






掌握每个Map集合底层采用什么数据结构存储数据,优缺点是什么,熟练使用集合对象的相关方法。
Map集合
- Map集合和Collection集合没有继承关系
- Map集合以key和value这种键值对存储数据。key和value只能存储引用,存储对象的内存地址。key起主导作用,value是key的一个附属品。在Map集合中有一个内部类Node,key和value是内部类的两个属性
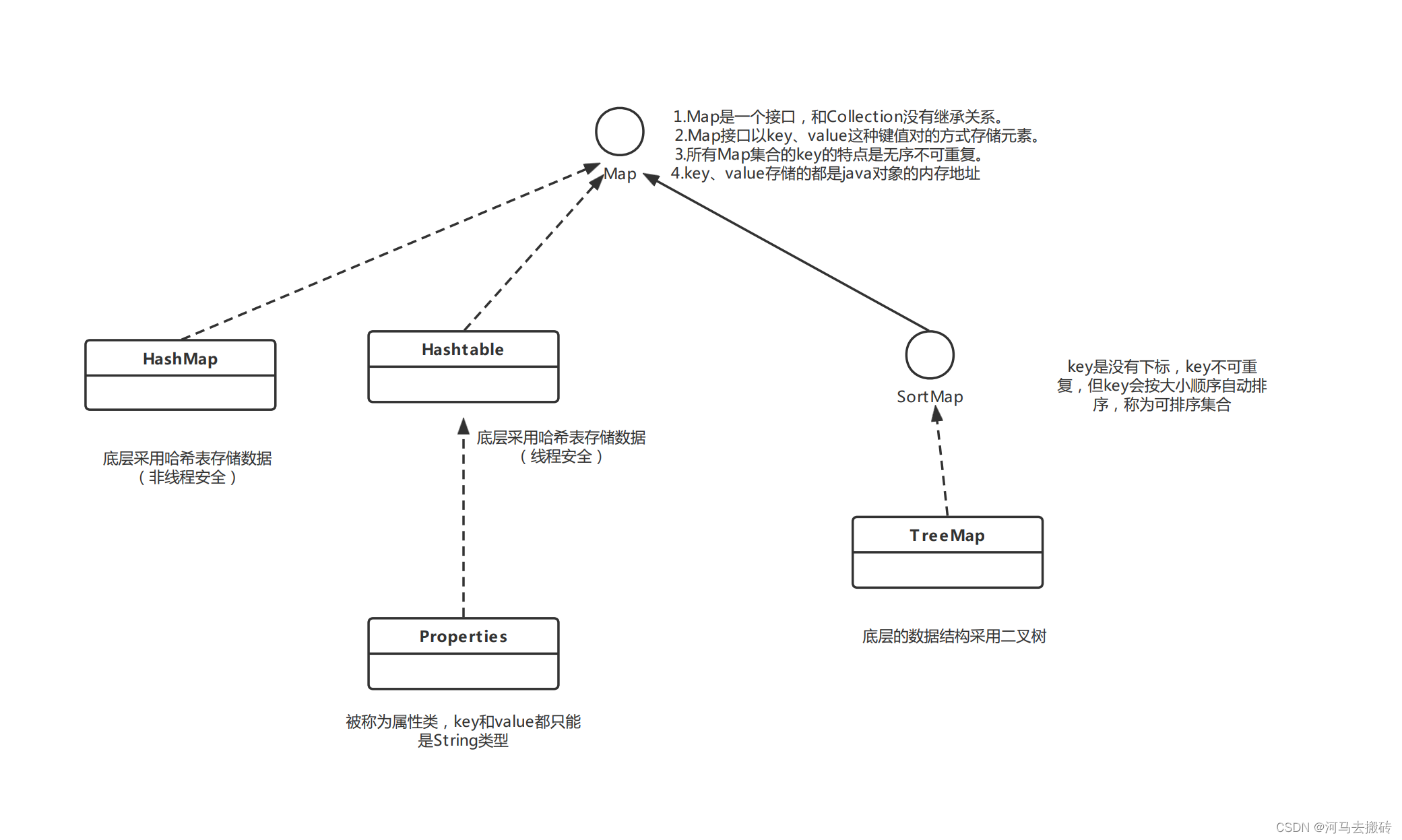
Map集合继承结构
map是键值对的集合接口,它的实现类主要包括:HashMap,TreeMap,Hashtable等。其中这区别如下(简单介绍):
HashMap:我们最常用的Map,它根据key的HashCode 值来存储数据,根据key可以直接获取它的Value,同时它具有很快的访问速度。HashMap最多只允许一条记录的key值为Null(多条会覆盖);允许多条记录的Value为 Null。非同步的。
TreeMap: 能够把它保存的记录根据key排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
Hashtable: 与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
Map接口中的通用方法
Map接口中的方法是Map集合公用的,有以下方法:
-
V put(K key,V value);添加元素。
-
V get(Object key);根据键获取值
-
void clear();移除所有的键值对元素
-
V remove(Object key);根据键删除键值对元素,并把值返回
-
boolean containsKey(Object key);判断集合是否包含指定的键
-
boolean containsValue(Object value);判断集合是否包含指定的值
-
boolean isEmpty();判断集合是否为空
-
Set<Map.Entry<K,V>> entrySet();把map集合转换为set集合,set集合中每个元素是Map.Entry类型,Map.Entry对象包含key,value
-
Set keySet();获取集合中所有键的集合,返回一个Set集合
-
Collection values();获取Map集合中所有的value,返回一个Collection集合
编写程序,熟悉运用
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
//Map集合常用方法
public class Test01 {
public static void main(String[] args) {
//创建map集合对象
Map<Integer,String> map = new HashMap<>();
//put方法添加键值对
map.put(1,"张三");
map.put(2,"李四");
map.put(3,"王五");
map.put(4,"lic");
//通过key获取对应的value
System.out.println("key为1对应的value是:"+map.get(1));
//获取键值对的数量
System.out.println("键值对的数量是:"+map.size());
//通过key删除键值对
//System.out.println(map.remove(1));
//判断集合中是否包含这个key
System.out.println("是否包含1这个key "+map.containsKey(1));
//判断集合中是否包含这个value
System.out.println("是否包含李四这个value "+map.containsValue("李四"));
//获取所有的value 返回Collection集合
Collection<String> values = map.values();
for (String a:values
) {
System.out.println(a);
}
//获取所有的key 返回Map集合
Set<Integer> keySet = map.keySet();
for (Integer k:keySet
) {
System.out.print(k);
}
//判断是否为空
System.out.println(map.isEmpty());
//清空集合
map.clear();
}
}
Map集合四种遍历
获取Map集合所有的key,返回Set集合,一种foreach遍历
//Map集合的遍历
//方法一:foreach
//获取map集合所有的key值 返回set集合
for (Integer in:map.keySet()) {
System.out.println(in+"="+map.get(in)); //通过key获取value
}
一种迭代器遍历
//方法二:迭代器
Set<Integer> values = map.keySet();
Iterator<Integer> iterator = values.iterator();
while (iterator.hasNext()){
Integer next = iterator.next();
System.out.println(next+"="+map.get(next));
}
Map集合转换成Set集合,set集合元素是Map.Entry对象,通过getKey()、getvalue()方法,再进行foreach遍历
//Map集合转换成Set集合,set集合元素是Map.Entry对象,foreach遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey()+"="+entry.getValue());
}
Map集合转换成Set集合,set集合元素是Map.Entry对象,通过getKey()、getvalue()方法,再进行迭代器遍历
//Map集合转换成Set集合,set集合元素是Map.Entry对象,迭代器遍历
Set<Map.Entry<Integer, String>> entries = map.entrySet();
Iterator<Map.Entry<Integer, String>> entryIterator = entries.iterator();
while (entryIterator.hasNext()){
Map.Entry<Integer, String> next = entryIterator.next();
System.out.println(next.getKey()+"="+next.getValue());
}
HashMap集合
HashSet集合底层是HashMap,HashMap集合底层采用哈希表存储数据,哈希表的数据结构是数组和链表的结合体,集数组的检索便利和链表的插入便利优点于一体。哈希表的随机增删在链表上,查询在数组,所以哈希表效率较高。

put、get方法实现原理
put方法实现原理:
1.将k,value封装到Node对象中;
2.调用k的hashCode方法返回hash值,然后通过哈希函数,将hash值转换成数组的下标,对应下标没有元素,就把Node添加进去,如果对应的位置有元素,则用k和元素链表上的k进行equals,返回false,将node添加到末尾,返回true,进行覆盖,把新的value赋值。
get方法实现原理:
1.调用k的hashCode方法返回hash值
2.通过哈希函数,将hash值转换成数组的下标,通过数组下标进行位置定位,若该位置什么也没有,返回null,若该位置有链表,则用这个k和链表上的k进行equals,若返回false,则get方法返回null,返回true,则返回这个链表节点上的value。
注意:
两个方法在使用时,底层都是先调用hashCode方法,再调用equals方法。
同时重写hashCode方法、equals方法。
示例HashMap,自定义类作为key、value:
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
public class HashMapTest {
public static void main(String[] args) {
//创建对象
HashMap<Integer,String> hashMap = new HashMap<>();
//添加元素 key重复时 value会覆盖
Person a = new Person(1, "张三");
Person b = new Person(2, "小白");
Person c = new Person(3, "李四");
Person d = new Person(4, "李翰");
hashMap.put(a.id,a.name);
hashMap.put(b.id,b.name);
hashMap.put(c.id,c.name);
hashMap.put(d.id,d.name);
//键值对的数量
System.out.println(hashMap.size());
//集合遍历
for (Map.Entry<Integer, String> entry : hashMap.entrySet()) {
System.out.println(entry);
}
//取出元素
System.out.println(hashMap.get(2));
}
}
class Person{
int id;
String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
//重写equals hashCode方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
Hashtable
Hashtable中的方法都带有synchronized:线程安全。线程安全有其他的方案, Hashtable对线程处理效率低
Hashtable初始化容量:

Hashtable扩容:
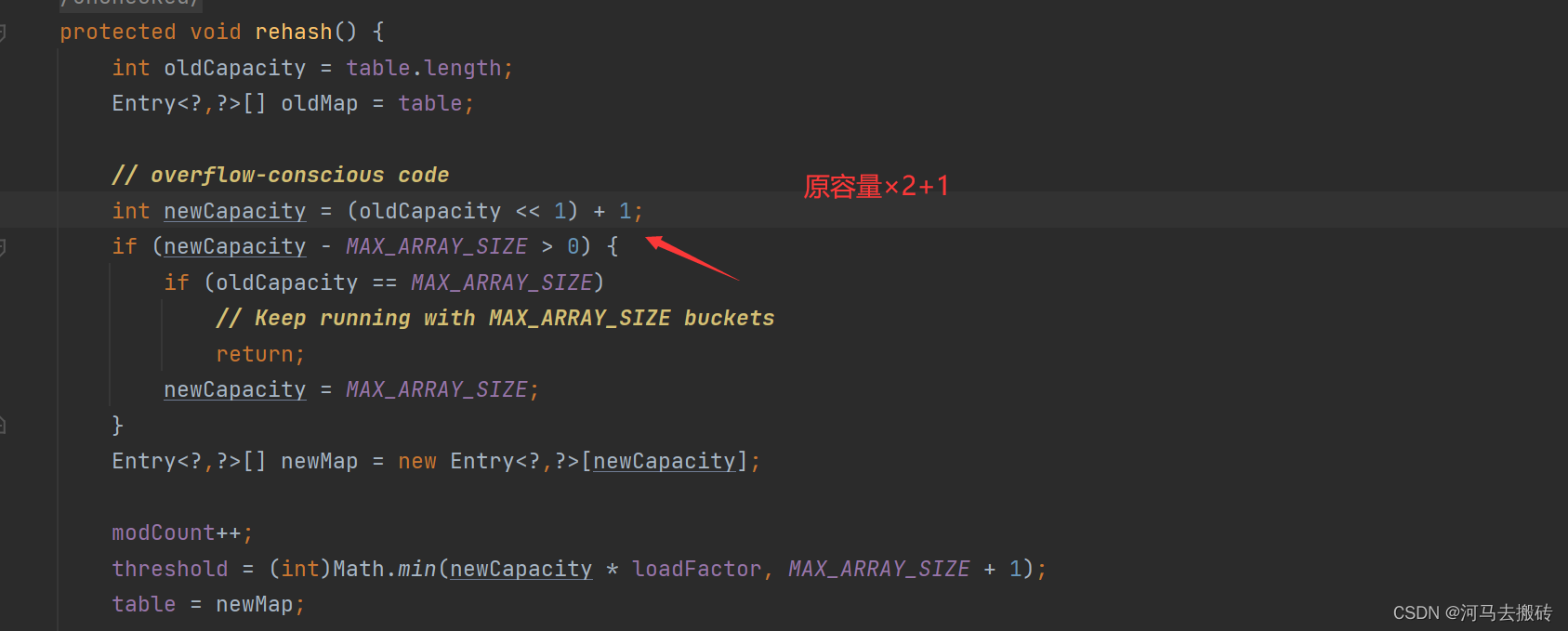
Hashtable中的key、value不允许为null, HashMap的key、value允许为null。
Properties类
Properties是Map集合,继承 Hashtable,key、value都是String类型。称为属性类。
import java.util.Properties;
public class Test04 {
public static void main(String[] args) {
Properties p = new Properties();
//存
p.setProperty("a","asd");
p.setProperty("s","ddn");
p.setProperty("d","oin");
//取
System.out.println(p.getProperty("a"));
System.out.println(p.getProperty("s"));
System.out.println(p.getProperty("d"));
}
}
TreeMap集合
继承Collection接口的Set集合的实现类TreeSet底层实际是TreeMap集合,TreeMap集合底层采用二叉树数据结构,存时采取左小右大原则,遍历时采取中序遍历(左根右)

示例方法:
import java.util.Map;
import java.util.TreeMap;
public class TreeMapTest {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(1,"李三");
map.put(8,"张三");
map.put(2,"李四");
map.put(3,"王麻子");
map.put(5,"李翰");
//返回与大于或等于给定键元素的最小键元素链接的键值对
System.out.println(map.ceilingEntry(4)); //5=李翰
//返回与大于或等于给定键元素的最小键元素链接的键值
System.out.println(map.ceilingKey(4));
//修改key的value
System.out.println(map.replace(8, "小马"));
System.out.println(map.get(8));
//遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry);
}
}
}















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









