







李沐深度学习——LeNet AlexNet Vgg
文章目录
一、LeNet
1.前言
LeNet,它是最早发布的卷积神经网络之一,因其在计算机视觉任务中的高效性能而受到广泛关注。 这个模型是由AT&T贝尔实验室的研究员Yann LeCun在1989年提出的(并以其命名),目的是识别图像 (LeCun et al., 1998)中的手写数字。 当时,Yann LeCun发表了第一篇通过反向传播成功训练卷积神经网络的研究,这项工作代表了十多年来神经网络研究开发的成果。
2.网络架构图
3.代码实现
net = nn.Sequential(
nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(),
nn.Linear(16*5*5,120),nn.Sigmoid(),
nn.Linear(120,84),nn.Sigmoid(),
nn.Linear(84,10))
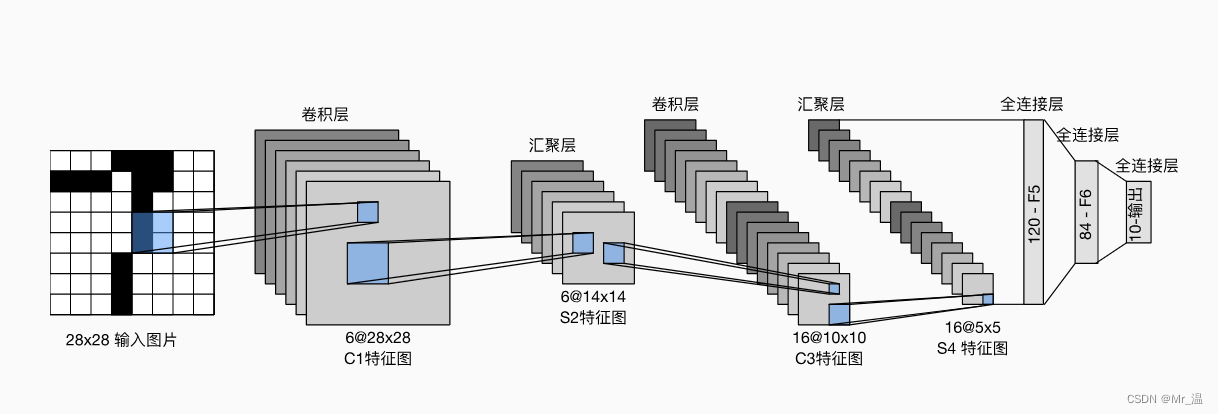
首先输入是一个28×28的图片,经过第一个卷积层,输出变为(28-5+1+4)=6×28×28,然后经过Sigmoid激活,经过平均池化层,输出变为(28-2)/2+1= 6×14×14,经过卷积层变为(14-5+1)=16×10×10,经过Sigmoid激活,经过平均池化层变为(10-2)/2+1 =16×5×5,然后经过Flatten函数,将其展成向量 (1×(16×5×5)),最后接几个全连接层输出。
4.总结
LeNet是最早发布的卷积神经网络之一。
二、AlexNet
1.前言
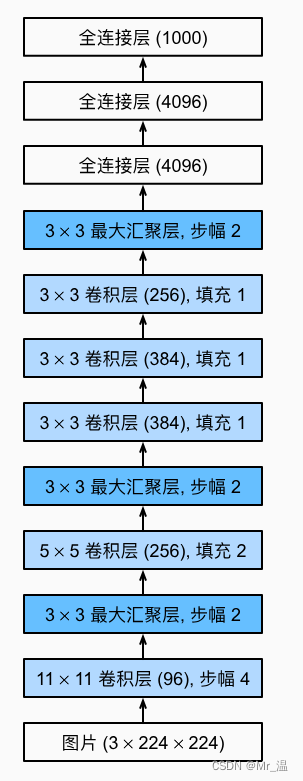
2012年,AlexNet横空出世。它首次证明了学习到的特征可以超越手工设计的特征。它一举打破了计算机视觉研究的现状。 AlexNet使用了8层卷积神经网络,并以很大的优势赢得了2012年ImageNet图像识别挑战赛。
它与LeNet很相似,但是又与LeNet有所不同。
不同之处在于:
1.使用了丢弃法,防止过拟合
2.使用Relu激活函数替代了Sigmoid函数。(Relu函数的梯度更大,在0点的梯度效果更好)。
3.使用最大池化层替换了平均池化层。
2.网络架构图
3.代码实现
# AlexNet
net = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
由于沐神为了时间,选用的数据集是Fashion-MNIST而不是ImageNet。所有刚开始加载数据集需要将图片拉长到224*224的大小,并且最后的线性层输出为10,表示有10个类别。
4. 总结
AlexNet的架构与LeNet相似,但使用了更多的卷积层和更多的参数来拟合大规模的ImageNet数据集。
今天,AlexNet已经被更有效的架构所超越,但它是从浅层网络到深层网络的关键一步。
尽管AlexNet的代码只比LeNet多出几行,但学术界花了很多年才接受深度学习这一概念,并应用其出色的实验结果。这也是由于缺乏有效的计算工具。
Dropout、ReLU和预处理是提升计算机视觉任务性能的其他关键步骤。
三、VGG网络
1.前言
虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。
使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的VGG网络中。通过使用循环和子程序,可以很容易地在任何现代深度学习框架的代码中实现这些重复的架构。
2.网络架构图
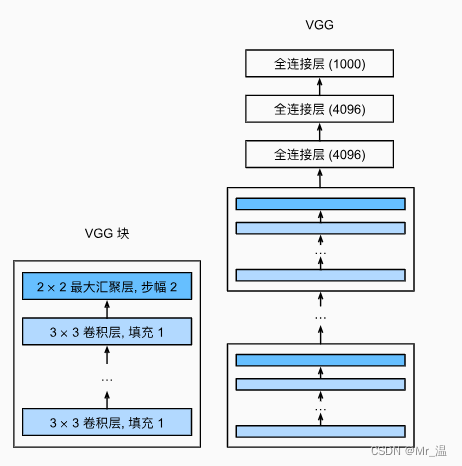
左侧的是VGG块,VGG网络可以理解为将多个VGG块联合起来(每个块让长宽减半,通道数翻倍),然后最终经过全连接层输出。
3.代码实现
1.VGG块函数
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
参数列表有三个,num_convs表示这个块有多少个卷积层,in_channels表示输入的通道数,out_channels表示输出的通道数。
然后依次将卷积层加入到layers里面(这里的卷积层没有改变宽高,只改变了通道数),然后每一个卷积加一个激活函数(如果卷积有多个,需要将in_channels=out_channels)。
最后加一个最大池化层,将宽高减半。
2. VGG函数
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs,out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs,in_channels,out_channels))
in_channels = out_channels
return nn.Sequential(*conv_blks,nn.Flatten() ,
nn.Linear(in_features=out_channels*7*7,out_features=4096),nn.ReLU(),
nn.Dropout(0.5),nn.Linear(4096,4096),nn.ReLU(),
nn.Dropout(0.5),nn.Linear(4096,10))
net=vgg(conv_arch)
首先定义一个conv_arch元组来表示有几个VGG块,(a,b)分别表示卷积层的数量和输出通道数
然后依次取conv_arch,将初始in_channels赋值为1,然后在网络中加入一个VGG块,加入完成之后将in_channels=out_channels
最后在原有的VGG块上加入全连接层。
4.总结
VGG-11使用可复用的卷积块构造网络。不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
VGG中每个块将长宽减半,通道数增倍,在后来的研究中发现这样做是有效的。
四、全文总结
这就是我对李沐大佬讲解的LeNet,AlexNet,VGG网络的理解即笔记。
感谢各位的浏览,如果有错误的地方还望各位指正。















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









