






一、Patition分区
1、默认Partition分区:
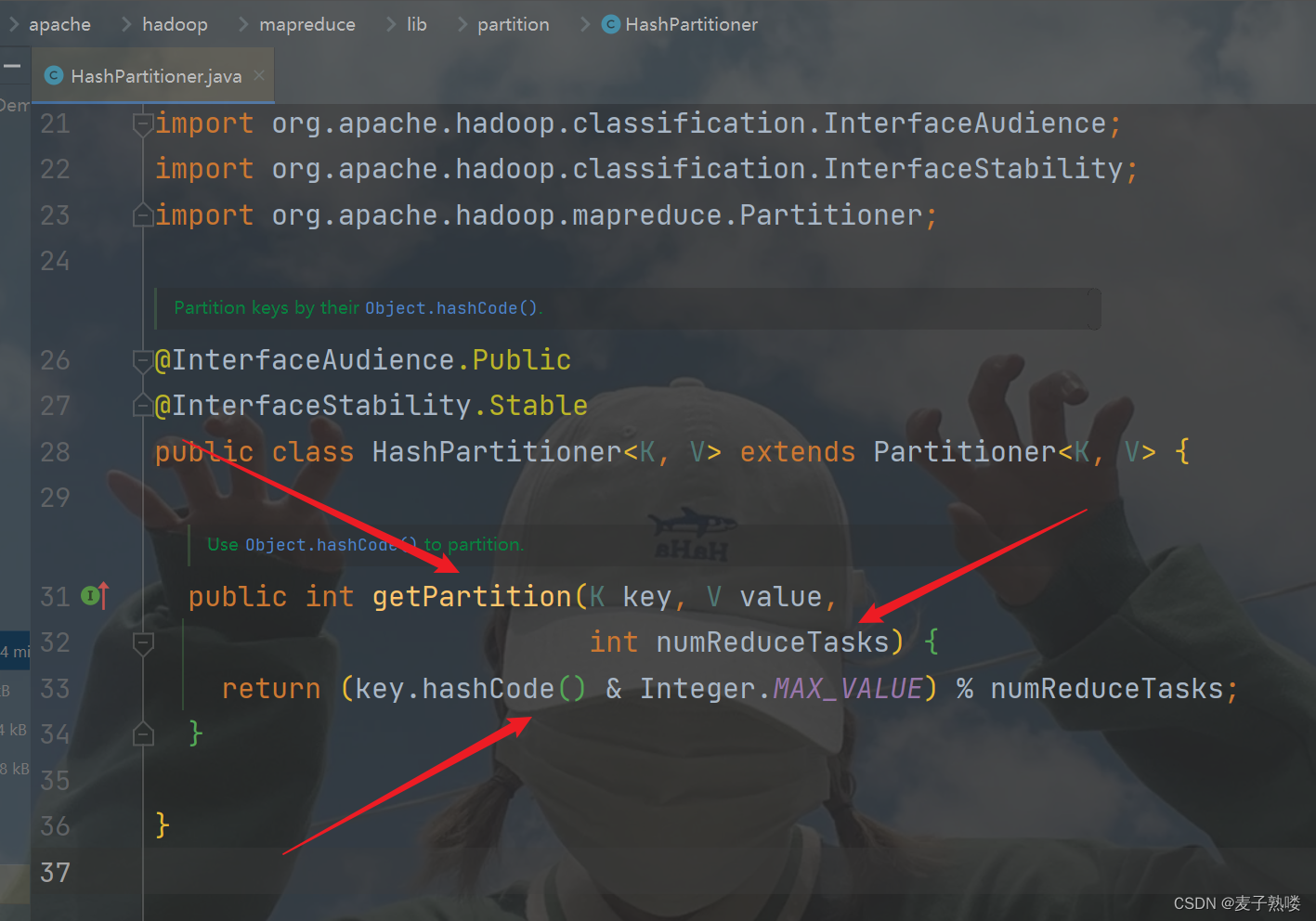
通过哈希函数,计算键(key)在 MapReduce 任务中的分区(partition)。通过对键(key)的哈希值模运算 % numReduceTasks,得到一个介于0到numReduceTasks之间的整数。该整数就是键(key)所对应的分区号,使得键(key)被映射到介于 0 到 numReduceTasks - 1 之间的分区,numReduceTasks 表示 Reduce 任务的总数,从而确定了键所属的分区。
2、自定义Partition分区:

通过重写getPartition方法,从而自定义有几个Partition分区。
3、Partition分区总结:
(1)、若ReduceTasks数 > Partition分区数,则会多产生几个空的输出文件part-r-000xx。
(2)、若ReduceTasks数 = Partition分区数,此乃最优结果,一个ReduceTask处理一个Partition中的数据。
(3)、若ReduceTasks数 < Partition分区数,则会有一部分数据无处安放,就会报错。
(4)、若ReduceTasks数 = 1,则不管有MapTask端输出多少个分区文件,最终结果都会交给这一个ReduceTask处理,所以也只会产生一个结果文件part-r-00000。并且在该情况下,Partition分区不会走自定义的方法,就走默认的getPartition方法。
(5)、分区号必须从0开始,逐一累加,直到 numReduceTasks - 1 结束。
二、ReduceTask
1、Reduce 任务是在 MapReduce 框架中的一个重要组成部分。它负责对Map阶段产生的中间键值对进行聚合和处理,生成最终的输出结果。
2、在 MapReduce 中,Reduce 任务的数量是可配置的,通常由用户在作业提交时指定。Reduce 任务的数量决定了并行处理的程度和数据的分片数量。较多的 Reduce 任务可以提高并行度,加快处理速度,但也会增加通信和存储开销。
3、ReduceTask的工作流程:
(1)、ReduceTask主动拉取Shuffle阶段产生的分区数据文件,并对其数据进行一次归并排序,方便后面的逻辑操作。
(2)、对相同键的键值对进行聚合和处理。通常,用户需要重写 Reduce 方法来定义具体的聚合逻辑。
(3)、将聚合后的结果输出到最终的输出文件或数据存储系统中。
4、ReduceTask数目的设定:
(1)、默认值是1。
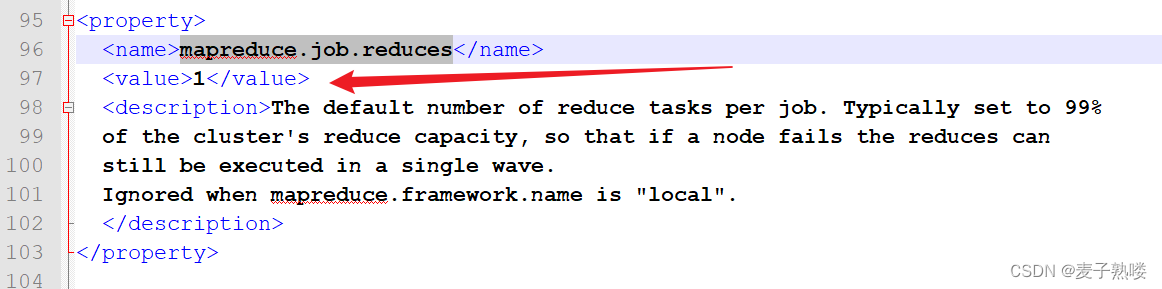
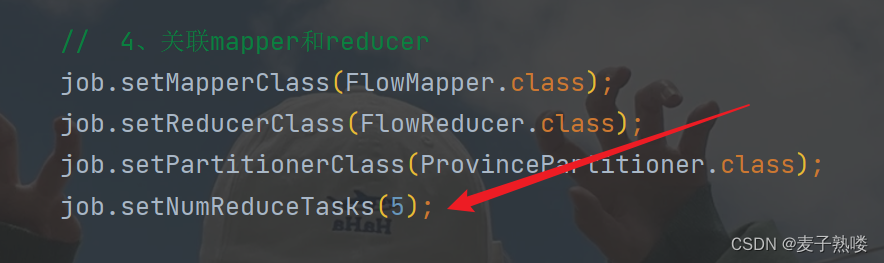
(2)、可以通过以下方式自定义ReduceTask的数目。
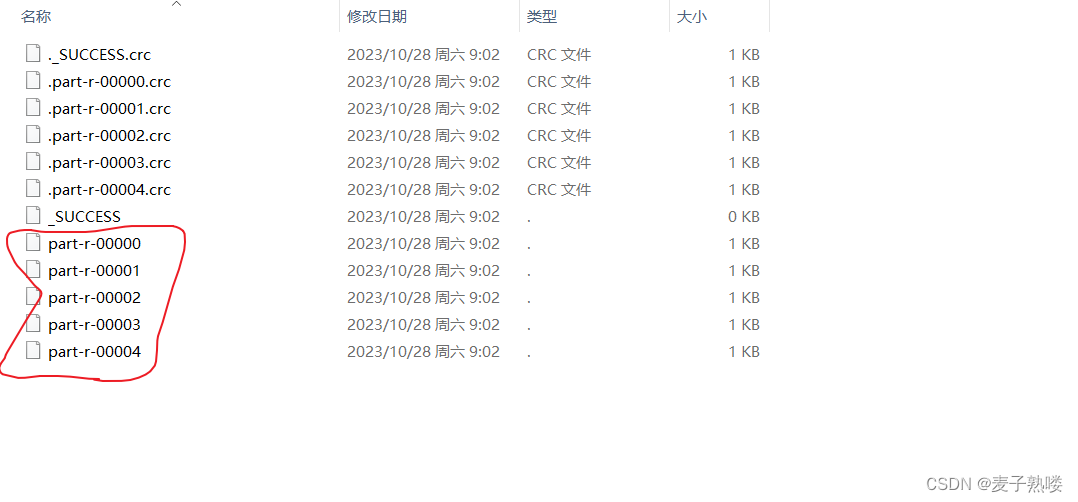
三、输出文件
即MapReduce阶段最终的输出文件。
例如我自定义ReduceTask的数目为5,则有5个输出文件。
四、分区数、Reduce Task 的数量和输出文件的个数之间的关系
1、分区数:在 MapReduce 中,MapTask 的输出会根据键(key)进行分区,不同的键会被分配到不同的分区中。分区数可以通过自定义partitioner来实现指定,创建一个自定义类继承Partitioner并且重写getPartition()方法,在方法中指定partition的个数以及分区号,分区数默认值为 1。分区数决定了 Reduce Task 的输入数据如何划分。
2、ReduceTask 的数量:默认值是1,ReduceTask 的数量由用户根据需求进行设置,可以通过 job.setNumReduceTasks(int numReduceTasks) 来指定。ReduceTask 的数量决定了最终输出文件的个数。
3、输出文件的个数:在 MapReduce 中,每个 ReduceTask 会生成一个输出文件。因此,输出文件的个数等于 ReduceTask 的数量。
4、分区数决定了 MapTask 的输出如何划分,ReduceTask 的数量决定了最终输出文件的个数。如果你设置了 n 个 ReduceTask,那么就会有 n 个输出文件。每个输出文件对应一个 ReduceTask 的输出结果。
5、输出文件的个数和 ReduceTask 的数量是一一对应的,但分区数与输出文件的个数之间没有直接的关系。分区数主要影响 MapTask 的输出划分方式,而不会直接决定最终输出文件的个数。
6、最优的情况就是分区数等于ReduceTask数目,一对一的情况,一个分区的文件数据由一个ReduceTask处理。在该情况下,分区数 = ReduceTask数 = 输出文件数。
五、本文由自己学习总结,如有错误之处,还望读者指出。希望大家一起进步,望诸君共勉之。















 999
999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









