







Pytorch 学习笔记03
TensorBoard使用
TensorBoard是一个用于可视化和调试深度学习模型的工具。帮助开发者更好地理解、优化和监控他们的模型训练过程。通过使用TensorBoard,开发者可以更直观地了解模型的训练过程和性能,从而更好地进行调试和优化。
(用来画图)
SummaryWriter使用
SummaryWriter为TensorBoard下的一个类。
初始化SummaryWriter类对象时,传入的第一个参数为事件文件保存的文件夹
writer = SummaryWriter("logs")
如何使用该文件夹下的事件文件
我目前的理解:这个文件夹下的事件文件,打开后都是对应的图片
打开方法:
在项目目录下打开命令行,输入tensorboard --logdir=logs --port=6007
logdir = 事件文件所在文件夹名
port 为自定义端口,避免在服务器上多个用户使用同一端口

add_scalar()()函数使用
Args:
tag (string): Data identifier 图像title
scalar_value (float or string/blobname): Value to save 相当于坐标系y轴
global_step (int): Global step value to record 相当于坐标系x轴
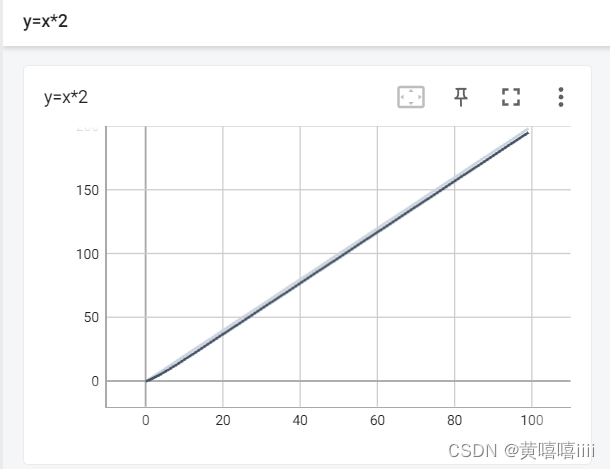
第一个参数为图像title,第二个参数为y轴,第三个参数为x轴
例: 生成曲线y=2x ,数据为0至100
代码:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# y=2x
for i in range(100):
writer.add_scalar("y=x*2",2*i,i)
writer.close()
通过命令行输入命令tensorboard --logdir=logs --port=6007 打开
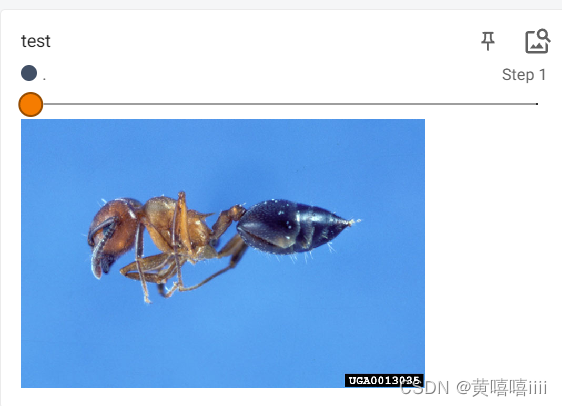
add_image()使用
常用来观察训练结果
Args:
tag (string): Data identifier 图像title
img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data 图片数据,需要为括号里的三种类型
global_step (int): Global step value to record 训练步骤,表示训练的第几步
用PIL包中的Image类进行图片读取,图片的类型为常用格式,不符合参数类型,所以利用numpy.array(),对PIL图片进行转换
image_path = "dataset/train/ants_image/5650366_e22b7e1065.jpg" # 图片路径
img_PIL = Image.open(image_path) # 用PIL的Image打开图片
img_array = np.array(img_PIL) # 将图片转为numpy型
一般情况下,图片的shape默认为:math:(3, H, W)``,参数dataformats为默认值(不用传参)。如果图片的shape为:math:(1, H, W), :math:(H, W), :math:(H, W, 3)类型,则需要设置参数dataformats为CHW \HWC\HW
H为高,W为宽,C为通道数

该图片为HWC格式,所以需要指定参数dataformats为HWC
代码:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "dataset/train/ants_image/5650366_e22b7e1065.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(type(img_array))
print(img_array.shape)
writer.add_image("test", img_array, 2, dataformats='HWC')
writer.close()
Transforms使用
在PyTorch的torchvision库中,transforms模块提供了一系列用于图像预处理和数据增强的转换操作。transforms模块可以用于加载、预处理和增强图像数据集,通常用于深度学习中的计算机视觉任务。
transforms模块包含了各种常用的图像转换操作,例如:
- Resizing(调整图像大小):可以将图像调整为指定大小。
- Cropping(裁剪图像):可以从图像中裁剪出感兴趣的区域。
- Flipping(翻转图像):可以水平或垂直翻转图像。
- Rotation(旋转图像):可以按指定角度对图像进行旋转。
- Normalization(标准化图像):可以对图像进行像素值的标准化处理。
- ToTensor(转换为张量):可以将图像转换为PyTorch张量的格式。
目前的理解: 对传入的图片进行改造。
Transforms模块中有很多类,这些类的功能都不同。每个类都相当于一个工具,可以对图片进行改造。
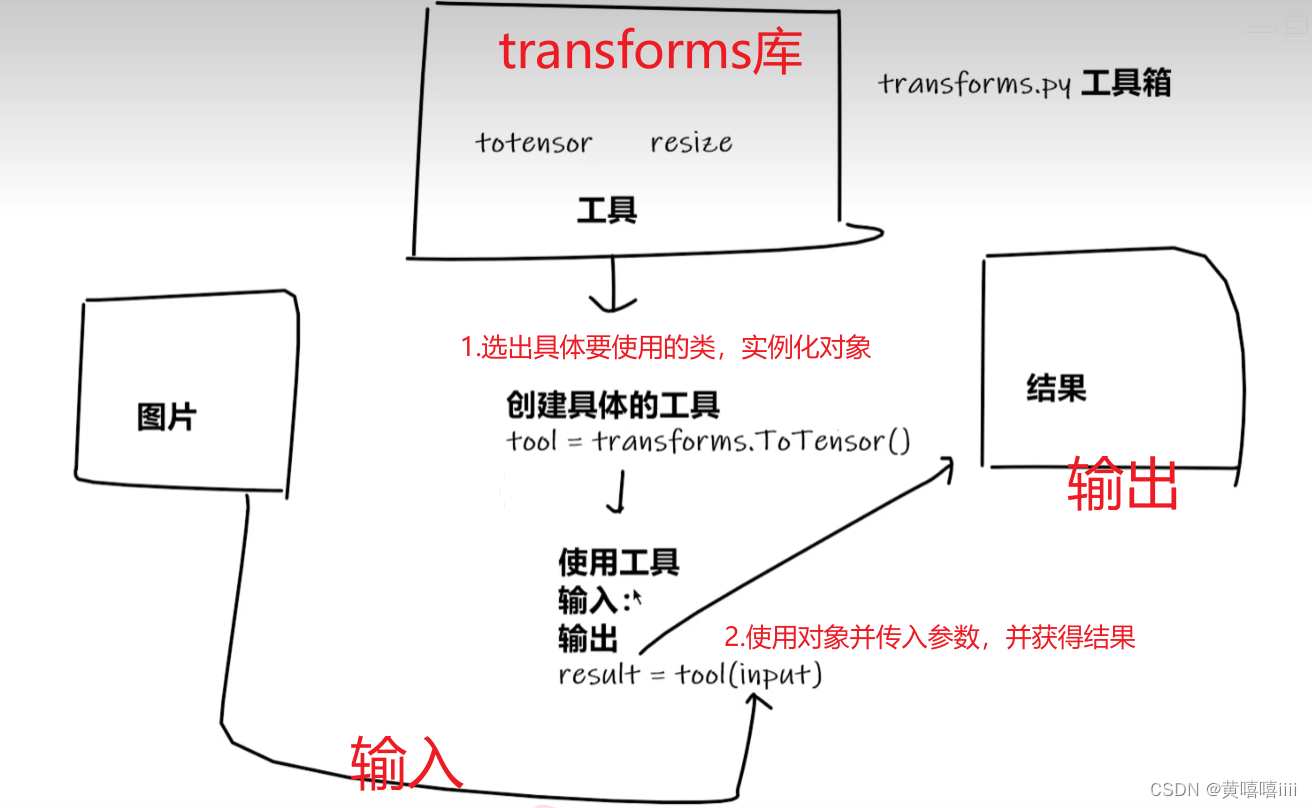
Transforms用法
- 从Transforms库中选取某个要使用到的类,对它进行实例化,生成一个对象。
- 不同的类传入的参数不同,根据具体情况传入相应参数即可
为什么用Tensor数据类型
Tensor数据类型封装了神经网络一些理论的数据类型。
-
支持并行计算:张量数据类型是为高效的并行计算而设计的。深度学习框架如PyTorch和TensorFlow都是基于张量计算的,可以利用图形处理单元(GPU)等硬件加速器进行并行计算,从而提高计算效率。
-
支持自动求导:深度学习中的反向传播算法需要计算梯度,而张量数据类型可以自动跟踪计算过程,并提供自动求导的功能。这使得在神经网络训练过程中能够方便地计算梯度并更新模型参数。
-
适用于多维数据:张量数据类型能够方便地表示和处理多维数据,如图像、音频、文本等。在计算机视觉任务中,通常使用多维张量表示图像数据,其中每个维度对应于图像的通道、高度和宽度。
-
集成深度学习框架:深度学习框架如PyTorch和TensorFlow提供了丰富的张量操作函数和工具,使得在处理和操作张量数据时更加便捷。这些框架还提供了各种内置的优化算法、模型结构和训练工具,可以直接应用于张量数据类型。
读取图片的方式
1. PIL
用PIL读取的图片类型为常用类型
from PIL import Image
img = Image.open(img_path)
2.oepncv
用opencv读取的图片类型为numpy型
import cv2
img = cv2.imread(img_path)
常见的Transforms
ToTensor类
作用:将PIL.Image或Numpy型图片转为Tensor型
用法:
from torchvision import transforms
tensor_trans = transforms.ToTensor() # 声明一个ToTensor对象
trans_img = tensor_trans(img) #将读取的图片作为参数传入,生成Tensor型图片
Normalize类
作用:使用平均值和标准偏差归一化张量图像
用法:
trans_norm = transforms.Normalize([2,0.5,0.5],[3,0.5,5]) # 第一个参数为平均值,第二参数为标准偏差
img_norm = trans_norm(trans_img) # 参数与返回值都为tensor类型图片
Resize类
作用:对图片尺寸进行缩放
用法:
trans_reize = transforms.Resize((512,512)) # 传入的参数为缩放的尺寸,可以是一个序列,也可以是一个整型 If size is a sequence like(h, w), output size will be matched to this. If size is an int,smaller edge of the image will be matched to this number.
img_resize = trans_reize(img) # 返回参数与传入参数的数据类型一致;传入参数可以为PIL.Image或tensor类型的图片
Compose类
Compose()中的参数为一个列表。Python中,列表的表示形式为[数据1, 数据2, …]。在Compose中,数据需要是transforms类型,所以得到,Compose([transforms参数1, transforms参数2, …])。
作用:将一系列transforms操作结合起来。
用法:
trans_reize2 = transforms.Resize(512) # Resize对象
totensor = transforms.ToTensor() # ToTensor对象
trans_compose = transforms.Compose([trans_reize2,totensor]) # Compose对象,传入参数为列表,列表中数据为transforms库的类对象
compose_img = trans_compose(img) # 传入图片,图片的数据类型应该与列表中第一个参数需要的数据类型一致
总结
- 关注输入和输出,多看官方文档
- 关注方法需要什么参数
TorchVision中数据集的使用
- 进入Pytorch官网,在导航栏Doc中选择Torchvision,查看官方文档。
- 左侧选择Datasets,然后下拉就可以找到各种数据集的文档
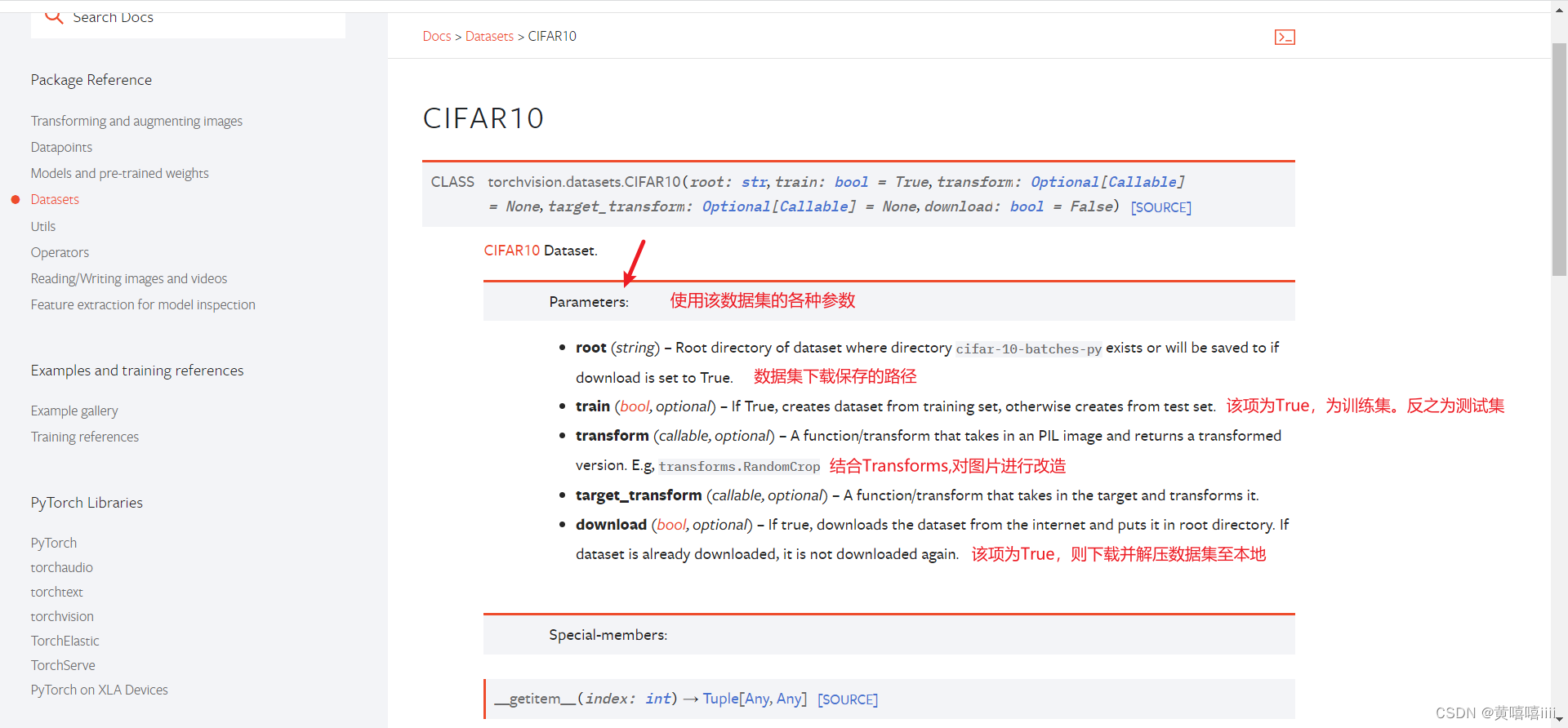
- 以 CIFAR10为例
代码:
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 设置transforms
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor() #将数据集中的PIL格式图片转为Tensor类型
])
# 训练集
train_set = torchvision.datasets.CIFAR10("./dataset/CIFAR10", transform=dataset_transform, train=True, download=True)
# 数据集
test_set = torchvision.datasets.CIFAR10("./dataset/CIFAR10", transform=dataset_transform, train=False, download=True)
# print(test_set[0])
# print(test_set.classes)
# img, target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])
writer = SummaryWriter("logs") # 使用tensorboard展示
for i in range(10): # 展示测试集中前十个数据
img, target = test_set[i]
writer.add_image("CIFAR10_testDataset",img,i)
writer.close()
注意:如果数据集下载很慢,可以复制输出的链接进行下载,再放至于root设置的文件夹下。
总结
- 多看官方文档,查看如何设置参数
















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









