







文章目录
00 前言
【我的AI安全之路】以下内容适合于有web安全基础但对AI"一无所知"的师傅们
如果是有安全基础,想入门AI安全,可以看下以web安全为背景介绍AI安全的书:《Web安全之机器学习入门》和《Web安全之深度学习实战》,以及一本关于对抗样本的书:《AI安全之对抗样本入门》
01 深度学习脆弱性
1.1 偷取模型
根据深度学习模型对外提供服务的形式进行分类
①云模式的API:通过遍历算法,在调用云模式的API后,可以在本地还原出一个与原始模式功能相同的模型。
【补充知识】
云API(官方定义):指开发者可以使用云应用编程接口编码,而这个接口具备一项云提供商的服务。但是同时对于云应用也是危险的,因为API也具备受攻击的一面,可能危害敏感业务数据。这意味着提供商和软件开发者需要按优先次序确定云API的安全。
关于云API的安全防御问题:
开发者应该使用无会话安全实践,别不HTTP认证,基于口令的认证或者Web服务安全。无会话安全也促进了更好地云服务可扩展性,因为任何服务器都可以处理用户请求,而且无需在它们之间共享会话。
开发者应该确定是否一个API执行了第二次安全检查,比如用户是否有合适的授权去查看、编辑或者删除服务和数据。一旦最初的认证是清晰的,开发者通常忽略了第二次的安全策略。
云提供商和开发者应该针对常见威胁测试云API安全,比如注入式攻击和跨站伪造。对于云服务提供商正在创建的API,测试尤为重要。然而,用户应该独立的核实云API安全,因为其对于审计和法规遵从非常重要。
如果加密密钥是API调用访问和认证方法论的一部分,就要安全地存储密钥,而且永远不要将其编码到一个文件或者脚本里面。
②私有部署到用户的移动设备或数据中心的服务器上:通过逆向等传统安全技术,把模型文件直接还原。(eg:通过调用AI SDK 的API还原模型文件)
1.2 数据投毒
-
数据投毒:指向深度学习的训练样本中加入异常数据,导致模型在遇到某些条件是会产生分类错误。
-
攻击方式
①通过在离线数据中添加精心构造的异常数据进行攻击,这一方式需要接触到模型的训练数据,但是攻击者半已接触到训练数据,攻击难以发生。
②利用在线数据(典型的场景:推荐系统),通过一定的算法策略,发起访问行为,最终导致系统产生错误。
02 对抗样本(adversarial examples)
2.1 对抗样本定义
在数据集中通过故意添加细微的干扰所形成的输入样本,这种样本导致模型以高置信度给出一个错误的输出。简单地讲,通过在原始数据上叠加精心构造的人类难以察觉得扰动,使深度学习模型产生分类错误。
【补充知识】
机器学习的本质是对条件概率或概率分布的估计。
所以机器学习会涉及到统计学中的置信区间和置信度等机器学习常用指标,这些概念有助于我们从直观上理解评价估计优劣的度量方法。这里有两篇文章解释了这些概念:关于置信区间和置信度的理解、机器学习常用指标。
2.2 对抗样本原理
以经典的二分类问题为例,机器学习模型通过在样本上训练,学习出一个分割平面,在分割平面的一侧的点都被识别为类别一,在分割平面的另外一侧的点都被识别为类别二。
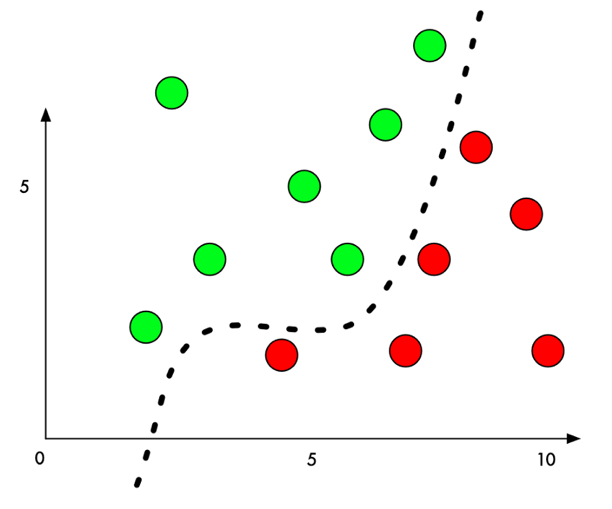
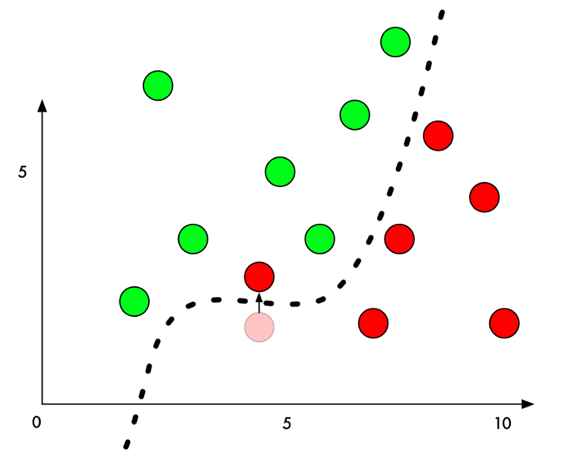
生成攻击样本时,我们通过某种算法,针对指定的样本计算出一个变化量,该样本经过修改后,从人类的感觉无法辨识,但是却可以让该样本跨越分割平面,导致机器学习模型的判定结果改变。
2.3 针对图像分类模型的对抗样本示例
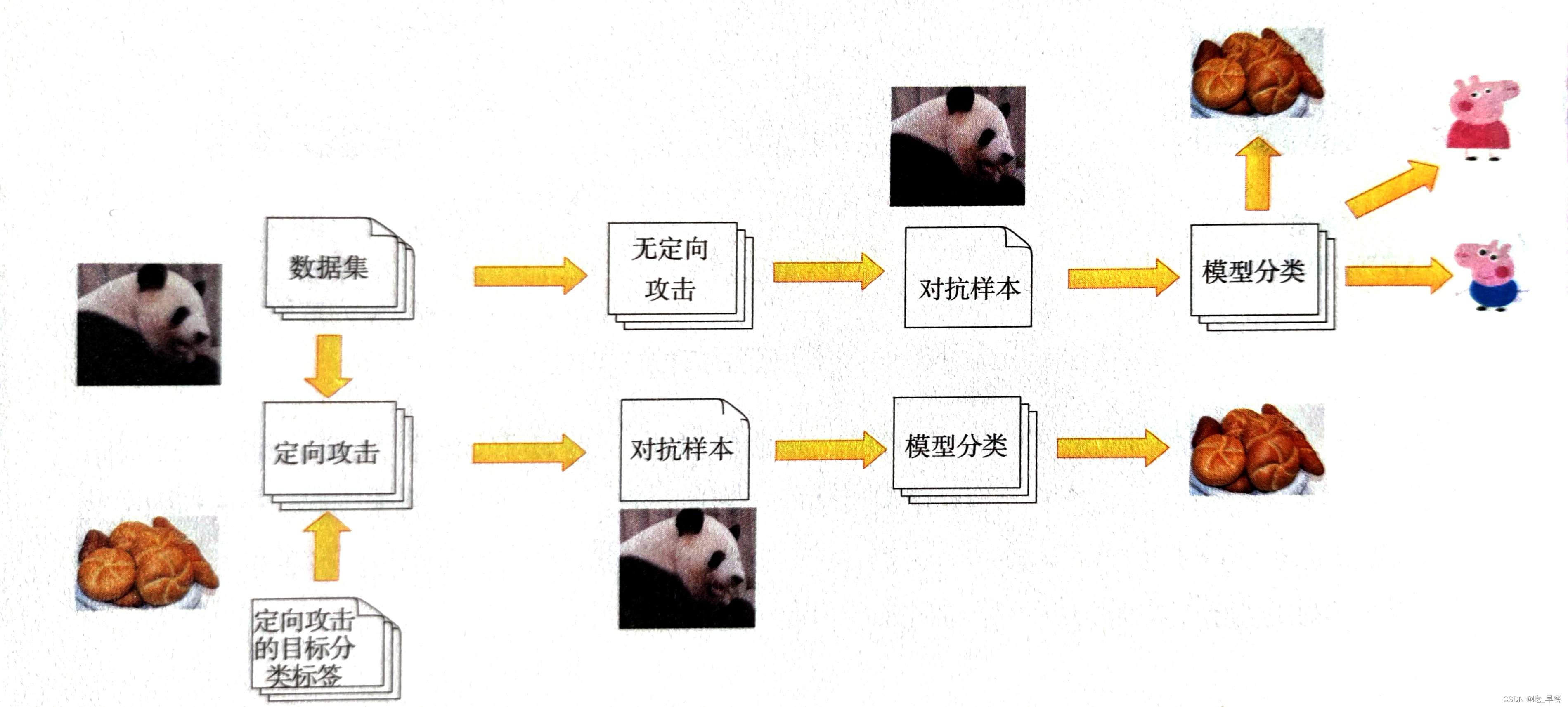
通过在原始图像上添加扰动,对肉眼来说看似还是一只熊猫,但是分类模型会以很大的概率识别为长臂猿。
2.4 对抗样本按照攻击后的效果分类
-
定性攻击(Targeted Attack)
在攻击前会设置攻击目标,攻击后的效果是确定的
-
无定向攻击(Non-Targeted Attack)
不设置攻击目标,只要攻击后的目标发生改变即可
2.5 对抗样本按照攻击成本分类
-
白盒攻击(White-Box Attack)
攻击难度低;前提是能够完整获取模型的结构,包括模型的组成以及隔层的参数情况,并且可以完整控制模型的输入,对输入的控制粒度甚至可以到比特级别。
-
黑盒攻击(Black-Box Attack)
攻击难度大;完全把被攻击模型当成黑盒,对模型的结构没有了解,只能控制输入,通过比对输入和输出的反馈来进行下一步攻击
-
真实世界/物理攻击(Real-World attack/Physical Attack)
难度最大;不了解结构,且对输入的控制很弱。
03 常见检测和加固方法
3.1 攻击方法(脆弱性检测)
-
白盒攻击算法列举:
最相似迭代算法(ILCM)
快速梯度算法(FGSM)
基础迭代算法(BIM)
显著图攻击算法(JSMA)
DeepFool算法
C/W算法
-
黑盒攻击方法列举:
单像素攻击(Single Pixel Attack)
本地搜索攻击(Local Search Attack)
3.2 防御方法(脆弱性加固)
-
加固的常见方法:
特征凝结(Feature squeezing)
空间平滑(Spatial smoothing)
标签平滑(Label smoothing)
对抗训练(Adversarial training)
虚拟对抗训练(Virtual adversarial training)
高斯数据增强(Gaussian data augmentation)
-
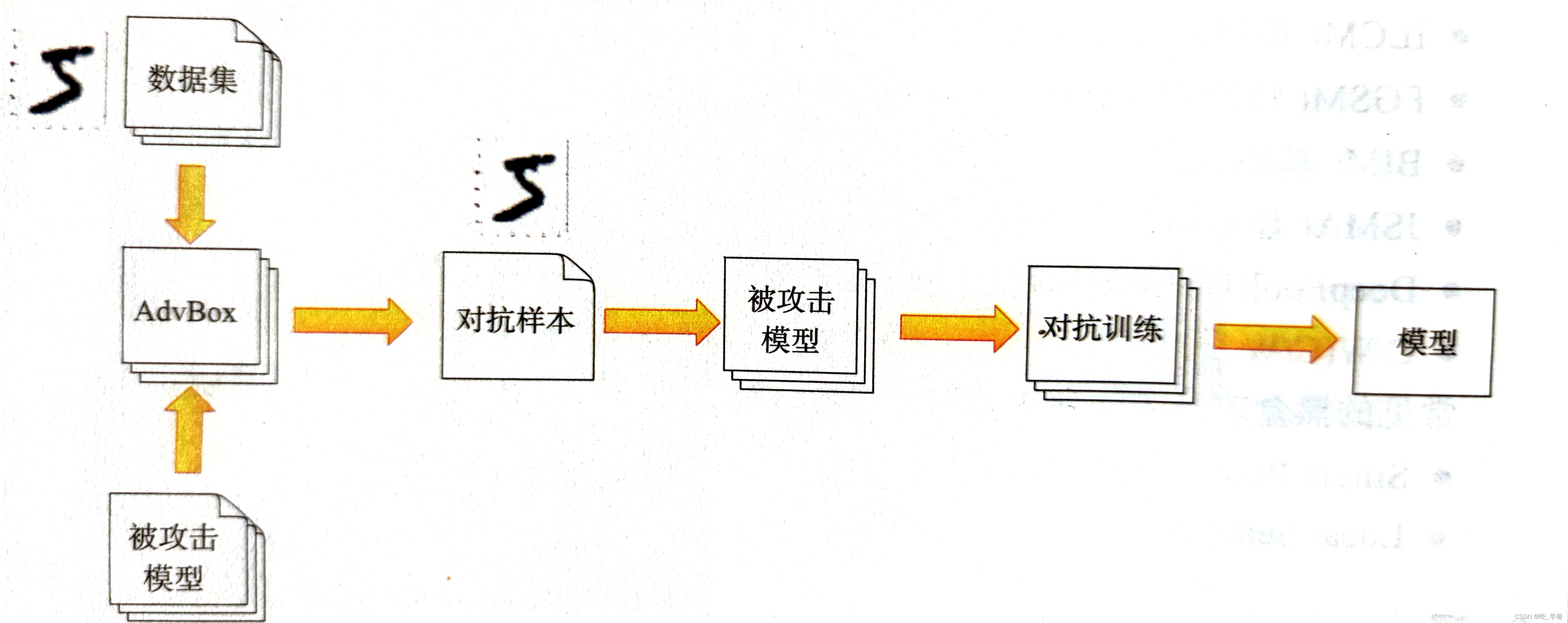
对抗训练(Adversarial training):让深度学习模型认识常见的对抗样本,具有识别对抗样本的能力。(对抗样本工具箱:AdvBox、FoolBox)
高斯数据增强(Gaussian data augmentation):在原始数据上叠加高斯噪声,训练数据叠加噪声后,重新输入给深度学习模型学习,通过增加训练轮数、调整参数甚至增加模型层数,在不降低原有模型准确度的情况下,让新生成的深度学习模型具有了一定的识别对抗样本的能力。
04 总结
以上知识点就是接下来AI安全对抗样本的学习路线,像我一样有web安全基础但对AI没有基础的情况下,算法是比较有难度的,里面有很多高等数学,线性代数,概率统计,离散数学有关的知识点,这是一个挑战,也怪我以前没好好学。
















 9622
9622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











