







一、数据读取过程
1、数据读取的基本流程
客户端连接到NameNode询问某个文件的元数据信息,NameNode返回给客户端一个包含该文件各个块位置信息,然后客户端直接连接对应的DataNode来并行读取块数据;最后,当客户得到所有块后,再按照顺序进行组装,得到完整文件。
2、从编程的角度理解数据读取过程
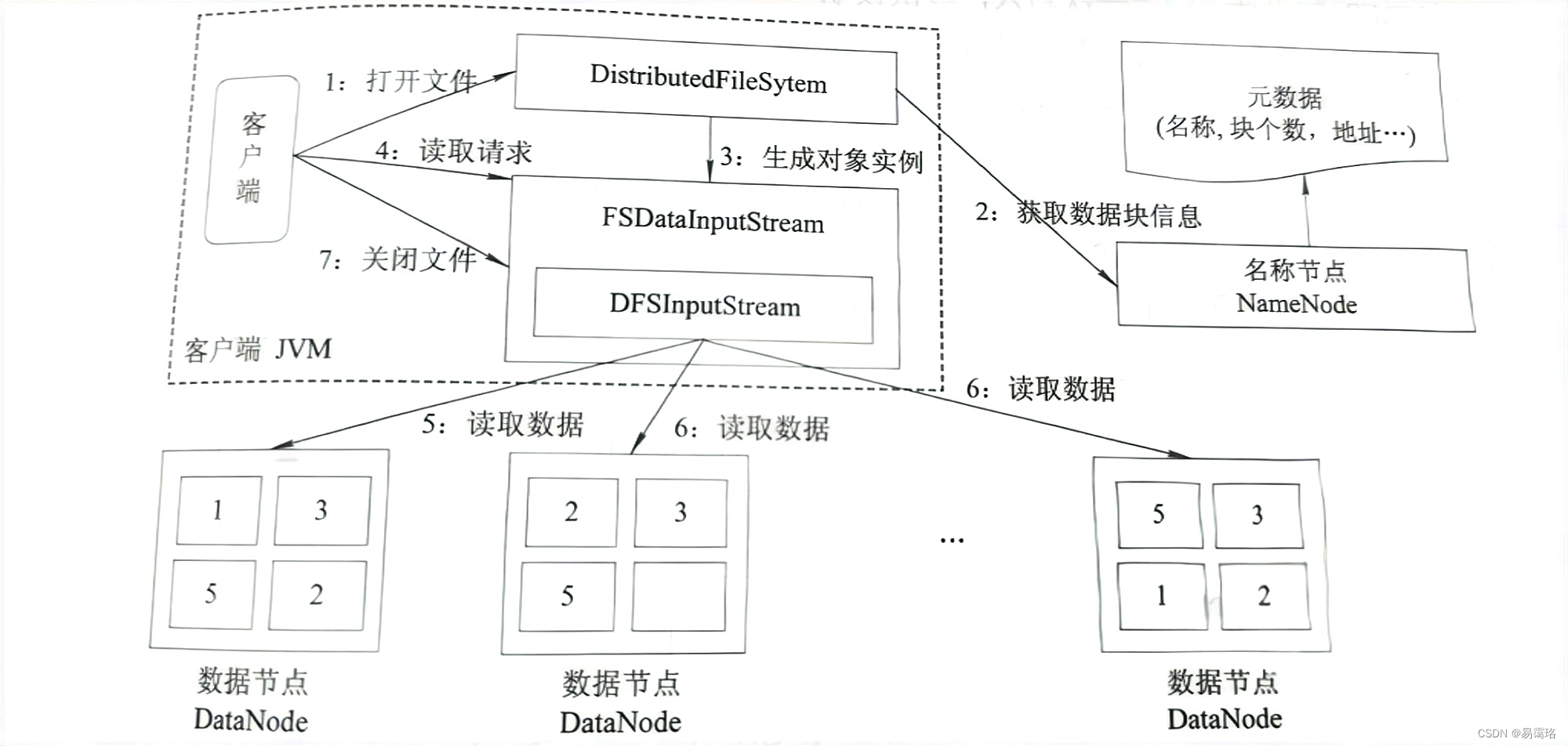
- 客户端生成一个FileSystem实例,并使用此实例的open()函数打开HDFS上的一个文件
- FileSystem用RPC调用NameNode,得到文件的数据块信息,对于每一个数据块,NameNode返回保存数据块的数据节点的地址。
- FileSystem实例获得地址信息后,生成一个FSDataInputStream对象实例返回给客户端。
- 客户端向FSDataInputStream发出读取数据的read()调用
- FSDataInputStream收到read()调用请求,其封装的DFSInputStream选择与第一个数据块最近的DataNode并读取相应的数据返回给客户端,当读完数据块后,DFSInputStream关闭和此数据节点的连接
- DFSInputStream依次选择后续数据块的最近DataNode节点并读取数据返回给客户端,直到最后一个数据块读取完毕。在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数,关闭文件
二、数据写入流程
1、数据写入的基本流程
客户端向NameNode发送文件写请求,NameNode给客户分配写权限。并随机分配块的写入地址——DataNode的IP,同时兼顾副本数量和块Rack自适应算法。
2、从编程的角度理解数据写入过程
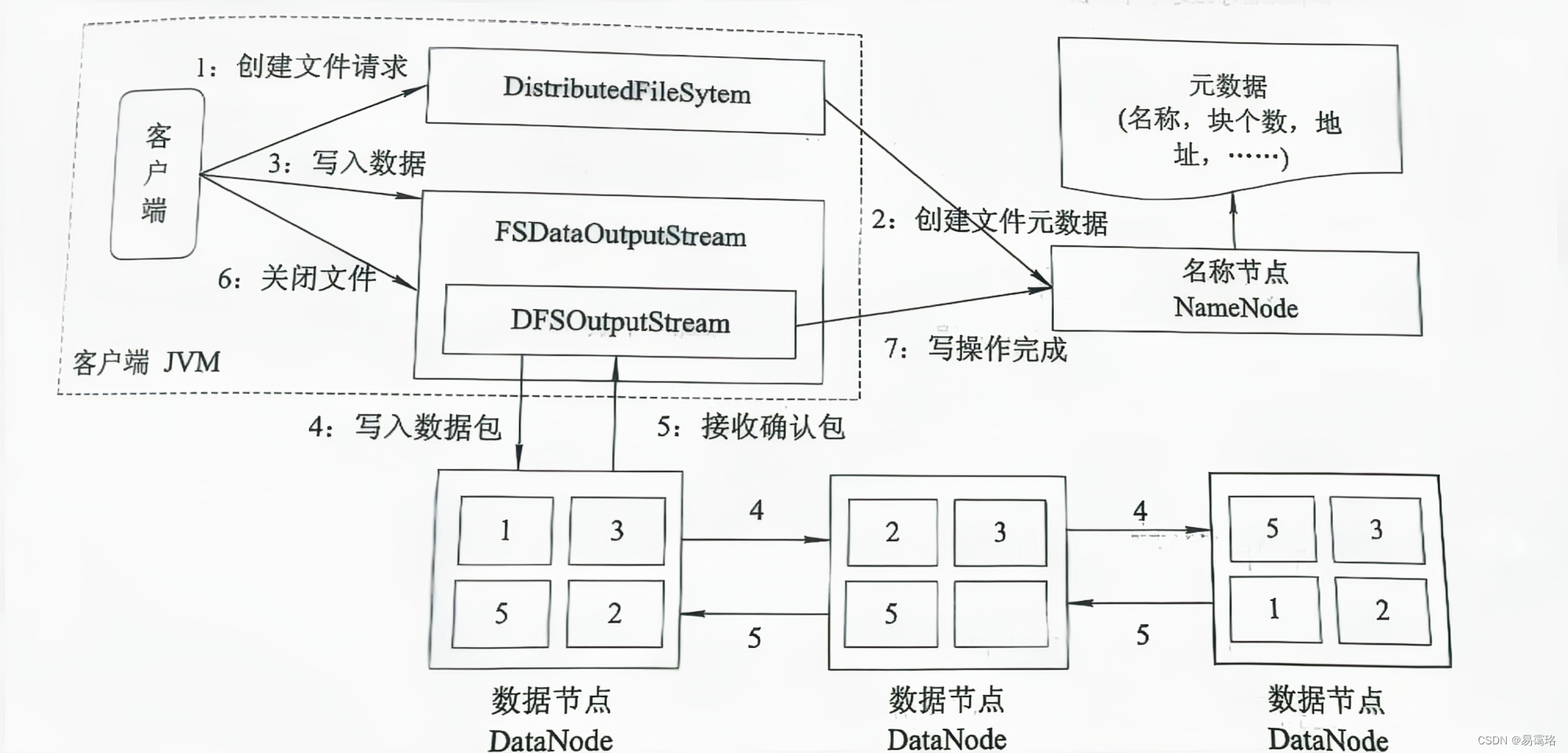
- 客户端生成一个FileSystem实例,并调用create()方法创建一个文件
- FileSystem用RPC调用NameNode,在文件系统的命名空间创建一个新的文件。NameNode首先确定文件原来不存在,并且客户端有创建文件的权限,然后才能创建新文件
- FileSystem返回DFSOutputStream,客户端开始写入数据
- DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer 读取,并通知NameNode分配DataNode,用来存储数据块(每块默认复制3块),分配的数据节点放在一个数据流管道里。Data Streamer将数据块写入管道中的第一个DataNode,;另外两个副本由DataNode传输到相邻DataNode。
- DFSOutputStream为发出去的数据块保存了ack queue,等待数据流管道中的数据节点告知数据已经写入成功
- 客户端结束写入数据后调用close(),此操作将所有的数据块写入数据流管道中的数据节点,并等待ack queue返回成功
- 通知NameNode写入完毕
















 2437
2437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











