






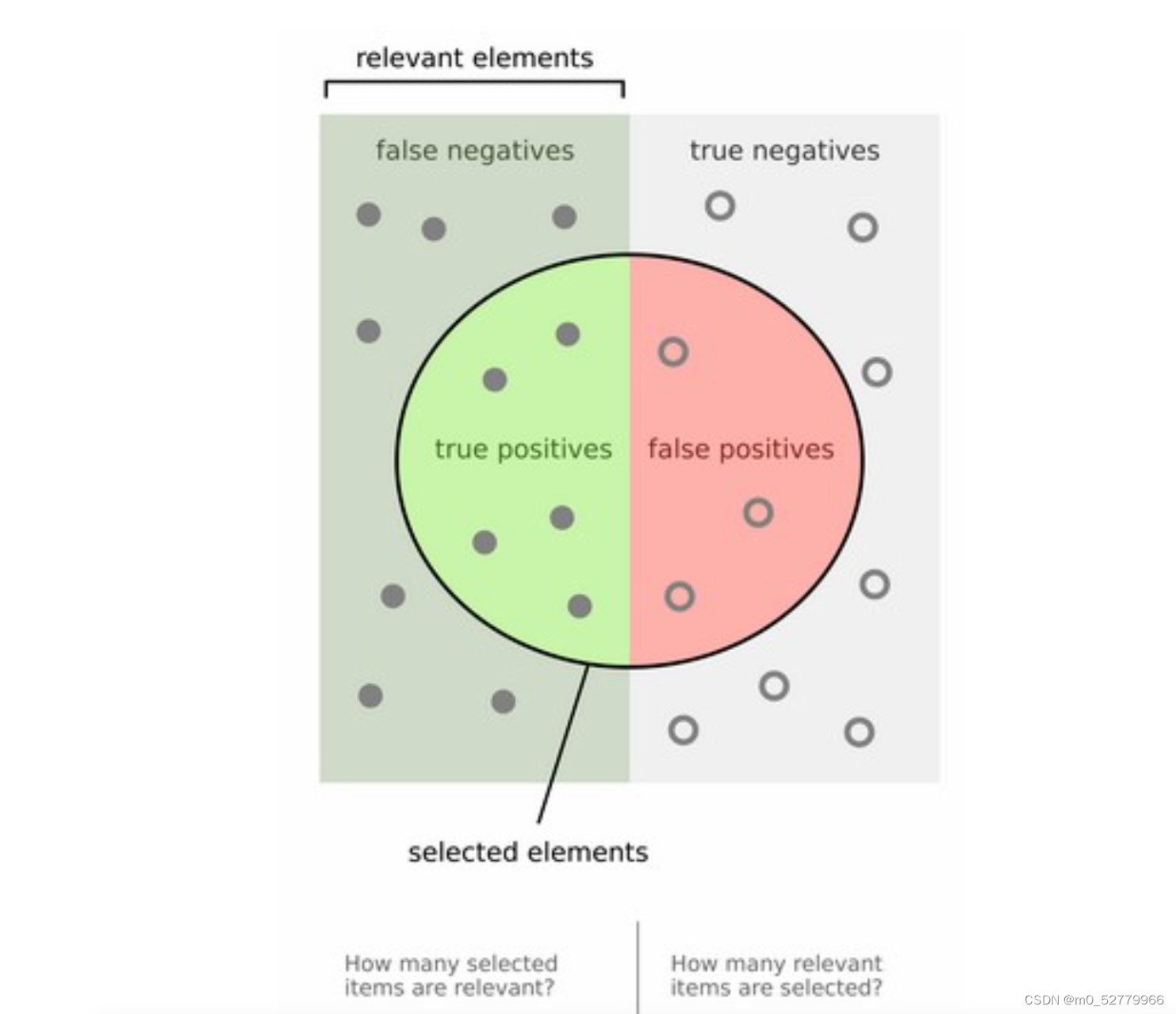
true positives + false positives;;;true negative + false negative
从后往前翻译——p:机器人认为是真值,n:机器人认为是假值;;;;;true:实际结果与机器识别结果对比显示为真值,false:实际结果与机器识别结果对比显示为假值。
那么这四个标签从后往前翻译(说人话就是):机器识别为真实际也为真,机器识别为真但实际为假,机器识别为假实际也确实为假,机器识别为假但实际为真。
那么所有的真样本为TP+FN,,,其余的便为所有的假样本。
从另一个角度翻译:将P和N分别表示为+1和-1(或者表示为0也可以,文章中用的是实心圆圈和空心圆圈表示),将T和F表示为+和-,那么四个结果分别为+(+1),-(+1),+(-1),-(-1)。这就很容易看出实际为真值的是第一个和第四个结果(正正得正,负负得正)。
至于文章中所引出的概念precision和recall可以这么解释;
precision:机器所得出的为真(+(+1))的样本的这个行为的准确度为多少
recall:机器所得出的为真(+(+1))的样本数量在所有实际为真的数量中的占比,因为有一部分实际真值被机器识别为了假。
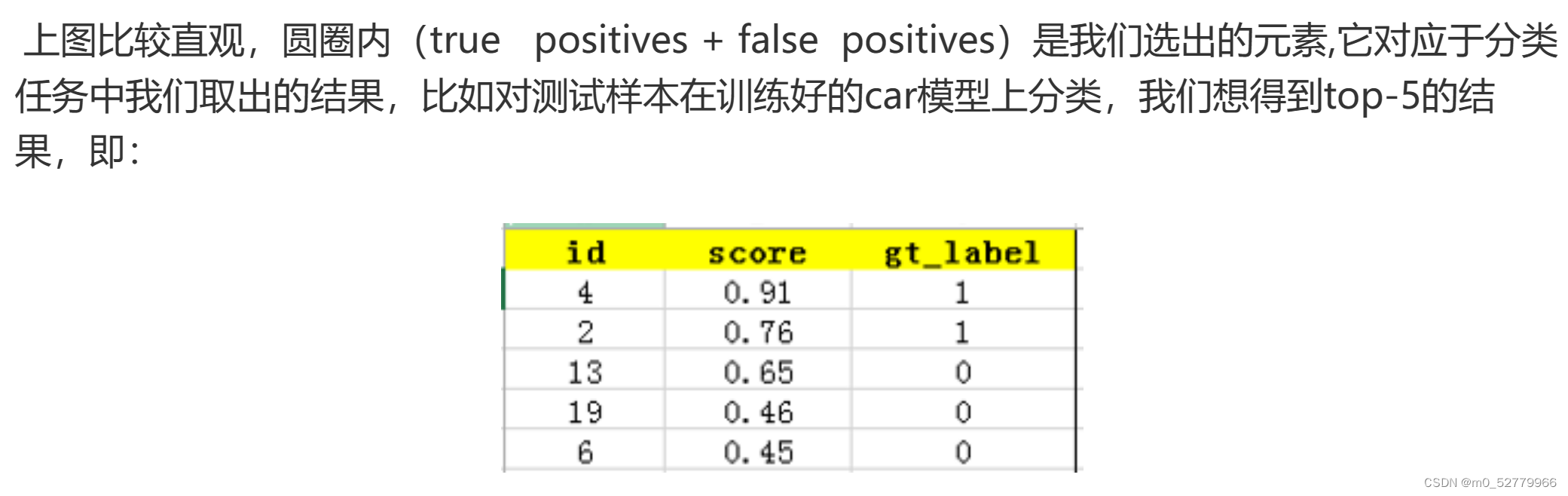
之所以文章中选了这五个,是因为上一步骤中已经将样本按照置信度从高到低排序了,那么我个人理解为将机器识别的置信度在45%的样本都定义为positive也即我所说的+(+1).
也即是说下图中黑色圆圈的标定在现在举例上是以45%为评判标准的。

这个第四列的max precision不好理解,评论区也是看了很久
可以这么直观解释:recall为1/6时,检索的数据是按照从recall为1/6到6/6中所有的precision的最大值也即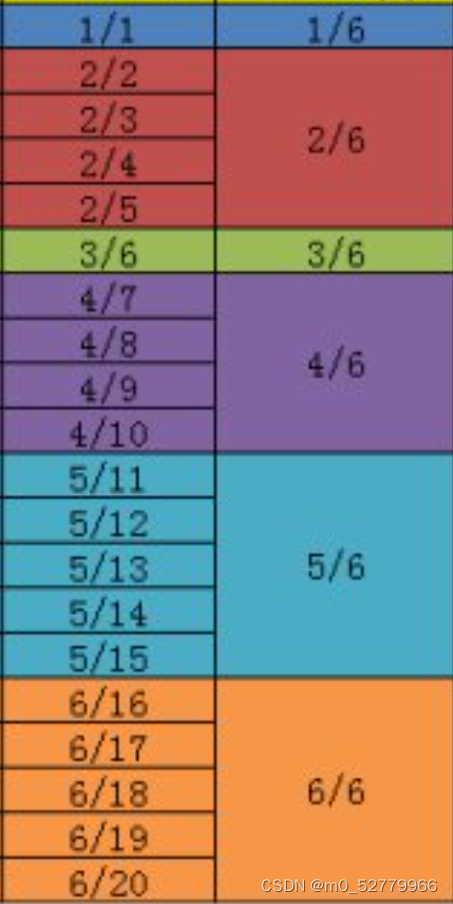 中的最大值,recall为2/6时检索的是
中的最大值,recall为2/6时检索的是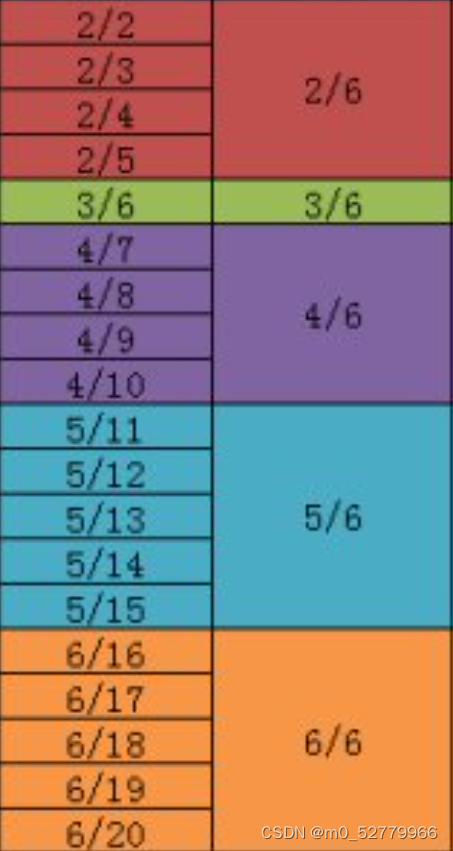 ,recall为3/6时检索的是
,recall为3/6时检索的是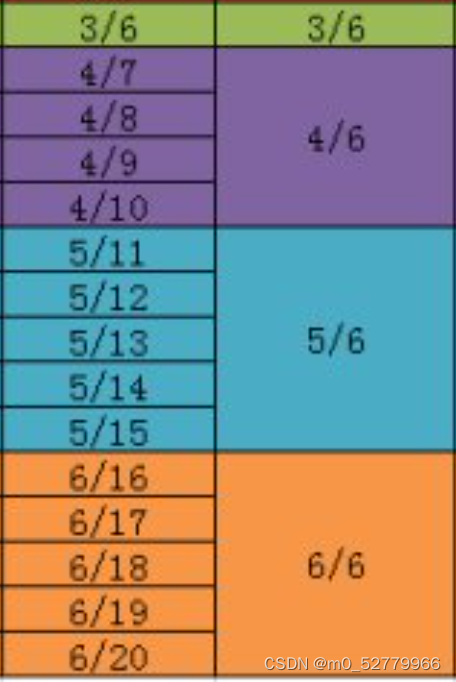 后续也都是这么操作,那么自然而然,表格中的数据都是正确的。
后续也都是这么操作,那么自然而然,表格中的数据都是正确的。















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









