







主要用于二分类问题
首先,找一个线性模型:
z
=
w
T
x
+
b
z = w^{T}x+b
z=wTx+b
sigmoid函数:
g
(
x
)
=
1
1
+
e
−
x
g(x)=\frac{1}{1+e^{-x}}
g(x)=1+e−x1
将线性模型套到sigmoid函数里,如下图公式:
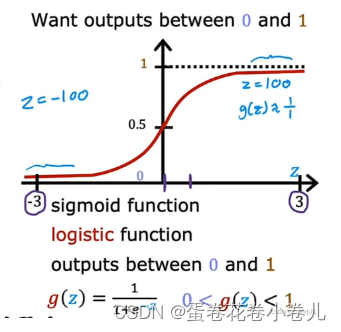
逻辑回归的作用:输入特征x,并输出一个介于0和1之间的数,这个数为 标签y取1的概率

逻辑回归条件概率推导

决策边界


损失函数
损失函数的意义:
如果模型的预测结果与实际观测结果相差较大,那么损失函数的值就会较大;通过最小化损失函数,我们可以找到一组最优的模型参数,使得模型能够更好地拟合训练数据,提高模型的准确度和泛化能力。所以它是评估模型性能和指导模型优化的关键指标。
损失函数推到由来
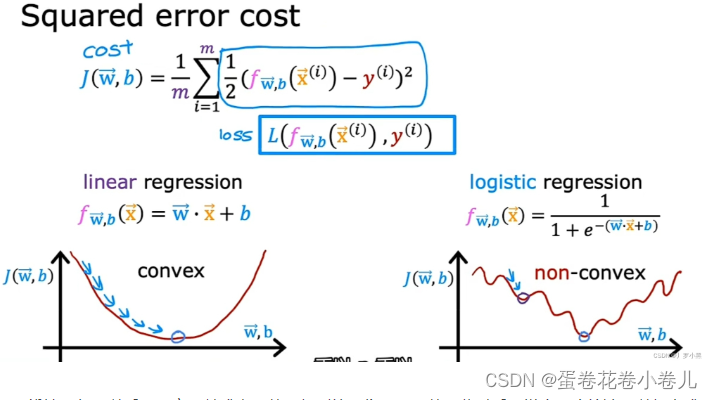
线性回归可以采用平方误差成本函数,得到的图像是凸函数,此时采用梯度下降算法可以得出成本函数的全局最小值。但,逻辑回归若也采用平方误差成本函数,得到的图像是非凸函数,此时采用梯度下降算法,只能得到局部最小值,很难得到全局最小值。(所以不用mse,用交叉熵)
损失函数: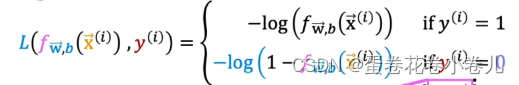
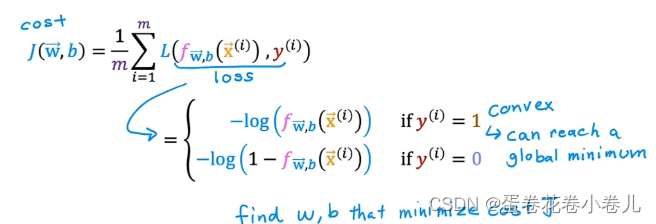
简化后:
该损失函数是凸函数,只有一个局部最小值,也是全局最小值。
逻辑回归的梯度下降法
参考文章
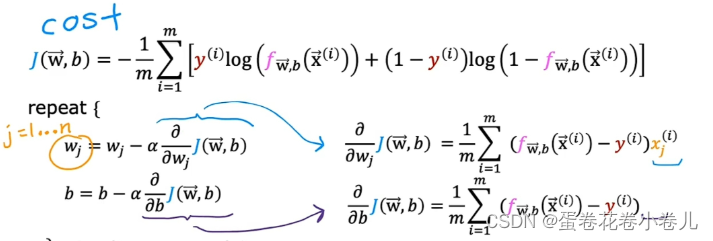

多元线性回归的梯度下降相同,因为逻辑回归有多个特征,梯度下降算法在每一步都要对其进行更新,且更新W时,对b也需要同时更新。
- 逻辑回归的梯度下降算法和线性回归的梯度下降算法看着很类似,但他们的f(x)函数不同
- 逻辑回归的梯度下降算法可以用学习曲线来监测算法是否收敛,也可以用向量化、特征缩放来简化算法的执行过程,提高算法的速度。
逻辑回归过拟合
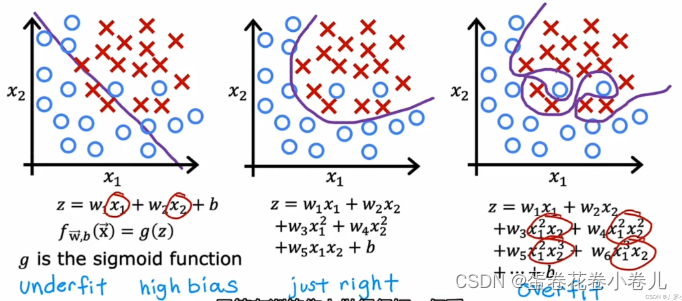
左欠拟合,中刚好,右过拟合
过拟合 解决办法:
- 增加数据集,模型变得不那么高方差
- 减少一些特征(可能会丢失一些有用信息)
- 正则化,缩小特征的参数(通常,我们只缩小Wj,并不缩小b)
正则化
- 正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的模型h(x)不同,所以有很大差别.
- θ 0 θ_{0} θ0不参与其中的任何一个正则化.(即都没有对b进行正则化,所以更新b时也不需要进行缩小操作 参考文章)

















 2267
2267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









