







- 梯度有方向,导数没有方向,在一维的情况下,导数近似等于梯度
激活函数梯度
Sigmoid函数
- 使结果在0,1之间

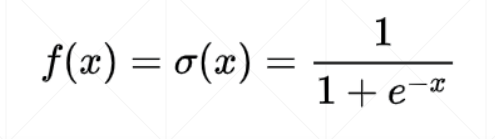
导数:

tanh函数
- 常用于RNN,输出在-1,1之间


导数:

relu函数
- 目前深度学习常用的激活函数


导数:
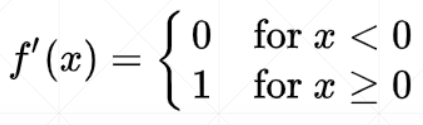
loss及其梯度
MSE 均方误差
- lo𝑠𝑠 = Σ [𝑦 − 𝑓𝜃(𝑥)]2
- 梯度: ∇𝑙𝑜𝑠𝑠 / ∇𝜃 = 2 Σ [ 𝑦 − 𝑓𝜃(𝑥) ] ∗ (∇𝑓𝜃(𝑥) / ∇θ)
- 代码中可以调用 function.mse_loss(a,b) 函数,a为y;b为 𝑓𝜃(𝑥)
- 下例中 .requires_grad_() 可以帮助记录更新信息

- 使用 torch.autograd.grad(loss, [w1, w2,…]) 计算每项梯度
- 使用 loss.backward() 计算梯度,并可以使用 .grad() 查看梯度信息(推荐该方法)

softmax函数
- 输出在0,1之间,且所有值的和为1,非常适合多分类问题

- 使用 function.mse_loss(a,dim) 函数对 a 的 dim 维度进行 softmax 计算

感知机梯度推导
- 下图中如 x00 上标表示层数编号;下标表示当前层数节点的编号

- 用下面的函数可以求 y2 对 y1 的导数

优化器实例

















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









