







一.总结
1.了解了论文中对并行谱聚类算法性能的测试(测试集、比较对象等)
2.了解了第二篇论文的主要工作和核心算法原理
二.学习笔记
1.三组测试集
(1)20个新闻组:包含19974个非空新闻组文档的集合,词汇量为62061,我们将全部数据分为20个簇,并把Arnoldi长度设置为40
(2)RCV1:一个来自Reuters Ltd的804414篇带标签的新闻专线报告的文档。在本次实验中,没有使用具有多个标签的文档,然后得到了分属53个类别的534135篇文档,Arnoldi长度设置为40
(3)PicasaWeb:Picasa是一个供用户上传、分享、管理图片的在线平台。我们收集的数据集由2121863张图片组成,每张图片提取出了144个特征(颜色、纹理、形状等),将全部数据分为1000个簇,Arnoldi长度设置为2000
2.使用稀疏相似矩阵聚类的效果
主要比较了传统的 聚类算法、使用完整相似矩阵的谱聚类算法
和使用稀疏相似矩阵的谱聚类算法
(k值取的100),选用的是测试集一,指标是
,越趋近于1表示聚类效果越好,实验结果如下

可见 不仅节省了相似矩阵存储的空间,聚类效果也更好
以下是 取不同k值时聚类效果的变化图
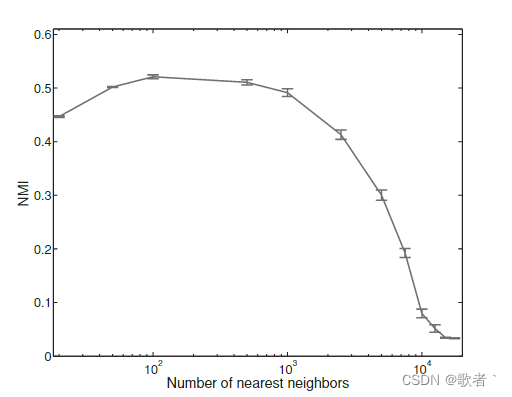
可见k取100左右时聚类效果是最好的
3.其他测试工作
(1)探究在RCV1和PicasaWeb测试集上使用不同数量的机器时,“计算稀疏相似矩阵”这一步的运行时间和加速比(没有和其他算法比较)
(2)探究在RCV1和PicasaWeb测试集上使用不同数量的机器时,“计算特征向量和k-means聚类”这一步(合着)的运行时间和加速比(没有和其他算法比较)
(3)固定机器数量时,在RCV1和PicasaWeb测试集上,加速比和数据集大小的关系(没有和其他算法比较)
(4)在一个专用的数据中心环境下对并行程序进行基准测试,以获得准确的计时(没有和其他算法比较)
4.开源代码
略有修改的代码可在 http://code.google.com/p/pspectralclustering/ 找到
(以下开始是第二篇论文的笔记)
5.基于DML变换的分布式数据上的谱聚类框架
所谓分布式数据,就是指数据集不是在一个机器上,而是存储在多个分布式节点上
DML变换的思想:用一组代表点(码字)来代表整个数据集,可将代表点集视为整个数据集的草图,由于二者相似度高,对代表点集的学习有望于接近对整个数据集的学习
如果数据集不是分布式的,那么引入DML变换的作用仅仅是加快计算速度,此外DML变换还能应用于分布式数据上的谱聚类,具体实现有三个步骤:
(1)对每个分布式节点存储的数据进行DML转换
(2)收集所有节点转换后得到的码字,并对码字进行谱聚类
(3)将谱聚类得到的聚类成员填充回各个分布式节点
这种方法的优点还有:
(1)消除了在分布式节点间传输大量数据的需要,只需要传输转换后的码字
(2)由于没有传输原始数据,数据的隐私性得到了保证
(3)因为谱聚类只需要在码字集合上进行,所以整体计算量大大减少
(4)因为DML和聚类成员的恢复是在单个节点上进行的,所以这一步可以并行完成
6.DML转换的两种具体实现
(1)k-means聚类实现
当用k-means算法实现DML时,得到的聚类中心的所有点的质心就是一个个的代表点,每个分布式节点各自进行k-means聚类,但注意每个节点的k值可能是不同的,唯一的要求是k应该足够大
(2)随机投影树实现
K-D树的生成过程:
把每一个分布式节点的所有数据点的集合对应一个根节点,对每一个数据点,根据它的坐标和中间截断点的大小关系将其划分到根节点的左子节点或右子节点中,对子节点再递归地进行上述步骤,直到满足某个条件。生成结束后,落在同一个叶节点内的数据点被认为是相似的
7.如何对分布式数据实现谱聚类
假设有S个分布式站点。
(1)对于每个站点,单独使用上述两种方法之一实现DML转换,记 为
号分布式站点里的数据的质心组(若采用k-means实现,一个组就是聚类结果的一个簇;若采用rptree,一个组里的数据点就是位于同一个叶节点里的数据点),每一个质心组里的数据点的质心就是一个码字。
(2)对码字实行谱聚类
(3)向S个分布式站点填充聚类成员















 3886
3886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









