







数据挖掘-使用支持向量机实现恶意url检测
项目代码见资源【数据挖掘】恶意url检测
一、实验任务:
选择恶意和正常URL链接数据进行研究(特征选择、算法选择),并编写代码构建模型,最终满足如下需求: - 打印出模型的准确率和召回率; - 代码可以根据输入的URL自动判定其安全性;
二、实验环境
AIstudio
(vscode也可以)
python 3.7.4
需要的包在代码中已经列出
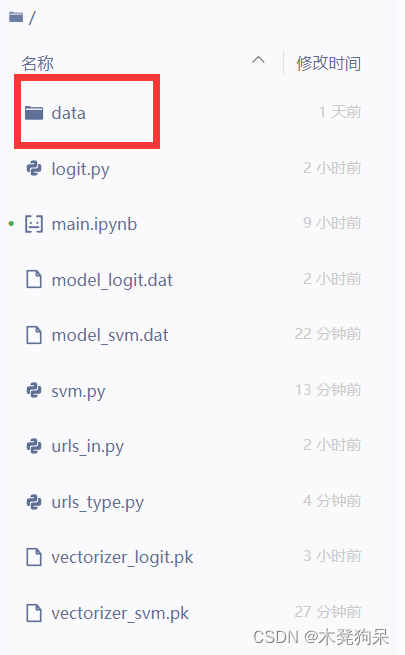
三、项目目录
训练
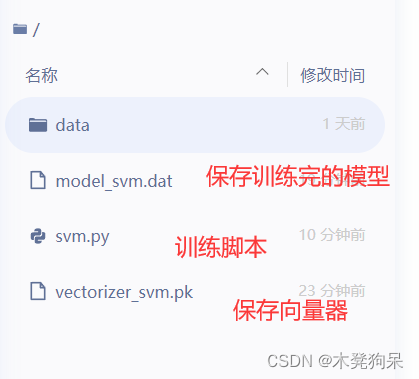
预测

logit是用逻辑回归实现的,经过对比,svm实现的准确率稍微高于logist,因此此处logit无用。
四、实验步骤
1.写训练脚本 svm.py
用支持向量机方法实现
导入需要的包
# coding: utf-8
#!/usr/bin/env python
import pickle
from sklearn import metrics
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
import random
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
数据清洗的函数
处理特殊符号和词, 通过/ - .分割文本,并且删除一些常见词如com https http
#dataset清洗
def makeTokens(f):
tkns_BySlash = str(f.encode('utf-8')).split('/') # make tokens after splitting by slash
total_Tokens = []
for i in tkns_BySlash:
tokens = str(i).split('-') # make tokens after splitting by dash
tkns_ByDot = []
for j in range(0,len(tokens)):
temp_Tokens = str(tokens[j]).split('.') # make tokens after splitting by dot
tkns_ByDot = tkns_ByDot + temp_Tokens
total_Tokens = total_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









