







json数据格式
json和Ajax阿贾克斯 都与前端开发有关
早期网站登录需要刷新,现在可以进行局部异步刷新,比如验证码输入过程中即可判定是否正确,这就是通过ajax来实现判定的,实现了web的二代升级
json和Xml可读性相近,前者更简易的语法,后者更规范的标签,json比xml在javascript使用更多
json对象表示为键值对,数据用逗号分隔,花括号保存对象, 方括号保存数组 //键值对 {“name” : “yoann”} 目前只要熟悉这种json文本格式,其他的还不需要
将json转化为JS对象,使用前端自带的JSON.parse() 反向转换则使用JSON.stringify()
插入JavaScript(前端开发使用)的学习内容:
HTML(结构):超文本标记语言,决定网页结构和内容
CSS(表现):层叠样式表,设定网页的表现样式
JavaScript:弱类型脚本语言,源代码不需经过编译,而由浏览器解释运行,用于控制网页的行为
引用Css预处理器来实现编程中的嵌套等活动,即是用编程语言做web页面设计,再通过编译器转换成正常css文件 ///比如SASS,LESS,其中LESS基于nodejs,通过客户端处理,使用简单
JavaScript很简单易学,是按照ECMAScript标准进行开发的,目前全浏览器支持ES5,但ES6目前是主流,所以需要webpack进行打包转成ES5使用
前端的三大框架:jQuery,封装了很多方法,简化DOM操作,但仅仅使用它来兼容IE 6,7,8(不是三大)
三大框架:Angular,前端开发+模块化开发
React:虚拟DOM,提高网页加载速度
Vue:渐进式JavaScript框架,实现前两种框架的优势
JavaScript构建工具:Babel,JS编译工具,如果浏览器不支持ES新特性,可以使用它编辑TypeScript
Restful风格
//restful是一种设计风格,使用restful API 配合团队的方案,使得代码更简洁规范
基本格式 GET:/api/file GET也可以换成POST,PUT,DELETE来实现不同的功能
基本上就是我们调用URI时的一种写法,URI对应唯一的资源,URL是URI的一种,
URL为统一资源定位器 ,接口属于服务端资源,首先要通过URL这个定位到资源才能去访问,而通常一个完整的URL组成由以下几个部分构成:
URI = scheme “😕/” host “:” port “/” path [ “?” query ][ “#” fragment ]
scheme: 指底层用的协议,如http、https、ftp
host: 服务器的IP地址或者域名
port: 端口,http默认为80端口
path: 访问资源的路径,就是各种web 框架中定义的route路由
query: 查询字符串,为发送给服务器的参数,在这里更多发送数据分页、排序等参数。
fragment: 锚点,定位到页面的资源
从大体样式了解URL路径组成之后,对于RESTful API的URL具体设计的规范如下:
1.不用大写字母,所有单词使用英文且小写。
2.连字符用中杠"-“而不用下杠”_"
3.正确使用 “/“表示层级关系,URL的层级不要过深,并且越靠前的层级应该相对越稳定
4.结尾不要包含正斜杠分隔符”/”
5.URL中不出现动词,用请求方式表示动作
6.资源表示用复数不要用单数
7.不要使用文件扩展名
也就是通过restful 指令完成CRUD(create,read,update,delete)
HTTP状态码
操作API的用户,可以通过HTTP状态码来获取操作是否成功的信息
200 (OK/正常)
200 (SC_OK)的意思是一切正常。一般用于相应GET和POST请求。这个状态码对servlet是缺省的;如果没有调用setStatus方法的话,就会得到200。
201 (Created/已创建)
201 (SC_CREATED)表示服务器在请求的响应中建立了新文档;应在定位头信息中给出它的URL。
202 (Accepted/接受)
202 (SC_ACCEPTED)告诉客户端请求正在被执行,但还没有处理完。
等等。。。
FeignClient
初步理解:类似于接口的一种方法,在spring cloud中可以进行调用,中间可以引用方法,也可以引用springMVC的相关内容
feign 负载均衡,是声明式的web service客户端,旨在使编写java http客户端变得更容易,在feign的实现下,我们不需要在一个接口被多次调用时多次封装对应的类,只需要创建一个接口并使用注解的方式来配置它,(类似于以前dao接口上标注mapper注解,现在是一个微服务接口上面标注一个feign注解即可)即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon时,自动封装服务调用客户端的开发量。
feign满足了面向接口编程的特性,feign同时集成了Ribbon,相当于在使用ribbon调用微服务的同等作用,feign定义服务绑定接口并以声明式的方法,优雅而且简单的实现了服务调用。(默认两种都是同等作用的)
基于接口的注解实现的,即是使用@Autoweired @RequestMapping等注解来实现相关内容的调用,之后就可以通过java编程性语言来定义和编辑相关的接口
在使用时在包中通过注解和Ribbon指令可以做类似于接口式的编程,而在.java主程序中,使用@EnableFeignClients和@ComponentScan来实现调用(和接口类似,但是不是implement方法)
补充:Ribbon(Netflix Ribbon)
ribbon是客户端负载均衡工具,在客户端代码中
如何实现负载均衡, 轮询,随机,Ribbon客户端组件提供了一系列配置如连接超时、重连等
通过轮询随机来实现负载均衡(Load Balance),相关软件lvs,nginx,dubbo,springcloud都可以实现负载均衡(springcloud负载均衡算法还可以自定义)
集中式LB,在消费和提供方中nginx,进程式LB,集成在消费方中
1.先将ribbon和erueka集成到客户端, 然后再配置erueka,配置之后使用//直接在客户端调用@LoadBalanced 就可以用ribbon了
iBATIS
iBATIS 它能够自动在 Java, .NET, 和Ruby on Rails中与SQL数据库和对象之间的映射。映射是从应用程序逻辑封装在XML配置文件中的SQL语句脱钩。
iBATIS强调使用SQL,iBATIS提供独立于数据库的接口和API,帮助应用程序的其余部分保持独立的任何持久性相关的资源。
iBATIS相关优势
支持存储过程:iBATIS的SQL封装以存储过程的形式,使业务逻辑保持在数据库之外,应用程序更易于部署和测试,更便于移植。
支持内嵌的SQL:预编译器不是必需的,并有完全访问所有的SQL语句的特性。
支持动态SQL: iBATIS特性提供基于参数动态生成SQL查询。
支持O / RM:iBATIS支持许多相同的功能作为一个O / RM工具,如延迟加载,连接抓取,缓存,运行时代码生成和继承
主要作用是:将我的的Java对象映射到SQL的参数和将SQL的查询结果转换为Java对象。
框架framework——mybatis(增强的JDBC)
三层架构:mvc做web框架的,m代表数据,v代表视图,c代表控制器
应用从逻辑上分为三层,界面层(接收用户的数据,并显示请求的结果jsp,html,和用户直接打交道的), 业务逻辑层(service,接收传递的数据,检查数据,计算业务逻辑),数据访问层(访问数据库,执行对数据的查询,修改,删除等)
三层对应的包,界面层(controller包:servlet)、业务逻辑层(service包:XXXservice类)、数据访问层(dao包:XXXdao类)
三层中类的交互 用户界面层–》业务逻辑层–》数据访问层(持久层)–》数据库(mysql)
三层对应的处理框架:界面层—servlet—springmvc(框架)
业务逻辑层—service类—spring(框架)
数据访问层—dao类—mybatis(框架)
框架就是模板,作为写程序的标准和格式,同时框架内有些功能是定义好的可用的,也可以加入自己的功能,可以利用框架中写好的功能去做
JDBC的缺陷:代码多,重复度高,业务代码和数据库代码混在一起,对ResultSet查询的结果,需要自己封装为List,还需要关注connection,statement,resultset的对象创建和销毁
iBATIS提供的持久性框架包括SQL MAPS :sql映射(可以把数据库表中的一行数据,映射成为一个java对象,一行数据可以看作一个java对象) 和Data Access Objects(DAOs):数据访问(可以对数据库执行增删改查)
提供功能:提供创建connection,statement,resultset能力,不需开发人员再创建
提供了执行sql语句的能力,不用你执行sql
提供了循环sql,把sql结果转化为java对象,list集合的能力
提供了关闭资源的能力,不用关闭connection,statement,resultset
需要开发人员做:提供sql语句
开发人员提供sql语句,mybatis处理sql,开发人员就能得到list集合或java对象(表中的数据)
入门的mybatis步骤:
1.新建student表
2.加入maven的mybatis坐标和mysql坐标
3.创建实体类,student–保存表中的一行数据
4.创建持久层的dao接口,实现操作数据库的方法
5.创建一个mybatis使用的配置文件,叫做sql映射文件:写sql语句的,一般一个表一个sql映射文件,这个文件是xml文件
6.创建mybatis的主配置文件,一个项目就是一个主配置文件。主配置文件提供了数据库的连接信息和sql映射文件的位置信息
7.创建使用mybatis类,通过mybatis访问数据库
创建一个初步的mybatis类练手
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace = "com.项目名.包名.类名">
<select id = "selectBlog" resultType = "Blog">
select * from Blog where id = #{id}
</select>
</mapper>
指定约束文件
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
mybatis-3-mapper.dtd是约束文件的名称,扩展名是dtd的。
约束文件作用:
限制,检查在当前文件中出现的标签,属性必须符合mybatis的要求
mapper 是当前文件的跟标签,必须的。
namespace叫做命名空间,唯一值的,也可以是自定义的字符串,要求你使用dao接口的全限定名称//尽量使用全限定斌名称 com.项目名.包名.类名
在当前文件中可以使用特定的标签,表示数据库的特定操作。
<select>:表示执行查询 <update>:表示更新数据库的操作,就是在<update>标签中,写的是update sql语句
<insert>表示插入,放insert语句 <delete>也用对应的语句
select表示查询操作。id:你要执行的sql语句的唯一标识,你的mybatis会使用这个id的值来找到要执行的sql语句,可以自定义,但是要求你使用接口中的方法名称。
<select id = "selectBlog" resultType = "Blog">
select * from Blog where id = #{id}
</select>
//resultType表示结果类型的,是sql语句执行后得到ResultSet,遍历这个ResultSet得到的java对象的类型
//所以最后select的返回值是什么类型,之前的resultType就写对应的类型的包名(全限定名称)
//1.定义Mybatis主配置文件的名称,从类路径的根开始(target/classes)
string config=“mybatis.xml”;
//2.读取这个config表示的文件
Inputstream in =Resources.getResourceAsstream(config);
//3.创建了SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder builder =new SqlsessionFactoryBuilder();
//4.创建SqlSessionFactory对象
SqlsessionFactory factory =builder.build(in);
//5.获取SqlSession对象,从sqlSessionFactory中获取Sqlsession
Sqlsession sqlsession=factory.opensession();
//6.【重要】指定要执行的sq1语句的标识。 sq1映射文件中的namespace +“.”+标签的id值 /通过它来指定目标
//string sqlid =“com.bjpowernode.dao.studentDao” + ".”+ “selectstudents”; string sqlid =“com.bipowernode.dao.studentDao.selectstudents”;
//7.【重要】执行sq1语句,通过sqlid找到语句
List studentList = sqlsession selectList(sqlid);
//8.输出结果
//studentList.forEach( stu -> System.out.println(stu));
for(student stu : studentlist){
System.out.println(“查询的学生=”+stu);}
//9.关闭Sqlsession对象
SqlSession.close();
在运行时,确保resources文件夹为test格式,mybatis.xml文件才能被转成class文件读取,同时确保pom.xml文件下有指向文件的扫描,才能确保dao文件下的StudentDao.xml文件拷贝一份到class文件下
在写完大框架之后,基本进行替换就可以实现不同的方法,(增加新方法定义,在xml中的<>来指定我们的sql语句,然后再替换掉sqlID 和对应的方法就可以了 //比如insert,直接使用insert into student value(#{id},#{name},#{emile},#{age}) 用收尾,不需要使用;
mybatis不会自动提交,所以表中数据不会更新,需要用sqlSession.commit();来提交
设置mybatis日志
<settings>
<!--设置mybatis输出日志-->
<setting name="logImpl" value="STDOUT LOGGING" />
</settings> //就是把电脑执行的过程日志简化输出,有助于了解步骤进行调试
写mybatis文件中几个主要的对象:
resources ,只负责读主配置文件 ,转化成一个Inputstream //Inputstream in =Resources.getResourceAsstream(config);
SqlSessionFactoryBuilder,创建SqlSessionFactory对象,创建builder,然后用build方法创建SqlSessionFactory //SqlSessionFactoryBuilder builder =newSqlsessionFactoryBuilder(); //SqlsessionFactory factory =builder.build(in);
SqlSessionFactory,重要 ,程序创建时耗时比较长,使用资源比较多,在整个项目中,有一个就够用了,本质上是一个接口 接口的实现类:DefaultSqlSessionFactory
作用是:获取Sqlsession对象,通过 Sqlsession sqlsession=factory.opensession();
opensession()方法说明:1、无参数的,获取的是非自动提交事务的Sqlsession对象; 2、opensession(boolean):opensession(true) 获取自动提交事务的Sqlsession对象;opensession(false) 获取非自动提交事务的Sqlsession对象
SqlSession:是接口,含有多种返回表中数据的方法 ,定义了操作数据的方法例如:selectOne(),selectList(),insert(),update(),delect(),commit(),rollback();
SqlSession接口的实现类(父类):DefaultSqlSession
使用要求: SqlSession对象不是线程安全的,需要在方法内部使用,在执行sql语句之前,使用openSession()获取SqlSessio在执行完sq1语句后,需要关闭它,执行SqlSession.close()这样能保证他的使用是线程安全的。
使用注解开发
MyBatis最初配置信息是基于 XML ,映射语句(SQL)也是定义在 XML 中的。而到MyBatis 3提供了新的基于注解的配置。不幸的是,Java 注解的的表达力和灵活性十分有限。最强大的 MyBatis 映射并不能用注解来构建,所以这里我们作为了解。使用注解开发可以摆脱mapper.xml映射文件
在接口中使用注解开发,例子:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Admin {
private static final Long serialVersionUID = 1L;
private int id;
private String username;
private String password;
}
public interface AdminMapper {
/**
* 保存管理员
* @param admin
* @return
*/
@Insert("insert into admin (username,password) values (#{username},#{password})")
int saveAdmin(Admin admin);
/**
* 跟新管理员
* @param admin
* @return
*/
@Update("update admin set username=#{username} , password=#{password} where id = #{id}")
int updateAdmin(Admin admin);
/**
* 删除管理员
* @param admin
* @return
*/
@Delete("delete from admin where id=#{id}")
int deleteAdmin(int id);
/**
* 根据id查找管理员
* @param id
* @return
*/
@Select("select id,username,password from admin where id=#{id}")
Admin findAdminById(@Param("id") int id);
/**
* 查询所有的管理员
* @return
*/
@Select("select id,username,password from admin")
List<Admin> findAllAdmins();
}
Mybatis的架构

mock单元测试
mock可以模拟对象返回方式来解决与该单元功能不相关的依赖关系,即模拟B类的m2方法返回结果来进行A类的m1方法单元测试,排除受到B类C类等其它不相关因素的影响。Mock 测试就是在测试过程中,对于某些不容易构造或者不容易获取的比较复杂的对象,用一个虚拟的对象(Mock 对象)来创建以便测试的测试方法。
MockMVC基于RESTful风格的测试
对于前后端分离的项目而言,无法直接从前端静态代码中测试接口的正确性,因此可以通过MockMVC来模拟HTTP请求。基于RESTful风格的SpringMVC的测试,我们可以测试完整的Spring MVC流程,即从URL请求到控制器处理,再到视图渲染都可以测试。
mock特点
不需要启用Spring及连接数据库。不需要联网,不要等其他人的方法完成
基本使用方法
Mockito基本使用方法简介
//(1)、静态导入会使代码更简洁
import static org.mockito.Mockito.*;
//创建mock对象,mock一个List接口
List mockedList = mock(List.class);
//如果不使用静态导入,则必须使用Mockito调用
List mockList = Mockito.mock(List.class);
//(2)、验证某些行为
//你可以mock一个具体的类型,而不仅是接口
LinkedList mockedList = mock(LinkedList.class);
mockedList.add("one");
//验证
verify(mockedList).add("one");
//一旦mock对象被创建了,mock对象会记住所有的交互。然后你就可能选择性地验证你感兴趣的交互。
//(3)、如何做一些测试桩
//测试桩
when(mockedList.get(0)).thenReturn("first");
when(mockedList.get(1)).thenThrow(new RuntimeException());
当调用mockList.get(0)的时候,返回first
当调用mockList.get(1)的时候,抛出一个运行时异常
//(4)、其他使用见上面文档
对于MockMVC
2.1、初始化MockMvc对象
@Autowired
private WebApplicationContext webApplicationContext;
private MockMvc mockMvc;
//在每个测试方法执行之前都初始化MockMvc对象
@BeforeEach
public void setupMockMvc() {
mockMvc = MockMvcBuilders.webAppContextSetup(webApplicationContext).build();
}
完成一些接口的测试
1)、尝试测试一个不存在的请求 /user/1
-
/** * @DisplayName 自定义测试方法展示的名称 * @throws Exception */ @DisplayName("测试根据Id获取User") @Test void contextLoads() throws Exception { //perform,执行一个RequestBuilders请求,会自动执行SpringMVC的流程并映射到相应的控制器执行处理 mockMvc.perform(MockMvcRequestBuilders //构造一个get请求 .get("/user/1") //请求类型 json .contentType(MediaType.APPLICATION_JSON)) // 期待返回的状态码是4XX,因为我们并没有写/user/{id}的get接口 .andExpect(MockMvcResultMatchers.status().is4xxClientError()); }
2)、在Controller中完成 /user/{id}
```java
/**
* id:\\d+只匹配数字
* @param id
* @return
*/
@GetMapping("/user/{id:\\d+}")
public User getUserById(@PathVariable Long id) {
return userService.getById(id);
}
修改一下测试类:期待返回的结果是200
//可以加入@MockBean,自己定义返回的结果,完成接下来的测试
@MockBean
private UserService userService;
@Test
void getUserById() throws Exception {
//perform,执行一个RequestBuilders请求,会自动执行SpringMVC的流程并映射到相应的控制器执行处理
mockMvc.perform(MockMvcRequestBuilders
//构造一个get请求
.get("/user/1")
//请求类型 json
.contentType(MediaType.APPLICATION_JSON))
// 期望的结果状态 200
.andExpect(MockMvcResultMatchers.status().isOk());
//添加ResultHandler结果处理器,比如调试时 打印结果(print方法)到控制台
.andDo(MockMvcResultHandlers.print());
}
常用API总结
常用的期望:
//使用jsonPaht验证返回的json中code、message字段的返回值
.andExpect(MockMvcResultMatchers.jsonPath("$.code").value("00000"))
.andExpect(MockMvcResultMatchers.jsonPath("$.message").value("成功"))
//body属性不为空
.andExpect(MockMvcResultMatchers.jsonPath("$.body").isNotEmpty())
// 期望的返回结果集合有2个元素 , $: 返回结果
.andExpect(MockMvcResultMatchers.jsonPath("$.length()").value(2));
附带常用API解释:
RequestBuilder/MockMvcRequestBuilders:
//根据uri模板和uri变量值得到一个GET请求方式的MockHttpServletRequestBuilder;
MockHttpServletRequestBuilder get(String urlTemplate, Object... urlVariables)
//同get类似,但是是POST方法;
MockHttpServletRequestBuilder post(String urlTemplate, Object... urlVariables)
//同get类似,但是是PUT方法;
MockHttpServletRequestBuilder put(String urlTemplate, Object... urlVariables)
//同get类似,但是是DELETE方法;
MockHttpServletRequestBuilder delete(String urlTemplate, Object... urlVariables)
//同get类似,但是是OPTIONS方法;
MockHttpServletRequestBuilder options(String urlTemplate, Object... urlVariables)
//提供自己的Http请求方法及uri模板和uri变量,如上API都是委托给这个API;
MockHttpServletRequestBuilder request(HttpMethod httpMethod, String urlTemplate, Object... urlVariables)
//提供文件上传方式的请求,得到MockMultipartHttpServletRequestBuilder;
MockMultipartHttpServletRequestBuilder fileUpload(String urlTemplate, Object... urlVariables)
//创建一个从启动异步处理的请求的MvcResult进行异步分派的RequestBuilder;
RequestBuilder asyncDispatch(final MvcResult mvcResult)
MockHttpServletRequestBuilder:
//:添加头信息;
MockHttpServletRequestBuilder header(String name, Object... values)/MockHttpServletRequestBuilder headers(HttpHeaders httpHeaders)
//:指定请求的contentType头信息;
MockHttpServletRequestBuilder contentType(MediaType mediaType)
//:指定请求的Accept头信息;
MockHttpServletRequestBuilder accept(MediaType... mediaTypes)/MockHttpServletRequestBuilder accept(String... mediaTypes)
//:指定请求Body体内容;
MockHttpServletRequestBuilder content(byte[] content)/MockHttpServletRequestBuilder content(String content)
//:请求传入参数
MockHttpServletRequestBuilder param(String name,String... values)
//:指定请求的Cookie;
MockHttpServletRequestBuilder cookie(Cookie... cookies)
//:指定请求的Locale;
MockHttpServletRequestBuilder locale(Locale locale)
//:指定请求字符编码;
MockHttpServletRequestBuilder characterEncoding(String encoding)
//:设置请求属性数据;
MockHttpServletRequestBuilder requestAttr(String name, Object value)
//:设置请求session属性数据;
MockHttpServletRequestBuilder sessionAttr(String name, Object value)/MockHttpServletRequestBuilder sessionAttrs(Map<string, object=""> sessionAttributes)
//指定请求的flash信息,比如重定向后的属性信息;
MockHttpServletRequestBuilder flashAttr(String name, Object value)/MockHttpServletRequestBuilder flashAttrs(Map<string, object=""> flashAttributes)
//:指定请求的Session;
MockHttpServletRequestBuilder session(MockHttpSession session)
// :指定请求的Principal;
MockHttpServletRequestBuilder principal(Principal principal)
//:指定请求的上下文路径,必须以“/”开头,且不能以“/”结尾;
MockHttpServletRequestBuilder contextPath(String contextPath)
//:请求的路径信息,必须以“/”开头;
MockHttpServletRequestBuilder pathInfo(String pathInfo)
//:请求是否使用安全通道;
MockHttpServletRequestBuilder secure(boolean secure)
//:请求的后处理器,用于自定义一些请求处理的扩展点;
MockHttpServletRequestBuilder with(RequestPostProcessor postProcessor)
MockMultipartHttpServletRequestBuilder
//:指定要上传的文件;
MockMultipartHttpServletRequestBuilder file(String name, byte[] content)/MockMultipartHttpServletRequestBuilder file(MockMultipartFile file)
ResultActions
//:添加验证断言来判断执行请求后的结果是否是预期的;
ResultActions andExpect(ResultMatcher matcher)
//:添加结果处理器,用于对验证成功后执行的动作,如输出下请求/结果信息用于调试;
ResultActions andDo(ResultHandler handler)
//:返回验证成功后的MvcResult;用于自定义验证/下一步的异步处理;
MvcResult andReturn()
ResultMatcher/MockMvcResultMatchers
//:请求的Handler验证器,比如验证处理器类型/方法名;此处的Handler其实就是处理请求的控制器;
HandlerResultMatchers handler()
//:得到RequestResultMatchers验证器;
RequestResultMatchers request()
//:得到模型验证器;
ModelResultMatchers model()
//:得到视图验证器;
ViewResultMatchers view()
//:得到Flash属性验证;
FlashAttributeResultMatchers flash()
//:得到响应状态验证器;
StatusResultMatchers status()
//:得到响应Header验证器;
HeaderResultMatchers header()
//:得到响应Cookie验证器;
CookieResultMatchers cookie()
//:得到响应内容验证器;
ContentResultMatchers content()
//:得到Json表达式验证器;
JsonPathResultMatchers jsonPath(String expression, Object ... args)/ResultMatcher jsonPath(String expression, Matcher matcher)
//:得到Xpath表达式验证器;
XpathResultMatchers xpath(String expression, Object... args)/XpathResultMatchers xpath(String expression, Map<string, string=""> namespaces, Object... args)
//:验证处理完请求后转发的url(绝对匹配);
ResultMatcher forwardedUrl(final String expectedUrl)
//:验证处理完请求后转发的url(Ant风格模式匹配,@since spring4);
ResultMatcher forwardedUrlPattern(final String urlPattern)
//:验证处理完请求后重定向的url(绝对匹配);
ResultMatcher redirectedUrl(final String expectedUrl)
//:验证处理完请求后重定向的url(Ant风格模式匹配,@since spring4);
ResultMatcher redirectedUrlPattern(final String expectedUrl)
在对应的Test文件中 ,使用Runwith加载所需的类和方法,使用@InjectMocks修饰需要测试的类,不能是接口(在修饰过程中将@Mock,@Spy等注解属性注入到其中)。使用@Mock修饰当前测试类(也就是@InjectMocks修饰的类)所使用的类。然后正常编写@Test文件就可以了,之后可以将之后的结果进行设定,也就是通过when字段 .thenReturn等方法返回正确的值,然后比对这个值和你预期中的值,最终能够将这一部分代码跑通。
Docker 与 微服务
docker的简介
提供标准化解决方案,系统平滑移植,容器虚拟化技术。开发人员使用docker将代码和相应的配置、环境、版本打包成为一个镜像文件,这些文件被运维人员使用docker引擎直接使用。(代码即是应用,可以直接用)
Docker是基于go语言实现的云开源项目,通过对应用组件的封装,分发,部署,运行等生命周期的管理,是用户的app及其运行环境实现“一次镜像,处处运行”。Docker容器技术基于Linux容器技术,使得Docker容器在所有操作系统上都是一致的,实现了跨平台,跨服务器。
解决了传统虚拟机资源占用多,冗余步骤多,启动慢的缺点,所以docker形成了容器虚拟化技术,容器没有自己的内核并且没有进行硬件虚拟,因此会更为轻便一些
tips:转型开发兼运维工程师DevOps dockerhub——安装docker镜像的仓库
docker实质上是在已经运行的linux下制造了一个隔离的文件环境,所以其必须部署在linux内核上!!!
docker的基本组成:镜像,容器,仓库!对应java中的类模板,实例对象,存放类的地方
也就是镜像(image文件)就是一个只读模板,一个镜像可以创建多个容器(new出来的对象),容器是用镜像创建的运行实例,容器为镜像提供了一个标准隔离的运行环境,可以看作是一个简易的Linux环境,而仓库就是集中存放镜像的地方(例如maven仓库存放各种jar包,github仓库存放各种git项目,而docker仓库存放各种镜像模板,而其中最大的公开仓库就是Docker Hub
docker的结构也是Client—server的结构,就像Oracle一样,Docker守护程序本身就运行主机上,但是需要一个软件通过socket链接从客户端访问,然后守护进程从客户端接收指令并管理运行在主机上的容器。就像需要plsql来操控Oracle数据库一样。
Docker镜像加载原理:
docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS。
**bootfs(boot file system)**主要包含bootloader和kernel, bootloader主要是引导加载kernel, Linux刚启动时会加载bootfs文件系统,在Docker镜像的最底层是引导文件系统bootfs。这一层与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。rootfs (root file system) ,在bootfs之上。包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。
Docker 镜像要采用这种分层结构最大的一个好处就是共享资源,方便复制迁移,就是为了复用。·Docker镜像层都是只读的,容器层是可写的 当容器启动时,一个新的可写层被加载到镜像的顶部。 这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。只有容器层是可写的,容器层下面的所有镜像层都是只读的。
退出容器的两种退出方式:exit(run进去容器,exit退出,容器停止) ctrl+p+q(run进去容器,ctrl+p+q退出,容器不停止)
数据卷的作用就是能够将容器内数据持久化,将其数据独立保存,不会在docker删容器的时候删除其挂载的数据卷 ,数据卷可以在容器之间共享或重用数据,且更改实时生效,它的更改不会包含在镜像的更新中,会一直持续到没有容器使用它。使用挂载:
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录 镜像名 //–privileged=true 是将容器root可以有编辑功能
设计数据卷的访问要求:ro = read only(此时如果宿主机写入内容,可以同步给容器内,容器可以读取到。)
docker run -it --privileged=true -v /宿主机绝对路径目录:/容器内目录:ro 镜像名 //ro表示只读,rw表示可读可写
TestContainer
test-container环境支持(示例):
提示一 : test-container基于Docker,使用test-container前需要安装Docker环境。
提示二 : test-container提供的环境不能应用于生产、只能用于测试环境等场景,它给我们提供了测试需要的各种环境
这是一个支持JUnit测试的Java库。 现在,开发人员可以轻松地在他们的JUnit测试期间启动有用的Docker容器,这些容器可以满足他们的所有需求。
Testcontainer提供了可以装入容器的任何东西的轻量,一次性的实例。 这使得使用Docker容器进行测试变得比以往更加容易。那么,测试容器能提供什么?
- **数据访问层集成测试:**开发人员可以使用自己喜欢的数据库的容器化实例来测试其数据访问代码以实现完全兼容性。 无需复杂的设置过程!
- **应用程序集成测试:**开发人员可以用它在具有相关性(例如数据库,消息队列或Web服务器)的短期测试模式下运行应用程序。
- **UI /验收测试:**开发人员可以使用容器化的Web浏览器进行自动化的UI测试。 每个测试都可以获取浏览器的新实例,而无需担心浏览器状态,插件版本或浏览器自动升级。 甚至还有每个测试环节或失败环节的录像,以确保一切顺利。
Testcontainer已被许多组织使用。 这个开源Java库通常需要Docker v1.10或更高版本才能工作。
Swagger
生成相应接口文档并测试
knife4j是为Java MVC框架继承Swagger生成Api文档的增强解决方式,作为工具可以输出文档和进行测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9nDAqH5k-1661735841515)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220802173223370.png)]
ELK技术栈——可视化日志框架
elk分别是什么
elasticsearch 搜索分析,logstash 数据抽取,kibana数据展现,现在还有beats和elastic cloud
es是java开发的,restful接口风格的
beats是轻量级的数据采集器,可替代logstash
数据库做搜索弊端,站内搜索的数据量小,简单搜索,可以使用数据库,但是互联网搜索的话由于数据量太大,需要分库分表。根据词的结构进行分词,将词分开储存为关键词,方便查询和存储
了解搜索技术
搜索引擎的种类
搜索引擎按照功能通常分为垂直搜索和综合搜索。
1、垂直搜索是指专门针对某一类信息进行搜索。
例如:会搜网 主要做商务搜索的,并且提供商务信息。除此之外还有爱看图标网、职友集等。
2、综合搜索是指对众多信息进行综合性的搜索。
例如:百度、谷歌、必应、搜狗、360搜索等。
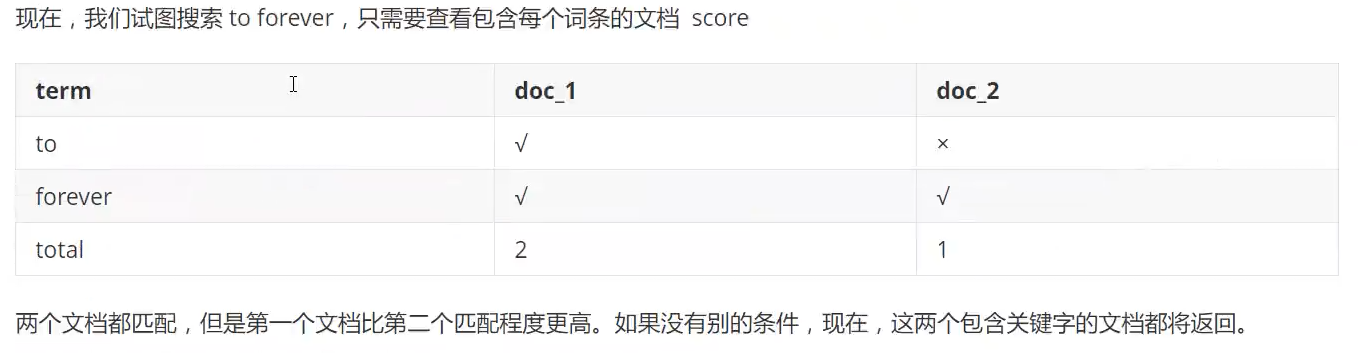
倒排索引
以我的理解就是:我们对数据库原始的数据根据字或词进行索引,创建倒排索引数据区域,记录字或词在文档中出现位置(id列表)。
用户有查询需求时,先访问倒排索引数据区域(下图),得出文档id列表后,通过文档id即可快速,准确的通过上图找到具体的文档内容。也就是先找到需要查询内容的各个关键字的id位置,然后再根据id拼凑或查询。
es可以进行全文检索,结构化检索和数据分析,近实时(秒级查询)核心概念:近实时(秒级出结果,需要倒排查询表中查询后再排序输出),节点(每个es实例就是一个节点,节点名自动分配,也可以手动配置。文档(es的最小数据单元,就像数据库中的一条记录,通常用json格式显示,多个document存在一个索引里面)索引(相当于数据库中的表)Field字段(相当于数据库中的列)分片(将索引分布式存储在各个服务器上,支持海量数据和高并发,充分利用多台机器的cpu)副本(由于分布式环境下可能出现某个分片宕机,所以对每个分片都要有备份,保证宕机时也能搜索,默认新建索引的时候,就会五分片一副本(共10个分片),所以es集群最少有两台。
get /索引名/type/id 获取内容 或者使用其他restful风格的内容,比如说get post put delect
tips:一般调用接口最常用的两种方式就是GET和POST。两者的区别也很明显,GET请求会将参数暴露在浏览器URL中,而且对长度也有限制。为了更高的安全性,所有接口都采用POST方式请求。
文档(英文小写),默认字段的解析“_index”(“book”)“_type”(“_doc”)“_id”(“1”)
不同的数据要放在不同的索引中,业务人员对订单进行分析,聚合count分组group by
es可以进行局部更新:
1.es内部获取旧文档;2.将传来的文档field更新到旧数据(内存),将旧文档标记为delete,创建新文档
es的高并发下问题:
线程1,2之间没有明显的前后顺序,而造成两次读取在库中只显示一次读取。使用悲观锁和乐观锁解决高并发问题
悲观锁常见于关系型数据库mysql和oracle也就是说线程1进行时,数据是锁住的,线程2无法读取到数据直至线程1完成后。(行级锁,表级锁,读锁和写锁)
乐观锁没有锁的概念,一般使用版本来控制,也就是说进程获取数据时也会获取版本信息,返回时将版本号+1,这样另一进程读取时只能读取版本号+1的数据,才能使用数据修改数据。
悲观锁的优点是方便,对程序来讲不透明不需要额外操作,缺点是并发能力非常弱。乐观锁:优点是并发能力高,不给数据加锁,所以支持多线程操作。缺点:麻烦。每次都需要对比版本号,在高并发情况下,重复次数会很多。
在es集群的后台,主从同步是异步多线程的,也就是说各个请求时乱序的,但是es内部的主从同步也是基于版本号的 ,所以如果后面新版本的线程如果先到了执行之后,原本旧版本使用的线程就不会再被执行了。
ElastciSearch
Elaticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用lava开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用
ES安装
提前说明:Elaticsearch基于java1.8以上使用 我们需要安装客户端与界面工具 Elaticsearch的版本要与java的jar包依赖对应
解压即可使用

启动elasticsearch.bat 访问 127.0.0.1:9200
安装可视化插件
-
安装elasticsearch-head插件(需要Node.js环境)
-
解决跨域问题
elasticsearch是面向文档
关系行数据库和elasticsearch客观的对比!
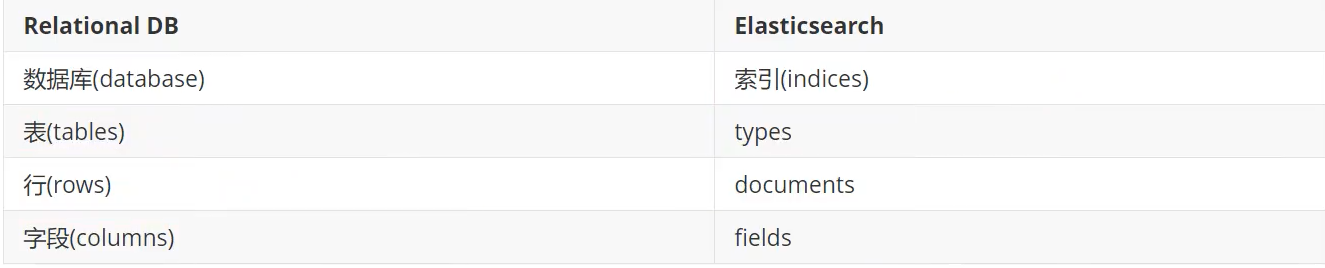
相关概念
物理设计∶
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
默认的集群名称就是elasticsearch
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的一各顺序找到它:索引》类型文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数,实际上它是个字符串。
文档

索引
就是数据库! 索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
如何分片

倒排索引

IK分词器
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,不符合要求
IK提供了两个分词算法:ik_ smart和ik_max_word,其中ik smart为最少切分,ik_max_word为最细粒度划分!
1.下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2.下载完毕后放入elasticsearch插件中即可 注意版本对应
3.启动elasticsearch

4.使用kibana测试,ik smart为最少切分:

ik_max_word为最细粒度划分:

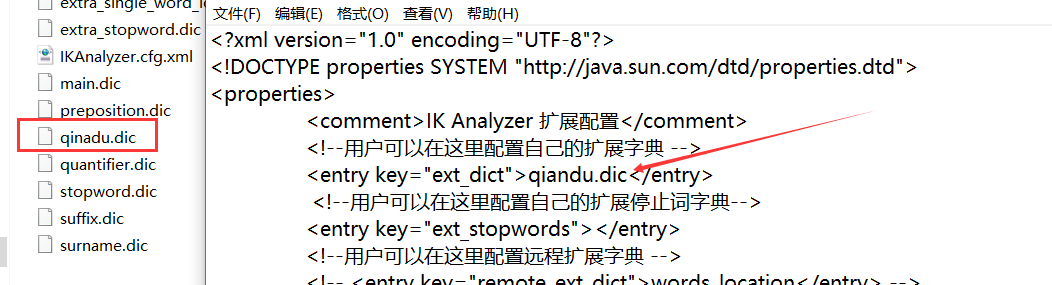
5.有时候分词器不能得出我们想要的,所以需要配置字典(我们需要自己配置分词就在自己定义的dic文件中进行配置即可!)
基本操作
补充:Restflu风格
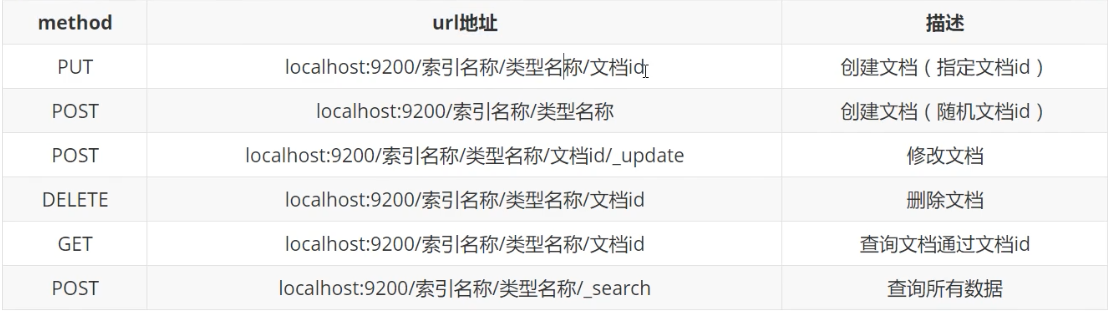
1.创建一个索引
PUT /索引名/类型名()可省略/文档id
{ 请求体 }

2.指定的类型

3.指定字段的类型
# 创建规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
4.查看ES默认规则
#如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型 另外通过命令elasticsearch索引情况!通过 get _cat/ 可以获得es的当前的很多信息
PUT /test3/_doc/1
{
"name": "前度",
"age": 10
}
GET test3
5.修改索引
方法1:提交还是使用PUT即可!然后覆盖!最新办法!
方法2:
POST /test1/type1/1/_update
{
"doc":{
"name": "张三"
}
}
6.删除索引
通过DELETE命令实现删除、根据你的请求来判断是删除索引还是删除文档记录!
DELETE test2
7.简单搜索
GET test1/_search?q=name:前度
_search:代表搜素
?q=xxxx: 搜素条件
8.复杂搜索
情景1:我们之后使用Java操作es ,所有的方法和对象就是这里面的key !

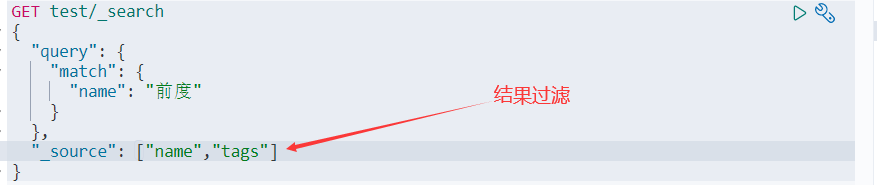
情景2:限制显示的字段信息
情景3:排序

情景4:分页查询

情景5:多条件都满足查询

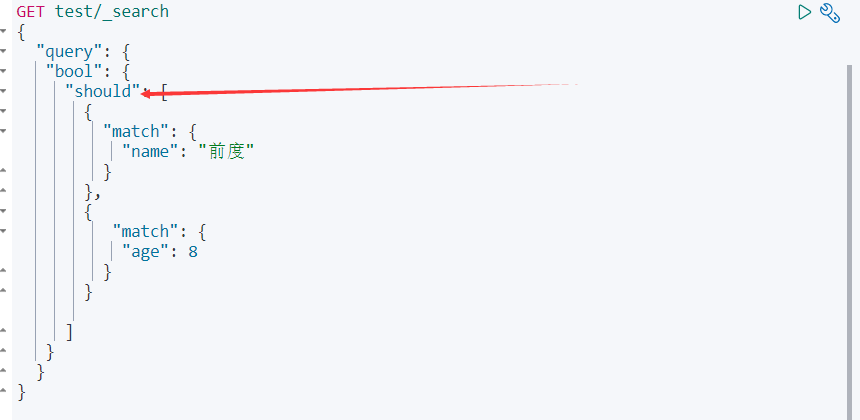
情景6:或(OR)查询
情景7:精确查询


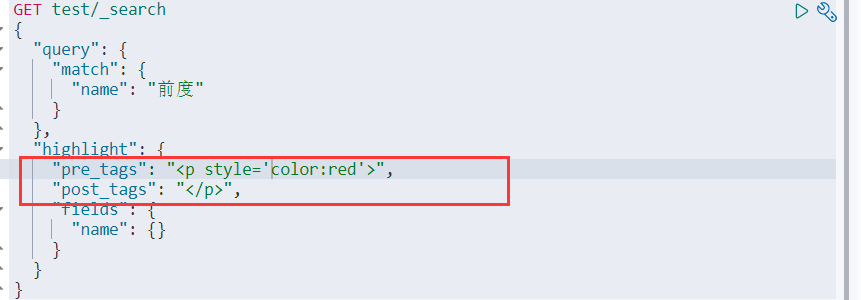
情景8:高亮显示

我们也能自定义高亮显示样式
集成SpringBoot
1.导入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<!--集成SpringBoot只需导入下面这个-->
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
自定义版本:

2.构建与关闭

3.源码


4. 配置
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
));
return client;
}
}
索引 API 操作
1.创建索引
@Autowired
private RestHighLevelClient client;
//索引的创建 Request
@Test
public void creatIndex() throws IOException {
//1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("qiandu_index");
//2、执行请求->请求后获得响应
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
2.判断索引是否存在
//获取索引
public void existsIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("qiandu_index");
//判断索引是否存在
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
}
3.删除索引
//删除索引
public void deleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("qiandu_index");
//判断索引是否存在
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//返回true代表删除
System.out.println(delete.isAcknowledged());
}
文档API操作
首先需要创建实体类
1.添加文档
//添加文档
public void addDocument() throws IOException {
// 创建对象
User user = new User(1, "qiandu");
//创建请求
IndexRequest request = new IndexRequest("qinadu_index");
//设置规则 PUT /qiandu_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
//将数据放入请求 JSON
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(user);
request.source(s, XContentType.JSON);
//发送请求,获取响应结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//返回的状态:create/update
System.out.println(indexResponse.status());
}
2.获取文档,判断是否存在
//获取文档,判断是否存在 GET qiandu_index/1
public void existsDocument() throws IOException {
GetRequest request = new GetRequest("qiandu_index", "1");
//不获取返回的_source的上下文
request.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
3.获取文档的信息
//获取文档的信息
public void getDocument() throws IOException {
GetRequest request = new GetRequest("qiandu_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//打印内容 或者用map
System.out.println(response.getSourceAsString());
//返回全部内容
System.out.println(response);
}
4.更新文档信息
//更新文档信息
public void updateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("qindau_index", "1");
request.timeout("1s");
User user = new User(2, "前度");
ObjectMapper objectMapper = new ObjectMapper();
String s = objectMapper.writeValueAsString(user);
request.doc(s, XContentType.JSON);
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
5.删除文档
//删除文档
public void deleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("qinadu_index", "2");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response.status());
}
6.批量插入数据
//批量插入/删除/更新数据
public void insert() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User(1, "前度1"));
userList.add(new User(2, "前度2"));
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 0; i < userList.size(); i++) {
//批量更新/删除也是如此
bulkRequest.add(
new IndexRequest("qiandu_index")
.id("" + (i + 1))
.source(objectMapper.writeValueAsString(userList.get(i)), XContentType.JSON)
);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//判断是否执行成功 返回false表示成功
System.out.println(response.hasFailures());
}
7.查询
//查询
public void query() throws IOException {
SearchRequest request = new SearchRequest("qiandu_index");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//设置高亮显示
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<p style=' color : red '");
highlightBuilder.postTags("</p>");
highlightBuilder.field("name");
highlightBuilder.requireFieldMatch()
TermQueryBuilder termQuery = QueryBuilders.termQuery("name", "前度");
sourceBuilder.query(termQuery).highlighter(highlightBuilder);
//设置超时
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(sourceBuilder);
//执行请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//返回的所有数据都在hits中
System.out.println(response.getHits());
//打印
for (SearchHit document : response.getHits().getHits()) {
//原结果
System.out.println(document.getSourceAsMap());
Map<String, HighlightField> highlightFields = document.getHighlightFields();
//得到高亮的字段
HighlightField field = highlightFields.get("name");
//原来的结果
Map<String, Object> sourceAsMap = document.getSourceAsMap();
//解析高亮的字段,替换原来的字段
if (field != null) {
Text[] fragments = field.fragments();
String n_field = "";
for (Text text : fragments) {
n_field += text;
}
sourceAsMap.put("name", n_field);
}
//sourceAsMap放入list中
}
}
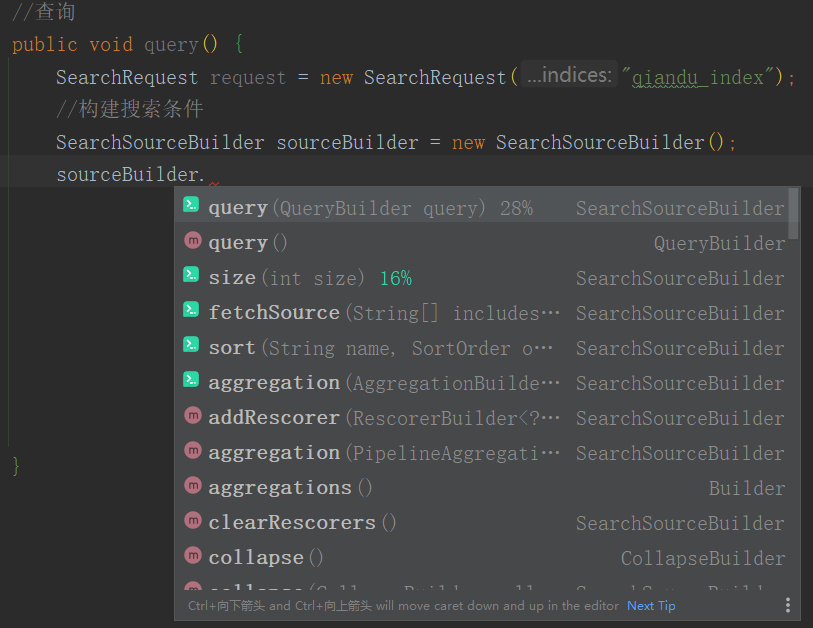
简单使用

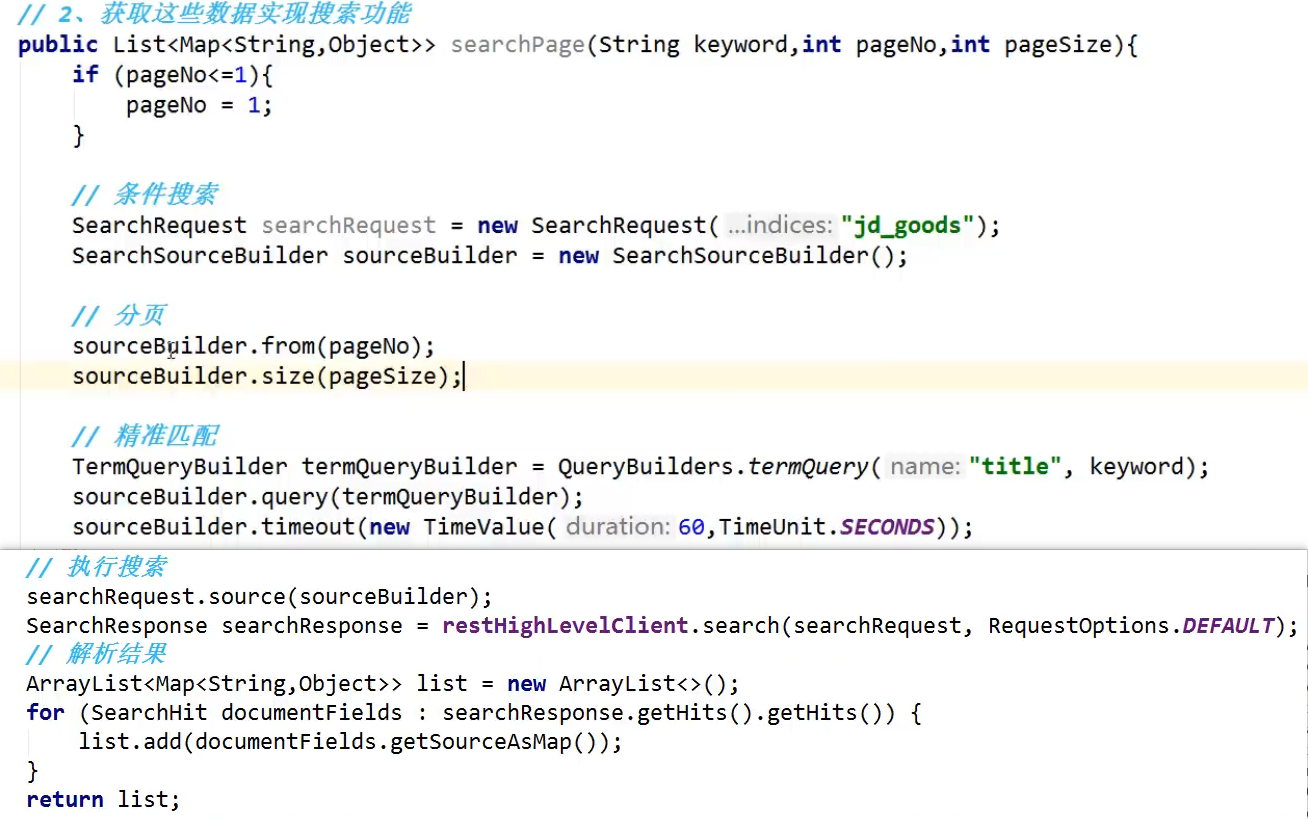
java IDEA快捷键
1 查看接口的实现类:Ctrl+Alt+B
2 返回上/下个光标地方:Alt+<- 和 Alt±>
3 查看Java方法调用树(被调/主调):Ctrl+Alt+H
4 查看表达式、变量、方法参数的传递关系:主菜单中选择Analyze | Dataflow from/to Here
5 查看类继承关系图:Ctrl+Alt+U
6 查看当前类的继承树:Ctrl+H
7 查看定义的变量在哪里被调用:Ctrl+Alt+F7
8 查看一个类中有什么方法:Alt+7 或 点左侧边栏Structure
DTO,VO,Entity的区别
1、entity 里的每一个字段,与数据库相对应,
2、vo 里的每一个字段,是和你前台 html 页面相对应,
3、dto 这是用来转换从 entity 到 vo,或者从 vo 到 entity 的中间的东西 。(DTO中拥有的字段应该是entity中或者是vo中的一个子集)
举个例子:
你的html页面上有三个字段,name,pass,age
你的数据库表里,有两个字段,name,pass , 注意没有 age。
而你的 vo 里,就应该有下面三个成员变量 ,因为对应 html 页面上三个字段 。
private string name;
private string pass;
private string age;
这个时候,你的 entity 里,就应该有两个成员变量 ,因为对应数据库表中的 2 个字段 。
private string name;
private string pass;
举个例子:业务经理让你做这样一个业务“年龄大于 20 的才能存入数据库,这个时候,你就要用到 dto 了,
1)你要先从页面上拿到 vo,然后判断 vo 中的 age 是不是大于 20。
2)如果大于 20,就把 vo 中的 name 和 pass 拿出来,放到 dto 中。
3)然后在把 dto 中的 name 和 pass 原封不动的给 entity,然后根据 entity 的值,在传入数据库。
一站式运维管理工具平台 OCP
OCP 是 OceanBase 一个一站式运维管控平台。
OCP的主要功能分为以下三个部分:
① OceanBase运维
OceanBase集群的安装部署和日常运维。
租户管理。
Database 管理。
OceanBase 相关生态工具的运维,目前已经支持 Obproxy。
主机和软件包的管理, 是最基础的运维能力,为运维 OceanBase 提供支持。
② OceanBase 监控
Metric监控指标,包括 OceanBase 和 Obproxy 的监控指标。
SQL 统计分析,慢 SQL 分析。
基于监控指标/日志的报警。
③ 元数据查询服务
存储并实时更新 OceanBase 的rootservice地址。
提供给其他组件查询 OceanBase 的rootservice地址。
记录 ObProxy 和 OceanBase 的关联关系。这是在前面基础上做的一个能力。
OCP 的应用场景
① 内部使用:比如蚂蚁内部、阿里集团内部很多机器需要管理,需要标准化管理的平台来支持大规模的管理,让 DBA 专注于更有价值的事。
② 独立输出:为企业用户提供企业级的管理服务。
③ 云上使用:将 OceanBase 以云服务的方式提供给用户。
OceanBase
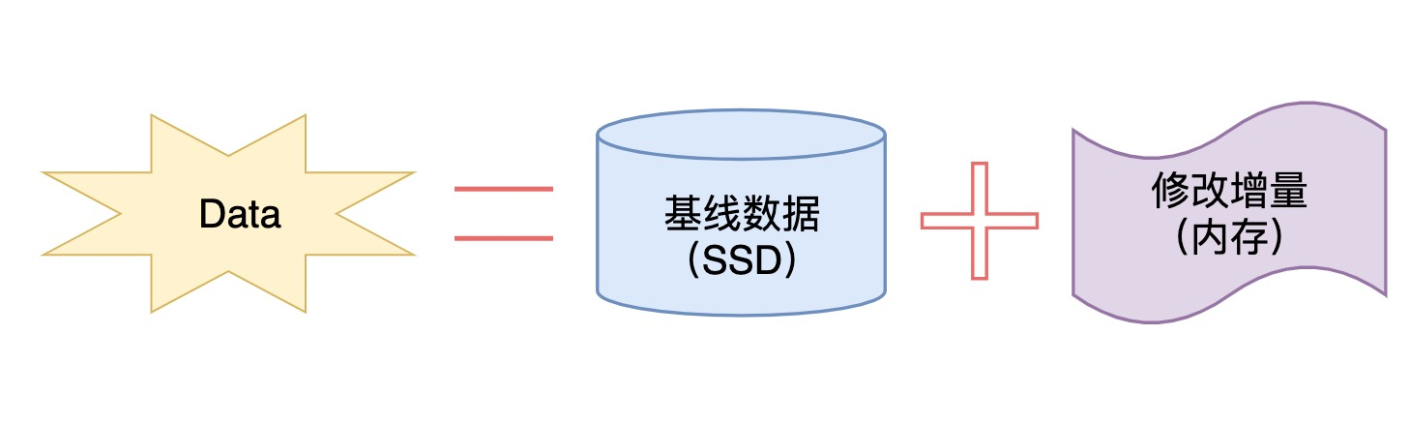
OceanBase本质上是一个基线加增量的存储引擎,跟关系数据库差别很大。 存储机制是LSM树(Log-Structured Merge Tree,日志结构合并树),这也是大多数NoSQL使用的存储机制。OceanBase采用了一种读写分离的架构,把数据分为基线数据和增量数据,其中增量数据放在内存里(MemTable),基线数据放在SSD盘(SSTable)。虽然不是刻意设计的,但OceanBase确实比传统数据库更适合像双十一、秒杀以及优惠券销售等短时间突发大流量的场景。
短时间内大量用户涌入,短时间内业务流量非常大,数据库系统压力非常大
一段时间(几秒钟、几分钟、或半个小时等)后业务流量迅速或明显回落
OceanBase是“基线数据(硬盘)”+“修改增量(内存)”的架构,如下图所示。
也就是**在新近的增删改的时候,会保存在内存中,所以性能会非常高,而要是执行查询的操作的时候,数据可能在硬盘中有元数据,在内存中还有更新后的数据,所以需要把两个数据合并获得新版本,再返回数值。**读数据的时候,数据可能会在内存里有更新过的版本,在持久化存储里有基线版本,需要把两个版本进行合并,获得一个最新版本。同时在内存实现了Block Cache和Row cache,来避免对基线数据的随机读。当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘(称为转储,又叫minor freeze)。同时每天晚上的空闲时刻,系统也会自动每日合并(简称合并,major freeze)。
OB为何采用这种特殊架构,简要来说,就是基于这样一条理论基础——尽管数据库本身的数据量越来越大,记录数越来越多,但每天的增删改数据量并不大,仅仅只占数据库总量一个很小的比例。 这个情况不只是对支付宝的支付数据,对其它大部分数据库实际应用情况也适用,是OB建立上述存储引擎的重要理论基础。
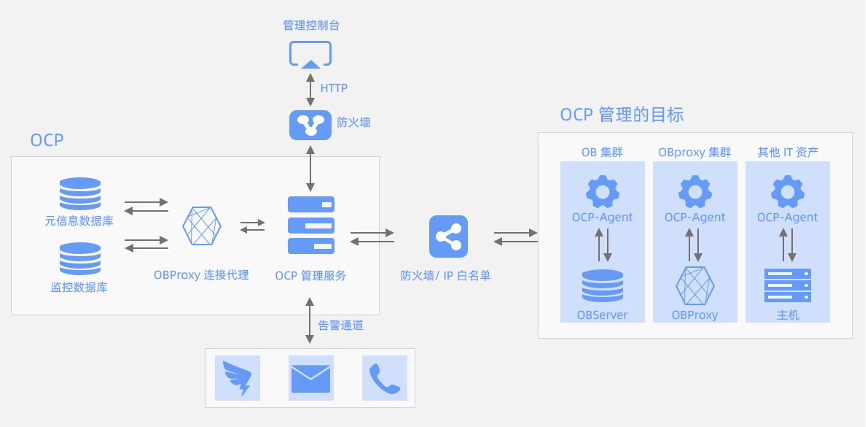
上图为 OCP 的系统架构
OCP 的系统架构的主要模块有三:
① OCP 管理服务:它包括一个由 Java 实现的应用程序,实现 OCP 平台的主要逻辑。它会与其他组件交互,对外提供 http服务。管理控制台提供给用户前端页面进行交互,其他系统也可以通过 open api 直接调用 OCP。
② 数据库存储:包括元信息数据库和监控数据库。其中元信息数据库存储 OCP 管理资源的记录,监控数据库存储 OCP 采集的一些监控指标,包括采集到的原始值以及计算后的统计数据。
③ OCP-Agent:它部署在每个 OCP 管控的主机上,提供两种能力。首先,提供运维接口,OCP 需要进行的运维操作通过调用 OCP-Agent 来实现,也通过这种方式,实现跨平台的能力;另外,提供监控能力,包括以服务的形式通过 Prometheus 协议提供 metric 数据,以及主动上报 SQL 相关的数据。
java缓存机制
1.缓存是计算机上的原始数据的复制集,缓存的使用与应用场景密切相关,在不同的场景上会有不同的意义
2.缓存的目的是想通过提高服务的性能从而提高应用的用户体验
3.系统性能的指标一般包括:响应时间、延迟时间、吞吐量、并发用户数量和资源利用率等几个方面
吞吐量:系统在单位时间内处理的请求的数量
缓存的原理与基本概念:
(1)缓存:
用于协调两者数据传输速度差异的结构,均可称之为Cache
<1>是用来协调CPU与主存之间存取速度的差异而设置的
<2>CPU的工作速度高,但内存的工作速度相对较低,为了解决这个问题,通常使用缓存
<3>缓存的存取速度介于CPU和主存之间
<4>缓存核心就是用空间换时间
<5>常见的应用包括CPU缓存、操作系统缓存、本地缓存、分布式缓存、HTTP缓存、数据库缓存等
<6>实现的难点就在于清空策略的实现,比较合理的思路就是定时回收与即时判断数据是否过期相结合
(2)缓存相关概念
<1>命中率:指请求次数与正确返回结果次数的比例,其影响因素包括数据实时性
1.提高缓存命中率,可以对缓存分层,分为全局缓存,二级缓存
2.他们是存在继承关系的,全局缓存可以有二级缓存来组成
<2>最大元素:缓存中可以存放的元素的最大数量
<3>清空策略:FIFO,最先进入缓存的数据在空间不够时会被优先清理;
LFU一直以来最少被使用的元素会被清理,可以给缓存元素设置一个计数器实现;
LRU最近最少使用的缓存元素会被清理,可以通过一个时间戳来讲最近未使用数据清除
<4>预热策略:全量预热,一开始就加载全部数据,适用于不怎么变化的数据(地区数据);
增量预热,查询不到时从数据源取出放入缓存
(3)缓存相关问题
<1>缓存穿透:
1.一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)
2.若key对应的value是一定不存在的,该key并发请求量很大,会直接去后端查找。这就叫做缓存穿透
3.解决方法包括:将查询结果为空的情况也进行缓存,
缓存时间设置短一点,并在该key对应的数据insert之后清理缓存, 对一定不存在的key进行过滤。
<2>缓存雪崩:
1.当缓存服务器重启或者大量缓存集中在某一个时间段失效的现象叫做缓存雪崩,
2.缓存雪崩后,这时会直接去后端查询,给后端系统(比如DB)带来很大压力
3.解决方案包括:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量,不同的key设置不同的过期时间,让缓存失效的时间点尽量均匀,做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
<3>缓存一致性:
1.通过锁解决一致性问题
2.采用延时双删策略(双删指的是对缓存进行2次删除操作),具体的步骤就是:先删除缓存; 再写数据库 ; 休眠500毫秒;再次删除缓存
3.设置缓存过期时间
4.结合双删策略+缓存超时设置:这样最差的情况是在超时时间内数据存在不一致,而且又增加了写请求的耗时
5.异步更新缓存(基于订阅binlog的同步机制)
5.1.MySQL binlog增量订阅消费+消息队列+增量数据更新到缓存(主要指:Redis)
5.2.实现步骤如下:读数据-热数据基本都在缓存
写数据-增删改都是操作MySQL
更新缓存数据:MySQ的数据操作binlog,来更新到缓存
5.3.缓存(Redis)更新:数据操作主要分为两大块:全量(将全部数据一次写入到缓存(redis))
增量(实时更新)
5.4.增量,指的是mysql的update、insert、delate变更数据
5.5.读取binlog后分析 ,利用消息队列,推送更新各台的缓存(redis)数据
5.5.1.MySQL中产生了新的写入、更新、删除等操作
5.5.2.就可以把binlog相关的消息推送至缓存(Redis)
5.5.3.缓存(Redis)再根据binlog中的记录,对缓存(Redis)进行更新
5.5.4.这种机制,很类似MySQL的主从备份机制,因为MySQL的主备也是通过binlog来实现的数据一致性
5.6.消息推送工具可以采用第三方:kafka、rabbitMQ等来实现推送更新缓存(Redis)
(4)分布式缓存系统需要注意缓存一致性、缓存穿透和雪崩、缓存数据的清理等问题
(5)为了保证系统的HA,缓存系统可以组合使用两套存储系统(memcache,redis)
java缓存种类
在java应用中通常由两类缓存:进程内缓存;进程外缓存
(1)进程内缓存(本地缓存):使用java应用虚拟机内存的缓存
<1>在一个JVM中,快速且可用性高
<2>会存在多态负载均衡主机数据不一致的问题
<3>适合最常用且不易变的数据
(2)进程外缓存:现在常用的各种分布式缓存
<1>扩展性强,而且相关的方案多,比如Redis Ehcache 等
<2>通常来说,从数据库读取一条数据需要10ms,从分布式缓存读取则只需要0.5ms左右
<3>本地缓存则只需要10μs
数据库的缓存机制
1、重要性
数据库通常是企业应用系统最核心的部分
数据库保存的数据量通常非常庞大
数据库查询操作通常很频繁,有时还很复杂
以上原因造成数据库查询会引起非常频繁的磁盘I/O读取操作,迫使CPU挂起等待,数据库性能极度低下
2、缓存策略
a、Query Cache
以SQL作为key值缓存查询结果集
一旦查询涉及的表记录被修改,缓存就会被自动删除
设置合适的Query Cache会极大提高数据库性能
Query Cache并非越大越好,过大的Qquery Cache会浪费内存。
MySQL: query_cache_size= 128M
b、Data Buffer
data buffer是数据库数据在内存中的容器
data buffer的命中率直接决定了数据库的性能
data buffer越大越好,多多益善
MySQL的InnoDB buffer:innodb_buffer_pool_size = 2G
MySQL建议buffer pool开大到服务器物理内存60-80%
Spring的缓存
当程序第一次调用该类的实例的某个方法时,Spring缓存机制会将该方法返回的数据放入指定缓存区。以后程序调用该类的实例的任何方法时,只要传入的参数相同,Spring将不会真正执行该方法,而是直接利用缓存区中的数据。
EhCache缓存实现的配置
为了使用EhCache,需要在应用的类加载路径下添加一个ehcache.xml配置文件。例如,使用如下echcache.xml文件。在对应的配置文件中分配好缓存和缓存的内容,在调用时可以更加快捷地直接使用缓存中的数据,提高性能。
使用@Cacheable执行缓存
@Cacheable可用于修饰类或修饰方法,当使用@Cacheable修饰类时,用于告诉Spring在类级别上进行缓存————程序调用该类的实例的任何方法时都需要缓存,而且共享同一个缓存区;当使用@Cacheable修饰方法时,用于告诉Spring在方法级别上进行缓存————只有当程序调用该方法时才需要缓存(可进行方法级别的缓存)之后使用@CacheEvict清除缓存,被@CacheEvict注解修饰的方法可用于清除缓存。
Redis
NoSQL数据库
**(not only sql 非关系型数据库key-value)**比如redis,mongoDB,Neo4j图关系型数据库。
用来解决性能问题
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C7wjO2Qc-1661735841516)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220815143305867.png)]
1.使用nosql作为单独一层,在进行分布式访问的时候可以存储session信息,避免重复存储session或者由于分布式导致查询不连贯,减小对cpu和内存的使用
2.使用nosql作为缓存数据库,减小直接对数据库进行的io读取
适用于对数据高并发的读写,对海量数据的读写,对数据高可扩展性的使用,不适用于需要事务支持的(不具备ACID特性),处理结构化存储查询。
对于用不着sql或者用了sql也不行的情况下,可以考虑用nosql。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DpClbElK-1661735841517)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220815155536952.png)]
redis是单线程+多路IO复用技术,单线程是指都找黄牛买票,黄牛买票的过程是单线程,多路复用是指每个人cpu都会一直进行而不会等待买票的操作。
相较于memcache的串多线程+锁效率要更高,同时相比来说支持更多的数据类型,支持持久化。
redis的数据类型
redis的key-value
针对key的操作:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W3n66P7p-1661735841517)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220815162740583.png)]
字符串类型(value值的类型):
redis的操作是原子操作,也就是说一旦开始就一直运行到结束,中间不会有任何context switch(切换到另一线程),中断只能发生于指令之间。也就是说当我们设置一个或者多个key-value对,当且仅当所有给定的key都不存在时才可以设置成功,如果有一个失败则全都设置失败。小于1m时扩容是翻倍扩容,大于1m时是每次增加1m的扩容方式,但最大不会超过512m。
redis列表(List):
也就是说key-value键值对中,key是唯一的,而value则包含多个名字,呈现出单键多值的状态。
redis列表是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边),其底层是一个双向链表,对两端操作性能很高,通过索引下标操作中间的节点性能较差。 常用的指令lpush和rpush分别是从左边和右边头插入值,而lpop和rpop则是从左右边突出一个值,值吐光了键就不存在了。rpoplpush,右边吐出一个值放在列表左边
****\常用命令\****
lpush/rpush <key><value1><value2><value3> .... 从左边/右边插入一个或多个值。
lpop/rpop <key>从左边/右边吐出一个值。值在键在,值光键亡。
rpoplpush <key1><key2>从<key1>列表右边吐出一个值,插到<key2>列表左边。
lrange <key><start><stop>
按照索引下标获得元素(从左到右)
lrange mylist 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
lindex <key><index>按照索引下标获得元素(从左到右)
llen <key>获得列表长度
linsert <key> before <value><newvalue>在<value>的后面插入<newvalue>插入值
lrem <key><n><value>从左边删除n个value(从左到右)
lset<key><index><value>将列表key下标为index的值替换成value
set集合
redis的set是String的无序集合,它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
常用指令
sadd <key><value1><value2> .....
将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers <key>取出该集合的所有值。
sismember <key><value>判断集合<key>是否为含有该<value>值,有1,没有0
scard<key>返回该集合的元素个数。
srem <key><value1><value2> .... 删除集合中的某个元素。
spop <key>***\*随机从该集合中吐出一个值。\****
srandmember <key><n>随机从该集合中取出n个值。不会从集合中删除 。
smove <source><destination>value把集合中一个值从一个集合移动到另一个集合
sinter <key1><key2>返回两个集合的交集元素。
sunion <key1><key2>返回两个集合的并集元素。
sdiff <key1><key2>返回两个集合的***\*差集\****元素(key1中的,不包含key2中的)
Redis哈希Hash
Redis hash是一个键值对集合,是一个String类型的field和value的映射表,hash特别适合用于存储对象,类似于java中的map<String,Object>
常用指令
hset <key><field><value>给<key>集合中的 <field>键赋值<value>
hget <key1><field>从<key1>集合<field>取出 value
hmset <key1><field1><value1><field2><value2>... 批量设置hash的值
hexists<key1><field>查看哈希表 key 中,给定域 field 是否存在。
hkeys <key>列出该hash集合的所有field
hvals <key>列出该hash集合的所有value
hincrby <key><field><increment>为哈希表 key 中的域 field 的值加上增量 1 -1
hsetnx <key><field><value>将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
zset
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个****评分(score)****,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。zset底层使用了两个数据结构,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到对应的score值。第二个使用的数据结构是跳跃表,目的在于给元素value排序,根据score的范围获取元素列表。
redis配置文件以及Springboot相关依赖配置文件
- 在pom.xml文件中引入redis相关依赖
<!-- redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId**>
</dependency>
<!-- spring2.X集成redis所需common-pool2-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.0</version>
</dependency>
2.application.properties配置redis配置
#Redis 服务器地址
spring.redis.host=192.168.140.136
#Redis服务器连接端口
spring.redis.port=6379
#Redis数据库索引(默认为0)
spring.redis.database= 0
#连接超时时间(毫秒)
spring.redis.timeout=1800000
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=20
#最大阻塞等待时间(负数表示没限制)
spring.redis.lettuce.pool.max-wait=-1
#连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=5
#连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
3.添加redis配置类
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setConnectionFactory(factory);
//key序列化方式
template.setKeySerializer(redisSerializer);
//value序列化
template.setValueSerializer(jackson2JsonRedisSerializer);
//value hashmap序列化
template.setHashValueSerializer(jackson2JsonRedisSerializer);
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
RedisSerializer<String> redisSerializer = new StringRedisSerializer();
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
//解决查询缓存转换异常的问题
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
// 配置序列化(解决乱码的问题),过期时间600秒
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofSeconds(600))
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(jackson2JsonRedisSerializer))
.disableCachingNullValues();
RedisCacheManager cacheManager = RedisCacheManager.builder(factory)
.cacheDefaults(config)
.build();
return cacheManager;
}
}
4、测试一下
RedisTestController中添加测试方法
@RestController
@RequestMapping("/redisTest")
public class RedisTestController {
@Autowired
private RedisTemplate redisTemplate;
@GetMapping
public String testRedis() {
//设置值到redis
redisTemplate.opsForValue().set("name","lucy");
//从redis获取值
String name = (String)redisTemplate.opsForValue().get("name");
return name;
}
}
Redis_事务_锁机制(例子:秒杀)
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。Redis事务的主要作用就是串联多个命令防止别的命令插队。
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,直到输入Exec后,Redis会将之前的命令队列中的命令依次执行。组队的过程中可以通过discard来放弃组队。 (在输入指令前先输入Multi等关键字)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-de1NM1xX-1661735841518)(file:///C:\tmp\ksohtml13548\wps1.jpg)]
事务的错误处理
组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FCs0TdKg-1661735841518)(file:///C:\tmp\ksohtml13548\wps2.png)]
如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sOYYVtjP-1661735841519)(file:///C:\tmp\ksohtml13548\wps3.png)]
Redis事务三特性
单独的隔离操作
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
没有隔离级别的概念
队列中的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
不保证原子性
事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
秒杀改进过程:
1.正常设计,使用ab模拟并发测试,会出现超卖现象2.加入乐观锁,可以解决超卖但是会出现遗留库存或者连接超时的问题,3.连接池可以解决超时问题4.使用LUA脚本解决库存依赖问题。
Redis持久化问题
两种方法RDB(Redis DataBase) AOF(Append Of File)
RDB(Redis DataBase)
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。 整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。l Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
l 在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OIRHHk5v-1661735841519)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220816161835729.png)]
AOF(Append Only File)是什么
以****日志*的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(*读操作不记录****), *只许追加文件但不可以改写文件*,redis启动之初会读取该文件重新构建数据,换言之,redis 重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作
AOF持久化流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gVMFYVRe-1661735841519)(C:\Users\MI\AppData\Roaming\Typora\typora-user-images\image-20220816161821641.png)]
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
泛泛性其他问题
redis是什么?
Redis是一个基于内存、可持久化、键值对模式的NoSQL数据库
优点是速度快(单线程,IO多路复用)、高性能、高可靠、可持久化(rdb,aof),支持丰富的数据结构
redis能用来做什么
分布式锁
主要利用redis的setnx命令进行,setnx:“set if not exists”,如果不存在则成功
其他实现方式:数据库、zookeeper
缓存
由于redis数据放在内存所以访问速度块、支持的数据类型比较丰富,所以redis很适合用来缓存数据
这里一般是做分布式缓存,本地缓存不需要用redis。
其他实现方式:自定义数据结构(例如java里的hashMap)
保存限时数据
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
Redis和Memcache区别
从数据结构上来说
redis在kv模式上,支持5种数据结构,String、list、hash、set、sorted set。
memcache只支持简单的kv存储
从可靠性的角度来说
redis支持持久化,有快照和AOF两种方式,
memcache不支持持久化
从数据一致性来说
memcache和redis都能保证数据一致
从集群方面来说
redis天然支持高可用集群,支持主从,
memcache需要自己实现类似一致性hash的负载均衡算法才能解决集群的问题,扩展性比较低。
从IO角度来说
redis和memecache都是I/O多路复用模型
从线程角度来说
memcahce是多线程,主线程阻塞,多个worker子线程执行读写
redis是单线程,这样虽然不用考虑锁,但是无法利用多核
总结
redis功能更强大,memcahce更快一些
Redis存在线程安全问题吗?
第一个,从Redis 服务端层面。
Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Server上执行的指令,不需要任何同步机制,不会存在线程安全问题。
虽然Redis 6.0里面,增加了多线程的模型,但是增加的多线程只是用来处理网络IO事件,对于指令的执行过程,仍然是由主线程来处理,所以不会存在多个线程通知执行操作指令的情况。
第二个,从Redis客户端层面。
虽然Redis Server中的指令执行是原子的,但是如果有多个Redis客户端同时执行多个指令的时候,就无法保证原子性。
假设两个redis client同时获取Redis Server上的key1, 同时进行修改和写入,因为多线程环境下的原子性无法被保障,以及多进程情况下的共享资源访问的竞争问题,使得数据的安全性无法得到保障。
当然,对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
外链图片转存中…(img-gVMFYVRe-1661735841519)]
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
泛泛性其他问题
redis是什么?
Redis是一个基于内存、可持久化、键值对模式的NoSQL数据库
优点是速度快(单线程,IO多路复用)、高性能、高可靠、可持久化(rdb,aof),支持丰富的数据结构
redis能用来做什么
分布式锁
主要利用redis的setnx命令进行,setnx:“set if not exists”,如果不存在则成功
其他实现方式:数据库、zookeeper
缓存
由于redis数据放在内存所以访问速度块、支持的数据类型比较丰富,所以redis很适合用来缓存数据
这里一般是做分布式缓存,本地缓存不需要用redis。
其他实现方式:自定义数据结构(例如java里的hashMap)
保存限时数据
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
Redis和Memcache区别
从数据结构上来说
redis在kv模式上,支持5种数据结构,String、list、hash、set、sorted set。
memcache只支持简单的kv存储
从可靠性的角度来说
redis支持持久化,有快照和AOF两种方式,
memcache不支持持久化
从数据一致性来说
memcache和redis都能保证数据一致
从集群方面来说
redis天然支持高可用集群,支持主从,
memcache需要自己实现类似一致性hash的负载均衡算法才能解决集群的问题,扩展性比较低。
从IO角度来说
redis和memecache都是I/O多路复用模型
从线程角度来说
memcahce是多线程,主线程阻塞,多个worker子线程执行读写
redis是单线程,这样虽然不用考虑锁,但是无法利用多核
总结
redis功能更强大,memcahce更快一些
Redis存在线程安全问题吗?
第一个,从Redis 服务端层面。
Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Server上执行的指令,不需要任何同步机制,不会存在线程安全问题。
虽然Redis 6.0里面,增加了多线程的模型,但是增加的多线程只是用来处理网络IO事件,对于指令的执行过程,仍然是由主线程来处理,所以不会存在多个线程通知执行操作指令的情况。
第二个,从Redis客户端层面。
虽然Redis Server中的指令执行是原子的,但是如果有多个Redis客户端同时执行多个指令的时候,就无法保证原子性。
假设两个redis client同时获取Redis Server上的key1, 同时进行修改和写入,因为多线程环境下的原子性无法被保障,以及多进程情况下的共享资源访问的竞争问题,使得数据的安全性无法得到保障。
当然,对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









