







论文:Communication-Efficient Learning of Deep Networks from Decentralized Data
联邦学习的入门论文。论文大意就是由于各种原因,我们需要一种新的分布式的学习算法,用于将各客户端的数据也都加入训练中,但是不能直接将客户端数据直接给服务端,这种算法就叫联邦学习。
论文里面写了俩算法,一个是FedSGD,一个是FedAVG。
FedSGD算法
Server端先给出一个模型,然后每轮选择随机K个Client给出Server的模型。这些Client训练完一次后再把得到的梯度传给Server,Server将这些梯度平均后更新自身的模型,然后再进行下一轮操作。
缺点:每次获取梯度后都要进行一轮通信,导致通信的频率过高。联邦学习中其实通信的代价也是非常大的,因此该算法耗时明显偏大。
FedAVG算法
Server端先给出一个模型,然后每轮选择随机K个Client给出Server的模型。这些Client训练完多次后再把得到的模型参数传给Server,Server将这些参数平均后合成自身的模型,然后再进行下一轮操作。
缺点:虽然通信代价比前者下降了许多,但是Server所获取的模型参数只是对于各Client参数的简单相加,没有考虑到异质性。而且遇到某些Client无法及时回传数据的情况,该算法会粗暴的将这些Client计算的结果忽略,这肯定会导致最终的结果产生偏差。
异质性
大致上分为两种异质性:数据异质性和系统异质性。
数据异质性
又分为数据量异质性、特征异质性和标签异质性。数据量异质性指的是每个Client之间的数据量不同,比如A有100个数据,B只有1个数据。标签异质性是指每个Client之间的数据标签不同,比如A中的数据有猫、狗、猪、马,B中的数据里只有乌龟。标签异质性会导致最终跑出来的模型产生偏差,比如给模型100张猫的图,1张狗的图,那么最终模型对于猫的辨认能力一定远大于对于狗的辨认能力。还有就是特征异质性,就是一些对比度或者不会影响最终判断的特征。
系统异质性
有许多。常见的是算力异质性,还有一些存储、网络之类的。
FedProx算法
论文:FEDERATED OPTIMIZATION IN HETEROGENEOUS NETWORKS
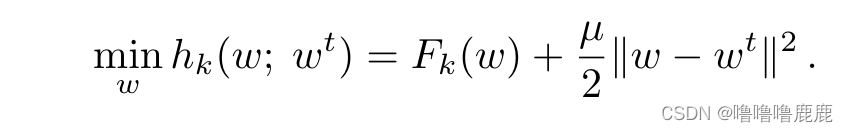
其他操作大致和FedAVG一样,但是损失函数里加了一项,如上图,是当前Client和Server参数差的平方,这使得Client的模型参数不会偏移Server里的参数太多,是一种中心化思想,大概能防止一些比较偏数据训练出的Client 产生不好的影响。
缺点:说到底还是一个比较保守的算法,导致Server的每一步更新都无法更新太多,直接导致算法效率较低。
SCAFFOLD算法
论文:SCAFFOLD: Stochastic Controlled Averaging for Federated Learning
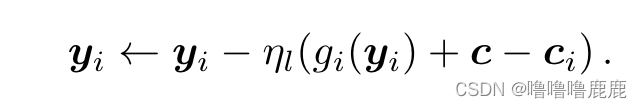
其他大致操作和FedAVG一样,但是损失函数里加了c作为所谓的"控制变差"。ci是第i个Client的梯度,c是所有Client的梯度的平均值,所以大概思想也是中心化,把所有的Client都往平均值拉。但是与Prox不同的是效率较高,考虑一种情况,所有Client的梯度都非常大,假设为100,那么Prox的损失函数此时也会非常大,会加上一个100的平方的量级,从而将Client的更新往中心拉,导致更新幅度较小。但是SCAFFOLD算法遇到这种情况每一项的ci都是100,c也是100,那么每一项都是加上一百再减去一百,没有任何变化,所以该更新多大幅度就更新多大幅度,因此这个算法的效率明显比Prox高不少。
知识蒸馏
其实就是先训练出一个非常笨重的模型,称为老师模型,然后再拿老师模型给出的数据喂给一个新的模型,新的模型是学生模型,会比老师模型轻量化一点。之所以能轻量化是因为老师模型跑出来的数据都是soft lable,会比hard lable有更多的信息,训练的效果更好。hard lable和soft lable感觉几句话说不清,就不多说了。
FedProto算法
论文:FedProto: Federated Prototype Learning across Heterogeneous Clients
定义了一个原型的概念。现在Model跑出来的不再是结果而是一个原型了,这个论文只讲了分类任务,有几个分类就有几个原型,原型里包含着一个高维的数据,代表着这个分类的抽象信息。
首先Server一开始的原型是空的,然后下发指令让各个Client跑出的原型作为结果回传给Server,Server将这些原型进行简单的平均之后成为自己的原型,然后再把这个原型下发给Client,让所有Client拟合这个原型(损失函数与Client的原型与Server的原型之差有关,差距越大函数值越大)。最终这个算法算出来的是每个分类的抽象数据,要是想知道某个图属于哪个类的话,随便找一个Client跑一下然后得出一个抽象数据,再跟每个分类的抽象数据算一下距离,哪个距离最小就属于哪个类。
这个算法容许每个Client的Model不一样,这是和其他算法最不一样的地方。
而且FedProto提出的思想将Model的硬聚合转化成每个类别的分别聚合,这样会非常有针对性。传统的硬聚合会将Model往数量多的Lable那边偏,但是这样每个类分成一个原型再聚合,就会好很多。
名词积累:bottleneck 瓶颈 fine tune 微调
附上FedAVG复现,用线程池实现
server.py
import copy
import numpy as np
import torch
from concurrent.futures import ThreadPoolExecutor
class Server:
def __init__(self, model, clients):
self.model = model
self.clients = clients
def aggregate_weights(self, weights_list):
avg_weights = copy.deepcopy(weights_list[0])
for key in avg_weights.keys():
for i in range(1, len(weights_list)):
avg_weights[key] += weights_list[i][key]
avg_weights[key] = torch.div(avg_weights[key], len(weights_list))
return avg_weights
def train(self, rounds, epochs, lr):
with ThreadPoolExecutor() as executor:
for r in range(rounds):
futures = [executor.submit(client.train, epochs, lr) for client in self.clients]
for future in futures:
future.result()
weights_list = [client.get_weights() for client in self.clients]
avg_weights = self.aggregate_weights(weights_list)
for client in self.clients:
client.set_weights(avg_weights)
print(f'Round {r + 1}/{rounds} completed')
def evaluate(self):
accuracy_list = []
for client in self.clients:
accuracy = client.evaluate()
accuracy_list.append(accuracy)
avg_accuracy = np.mean(accuracy_list)
print(f'Average accuracy: {avg_accuracy}')
client.py
import random
import torch
from torch import nn, optim
import time
class Client:
def __init__(self, model, train_loader, test_loader, device, client_id):
self.model = model
self.train_loader = train_loader
self.test_loader = test_loader
self.device = device
self.model.to(self.device)
self.client_id = client_id
def train(self, epochs, lr):
time.sleep(random.randint(1, 5))
print("Client{} start training......".format(self.client_id))
self.model.train()
optimizer = optim.Adam(self.model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
for data, target in self.train_loader:
data, target = data.to(self.device), target.to(self.device)
optimizer.zero_grad()
output = self.model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
def evaluate(self):
self.model.eval()
correct = 0
with torch.no_grad():
for data, target in self.test_loader:
data, target = data.to(self.device), target.to(self.device)
output = self.model(data)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
accuracy = correct / len(self.test_loader.dataset)
return accuracy
def get_weights(self):
return self.model.state_dict()
def set_weights(self, state_dict):
self.model.load_state_dict(state_dict)
test.py
import torch
from torch import nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Subset
from torch.nn import functional as F
from client import Client
from server import Server
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.fc1 = nn.Linear(256 * 4 * 4, 512)
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = x.view(-1, 256 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
num_clients = 5
train_loaders = []
test_loaders = []
data_len = len(train_dataset) // num_clients
test_data_len = len(test_dataset) // num_clients
for i in range(num_clients):
train_indices = list(range(i * data_len, (i + 1) * data_len))
test_indices = list(range(i * test_data_len, (i + 1) * test_data_len))
train_loader = DataLoader(
dataset=Subset(train_dataset, train_indices),
batch_size=32, shuffle=True)
test_loader = DataLoader(
dataset=Subset(test_dataset, test_indices),
batch_size=32, shuffle=False)
train_loaders.append(train_loader)
test_loaders.append(test_loader)
# 确保最后一个客户端获取剩余的所有数据
if len(train_dataset) % num_clients != 0:
remaining_train_indices = list(range(num_clients * data_len, len(train_dataset)))
train_loaders[-1] = DataLoader(
dataset=Subset(train_dataset, remaining_train_indices),
batch_size=32, shuffle=True)
if len(test_dataset) % num_clients != 0:
remaining_test_indices = list(range(num_clients * test_data_len, len(test_dataset)))
test_loaders[-1] = DataLoader(
dataset=Subset(test_dataset, remaining_test_indices),
batch_size=32, shuffle=False)
device = torch.device("mps")
clients = [Client(CNN(), train_loaders[i], test_loaders[i], device, i) for i in range(num_clients)]
server = Server(CNN(), clients)
server.train(rounds=5, epochs=1, lr=0.001)
server.evaluate()
有错误请指正 本人也是刚刚入门















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









