






首先,在斯坦福该课程官网下载了作业1(网页版看作业),按照它里面的README.md配置相应的环境,激活conda activate cs224n,进入作业代码jupyter notebook exploring_word_vectors.ipynb
之后,运行了代码开始报错ImportError: cannot import name ‘triu‘ from ‘scipy.linalg‘,找到原因scipy版本问题,1.13.0太高了,于是降低版本就行,参考文章点击此处,我安装的scipy1.11.2也是可以的。(想要安装快速一点,可以使用清华源)
解决完这个问题,又出来Couldn’t reach ‘stanfordnlp/imdb’ on the Hub (ConnectionError),不能连接到github上,所以查询得知,得科学上网,如果还不行,参考这个文章。
最后我还是没能解决,于是用了以前的课程代码,只有数据获取不太一样,作业都是一样的,不影响使用。
第一部分:基于计数的词向量
1.1:实现 dicintct_words

根据题目提示,看一看列表推导式,也提示corpus_words要用sorted排序。还提到要删除重复单词,所以我们用了python sets。

代码里写了他是list类型。
所以答案:
corpus_words = sorted(list(set([word for sentence in corpus for word in sentence])))
num_corpus_words = len(corpus_words)
word for sentence in corpus for word in sentence这句话什么意思呢。比如有下面三句话:
# i love you
# good morning
# i like food
tmp = []
for sentence in corpus:
for word in sentence:
tmp.append(word)
#tmp输出 [i love you good morning i like food]
#用完set变成 (i love you good morning like food)
#把重复的i删除了一个
1.2:实现compute_co_occurrence_matrix

words, n_words = distinct_words(corpus)
#初始化一个全零的矩阵 M,大小为 n_words x n_words
M = np.zeros((n_words, n_words))
word2ind = {word: i for i, word in enumerate(words)}
#创建一个字典 word2ind,它将每个单词映射到其在 words 列表中的索引。
# ------------------
# Write your implementation here.
for sentence in corpus:
for i, word in enumerate(sentence):
#遍历每个单词并获取其索引 i 和内容 word
center_word_index = word2ind[word]#获取中心词的索引
start = max(i - window_size, 0)
end = min(i + window_size + 1, len(sentence))
for j in range(start, end):
if j != i:#跳过当前中心词,避免自共现
co_word_index = word2ind[sentence[j]]#获取当前单词的索引
M[center_word_index, co_word_index] += 1
#在共现矩阵 M 中,将中心词和共现词的对应位置的值加 1,表示这两个词在文档中共现了一次
# ------------------
return M, word2ind

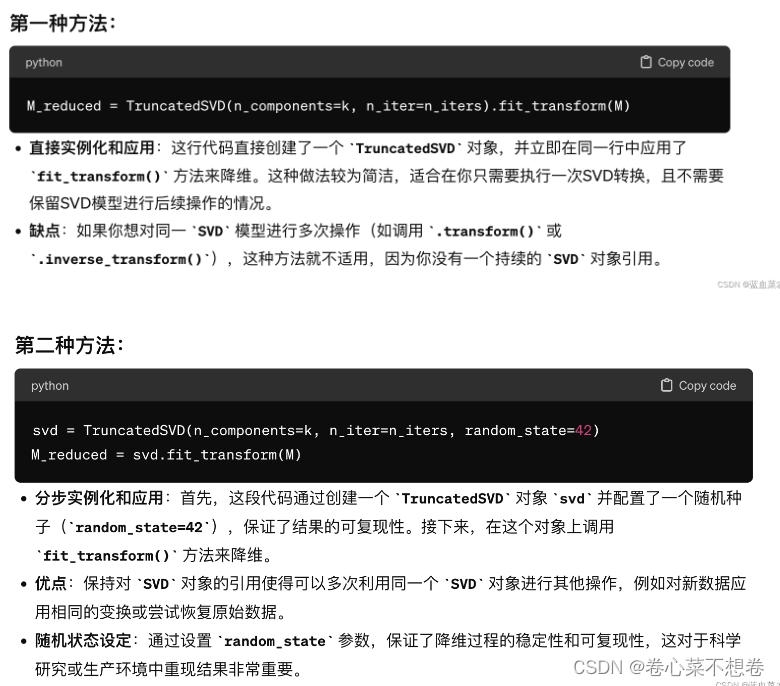
1.3:实现 reduce_to_k_dim

svd = TruncatedSVD(n_components = k, n_iter = n_iters)
M_reduced = svd.fit_transform(M)


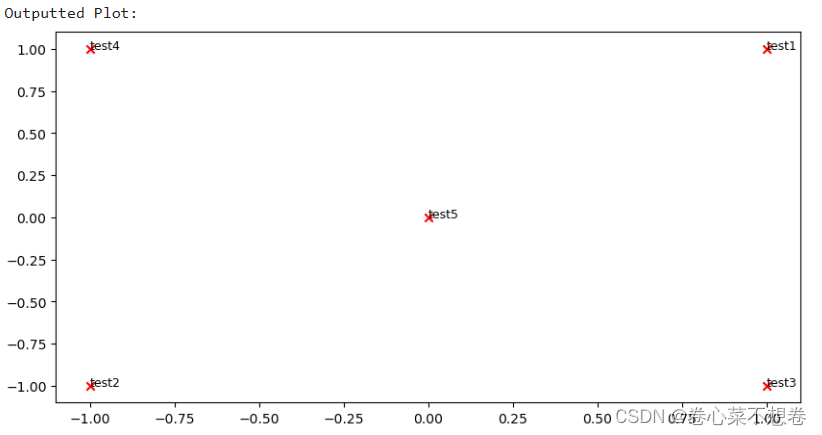
1.4:实现 plot_embeddings

for w in words:
index = word2ind[w]
embedding = M_reduced[index]
x, y = embedding[0], embedding[1]
#从二维嵌入向量中提取x和y坐标
plt.scatter(x, y, marker = 'x', color = 'red')
plt.text(x, y, w, fontsize = 9)
#添加文本标签
plt.show()
第 2 部分:基于预测的词向量
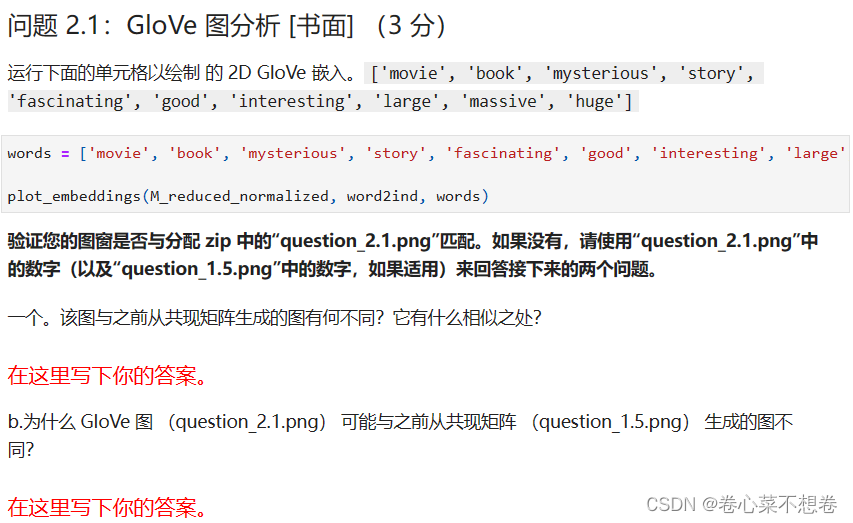
问题1:

问题2:

参考文章:
cs224n 2024春 课后作业a1
共现矩阵、SVD与GloVe词向量






























 4348
4348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









