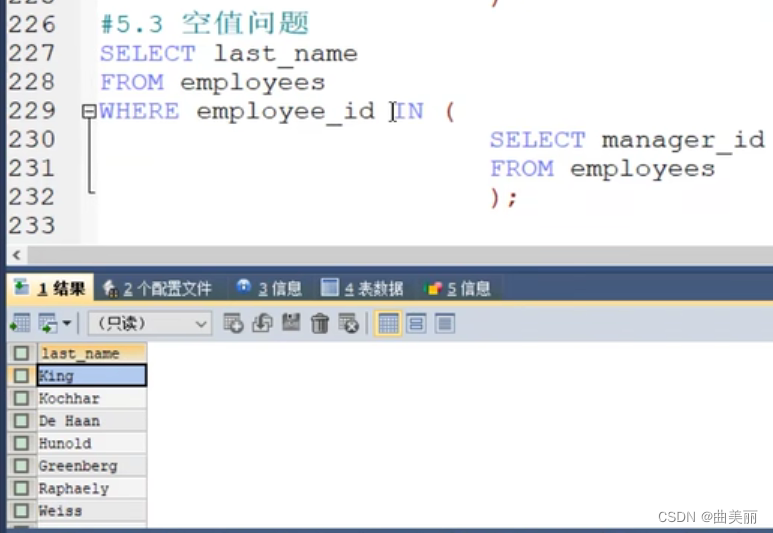
错误案例:查询不是管理者的员工:这样查会查不到结果集。因为有一个员工的管理者字段为空
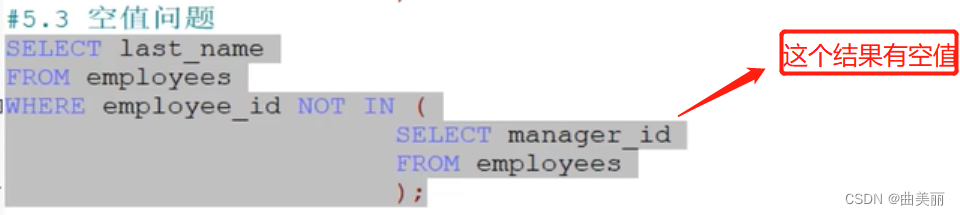
解决办法:判空

相关子查询
以上都是不相关子查询。

回顾:外查询的每一条数据跟子查询的平均工资比
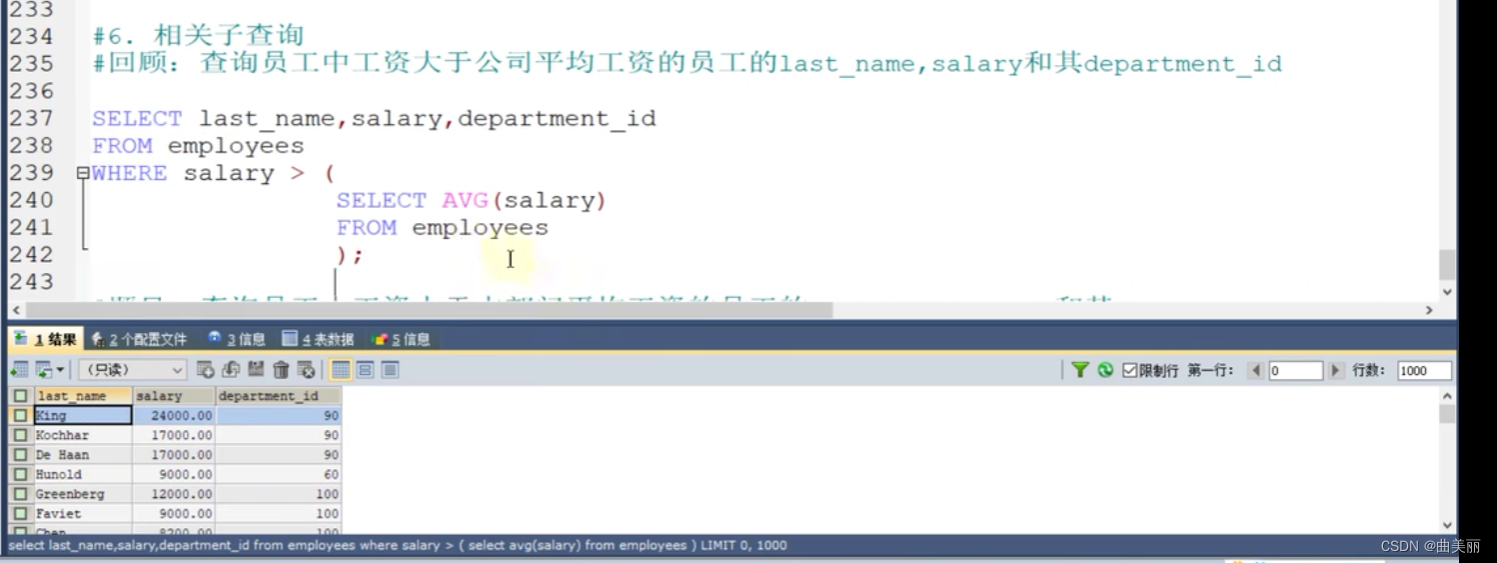
相关子查询


order by中
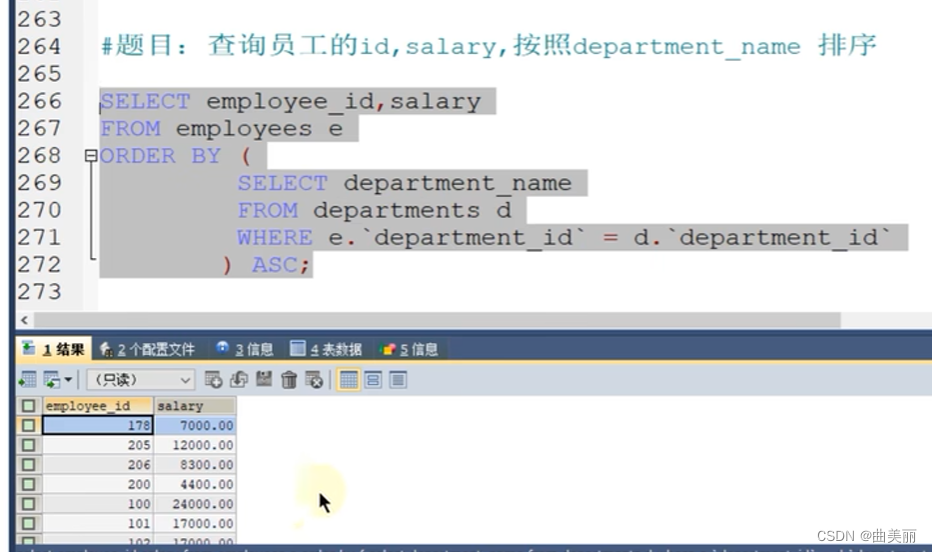

查询哪些员工调过两次岗以上

exists和not exists关键字,也是相关子查询



注意:内查询中的 select * 无所谓,用select '1’都可以。

查询没有员工的部门


相关更新
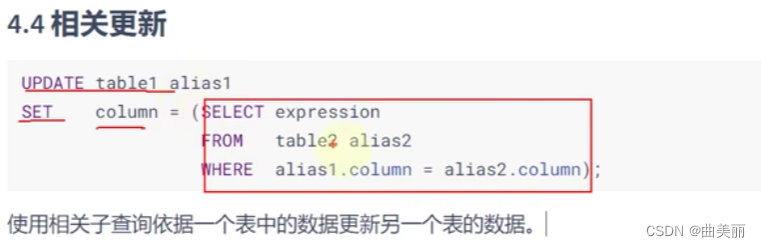
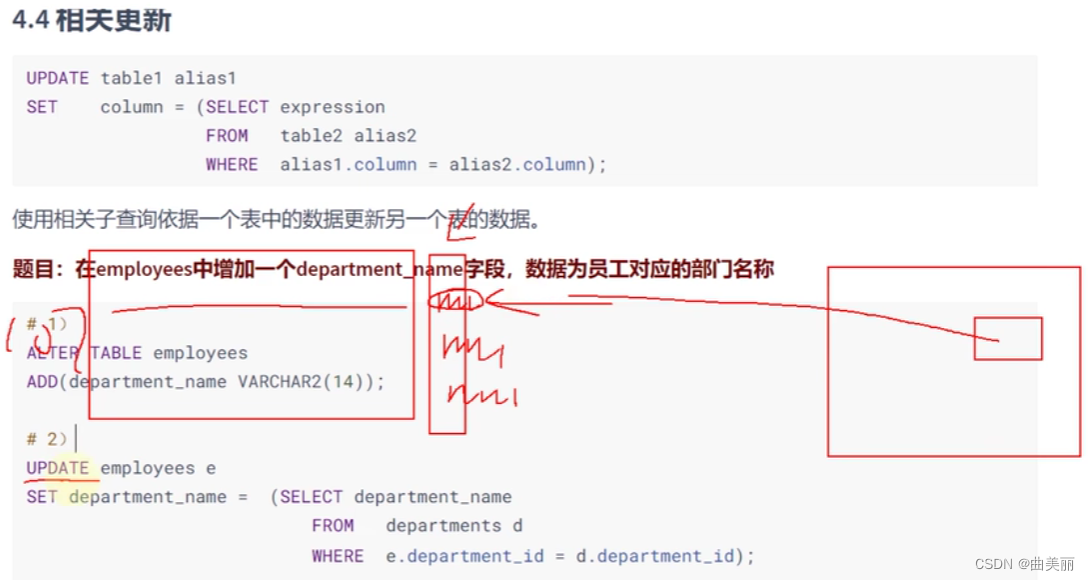
给表a加字段,但是表a原来的数据中加的这个字段不能空,所以需要查询这个字段来源表的值填上去,使表a的这个字段不为空。
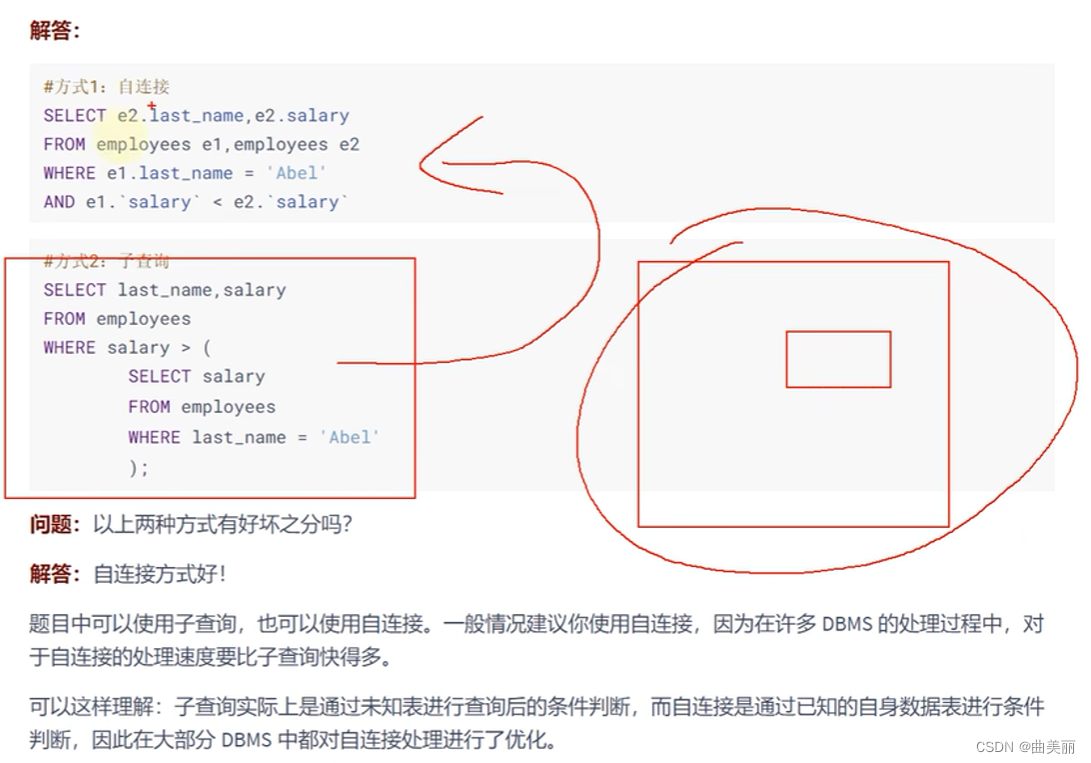
相关删除

自连接要比子查询效率高。
视图
就是存储起来的sql语句(持久化sql语句)。
修改视图view是可以把原表同时修改的。也就是同步。view其实就是表的数据。
存储过程与函数
存储过程:
存储过程是没有返回值的(存储函数有返回值)
一组经过预先编译的sql语句的封装。




可以使用参数。in、out、inout

存储函数:
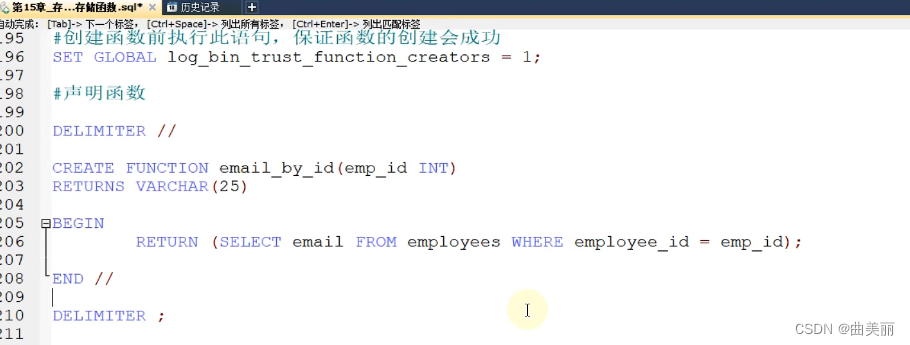

存储过程和方法的查看

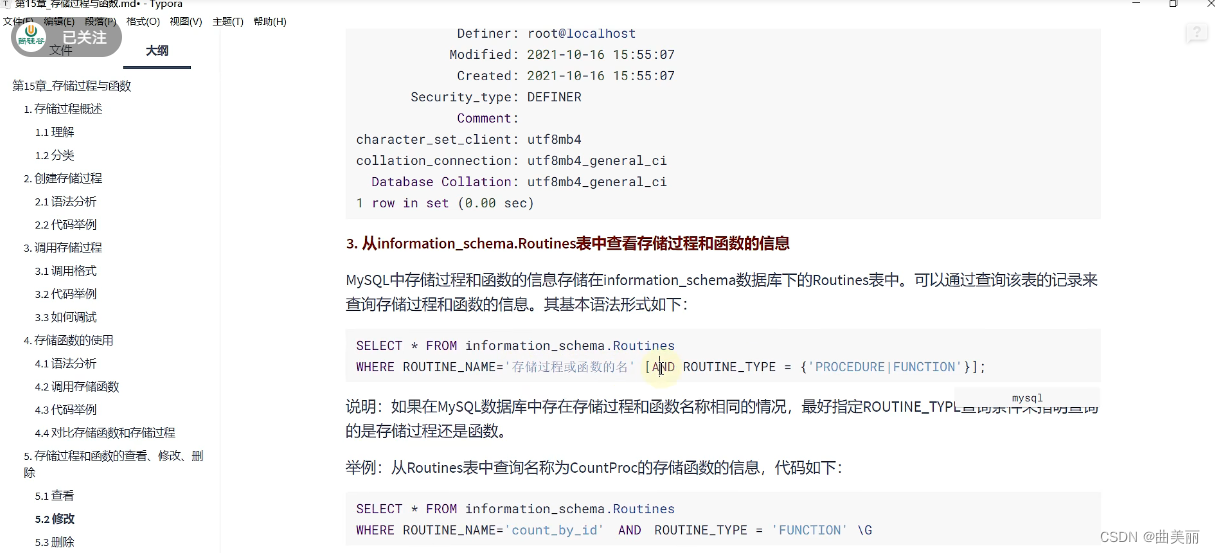
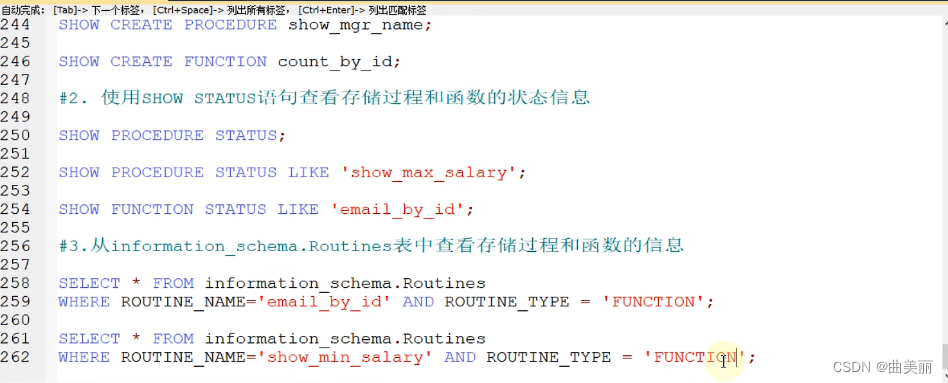
修改存储结构和函数,只能修改特性不能修改函数体里面的sql功能,如果想修改功能只能删除再添加。















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









