










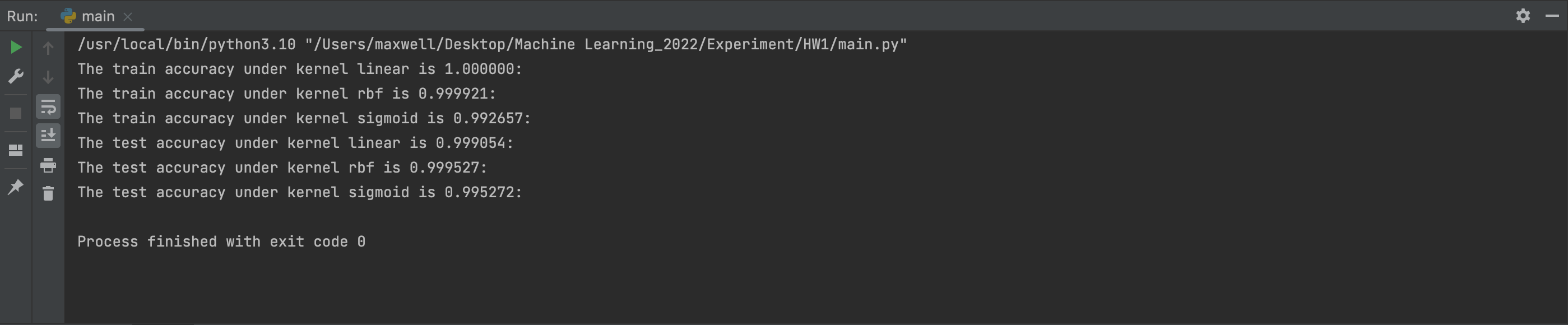
2022Fall 机器学习
1. 实验要求
- 考虑两种不同的核函数:i) 线性核函数; ii) ⾼斯核函数
- 可以直接调⽤现成 SVM 软件包来实现
- ⼿动实现采⽤ hinge loss 和 cross-entropy loss 的线性分类模型,并⽐较它们的优劣
2. 实验内容
1) SVM 模型的⼀般理论
2) 采⽤不同核函数的模型和性能⽐较及分析
3) 采⽤ hinge loss 的线性分类模型和 SVM 模型之间的关系
4) 采⽤ hinge loss 线性分类模型和 cross-entropy loss 线性分类模型⽐较
5) 训练过程(包括初始化⽅法、超参数参数选择、⽤到的训练技巧等)
6) 实验结果、分析及讨论
实验数据:
-
数据集: 手写体数据集
-
数据描述:
-
第 1 行是表头,介绍了文件中各列表示的信息;其余的每一行对应一个样本,各样本包含 785列。
-
第 1 列是标签,值为 0 或 1;其余 784 列是手写体的像素值,值的区间是 0 到 255。
-
3. 实验过程
1) SVM 模型的⼀般理论
支持向量机(Support Vector Machine)是一种按监督学习方式对二元数据进行分类的广义线性分类器,它的学习目标是要在n维的特征空中找到一个最大边距的超平面对数据进行分类,该超平面可以将求解最优参数的原问题转化为一个求解凸二次规划的对偶问题;
在训练样本的特征空间中,根据其是否线性可分,引申出了两种侧重点不同的SVM模型,一种是硬间隔SVM(Hard Margin),另一种是软间隔SVM(Soft Margin),前者假定了样本在其特征空间中是线性可分的(也就是能找到一个超平面,可以将不同类别的样本划分开),后者则假定了样本在其特征空间中线性不可分,其引入了松弛变量(Slack Variable) ξ i ≥ 0 \xi_i \geq 0 ξi≥0 (表示样本偏离支持向量的距离)允许SVM在一些样本上出错,但会得到相应的惩罚 ξ i \xi_i ξi ;这里提到的Margin是指与分类的超平面距离最近的样本点(支持向量)之间的距离,为了让模型能够在Unseen Data上表现尽可能地好,因此需要让这个Margin尽可能地大;
在硬间隔SVM中,为了使得间隔最大,我们要找到满足KaTeX parse error: Undefined control sequence: \norm at position 38: …b} \frac{1}{2} \̲n̲o̲r̲m̲{\bold{w}}^2的最优的 w \bold{w} w和b,使得 y ( l ) ( w T x + b ) ≥ 1 , f o r l = 1 , 2 , . . . , N y^{(l)}(\bold{w}^T\bold{x}+b)\geq1 ,\ for \ l=1,2,...,N y(l)(wTx+b)≥1, for l=1,2,...,N 成立;而在软间隔SVM中,为了使得间隔最大,而又要考虑松弛变量,我们要找到满足KaTeX parse error: Undefined control sequence: \norm at position 38: …b} \frac{1}{2} \̲n̲o̲r̲m̲{\bold{w}}^2 + …(这里的C是惩罚系数,用来控制惩罚力度)使得 y ( l ) ( w T x + b ) ≥ 1 − ξ n , f o r l = 1 , 2 , . . . , N y^{(l)}(\bold{w}^T\bold{x}+b)\geq1-\xi_n ,\ for \ l=1,2,...,N y(l)(wTx+b)≥1−ξn, for l=1,2,...,N 成立;
总之,在线性可分时,在原空间寻找两类样本的最优分类超平面。在线性不可分时,加入松弛变量并通过使用非线性映射(核函数)将低维度输入空间的样本映射到高维度空间使其变为线性可分,这样就可以在该特征空间中寻找最优分类超平面。SVM 的特性是 “支持向量” , 即线性超平面只由少数 “支持向量” 所决定。
2) 采⽤不同核函数的模型和性能⽐较及分析
在本次实验中,采用skearn包中提供的SVM模型;
- 线性核函数
相关代码:
SVM Train
def svm_train(path, kernel):
classifiers = []
trainset = pandas.read_csv(path)
label = trainset.values[:, 0]
data = trainset.values[:, 1:]
for k in kernel:
clf = svm.SVC(kernel='linear').fit(data, label)
train_score = clf.score(data, label)
print("The train accuracy under kernel %s is %f: " % (clf.kernel, train_score))
classifiers.append(clf)
return classifiers
这里使用了sklearn svm中的SVC模型来进行训练,采用线性核函数,并且调用fit来计算出超平面,且所有相关属性都保存在了分类器 clf中;
实验结果:

从训练和测试的准确度来看,分别取得了1和0.999054的分数;
线性核函数的时候在训练集上的准确度达到了1,但是在测试集上的表现却相对来说没那么好,因此估计在使用线性核函数的时候,有可能出现了过拟合的现象。
故考虑对惩罚系数C进行调整,当C比较小时,意味我们不想理那些离群点,会选择较少的样本来做支持向量,最终的支持向量和超平面的模型也会简单:
def svm_train(path, kernel):
classifiers = []
trainset = pandas.read_csv(path)
label = trainset.values[:, 0]
data = trainset.values[:, 1:]
for k in kernel:
clf = svm.SVC(kernel=k, C=0.0000001).fit(data, label)
train_score = clf.score(data, label)
print("The train accuracy under kernel %s is %f: " % (clf.kernel, train_score))
classifiers.append(clf)
return classifiers
最后发现,在C为0.0000001的时候,模型在测试集上表现得比之前更好,达到了0.999527的分数

这有可能是因为SVM在训练的过程中,超平面的划分对训练集中的数据的要求没有那么大了,它会尽可能地最大化Margin,而不是尽可能地让所有数据都能够被区分开(而牺牲了Margin的最大化,相当于牺牲了Generalization),因此它会在测试集上表现得比之前C=1的时候要好。
- ⾼斯核函数
SVM Train
def svm_train(path, kernel):
classifiers = []
trainset = pandas.read_csv(path)
label = trainset.values[:, 0]
data = trainset.values[:, 1:]
for k in kernel:
clf = svm.SVC(kernel='rbf').fit(data, label)
train_score = clf.score(data, label)
print("The train accuracy under kernel %s is %f: " % (clf.kernel, train_score))
classifiers.append(clf)
return classifiers
这部分代码与上面类似,使用了sklearn svm中的SVC模型来进行训练,这里采用高斯核函数;
实验结果:
在默认参数下取得的准确度如下:

在训练集和测试集上,分别取得了0.999921和0.999527的分数;
- 在不同kernel下SVM的表现:
综上我们发现:
SVM模型在核函数为高斯核函数的时候,在测试集上表现最好(0.999921),而使用线性核函数的时候在训练集上的准确度达到了1,但是在测试集上的表现却相对来说没那么好,因此估计在使用线性核函数的时候,有可能出现了过拟合的现象,最后通过调整惩罚系数C,让SVM尽可能地最大化Margin,而不是关注于将训练集中的数据完美地区分开。
参数调整:
(1)网格搜索
model = svm.SVC()
params = [
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]},
{'kernel': ['poly'], 'C': [1, 10], 'degree': [2, 3]},
{'kernel': ['rbf'], 'C': [1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001]}]
model = GridSearchCV(estimator=model, param_grid=params, cv=5, n_jobs=8)
model.fit(data, label)
print("模型的最优参数:", model.best_params_)
print("最优模型分数:", model.best_score_)
print("最优模型对象:", model.best_estimator_)
使用了8个进程跑,速度十分慢;

最后得到了:

使用搜索出来的参数进行测试:
def svm_train(path, kernel):
classifiers = []
trainset = pandas.read_csv(path)
label = trainset.values[:, 0]
data = trainset.values[:, 1:]
for k in kernel:
# clf = svm.SVC(kernel=k).fit(data, label)
clf = svm.SVC(kernel='poly', degree=2).fit(data, label)
train_score = clf.score(data, label)
print("The train accuracy under kernel %s is %f: " % (clf.kernel, train_score))
classifiers.append(clf)
return classifiers
得到的准确度如下

反而比高斯核函数在测试集上的准确率要来得低
3) 采⽤ hinge loss 的线性分类模型和 SVM 模型之间的关系
Hinge Loss的公式为: L ( z ) = m a x ( 0 , 1 − z ) L(z) = max(0, 1-z) L(z)=max(0,1−z) z在这里为 y y ^ y \hat{y} yy^, y ^ = x w \hat{y}=\bold{xw} y^=xw指的是分类结果,也就是说,如果样本被正确分类,那么它的Hinge Loss为0,否则就是 1 − y y ^ 1- y\hat{y} 1−yy^
对Hinge Loss求梯度可得:
KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲(L(\bold{w}))}{…
Hinge Loss的图像如下:

对采用Hinge Loss的线性分类器进行训练,使用的参数为:
num_epochs = 360
learning_rate = 0.00001
需要注意的是,在原数据集中标签采用的都是0和1,但是在hinge loss中所关注的标签为-1和1,所以在使用Hinge Loss之前需要将标签转换为-1和1两类
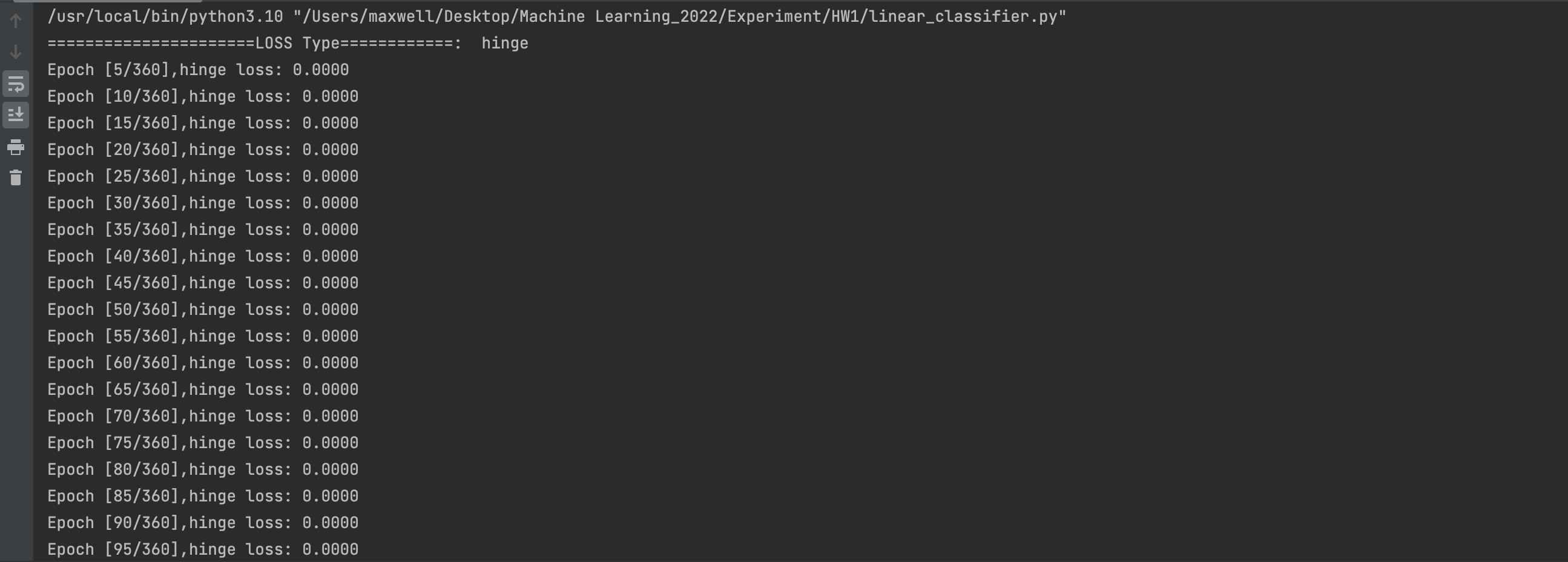
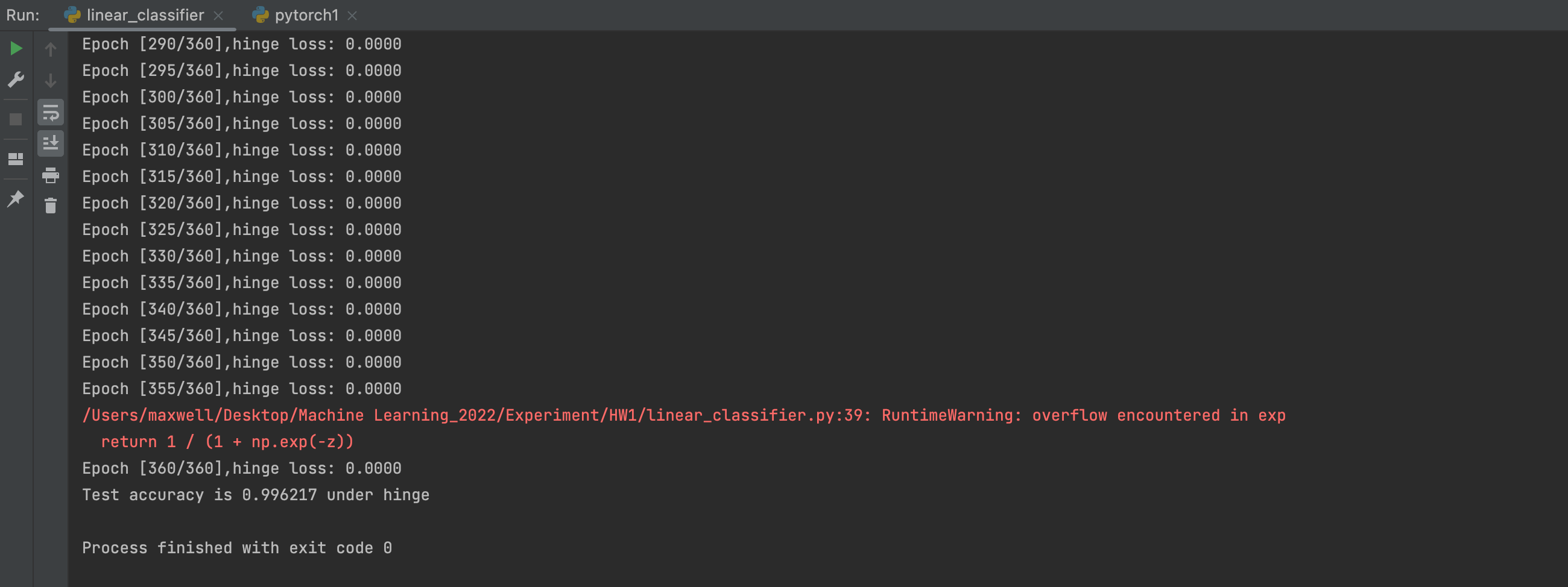
使用Hinge Loss的线性分类器所得到的准确率约为0.996217
- 它们两者之间的关系:
在SVM中,软间隔SVM所使用的松弛变量就是hinge loss,即KaTeX parse error: Undefined control sequence: \norm at position 38: …b} \frac{1}{2} \̲n̲o̲r̲m̲{\bold{w}}^2 + …,其中 ξ n \xi_n ξn就是 L ( z ) = m a x ( 0 , 1 − y i y i ^ ) L(z) = max(0, 1-y_i\hat{y_i}) L(z)=max(0,1−yiyi^)
它用来表示样本偏离支持向量的距离,允许SVM在一些样本上出错,而在这里,我们则是求Hinge loss的梯度,利用梯度下降的方法逐步地来更新参数,我认为,在SVM中,由于其特性,其超平面的确定只由支持向量来决定(和分类最相关的少数点,考虑局部),其余大多数样本都不需保留,而采⽤ hinge loss 的线性分类模型则相反,它考虑了所有训练样本(考虑全局)。
4)采⽤ hinge loss 线性分类模型和 cross-entropy loss 线性分类模型⽐较
Cross-entropy Loss的公式为: L ( w ) = − y l o g ( σ ( x w ) ) − ( 1 − y ) l o g ( 1 − σ ( x w ) ) L(\bold{w}) = -ylog(\sigma(\bold{xw}))-(1-y)log(1-\sigma(\bold{xw})) L(w)=−ylog(σ(xw))−(1−y)log(1−σ(xw))
其梯度为:

现采用线性分类模型:
f ( x ) = σ ( x w + b ) f(\bold{x}) = \sigma(\bold{xw}+b) f(x)=σ(xw+b)
对分别采用Hinge loss和Cross Entropy Loss的线性分类器进行训练,使用的参数都为:
num_epochs = 360
learning_rate = 0.00001
这里学习率使用0.0001的原因是在cross-entropy loss 线性分类模型中,如果设置太大的学习率,在求解loss的时候因为梯度变化得太快,极容易出现上溢,因此这里调低了学习率,减小梯度变化的速度。
而对于W和B,采用了如下的方式来初始化:
W = np.random.normal(0, 0.01 ** 2, (in_feature,)) # Gaussian Distribution (一维数组,有1行,in_feature列)
B = 0
这里的W使用被广泛认为不错的初始化值即:均值为0,方差为0.01^2的高斯分布。
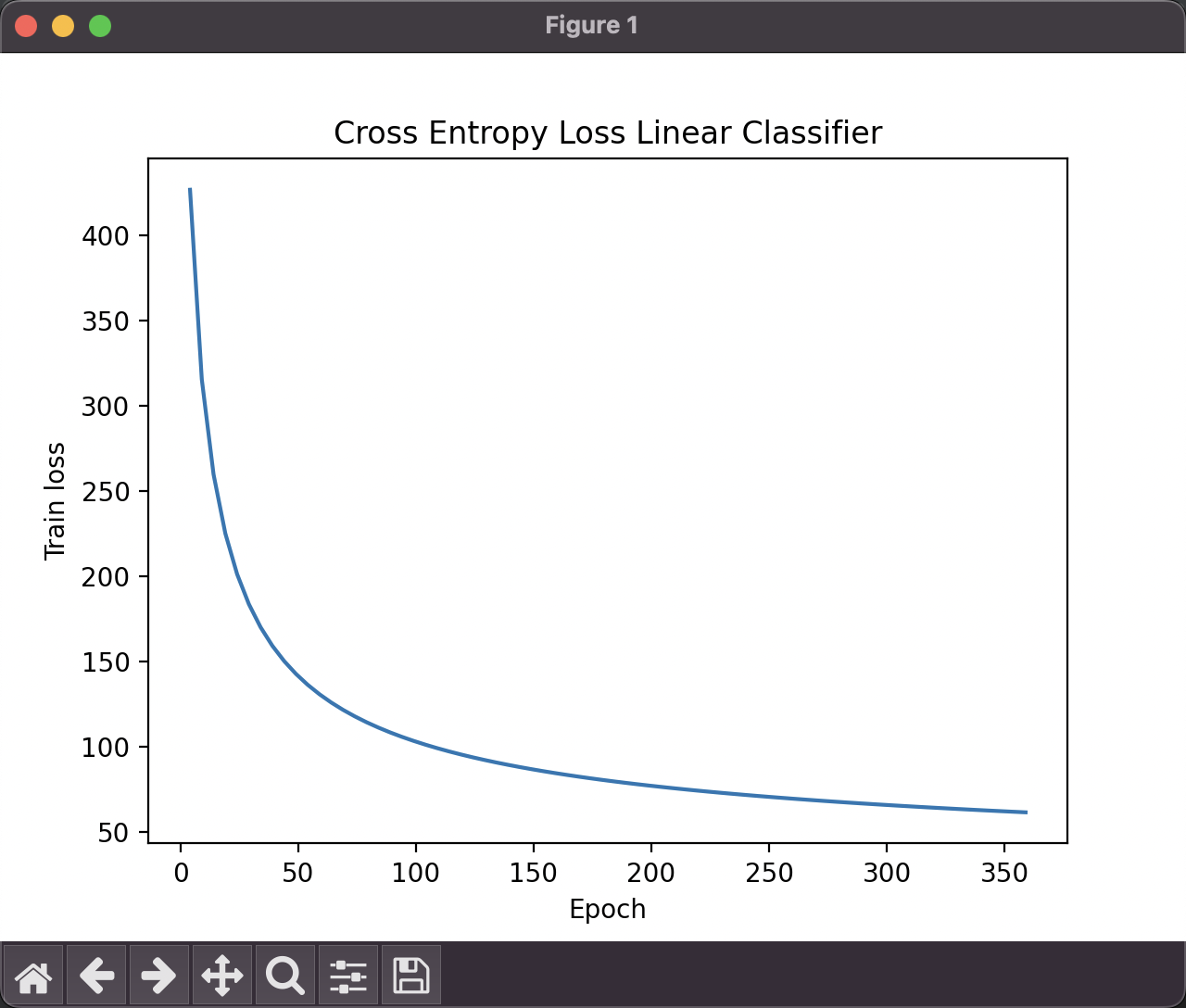
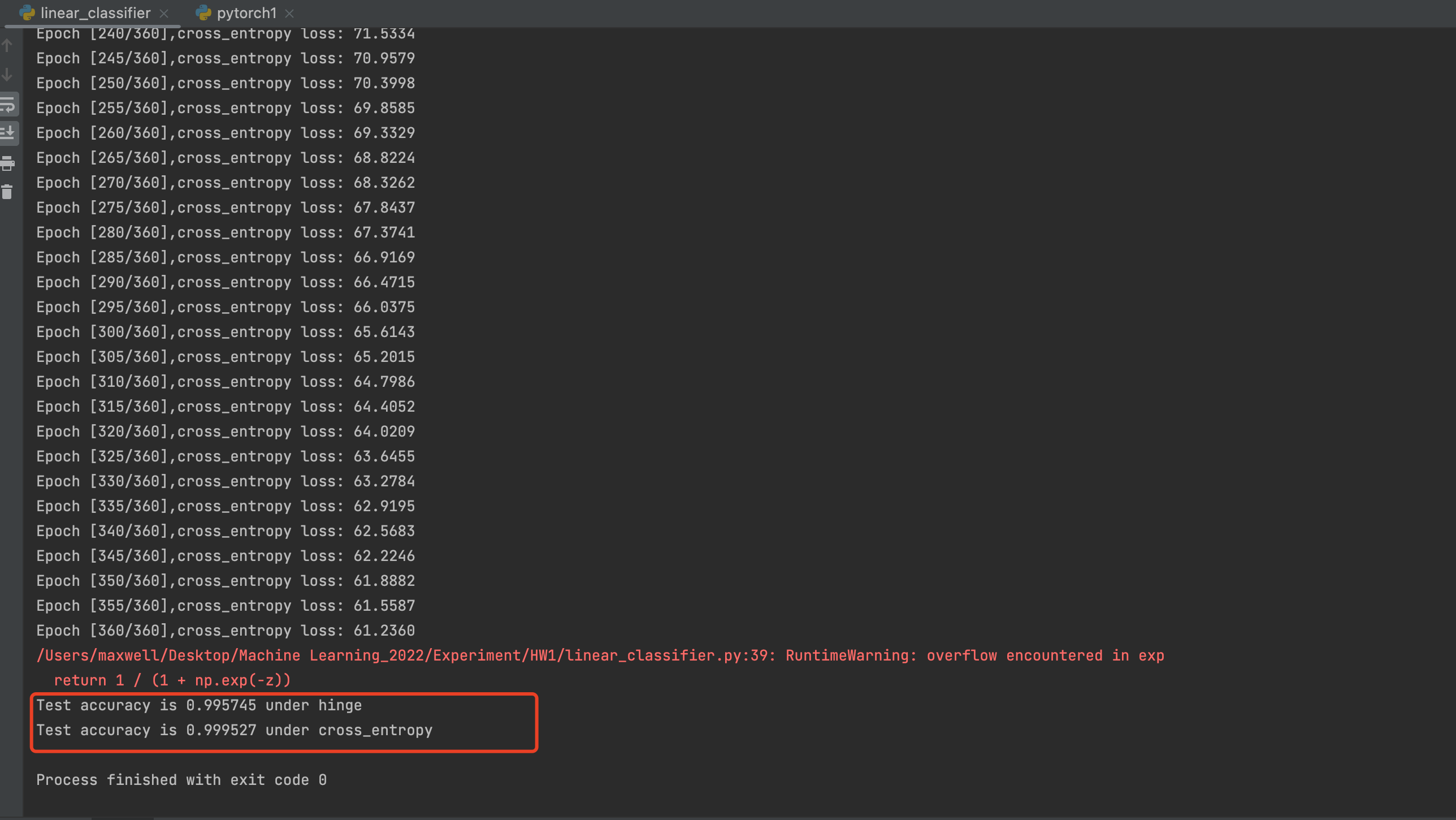
使用Hinge Loss的线性分类器所得到的准确率约为0.995745
使用Cross Entropy Loss的线性分类器所得到的准确率约为0.999527
- 实验分析:
- 在同一参数下,我们发现,使用Cross Entropy Loss的线性分类器的准确率要相对高一些;
- Hinge Loss会相对来说更关注那些被错误分类的样本,对于那些正确分类的样本的损失为0,而错误分类的样本,其损失呈线性增长;对于Cross Entropy Loss来说,我们可以从它的图像可以知道,它是一个凸函数,只存在一个最优点,没有局部最优解,便于优化。
4. 实验总结
在本次实验中,我总结了SVM的基本理论,并且针对SVM的不同核函数(包括线性核函数和高斯核函数)针对其性能进行⽐较和分析,之后又引入了线性分类模型(分别采用hinge loss 和cross-entropy loss)对不同的Loss的性能进行比较和分析。
综合来说,从我的实验结果来看,对于该数据集,在测试集上分类性能最好的是采用高斯核函数的SVM,达到了0.999921的分数,而在于两种线性分类器之间来比较的话,使用cross-entropy loss的线性分类模型性能最好,达到了0.999527的分数,其在较高的学习率时,容易使得梯度上溢,通过降低学习率后,能够有效地解决该问题;在采用线性核函数的SVM中,我发现了它在训练集上过拟合的问题,通过调整惩罚系数后,其在测试集上的表现有所提升。
这次实验给我提供了一次实践的机会,让我能够将学习到的知识运用到现实当中,我对SVM的理解又更进了一步,对SVM以及其他线性分类器的区别,以及不同损失函数的选择,超参数的调整都有了更深刻的理解。















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









