







Pytorch 学习笔记02
Dataset、Dataloader的学习
Python学习中两大法宝函数
dir()
用法:dir(package名字)
作用:用来查看一个包或者包下一个模块中包含了什么东西
help()
用法:help(函数名)
作用:用来查看一个函数如何使用
Pytorch加载数据初认识
Dataset
提供一种方式去获取数据及其label
主要实现以下两个功能:

Dataset代码实战
要实现一个Dataset,需要自定义一个Mydata类(类的名字自定义),该类需要继承 torch.utils.data 下的 Dataset 类。
并根据数据集的情况重载Dataset 类下的函数,如:
def __init__(self) 为后续函数如 __getitem__或len函数初始化所需要的变量
def __getitem__(self, index) 重写这个函数等于重载运算符[],通过这个函数返回数据及对应label
def __len__(self) 重载len函数,返回数据集的大小
数据集介绍
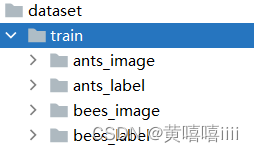
使用的ants和bees的数据集,训练数据集下有4个文件夹,分别为ants_image、ants_label、bees_image、bees_label。
每个图片对应的label存在于与该文件同名的txt文件中。
init()函数
根据该数据集的结构,该函数需要三个参数
:param root_dir: 数据集路径(不包括上级目录)
:param img_dir: 图片上级目录名称
:param label_dir: label上级目录名称
注意:在类的__init__函数中用self.变量名的形式初始化了的变量,为全局变量,可以在该类的其他函数中通过self.变量名的形式使用
- 将传入的参数声明为类成员变量
- 拼接图片所在文件目录的路径
- 将所有的数据(图片文件名)通过函数
os.listdir(self.path)组成一个list列表
getitem()函数
重载该函数实际为重载运算符[],该函数会返回图片及图片对应的label。
:param index: 数据的索引
:return: 图片,标签
- 根据index索引,从图片文件名列表中获取图片文件名
- 拼接图片所在目录路径和图片文件名,用PIL的Image类 获得图片
- 拼接label所在目录路径。
- 返回获得的图片和对应label
len()
重载该函数,以获得数据集的大小
Mydata类用法
声明好初始化一个Mydata类所需要传入的参数,就可以定义一个Mydata类的对象。
因为声明了__init__函数,所以声明对象传入参数时会自动调用进行初始化。
ants_dataset = Mydata(参数) # ants_dataset为自定义对象名
img, label = ants_dataset[0]
因为重载了__getitem__()函数,所以通过ants_dataset[index]的方式来调用该函数,进而获取相应index下的图片及其label
注意:这个实例里的图片是用PIL包下的Image类打开的
代码
from torch.utils.data import Dataset
from PIL import Image
import os
"""
os.path.join(路径,路径,路径,路径) 用来拼接路径
os.listdir(路径) 将当前路径下的数据集变成list
"""
class MyData(Dataset):
def __init__(self, root_dir, img_dir, label_dir):
"""
为后续函数如 __getitem__或len函数初始化所需要的变量
:param root_dir: 数据集路径(不包括上级目录)
:param img_dir: 图片上级目录名称
:param label_dir: label上级目录名称
"""
# 在类的__init__函数中用self.变量名的形式初始化了的变量,为全局变量,可以在该类的其他函数中通过self使用
self.root_dir = root_dir
self.label_dir = label_dir
self.img_dir = img_dir
self.path = os.path.join(self.root_dir,self.img_dir) # 拼接图片所在文件夹目录路径
self.img_path_list = os.listdir(self.path) # 获取图片名称列表
def __getitem__(self, index):
"""
重写这个函数等于重载运算符[],通过这个函数返回数据及对应label
:param index: 数据的索引
:return: 图片,标签
"""
img_name = self.img_path_list[index] # 根据index,从图片名称列表中获取图片
img_item_path = os.path.join(self.root_dir, self.img_dir, img_name) # 拼接图片的路径
img = Image.open(img_item_path) # 用PIL的Image类 获得图片
label_item_path = os.path.join(self.root_dir, self.label_dir, img_name.split('.')[0]+'.txt')
# 拼接label的路径,每个图片的label保存在同名txt文件中
with open(label_item_path,'r') as f:
label = f.read()
return img,label
def __len__(self):
"""
重载len函数,返回数据集的大小
:return:
"""
return len(self.img_path_list)
root_dir = "dataset/train"
ants_label_dir = "ants_label"
ants_image_dir = "ants_image"
bees_label_dir = "bees_label"
bees_image_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)
train_data = ants_dataset + bees_dataset
img, label = ants_dataset[0]
img.show()
print(label)
Dataloader
在PyTorch中,torch.utils.data.DataLoader是一个用于批量加载数据的实用程序类。它可以用于将数据集对象转换为可迭代的数据加载器,以便在训练或测试模型时方便地获取数据。
DataLoader接受一个Dataset对象作为输入,该对象表示数据集。数据集可以是自定义的,也可以是PyTorch提供的内置数据集,如torchvision.datasets中的数据集。Dataset对象提供了数据集的访问方法和样本的获取方式。
DataLoader将数据集分割成小批量(batch),并在每个批量中提供数据。它还可以并行地加载数据,以提高数据加载的效率。可以指定批量大小(batch size)、是否随机洗牌数据、并行加载的线程数等参数。
主要参数
Parameters:
dataset (Dataset) – dataset from which to load the data. #传入的数据集
batch_size (int, optional) – how many samples per batch to load (default: 1). # 每一批数据的大小
shuffle (bool, optional) – set to True to have the data reshuffled at every epoch (default: False). #每次遍历整个数据集时是否重新打乱数据
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0) # 数据加载时的线程数
drop_last (bool, optional) – set to True to drop the last incomplete batch, if the dataset size is not divisible by the batch size. If False and the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default: False) # 是否舍弃最后一批不完整的数据
如何理解深度学习中的epoch
在深度学习中,"epoch"是指完整遍历整个训练数据集的次数。在训练神经网络时,数据通常会被分成小批量(batch)进行处理,每次处理一个批量的数据进行前向传播、计算损失和反向传播更新参数。
案例
读取pytorch官方的数据集CIFAR10。
代码:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 设置transforms,数据转换
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor() #将数据集中的PIL格式图片转为Tensor类型
])
# 数据集对象
test_set = torchvision.datasets.CIFAR10("./dataset/CIFAR10", transform=dataset_transform, train=False, download=True)
# DataLoader对象
test_dataloader = DataLoader(dataset=test_set, batch_size=64 , shuffle=False, num_workers=0, drop_last=True)
# tensorboard对象
writer = SummaryWriter("logs")
for epoch in range(2): # 遍历两次数据集
step = 0 #训练步骤
for imgs, tars in test_dataloader: # imgs为输入图片的批量,tars为与图像对应的label的批量
writer.add_images(f"epoch : {epoch}",imgs,step)
step += 1
writer.close()
总结
- 多查看pytorch官方文档,有详细地使用方法
















 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









