






第1关:Series对象
知识点
1.pandas的Series对象是可保存任意类型的数据的一维数组,可用一个数组创建Series对象。
data = pd.Series([0.25, 0.5, 0.75, 1.0]) 2.Series对象和Numpy数组的差异:Numpy数组通过隐式定义的整数获取数值,Series对象使用显式定义的索引与数值关联。
In:data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd'])
In:data["a"]
Out:0.253.Series对象是一种可将类型键映射到一组类型值的数据结构,可以直接使用Python字典创建一个Series对象。
population_dict = {'California': 38332521,'Texas': 26448193, 'New York': 19651127,'Florida': 19552860, 'Illinois': 12882135}
population = pd.Series(population_dict) 测试说明
测试输入中的第一行为Series对象中的列索引,第二行为Series对象中每一行的值。
import pandas as pd
a = input() # 输入的是一个字符串,详细数据可查看测试集
b = input()
# 使用任意方法创建一个Series对象,并输出
#********* Begin **********#
a=a.split(",")
b=b.split(",")
output_dict={}
for i in range(len(a)):
output_dict[a[i]]=b[i]
result=pd.Series(output_dict)
print(result)
#********* Begin **********#第2关:Series数据选择
知识点
1.Series对象提供了键值对的映射,可用字典的表达式和方法检测键/索引和值,也可像字典一样修改Series对象的值。
2.Series对象具备和Numpy数组一样的数组数据选择功能,如索引、掩码、花哨索引等操作。
In: import pandas as pd
In: data = pd.Series([0.25, 0.5, 0.75, 1.0], index=['a', 'b', 'c', 'd'])
#将显式索引作为切片
In: data['a':'c']
Out: a 0.25
b 0.50
c 0.75
dtype: float64
#将隐式整数索引作为切片
In: data[0:2]
Out: a 0.25
b 0.50
dtype: float64
#掩码
In: data[(data > 0.3) & (data < 0.8)]
Out: b 0.50
c 0.75
dtype: float64
#花哨索引
In: data[["a","e"]]
Out: a 0.25
e 1.25
dtype: float643.索引器
(1)loc属性:取值和切片都是显式的
(2)iloc属性:取值和切片都是隐式的
编程要求
- 添加一行数据,时间戳
2019-01-29值为320; - 获取
2019-01-04号之后的数据(包含该日期); - 最后筛选值大于
100的数据,得到以下目标Series对象2019-01-06 981 2019-01-11 647 2019-01-17 198 2019-01-20 1698 2019-01-21 7496 2019-01-24 8201 2019-01-29 320 dtype: int64import pandas as pd import numpy as np arr = input() dates = pd.date_range('20190101', periods=25) # 生成时间序列 df = pd.Series(eval(arr),index=dates) #完成编程要求,并输出结果 #********** Begin **********# df[pd.to_datetime('2019-01-29')]=320 #将字符串转换成时间戳 a = df['2019-01-04'::] print(a[a>100]) #********** End **********
第3关:Series方法
编程要求
1.创建一个名为series_a的series数组,当中值为[1,2,5,7],对应的索引为['nu', 'li', 'xue', 'xi']
2.创建一个名为dict_a的字典,字典中包含如下内容{'ting':1, 'shuo':2, 'du':32, 'xie':44}
3.将dict_a字典转化成名为series_b的series数组。
# -*- coding: utf-8 -*-
from pandas import Series,DataFrame
import pandas as pd
def create_series():
'''
返回值:
series_a: 一个Series类型数据
series_b: 一个Series类型数据
dict_a: 一个字典类型数据
'''
# 请在此添加代码 完成本关任务
# ********** Begin *********#
series_a=Series([1,2,5,7],index=['nu','li','xue','xi'])
dict_a={'ting':1,'shuo':2,'du':32,'xie':44}
series_b=Series(dict_a)
# ********** End **********#
# 返回series_a,dict_a,series_b
return series_a,dict_a,series_b
create_series()
第4关:DataFrame对象
知识点
1.DataFrame对象的创建方法
#通过数组创建
pd.DateFrame(array, index=list0, columns=list1) #list表示一个列表
#通过单个Series对象创建
pd.DateFrame(Series,columns=list)
#通过字典列表创建
data = [{'a': i, 'b': 2 * i} for i in range(3)]
pd.DataFrame(data)
2.DataFrame是通用的Numpy数组,是特殊的字典,和Series类似
编程要求
-
将数据转换为
Series对象 然后通过Series对象创建一个DataFrame对象,并输出; -
将数据转换为字典,然后通过字典创建一个
DataFrame对象,并输出;
测试说明
测试输入的第一行为列索引,第二行为第一列数据,第三行为第二列数据。
import pandas as pd
import numpy as np
index = input() # 输入的是一个字符串,用于列索引,详细数据请查看测试集
value1 = input() # DataFrame对象的第一列数据
value2 = input() # DataFrame对象的第二列数据
# 将数据转换为Series对象 然后通过Series对象创建一个DataFrame对象,然后输出
#********** Begin **********#
d1 = {'first': pd.Series(np.array(value1.split(',')), index=np.array(index.split(','))),
'second': pd.Series(np.array(value2.split(',')), index=np.array(index.split(',')))}
df1 = pd.DataFrame(d1)
print(df1)
#********** End **********#
# 将数据转换为字典,然后通过字典创建一个DataFrame对象,然后输出
#********** Begin **********#
d2 = {'first': np.array(value1.split(',')), 'second': np.array(value2.split(','))}
df2 = pd.DataFrame(d2,index=np.array(index.split(',')))
print(df2)
#********** End **********#
第5关:DataFrame对象访问
知识点
1.DataFrame可看作一个由若干Series对象构成的字典,通过对列名进行字典形式的取值获取数据。
2.DataFrame可看成是一个增强版的二维数组,许多数组操作方式都可以用在DataFrame对象上。
编程要求
- 完成下列要求。初始
DataFrame如图所示:
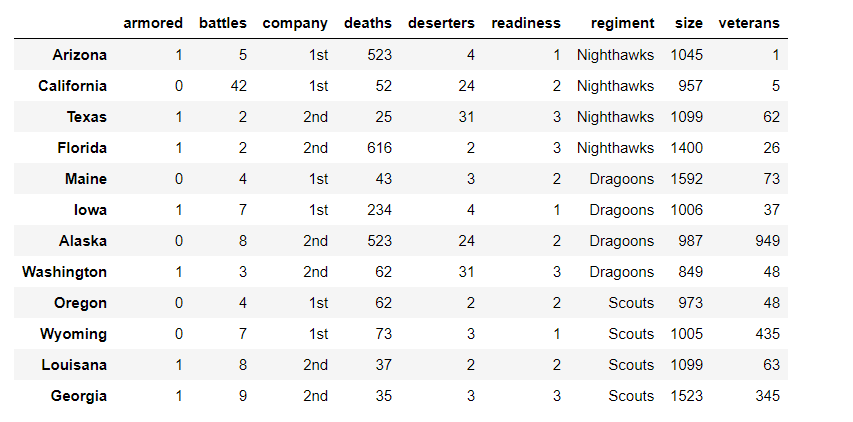
- 根据相关知识介绍的取值方法将初始
DataFrame转换成下图所示DataFrame,并输出:
| Florida | Washington | |
| deaths | 616 | 62 |
| battles | 2 | 3 |
| size | 1400 | 849 |
| veterans | 26 | 48 |
| readiness | 3 | 3 |
| armored | 1 | 1 |
| deserters | 2 | 31 |
import pandas as pd
def demo(raw_data,origin):
df = pd.DataFrame(raw_data,index=origin)
#转换成编程要求所示DataFrame, 并输出
#********** Begin **********#
# df=df.T
# print(df)
data=df.loc[['Florida','Washington']]
data=data.T
result=data.loc[['deaths','battles','size','veterans','readiness','armored','deserters']]
print(result)
#********** End **********#
return result














 3012
3012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









