






一、雪花算法
当前项目中,需要给请求一个唯一标识,用来标识一个请求和响应的关联关系,要求请求的id必须唯一,且不能占用过大的空间,可用的方案如下:
1、自增id,单机的自增id不能解决不重复的问题,微服务情况下我们需要一个稳定的发号服务才能保证,但是这样做性能偏低。
2、uuid,将uuid作为唯一标识占用空间太大
3、雪花算法,最优解。接下来我们简单地介绍一下雪花算法,同时带着大家一起手写雪花算法。
#1、简介
雪花算法(snowflake)最早是twitter内部使用分布式环境下的唯一ID生成算法,他使用64位long类型的数据存储id,具体如下:
0 - 0000000000 0000000000 0000000000 0000000000 0 - 0000000000 - 000000000000
符号位 时间戳 机器码 序列号
最高位表示符号位,其中0代表整数,1代表负数,而id一般都是正数,所以最高位为0。当然知道了这个理论,我们甚至可以自由设定属于我们自己的雪花算法。
-
41位存储毫秒级时间戳,这个时间戳不是存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 开始时间戳) * 得到的值),这样我们可以存储一个相对更长的时间。
-
10位存储机器码,最多支持1024台机器,当并发量非常高,同时有多个请求在同一毫秒到达,可以根据机器码进行第二次生成。机器码可以根据实际需求进行二次划分,比如两个机房操作可以一个机房分配5位机器码。
-
12位存储序列号,当同一毫秒有多个请求访问到了同一台机器后,此时序列号就派上了用场,为这些请求进行第三次创建,最多每毫秒每台机器产生2的12次方也就是4096个id,满足了大部分场景的需求。
总的来说雪花算法有以下几个优点:
- 能满足高并发分布式系统环境下ID不重复
- 基于时间戳,可以保证基本有序递增
- 不依赖第三方的库或者中间件
- 生成效率极高
#2、手撸雪花
我们了解了雪花算法的的一些基础知识后就可以独立的编写一个属于自己的雪花算法了,可能并没有完全按照雪花算法的定义去实现,但是这正是程序的魅力,如机房不需要那么多,那就可以将时间戳的位数变的多一点,但事实上雪花算法是经过twitter等公司进行的最佳实践:
public class IdGenerator {
// 雪花算法 -- 世界上没有一个片雪花是一样的
// 机房号(数据中心) 5bit 32
// 机器号 5bit 32
// 时间戳(long 1970-1-1) 原本64位表示的时间,
// 现在由41位构成,(我们整个案例中使用了42位,实时上有点问题,会出现负数,所有要看我们的业务需求)
// 自由选择一个比较近的时间,比如我们公司成立的时间戳,项目启动的时间戳等
// 同一个机房的同一个机器号的同一个时间可以因为并发量很大需要多个id
// 序列号 12bit 5+5+42+12 = 64
// 起始时间戳
public static final long START_STAMP = DateUtil.get("2022-1-1").getTime();
//
public static final long DATA_CENTER_BIT = 5L;
public static final long MACHINE_BIT = 5L;
public static final long SEQUENCE_BIT = 12L;
// 最大值 Math.pow(2,5) -1
public static final long DATA_CENTER_MAX = ~(-1L << DATA_CENTER_BIT);
public static final long MACHINE_MAX = ~(-1L << MACHINE_BIT);
public static final long SEQUENCE_MAX = ~(-1L << SEQUENCE_BIT);
// 时间戳 (42) 机房号 (5) 机器号 (5) 序列号 (12)
// 101010101010101010101010101010101010101011 10101 10101 101011010101
public static final long TIMESTAMP_LEFT = DATA_CENTER_BIT + MACHINE_BIT + SEQUENCE_BIT;
public static final long DATA_CENTER_LEFT = MACHINE_BIT + SEQUENCE_BIT;
public static final long MACHINE_LEFT = SEQUENCE_BIT;
private long dataCenterId;
private long machineId;
private LongAdder sequenceId = new LongAdder();
// 时钟回拨的问题,我们需要去处理
private long lastTimeStamp = -1L;
public IdGenerator(long dataCenterId, long machineId) {
// 判断传世的参数是否合法
if(dataCenterId > DATA_CENTER_MAX || machineId > MACHINE_MAX){
throw new IllegalArgumentException("你传入的数据中心编号或机器号不合法.");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
public long getId(){
// 第一步:处理时间戳的问题
long currentTime = System.currentTimeMillis();
long timeStamp = currentTime - START_STAMP;
// 判断时钟回拨
if(timeStamp < lastTimeStamp){
throw new RuntimeException("您的服务器进行了时钟回调.");
}
// sequenceId需要做一些处理,如果是同一个时间节点,必须自增
if (timeStamp == lastTimeStamp){
sequenceId.increment();
if(sequenceId.sum() >= SEQUENCE_MAX){
timeStamp = getNextTimeStamp();
sequenceId.reset();
}
} else {
sequenceId.reset();
}
// 执行结束将时间戳赋值给lastTimeStamp
lastTimeStamp = timeStamp;
long sequence = sequenceId.sum();
return timeStamp << TIMESTAMP_LEFT | dataCenterId << DATA_CENTER_LEFT
| machineId << MACHINE_LEFT | sequence;
}
private long getNextTimeStamp() {
// 获取当前的时间戳
long current = System.currentTimeMillis() - START_STAMP;
// 如果一样就一直循环,直到下一个时间戳
while (current == lastTimeStamp){
current = System.currentTimeMillis() - START_STAMP;
}
return current;
}
public static void main(String[] args) {
IdGenerator idGenerator = new IdGenerator(1,2);
for (int i = 0; i < 1000; i++) {
new Thread(() -> System.out.println(idGenerator.getId())).start();
}
}
}
二、序列化
在需要传输的内容中封装了负载(payload),这是一个java对象,其实整个request就是一个java对象,我们需要将它转化为一个二进制字节流用于网络传输,这个过程就是序列化。
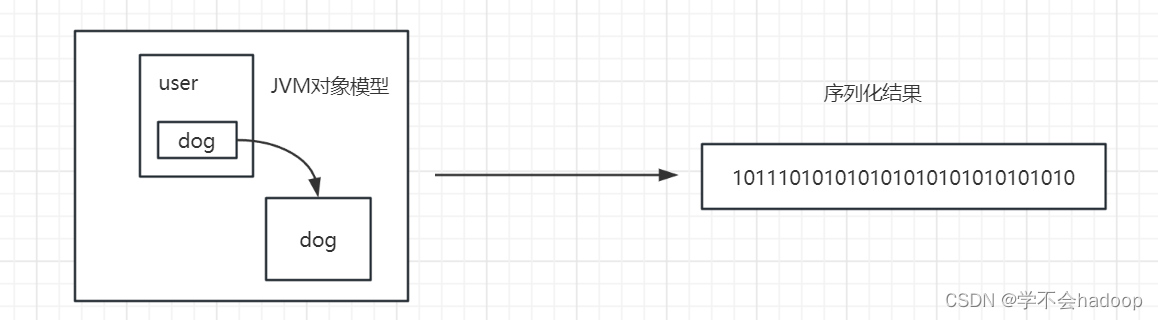
那么有人会想:jvm中的对象本来就是以二进制的形式存储的呀?
jvm中的对象是使用java的对象模型存储的,一个对象包含了对象头、成员变量的值、class指针、指向其他对象的引用等,这其中很多数据是不连续、而且这种模型只有java中可以被识别。如上图,这里会涉及很多的问题?
1、如何标记user属于什么类型?
2、user对象模型中的对象头等信息怎么处理?
3、user对象中指向其他对象的地址,以及dog对象怎么存储?即使存储了传递到其他的环境还能被识别吗?
所以,我们必须按照一套特定的逻辑对以上的问题进行解决,指定出一套序列化的方式,比如json将对象转化为可识别的字符序列来存储和传输,再比如很多常见的高性能的序列化方式hessian、protobuf等,都是提供的自己的序列化方案,以及现跨语言的相关实现。
#1、jdk的序列化方式
jdk的序列化方式就是使用IO进行序列化,他只支持不同的jvm之间的传输,并不能跨语言,代码如下:
public class JdkSerializer implements Serializer {
@Override
public byte[] serialize(Object object) {
if (object == null) {
return null;
}
try (
// 将流的定义写在这里会自动关闭,不需要在写finally
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream outputStream = new ObjectOutputStream(baos);
) {
outputStream.writeObject(object);
byte[] result = baos.toByteArray();
if(log.isDebugEnabled()){
log.debug("对象【{}】已经完成了序列化操作,序列化后的字节数为【{}】",object,result.length);
}
return result;
} catch (IOException e) {
log.error("序列化对象【{}】时放生异常.",object);
throw new SerializeException(e);
}
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> clazz) {
if(bytes == null || clazz == null){
return null;
}
try (
// 将流的定义写在这里会自动关闭,不需要在写finally
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
ObjectInputStream objectInputStream = new ObjectInputStream(bais);
) {
Object object = objectInputStream.readObject();
if(log.isDebugEnabled()){
log.debug("类【{}】已经完成了反序列化操作.",clazz);
}
return (T)object;
} catch (IOException | ClassNotFoundException e) {
log.error("反序列化对象【{}】时发生异常.",clazz);
throw new SerializeException(e);
}
}
}
2、hessian序列化
Hessian序列化是一种支持动态类型、跨语言、基于对象传输的网络协议,Java对象序列化的二进制流可以被其他语言(如,c++,python)。特性如下:
- 自描述序列化类型。不依赖外部描述文件或者接口定义,用一个字节表示常用的基础类型,极大缩短二进制流。
- 语言无关,支持脚本语言
- 协议简单,比Java原生序列化高效 相比hessian1,hessian2中增加了压缩编码,其序列化二进制流大小是Java序列化的50%,序列化耗时是Java序列化的30%,反序列化耗时是Java序列化的20%。
样例代码如下:
public class HessianSerializer implements Serializer {
@Override
public byte[] serialize(Object object) {
if (object == null) {
return null;
}
try (
// 将流的定义写在这里会自动关闭,不需要在写finally
ByteArrayOutputStream baos = new ByteArrayOutputStream();
) {
Hessian2Output hessian2Output = new Hessian2Output(baos);
hessian2Output.writeObject(object);
hessian2Output.flush();
byte[] result = baos.toByteArray();
if(log.isDebugEnabled()){
log.debug("对象【{}】已经完成了序列化操作,序列化后的字节数为【{}】",object,result.length);
}
return result;
} catch (IOException e) {
log.error("使用hessian进行序列化对象【{}】时发生异常.",object);
throw new SerializeException(e);
}
}
@Override
public <T> T deserialize(byte[] bytes, Class<T> clazz) {
if(bytes == null || clazz == null){
return null;
}
try (
// 将流的定义写在这里会自动关闭,不需要在写finally
ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
) {
Hessian2Input hessian2Input = new Hessian2Input(bais);
T t = (T) hessian2Input.readObject();
if(log.isDebugEnabled()){
log.debug("类【{}】已经使用hessian完成了反序列化操作.",clazz);
}
return t;
} catch (IOException e) {
log.error("使用hessian进行反序列化对象【{}】时发生异常.",clazz);
throw new SerializeException(e);
}
}
}
3、工厂模式的使用
为了让框架可以支持更多的序列化方式,我们设计了序列化器工厂,并对不同的序列化器进行了缓存,我们可以根据序列化的类型和编号轻松的获取一个序列化器。
public class SerializerFactory {
private final static ConcurrentHashMap<String, ObjectWrapper<Serializer>> SERIALIZER_CACHE = new ConcurrentHashMap<>(8);
private final static ConcurrentHashMap<Byte, ObjectWrapper<Serializer>> SERIALIZER_CACHE_CODE = new ConcurrentHashMap<>(8);
static {
ObjectWrapper<Serializer> jdk = new ObjectWrapper<>((byte) 1, "jdk", new JdkSerializer());
ObjectWrapper<Serializer> json = new ObjectWrapper<>((byte) 2, "json", new JsonSerializer());
ObjectWrapper<Serializer> hessian = new ObjectWrapper<>((byte) 3, "hessian", new HessianSerializer());
SERIALIZER_CACHE.put("jdk",jdk);
SERIALIZER_CACHE.put("json",json);
SERIALIZER_CACHE.put("hessian",hessian);
SERIALIZER_CACHE_CODE.put((byte) 1, jdk);
SERIALIZER_CACHE_CODE.put((byte) 2, json);
SERIALIZER_CACHE_CODE.put((byte) 3, hessian);
}
/**
* 使用工厂方法获取一个SerializerWrapper
* @param serializeType 序列化的类型
* @return SerializerWrapper
*/
public static ObjectWrapper<Serializer> getSerializer(String serializeType) {
ObjectWrapper<Serializer> serializerWrapper = SERIALIZER_CACHE.get(serializeType);
if(serializerWrapper == null){
log.error("未找到您配置的【{}】序列化工具,默认选用jdk的序列化方式。",serializeType);
return SERIALIZER_CACHE.get("jdk");
}
return SERIALIZER_CACHE.get(serializeType);
}
public static ObjectWrapper<Serializer> getSerializer(Byte serializeCode) {
ObjectWrapper<Serializer> serializerWrapper = SERIALIZER_CACHE_CODE.get(serializeCode);
if(serializerWrapper == null){
log.error("未找到您配置的【{}】序列化工具,默认选用jdk的序列化方式。",serializeCode);
return SERIALIZER_CACHE.get("jdk");
}
return SERIALIZER_CACHE_CODE.get(serializeCode);
}
/**
* 新增一个新的序列化器
* @param serializerObjectWrapper 序列化器的包装
*/
public static void addSerializer(ObjectWrapper<Serializer> serializerObjectWrapper){
SERIALIZER_CACHE.put(serializerObjectWrapper.getName(),serializerObjectWrapper);
SERIALIZER_CACHE_CODE.put(serializerObjectWrapper.getCode(),serializerObjectWrapper);
}
}















 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









