








- 原始项目可能主要的功能是接收下位机传送来的很多参数,然后将参数以不同形式表达出来,在此过程中会涉及到文件上传下载、excel表格导出…等,但是呢,这么多数据不玩一下岂不是太浪费。于是,额们决定这样来:
- 项目中有一个摄像头实时监控模块,但是我们项目用的摄像头有缺陷,识别不准确、只能进行离线计算【比如套牌车这种应用场景,等你离线去算时人家早没了,会花很多功夫,所以得搞实时时的】
- 具体实施思路的主要流程:
由我们的高速这个凝冰预警系统中的实时监控摄像头拍摄到数据,然后将数据给到我们留的Rest接口的服务,我们搞了俩【搞个集群是为了防止高并发以及高可用的情况】,这些接口就是用来接收我们其他系统发来的交通流数据的,比如拍的照片等等通过这个REST接口把数据保存到本地磁盘- 利用LOG4J日志技术把采集到的数据以文件的形式存到本地磁盘【log.info(“要存的数据”)】。主要的采集数据并存储的逻辑在咱们的DataService的子实现类中【代码要规范,该定义接口、异常类等都要定义,搞配置文件出来提高灵活性】
/** *接收数据,并通过Logger保存数据到文件中 */ ... @Service public class DataServiceImpl implements DataService{ ... public void process(String dataType, HttpServletRequest request){ //保护性的判断 if(StringUtils.isEmpty(dataType)){...} //判断请求头中是否传入了数据 int contentLength = request.getContentLength(); if(contentLength < 1){...} //通过字节流读数据,从Request中读取数据 byte[] datas = new byte[contentLength];//存放数据的字节数组 BufferInputStream input = new BufferedInputStream(request.getInputStream()); ... //把JSON字符串先解析出来再存储 ... logger.info(jsonStr); } } - 日志配置文件中,主要的<logger…>中要写项目中哪个包有日志操作行为【具体到本项目中就是存储采集回来的数据】,然后定义日志级别level为INFO,再就是,定义向文件中输出,在中配置文件输出路径
- 关于日志,再多唠唠。咱们这里的日志一般指的是用户的行为,不是之前咱们项目产生的那个狭义的错误日志
- 日志数据分析:涉及到大的数据量的平台系统都可以用

日志数据分分析项目&离线批处理项目的整体流程:一般咱们的代码部署在web容器中,flume一般要跨机器,如果发送数据过程中网络断了怎么办,所以中间搞了个Nginx暂存一下数据,放到本地文件中,然后Flume从本地文件中拿到数据给HDFS,然后…
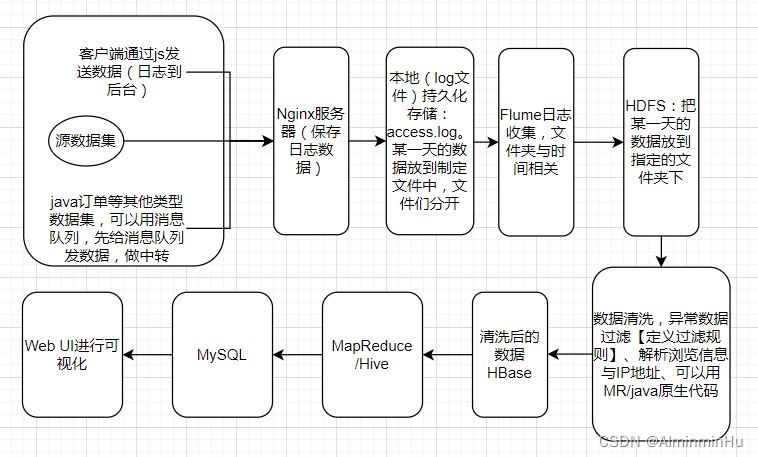
- 数据收集:
- 数据来源:可以从前端得到用户提交的或者操作的数据【咱们通过写java代码向nginx中发送数据http://…?key1=val1&key2=val2&…。其实就是向队列中放数据,然后在另一端从队列中拿数据】
- Flume:可以从不同的Nginx服务器中收集到数据
- 数据来源:可以从前端得到用户提交的或者操作的数据【咱们通过写java代码向nginx中发送数据http://…?key1=val1&key2=val2&…。其实就是向队列中放数据,然后在另一端从队列中拿数据】
- 数据清洗
- 异常数据过滤:定义过滤规则
- 解析浏览信息与IP地址
- 数据存储:技术选型中存储引擎中可以使用HDFS、HBase
- 数据分析:用MapReduce、Hive来进行分析
- 数据可视化
- 数据收集:
- 日志数据分析:涉及到大的数据量的平台系统都可以用
- 利用LOG4J日志技术把采集到的数据以文件的形式存到本地磁盘【log.info(“要存的数据”)】。主要的采集数据并存储的逻辑在咱们的DataService的子实现类中【代码要规范,该定义接口、异常类等都要定义,搞配置文件出来提高灵活性】
然后通过多个Flume去采集多个磁盘的数据,采集来的数据先汇总到一个总的Flume,由这个总的Flume把数据采集到kafka中【kafka只能保存7天】- Flume经常用于数据采集
kafka传给Flink去进行计算,实时分析... @RestController @RequestMapping("/xxx") /** * 这个控制器是,只要有采集的数据请求来http://localhost/...,因为咱们用的是Post方式,所以请求头中有参数来 */ public class DataController{ @PostMapping("/sendData/{dataType}") /** * 因为数据有很多类型,所以得有表示数据类型的字符串变量 * 还因为数据是通过请求参数传进来的,所以得加个@PathVariable() */ public Object collect(@PathVariable("dataType") String dataType, HttpServletRequest request){ ...; } }- 可以用Flink先进行数据清洗
- 利用SpringBoot进行数据采集的实现。比如定义DataController为数据采集的一个控制器
- 然后,进而利用数据进行:
- 实时监控交通流三参数:流密速,基本上车速居多
可以根据逻辑回归去预测某个路段拥堵情况
- 实时智能报警:页面上有路况的预警处理,LED警示牌,师兄去隧道那边做的
- 实时监控交通流三参数:流密速,基本上车速居多
java基础巩固-宇宙第一AiYWM:为了维持生计,做项目经验之~高速项目大数据及机器学习算法方面的思路总结~整起

于 2023-01-27 21:40:36 首次发布















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









