







Rich Knowledge Sources Bring Complex Knowledge Conflicts: Recalibrating Models to Reflect Conflicting Evidence
EMNLP2022
文章主要探究的是当模型内部参数的信息和检索结果信息冲突时,LLM的决策问题
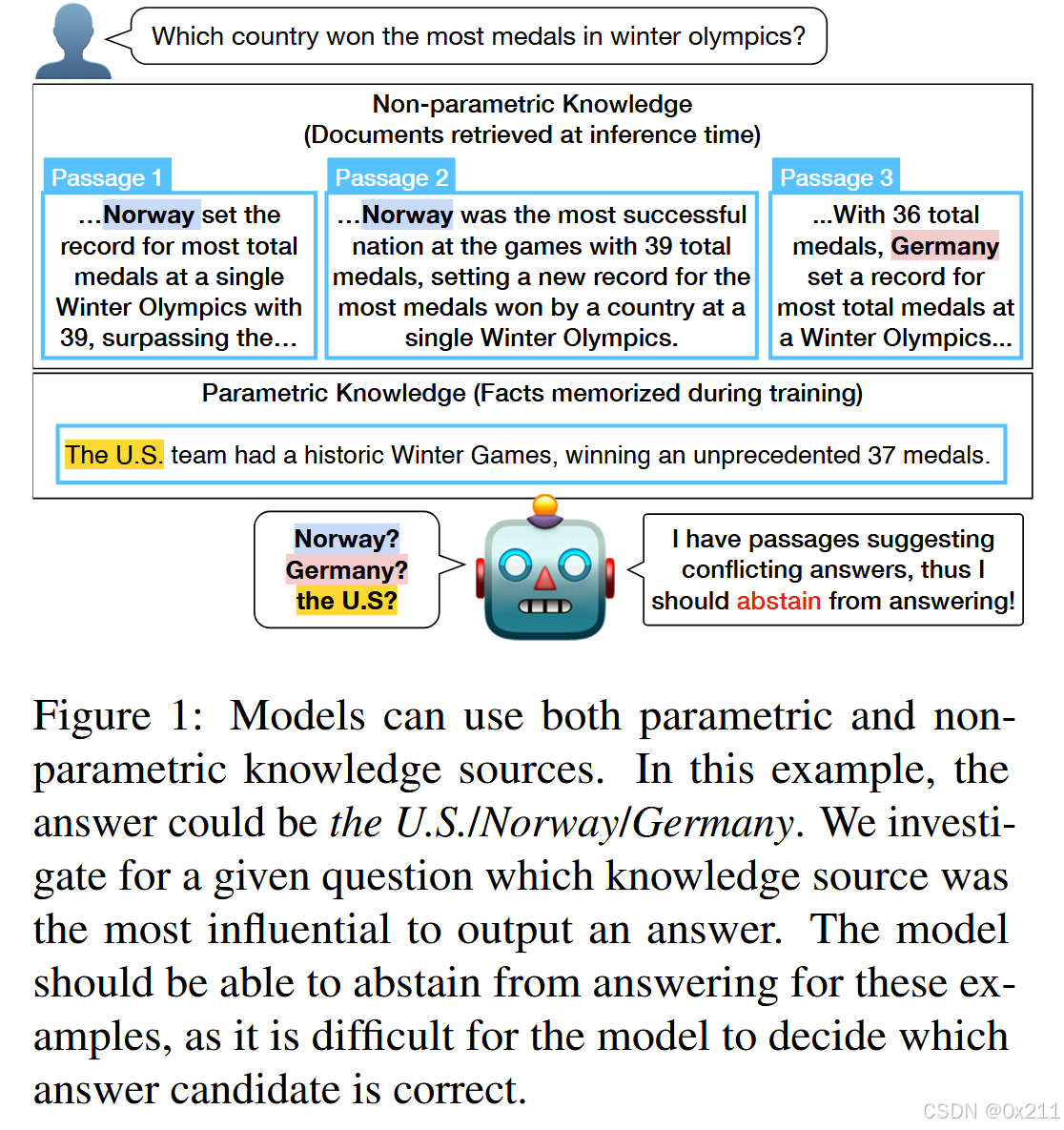
文章关注以下核心问题:当提供大量证据段落和经过预训练和微调的语言模型时,模型的答案基于哪个知识源?
和Entity-based knowledge conflicts in question answering.的聚焦点不同,前者在有限的单一证据文件中进行了探究,本文是模拟更加现实的场景,在多个证据段落下(最多100个),观察决策结果
根据经验测试了 QA 模型如何使用不同的知识来源。 我们提出了对知识冲突的第一个分析,其中(1)模型使用多个段落,(2)知识冲突源于不明确且依赖于上下文的用户查询,以及(3)不同段落之间存在知识冲突。 我们的发现如下:当提供高召回率检索器时,模型几乎完全依赖于证据段落,而不会从参数知识中产生幻觉答案。 当不同的段落提出多个相互冲突的答案时,模型更喜欢与其参数知识相匹配的答案。 最后,我们确定了基于检索的生成模型的各种弱点,包括其置信度得分没有反映知识源之间存在冲突的答案。 我们最初的校准研究表明,阻止模型在存在丰富的、潜在冲突的知识源的情况下呈现单一答案是具有挑战性的,并且需要未来的研究。
文章研究了两种基于检索的生成QA模型:Fusion-in-Decoder(FiD)和RAG。前者把问题和检索到的每一个文本都单独使用特殊的符号拼接起来,分别输入给encoder,得到的结果全部拼接起来交给decoder进行解码;后者是把问题本体和检索出来的相关文段内容整体交予生成器。
对模型置信度的研究:
分析模型的置信度得分,提出更加细致的问题:在扰乱知识源后,模型对黄金答案的信心是否会降低。做法:比较扰动前后同一示例的模型置信度。评分:使用答案的生成改了或者单独训练的答案的置信度
基于检索的生成模型什么时候依赖内部知识,什么时候依赖检索结果?
评估模型是否生成一组证据文档中不存在的新答案
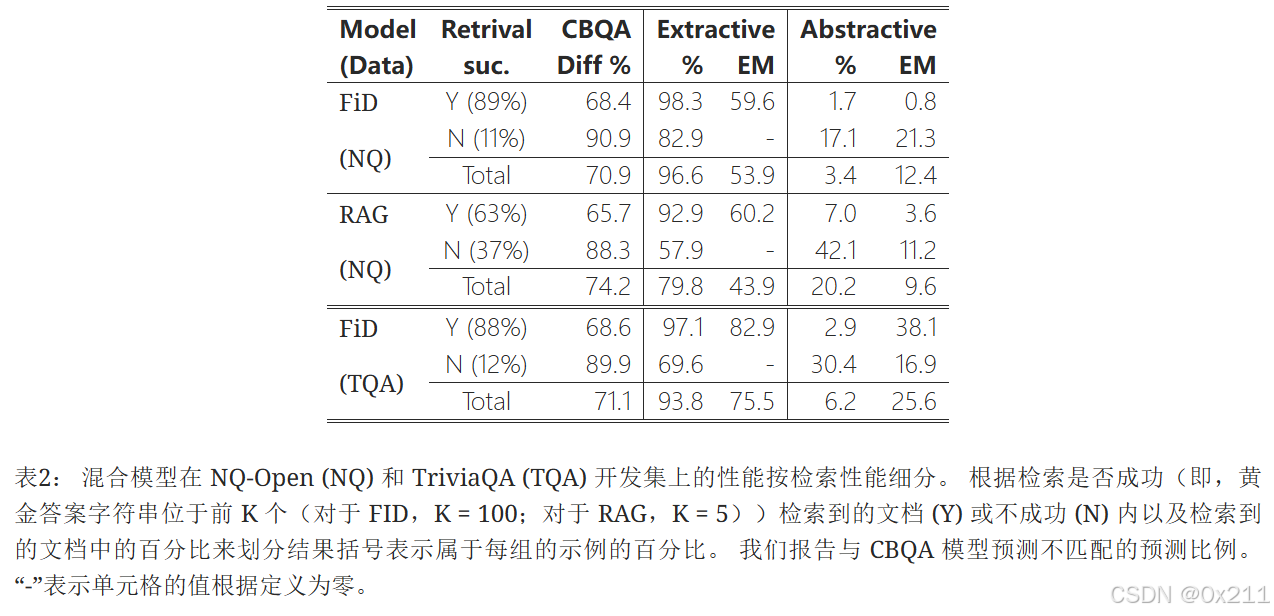
上表报告了模型生成证据段落中未找到的跨度的频率
观察到模型通常会复制证据段落中的跨度,仅在 NQ/TriviaQA 中的 FiD 示例中生成 3.4%/6.2% 的新跨度,在 NQ 中的 RAG 中仅生成 20.2% 的示例跨度。 即使对于检索到的文档不包含答案字符串的一小部分示例,FiD 仍然可以提取 NQ/TriviaQA 中 82.9%/69.6% 的示例。 相比之下,对于 RAG,检索到的文档经常错过黄金答案 (37%),这种复制行为不太常见,为 42.1% 的示例生成了看不见的文本。
结果表明,随着检索器性能的提高,对检索到的文档的依赖也会增加。 我们还报告了模型预测与在相同数据上训练的 T5 闭卷问答 (CBQA) 模型不同的示例的百分比。超过70%的示例有不同 来自 CBQA 模型的答案,即使答案是抽象的,证明了混合模型使用段落,即使没有精确的字符串匹配。
多数情况下,模型倾向于从证据段落中复制答案,FiD 在 NQ/TriviaQA 中仅分别有 3.4%/6.2% 的例子生成新答案,RAG 在 NQ 中有 20.2%。且随着检索性能提升,对检索文档的依赖增加。
重温前任工作中的知识冲突研究
文中的观察结果和前人工作中的结果矛盾,他们表明模型经常依赖参数知识,生成检索到的证据段落中不存在的答案;如果把原始段落中的关键回答信息修改为其他内容(可能和LM的知识相矛盾),模型会在17%的情况下生成原始答案。
在多证据段落设置下,FiD 在高召回率时主要依赖证据段落而非参数知识,这是因为多段落训练弥补了检索缺陷,使正确答案更易获取。
知识冲突场景下的模型行为
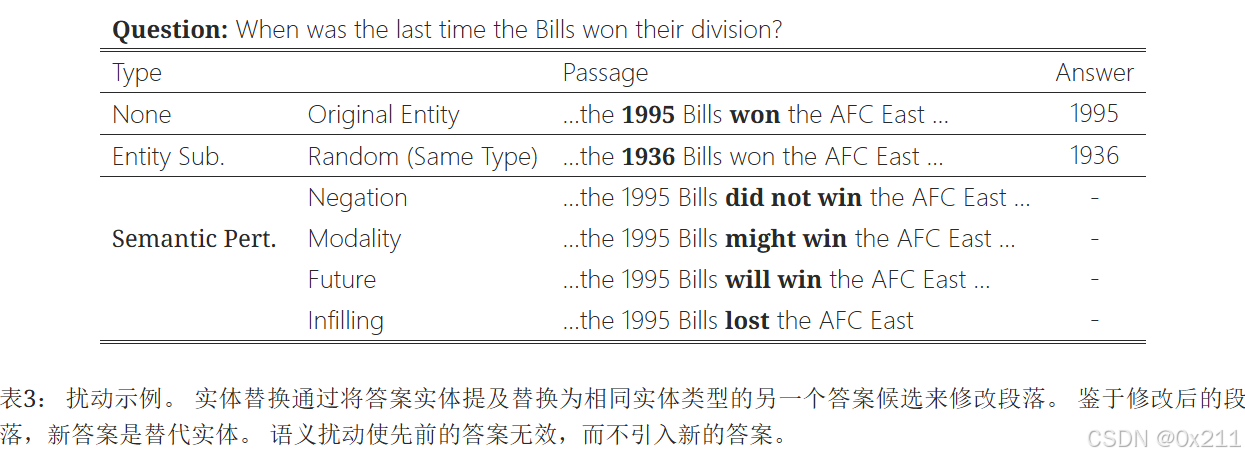
实体替换实验结果:
对部分证据段落进行实体替换模拟冲突,当所有段落被扰动时,模型能避免预测原答案,但部分扰动时仍倾向于原答案,且对高分(检索结果更靠前)段落扰动时模型改变答案更频繁,表明模型依赖少数最相关段落且用参数知识解决冲突。
语义扰动实验结果:
进行否定、时态改变等语义扰动后,模型大多仍输出原答案,对扰动不敏感,校准分数也基本稳定。
模型信心与知识冲突的关系
模型信心不受知识冲突影响,单独训练的校准器虽有改进,但效果有限,理想情况下模型信心应随冲突答案出现而降低,但实际未观察到这种联系。
模型校准研究结果
训练校准器使其在冲突证据下避免给出单一答案具有挑战性,数据增强可提升校准器性能,但对不同冲突证据集的泛化能力不足,基于更真实冲突证据集训练的校准器泛化效果相对更好。
总结
文章回答了这样几个问题:
- 模型是根据检索到的文档还是参数知识得出答案?当检索器性能较高的时候,模型生成答案的依据主要源于检索到的文档(个人猜测是因为检索性能高,直接包含问题答案的语句会被检索出来)
- 当不同的检索文本结果中给出的是不同的答案,模型如何使用这些文本段落?模型是依赖于最相关的检索段落(top检索结果)+内部知识辅助输出。
- 如果某些检索文本结果受到干扰而无法支持答案,模型如何表现?模型很大程度上忽略语义扰动并输出检索到的文本中存在的答案实体
- 知识冲突如何影响模型的置信度得分?置信度分数对知识冲突不敏感,且单独训练的校准器提供了一些改进。
- 能否训练一个模型,在相互矛盾的证据时避免返回单一的答案?如果在冲突数据集上戌年校准器,校准器会学会克制,但是不能泛化到不同类型冲突证据集。
- 存在互相矛盾的知识时模型应该做什么?提出了训练校准器的部分解决方案,校准器在提供相互矛盾的证据时会学会放弃回答。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









