







算法:FedNova
论文:Tackling the Objective Inconsistency Problem in Heterogeneous Federated Optimization
数学公式含量巨大,还有一些原创概念名词,看半天只看了个大概。大意就是通过加权平均的方式,让epoch多的client影响小一点,epoch少的client影响大一点,最终让所有client的影响与epoch的大小没什么关系。因为epoch在FL中影响巨大,epoch多的Client会将最终结果明显的往自己这边带。
论文:Federated learning on non-iid data silos: An experimental study
综述类的论文,前面大概介绍了下FL面临的各种异构和挑战,第11页开始介绍结论:
- 没有能稳压任何算法的算法,都有其局限性,就算能赢其他算法也只是在某些数据分布下,而且只是略胜
- 现有的算法在MNIST上表现优异,在CIFAR-10上表现差
- 现有的算法在Client只有一种Lable的情况下都表现很差
- 现有的算法在Client上都走向本地最优而非全局最优,本地epoch次数很重要
- 简单的模型参数平均并非好做法,要考虑其他参数比如方差均值等
还有一些展望和杂七杂八的
论文:Federated learning on non-IID data: A survey
一个综述类的论文,大概是把FL的所有方向和现状讲了个遍,想仔细看完应该要好久的时间,还没认真看完。
论文:Federated Learning with Personalization Layers
不知道算不算PFL的入门论文。接触一些新名词,如下
协同过滤
推荐算法,推荐喜欢的,过滤讨厌的。
迁移学习、多任务学习、元学习
迁移学习:模型可以将从任务(数据)A中学习到的知识应用于任务B中。比如Model从A中学习到了怎么分辨猫狗,再马上给他一个任务B,判断是不是兔子,那虽然给Model其他的动物图片它分辨不出来,但是给猫狗的图片会直接说No。不过如果B的数据量够了,就不再需要A的迁移学习了。
多任务学习:Model需要输出多个Lable。例如给出一张图片需要同时判断猫狗兔是否存在。
元学习:迁移+多任务学习的加强版,只需要提供小样本就可以学习到新领域的东西,更多样更高效
文章大意
将Model分为Base层和个性化层,Base层的作用是将数据抽象成高维提取特征,提取特征这个操作是一种比较统一化的操作,所以这个层的参数更新需要所有Client的参数加在一起加权更新。个性化层也就是分类层,用于完成最终的数据分类工作,这个层的能力需要“定制”,要有个性一点,所以这个层的参数本地更新就行了。
这是因为由于数据异质性导致所有的Client数据分布不一样,比如Client A具有很多的Lable A,Lable B,事实上它的重点也就是分出Lable A和B;而ClientB有很多的LableC和D,而这个Client想做的事也就只有分出LableC和D,前面两个Lable不关心。如果按FedAVG跑出一个统一的模型,结果大概率是分辨四个Lable的效果都比较一般,但如果让Model中的个性层只跑自己专长的数据,那ClientA分辨AB的能力和ClientB分辨CD的能力肯定高于FedAVG。
这应该就是PFL的思想,P层个性化地只训练自己这边的数据,因为别人的数据可能是自己毫不关心的,加进来跑还会影响自己的专项能力。同时B层又有FL的好处,提取特征的能力是大家都需要的,所以就大家一起学习提高能力。
算法:FedPAC
论文:PERSONALIZED FEDERATED LEARNING WITH FEATURE ALIGNMENT AND CLASSIFIER COLLABORATION
上面这篇论文的改良版,提出了FedPAC框架。说了上面这篇在数据同质的情况下表现差,因为同质下一起跑数据效率才最高,但上文的做法还是自己跑自己的,太死板了。这篇文章提出了一种做法即基于正则化的特征对齐,能够让特征相近的数据一起学习,特征不同的数据分开学习,这样在两种情况下都表现良好。
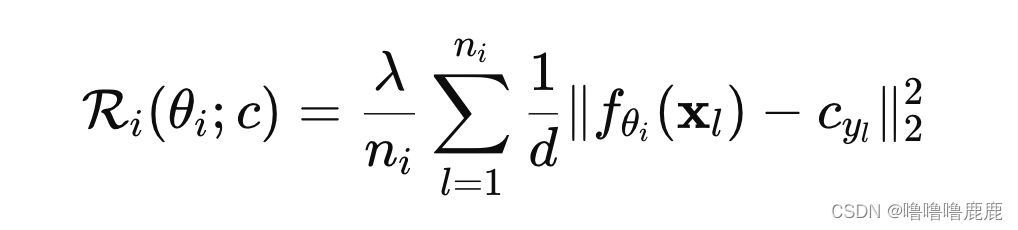
FedPAC的正则项的公式长这样,大概就是自身特征质心与全局特征质心的距离的平方,特征质心是每个特征分别计算。因此在遇到其他Client有训练同样的特征的时候会将当前Client往全局最优的方向拉,起到一种大家一起训练的效果;在遇到其他Client都没有训练该特征的时候,也只会将当前Client的训练方向往原点拉,虽然会降低训练速度但并不影响准确率。
算法:Per-FedAVG
论文:Personalized Federated Learning: A Meta-Learning Approach
大概就是在FedAVG的基础上,拿到全局Model后本地再自己跑一点数据微调一下,让Model更适合解决本地的数据。与FedPer不同,这个没分层。
算法:KAFAL感知联邦主动学习
论文:arXiv’22 Knowledge-Aware Federated Active Learning with Non-IID Data
内含两种算法:KSAS知识专攻主动采样,KCFU知识补偿联邦更新
KSAS:
考虑到罕见类对全局模型作用不大又会产生不好的影响,所以定义了一个知识专用KL散度去增强多数类的影响。
KCFU:
通过知识蒸馏的方式,让全局模型给client喂罕见类,从而增强client模型的泛化能力。
下面是本地更新算法LocalUpdate

这段算法大意:第一轮先只拿标注的数据跑一下交叉熵(文中给它加了个前缀balanced,据说能更好的应付non-IID),之后所有的轮次都是里面混着未被标注的数据跑的,损失函数是标注的数据的交叉熵与未标注数据全局模型和局部模型跑出来结果的KL散度这俩东西分别乘上一个神秘的比例相加。至于为啥是第一轮和后面所有的轮次处理的方法不一样,论文里好像没说,个人感觉是第一遍正常跑让模型有基本的分辨能力,相当于打好基础,之后拿参杂着未标注的数据跑以增强模型的鲁棒性。
然后这个论文全局模型的更新就是常规的参数更新。
这篇文章给我的启发是可以限制某个场景,然后用某种算法解决。本文就是限定了数据集一部分是有标签一部分无标签的情况。感觉可以想一个特殊的场景,然后想办法处理这个场景下的FL该怎么做。除此之外应该多接触一些算法,比如这篇文章的知识蒸馏和主动学习,因为各种场景还是需要各种算法去解决。















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









