







实验室项目来了一个新需求:因为我们那个系统主要是人家用下位机把一些路面参数、空气湿度等参数测出来之后发送到我们阿里云服务器上的pg数据库中,然后我们对数据进行页面上的展示。然后公司那边说有个需求,就是想计算出,两个使用仪器的用户都共同关注了哪些参数(我们参数有很多,有时候比如说土壤水分1一直到土壤水分99,土壤导电率1到99这种,)
PART1-1:刚开始想着,能不能搞个工具类,然后里面搞些Map或者Set集合们,利用键值的对应关系,来了用户就往里塞,比如用户一关注了土壤水分1,但是后来感觉没办法记录时间呀,因为要知道这个用户是啥时候采集的这个数据或者说参数上传到数据库的,所以就搁置了。
PART1-2:
- 使用Redis实现多用户关注共同的参数的统计功能:
- 然后我当时就依稀记得,学redis时,redis可以计算出两个用户共同关注了哪些相同的用户。
实现思路就是,比如用户1和用户2都给土壤温度50上传过数据(说明他们此时都关注了这个土壤50这个参数),所以当用户1上传土壤50这个参数值时后台会打印用户2在那年那月那日那天也上传了这个土壤温度50这个参数值Redis的共同关注功能本质上就是计算两个用户关注集合的交集。刚开始没有用redis时直接用pg数据库这种关系型数据库上手计算共同值【想着看能不能用数据库的各种SQL函数啥的,查了半天,试了半天】时直接给我整蒙了,我所使用的关系数据库并不直接支持交集计算操作,有时候刚好两个参数需要计算两个集合的交集,除了需要对两个数据表执行合并(join)操作之外,还需要对合并的结果执行去重复(distinct)操作,最终导致交集操作的实现变得异常复杂。越写越乱越复杂。 然后我上谷歌搜了后,才知道redis支持对集合执行交集、 并集、差集等集合计算操作,其中的交集计算操作可以直接用于实现我想要的共同关注功能。 之前需要使用一段甚至一大段SQL查询才能实现的功能,现在只需要调用一两个Redis命令就能够实现了,而且不仅代码量更少,速度也更快。- redis的set集合可以很轻松的实现“共同好友、共同关注”等功能。
- sadd 将一个或多个成员元素加入到集合中,已经存在于集合的成员元素将被忽略;SADD key member1 [member2] 向集合添加一个或多个成员
- SINTER 返回给定所有给定集合的交集; SINTER key1 [key2] 返回给定所有集合的交集
- SUNION 返回给定集合的并集;SUNION key1 [key2] 返回所有给定集合的并集
- SDIFF 返回第一个集合与其他集合之间的差异;SDIFF key1 [key2] 返回给定所有集合的差集)
- 然后我当时就依稀记得,学redis时,redis可以计算出两个用户共同关注了哪些相同的用户。
PART2:那上面的共同关注大概有个设计思路后,咱们再看看 如果让咱们计算数据流中不同元素的个数?例如,独立访客(Unique Visitor,简称UV)统计。这个问题称为基数估计(Cardinality Estimation)。
- 有以下几种不同的设计思路:
- 方案1: HashSet:首先最容易想到的办法是
用HashSet,每来一个元素,就往里面塞,HashSet的大小就所求答案。但是在大数据的场景下,HashSet在单机内存中存不下。 - 方案2: bitmap
HashSet耗内存主要是由于存储了元素的真实值,可不可以不存储元素本身呢?bitmap就是这样一个方案,假设已经知道不同元素的个数的上限,即基数的最大值,设为N,则开一个长度为N的bit数组,地位跟HashSet一样。每个元素与bit数组的某一位一一对应,该位为1,表示此元素在集合中,为0表示不在集合中。那么bitmap中1的个数就是所求答案。- 这个方案的缺点是,bitmap的长度与实际的基数无关,而是与基数的上限有关。假如要计算上限为1亿的基数,则需要12.5MB的bitmap,十个网站就需要125M。关键在于,这个内存使用与集合元素数量无关,即使一个网站仅仅有一个1UV,也要为其分配12.5MB内存。该算法的空间复杂度是O(N_{max})O(Nma**x)。
实际上目前还没有发现在大数据场景中准确计算基数的高效算法,因此在不追求绝对准确的情况下,使用近似算法算是一个不错的解决方案。
- 这个方案的缺点是,bitmap的长度与实际的基数无关,而是与基数的上限有关。假如要计算上限为1亿的基数,则需要12.5MB的bitmap,十个网站就需要125M。关键在于,这个内存使用与集合元素数量无关,即使一个网站仅仅有一个1UV,也要为其分配12.5MB内存。该算法的空间复杂度是O(N_{max})O(Nma**x)。
- 方案3: Linear Counting:

- Linear Counting的基本思路是:
- 选择一个哈希函数h,其结果服从均匀分布
- 开一个长度为m的bitmap,均初始化为0
- 数据流每来一个元素,计算其哈希值并对m取模,然后将该位置为1
- 查询时,设bitmap中还有u个bit为0,则不同元素的总数近似为

- Linear Counting的基本思路是:
- 方案4: LogLog Counting:

- 方案1: HashSet:首先最容易想到的办法是
PART3:频率估计(Frequency Estimation)问题:计算数据流中任意元素的频率
- 方案1: HashMap
用一个HashMap记录每个元素的出现次数,每来一个元素,就把相应的计数器增1。这个方法在大数据的场景下不可行,因为元素太多,单机内存无法存下这个巨大的HashMap。
- 方案2: 数据分片 + HashMap:
- 既然单机内存存不下所有元素,一个很自然的改进就是使用多台机器。
假设有8台机器,每台机器都有一个HashMap,第1台机器只处理hash(elem)%8==0的元素,第2台机器只处理hash(elem)%8==1的元素,以此类推。查询的时候,先计算这个元素在哪台机器上,然后去那台机器上的HashMap里取出计数器。 - 方案2能够scale, 但是依旧是把所有元素都存了下来,代价比较高。如果允许近似计算,那么有很多高效的近似算法,单机就可以处理海量的数据。
- 既然单机内存存不下所有元素,一个很自然的改进就是使用多台机器。
- 方案3: Count-Min Sketch【Count-Min Sketch算法的优点是省内存,缺点是对于出现次数比较少的元素,准确性很差,因为二维数组相比于原始数据来说还是太小,hash冲突比较严重,导致结果偏差比较大。】


PART4:寻找数据流中出现最频繁的k个元素(find top k frequent items in a data stream)。这个问题也称为 Heavy Hitters.例如搜索引擎的热搜榜,找出访问网站次数最多的前10个IP地址,等等。
- 方案1: HashMap + Heap:
如果元素数量巨大,单机内存存不下,怎么办?有两个办法,见方案2和3。- 用一个 HashMap<String, Long>,存放所有元素出现的次数,用一个小根堆,容量为k,存放目前出现过的最频繁的k个元素,
- 每次从数据流来一个元素,如果在HashMap里已存在,则把对应的计数器增1,如果不存在,则插入,计数器初始化为1
- 在堆里查找该元素,如果找到,把堆里的计数器也增1,并调整堆;如果没有找到,把这个元素的次数跟堆顶元素比较,如果大于堆顶元素的出现次数,则把堆丁元素替换为该元素,并调整堆
- 空间复杂度O(n)。HashMap需要存放下所有元素,需要O(n)的空间,堆需要存放k个元素,需要O(k)的空间,跟O(n)相比可以忽略不急,总的时间复杂度是O(n)
- 时间复杂度O(n)。每次来一个新元素,需要在HashMap里查找一下,需要O(1)的时间;然后要在堆里查找一下,O(k)的时间,有可能需要调堆,又需要O(logk)的时间,总的时间复杂度是O(n(k+logk)),k是常量,所以可以看做是O(n)。
- 用一个 HashMap<String, Long>,存放所有元素出现的次数,用一个小根堆,容量为k,存放目前出现过的最频繁的k个元素,
- 方案2: 多机HashMap + Heap
可以把数据进行分片。假设有8台机器,第1台机器只处理hash(elem)%8==0的元素,第2台机器只处理hash(elem)%8==1的元素,以此类推。- 每台机器都有一个HashMap和一个 Heap, 各自独立计算出 top k 的元素。
- 把每台机器的Heap,通过网络汇总到一台机器上,将多个Heap合并成一个Heap,就可以计算出总的 top k 个元素了
- 方案3: Count-Min Sketch + Heap

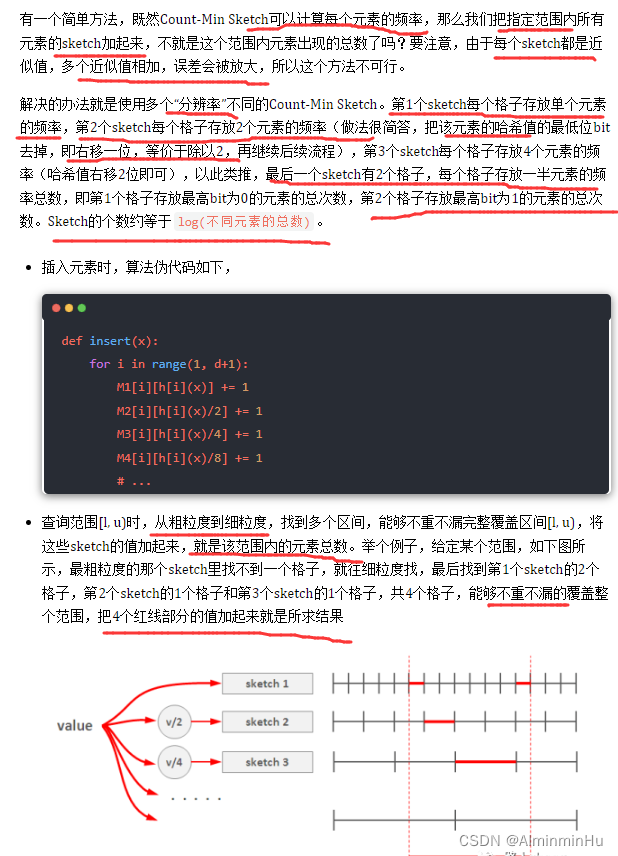
PART5:给定一个无限的整数数据流,如何查询在某个范围内的元素出现的总次数?例如数据库常常需要SELECT count(v) WHERE v >= l AND v < u。这个经典的问题称为范围查询(Range Query)。
巨人的肩膀:
Redis设计与实现
Redis官方文档
Spring官方文档
https://github.com/donnemartin/system-design-primer
Google搜索引擎
路人张老师的公众号文章















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









