







实验4 K-Means 实操项目:不同含量果汁饮料的聚类
【实验内容】
某企业通过采集企业自身流水线生产的一种果汁饮料含量的数据集,来实现K-Means算法。通过聚类以判断该果汁饮料在一定标准含量偏差下的生产质量状况,对该饮料进行类别判定。
【数据集】
该数据集共有样本59个,变量2个,包括juice(该饮料的果汁含量偏差)、sweet(该饮料的糖分含量偏差),单位均为mg/ml。
所有特征变量都为与标准含量相比的偏差,该数据集没有目标类别标签变量。
【实验要求】
1.加载数据集,读取数据,探索数据。(数据集路径:data/data76878/4_beverage.csv)
2.样本数据转化(可将pandasframe格式的数据转化为数组形式),并进行可视化(绘制散点图),观察数据的分布情况,从而可以得出k的几种可能取值。
3.针对每一种k的取值,进行如下操作:
(1)进行K-Means算法模型的配置、训练。
(2)输出相关聚类结果,并评估聚类效果。
这里可采用CH指标来对聚类有效性进行评估。在最后用每个k取值时评估的CH值进行对比,可得出k取什么值时,聚类效果更优。
注:这里缺乏外部类别信息,故采用内部准则评价指标(CH)来评估。 (metrics.calinski_harabaz_score())
(3)输出各类簇标签值、各类簇中心,从而判断每类的果汁含量与糖分含量情况。
(4)聚类结果及其各类簇中心点的可视化(散点图),从而观察各类簇分布情况。(不同的类表明不同果汁饮料的果汁、糖分含量的偏差情况。)
4.【扩展】(选做):设置k一定的取值范围,进行聚类并评价不同的聚类结果。
参考思路:设置k的取值范围;对不同取值k进行训;计算各对象离各类簇中心的欧氏距离,生成距离表;提取每个对象到其类簇中心的距离,并相加;依次存入距离结果;绘制不同看、值对应的总距离值折线图。
import pandas as pd
import numpy as np
from sklearn import metrics
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 一、数据获取
# ------ 1.1.导入数据 ------
df = pd.read_csv('data/data76878/4_beverage.csv',encoding='GB18030') # 数据集地址
# print(df)
print(df.shape) # 输出数据维度
print(df.head()) # 展示前5行数据
# 二、数据可视化
def showOrgData(dataMat):
df=np.array(dataMat)
print(type(df))
plt.scatter(df[:, 0], df[:, 1],color='m', marker='o', label='Org_data')
plt.xlabel('juice')
plt.ylabel('sweet')
plt.legend(loc=2) # 把说明放在左上角,具体请参考官方文档
plt.show()
#三、数据处理
df=np.array(df) # 将pandasframe格式的数据转化为numpy的数组形式
# 样本数据散点图(未划分之前的数据集)
showOrgData(df)
#四、训练不同k值下的kmeans
score_all=[]
list1=range(2,8)
for i in range(2,8):
estimator = KMeans(n_clusters=i)
estimator.fit(df)
y_pred = estimator.fit_predict(df)
#五、画出不同k值下的结果散点图
plt.scatter(df[:, 0], df[:, 1], c=y_pred,label=i)
plt.legend(loc=2) # 把说明放在左上角,具体请参考官方文档
plt.xlabel('juice')
plt.ylabel('sweet')
# 重要属性cluster_centers_,查看质心
centroid = estimator.cluster_centers_
print("k=%d:" % i)
print("centroid:\n",centroid)
# 各类簇中心点的可视化
plt.scatter(
centroid[:, 0],
centroid[:, 1],
marker="x",
c="black",
s=48
)
#六、记录不同k值下聚类的CH评价指标的结果
score = metrics.calinski_harabasz_score(df, y_pred)
score_all.append(score)
print("score=",score)
print('------------------------------')
plt.show()
#七、画出不同k值对应的聚类效果(折线)
plt.plot(list1,score_all)
plt.xlabel('k')
plt.ylabel('CH')
plt.show()
(59, 2)
juice sweet
0 2.1041 0.8901
1 -1.0617 -0.4111
2 0.3521 -1.7488
3 -0.1962 2.5952
4 1.4158 1.0928
<class 'numpy.ndarray'>
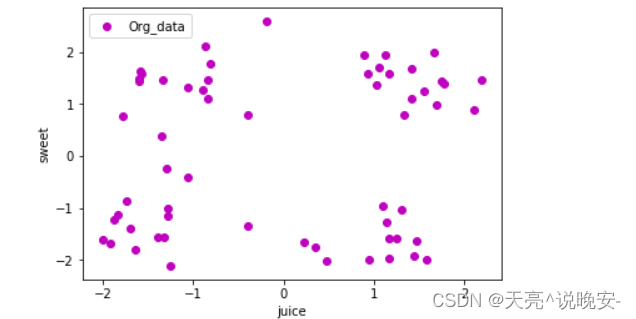
k=2:
centroid:
[[-0.30035357 -1.44121786]
[ 0.20340968 1.43033548]]
score= 60.84196357784196
------------------------------
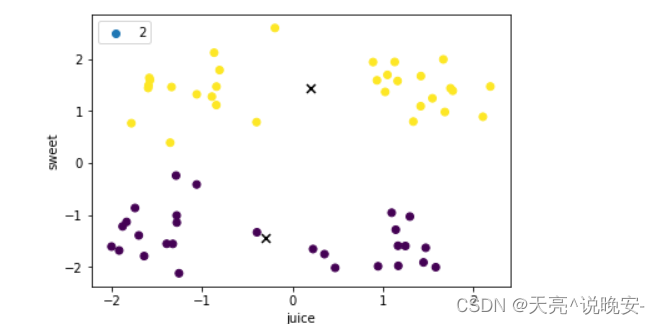
k=3:
centroid:
[[ 1.44084375 1.44255625]
[-0.30035357 -1.44121786]
[-1.11652 1.4173 ]]
score= 73.95986749645601
------------------------------
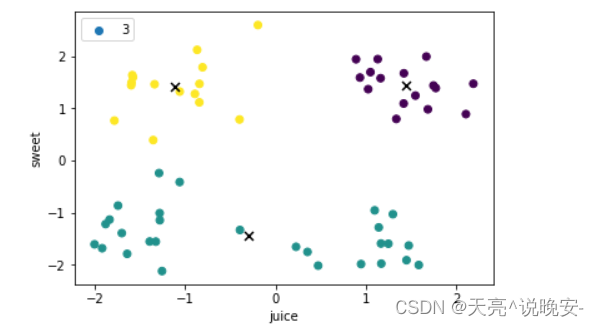
k=4:
centroid:
[[-1.46766 -1.26746 ]
[-1.11652 1.4173 ]
[ 1.44084375 1.44255625]
[ 1.04653846 -1.64170769]]
score= 188.0667309404243
------------------------------

k=5:
centroid:
[[-1.372475 0.1269 ]
[-1.04686923 1.54623846]
[ 1.44084375 1.44255625]
[ 1.04653846 -1.64170769]
[-1.51257692 -1.41239231]]
score= 166.672060725869
------------------------------

k=6:
centroid:
[[-1.6057 -1.41931667]
[ 1.44084375 1.44255625]
[-1.100825 1.60950833]
[ 1.25578 -1.59305 ]
[ 0.163025 -1.68525 ]
[-1.17786 0.25892 ]]
score= 156.11781485190343
------------------------------
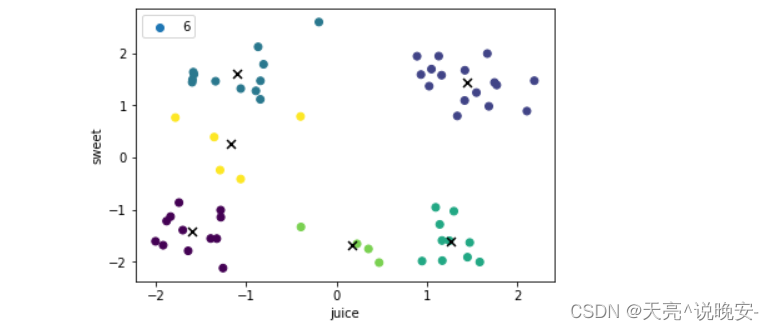
k=7:
centroid:
[[-1.04686923 1.54623846]
[-1.6057 -1.41931667]
[ 1.7232875 1.1631875 ]
[ 1.25578 -1.59305 ]
[ 1.1584 1.721925 ]
[-1.372475 0.1269 ]
[ 0.163025 -1.68525 ]]
score= 154.72893842750688
------------------------------
















 3537
3537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









