







《特征工程入门与实践》读书记录
数据集已放在《特征工程入门与实践》data中,可以自行免费下载,下载链接:
《特征工程入门与实践》data-数据挖掘文档类资源-CSDN下载
也可在官方网站进行下载。
3.1 识别数据中的缺失值
首先导入需要的包,如下所示:
import numpy as np # 数学计算包
import matplotlib.pyplot as plt # 流行的数据可视化工具
import seaborn as sns # 另一个流行的数据可视化工具
import pandas as pd
%matplotlib inline
plt.style.use('fivethirtyeight') # 流行的数据可视化主题读入文件数据:
pima_column_names = ['times_pregnant', 'plasma_glucose_concentration', 'diastolic_blood_pressure', 'triceps_thickness', 'serum_insulin', 'bmi', 'pedigree_function', 'age', 'onset_diabetes']
pima = pd.read_csv('D:\下载\源代码文件\源代码文件\data\pima.data', names=pima_column_names)
pima.head()结果如下所示:

然后就可以看一下热力图,判断一下它们之间的相关性之类的,这些都是比较基本的东西,如下所示:
# 数据集相关矩阵的热力图
sns.heatmap(pima.corr())
# plasma_glucose_concentration很明显是重要的变量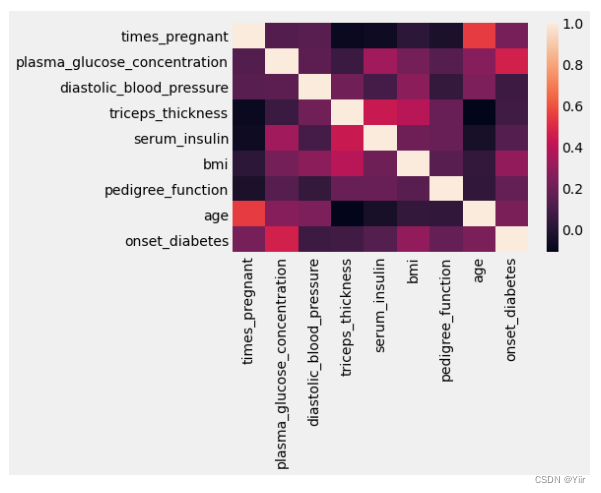
我们也可以具体看一下他们之间的相关矩阵,使用如下函数:
pima.corr()['onset_diabetes'] # 相关矩阵
# plasma_glucose_concentration很明显是重要的变量这里需要注意,如果说不加后面那个[]里面的内容的话,就会是一个dataframe,我们可以选取一列去查看,就像代码中一样。
然后我们可以去查看数据中是否有缺失值,一开始用isnull(),我们发现数据中是没有缺失值的,但是这个时候注意,可以用describe看一下数据的大体分布情况,可以看到是min值有些是0,是不符合常理的,所以可以看出,其中的空值都是让null被0填充了。
3.2 处理数据集中的缺失值
columns=['serum_insulin','bmi','plasma_glucose_concentration','diastolic_blood_pressure','triceps_thickness']
for col in columns:
pima[col].replace([0],[None],inplace=True)
然后再看缺失值,就合适很多了。

3.2.1 删除有害的行
有两种方式进行缺失值的处理,一个是删除有害的行,就是直接dropna(),有一个方法可以去进行删除行之后的表格变化,可以这样进行,如下所示:
ax=((pima_dropped.mean()-pima.mean())/pima.mean())
plt1=ax.plot(kind='bar')
plt1.set_ylabel('% change')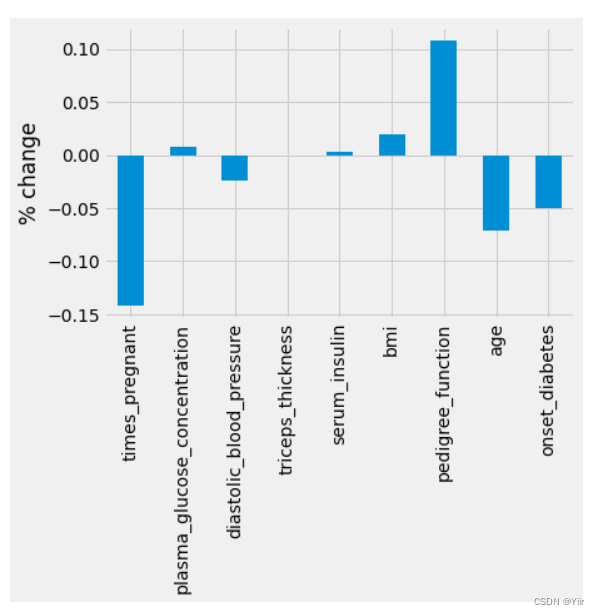
在这个之后,可以进行机器学习的一部分训练,如下所示:
knn=KNeighborsClassifier()
params={'n_neighbors':[1,2,3,4,5,6,7,8,9,10]}
grid=GridSearchCV(knn,params)
grid.fit(X_dropped,y_dropped)
print(grid.best_score_, grid.best_params_)得到0.76的正确率,还是不错的正确率(而且用了很少的数据集)
3.2.2 填充缺失数据
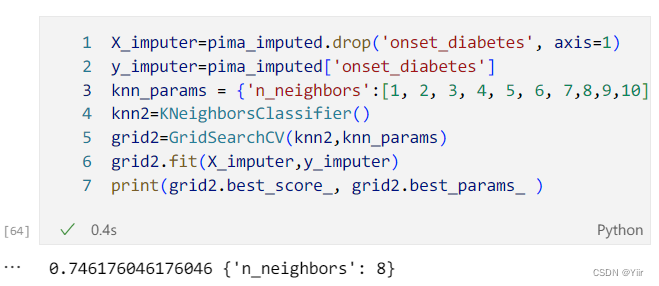
这部分才是重点部分,首先,我们可以指定一个填充策略,如果这个填充策略是对于整个表格的话,那我们可以使用一个简单的流水线的方式,如下所示:
from statistics import mean
from sklearn.impute import SimpleImputer
imputer=SimpleImputer(strategy='mean')
pima_imputed=imputer.fit_transform(pima)
pima_imputed=pd.DataFrame(pima_imputed,columns=pima_column_names)
pima_imputed.isnull().sum()这里需要注意两个点
1. fit之后生成的是一个数组形式,如果想要进行后续的操作的话,可以将其先变成dataframe的形式
2. isnull()得到的是一个dataframe,如果想要得到最后的结果的话,可以sum()一下,就看到每一列的null值了。
然后还是看一下结果,代码和上述一样。
3.2.3 在机器学习流水线中填充值
首先我们导入相应的包,然后先进行划分,然后再进行训练数据的平均值的计算并且填充,填充到xtrain和xtest里面,这里需要注意的是,如果用整个数据集的平均值进行填充是不对的,正确的方法如下所示:
# 使用相同的随机状态,保证划分不变
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=99)
training_mean = X_train.mean()
X_train = X_train.fillna(training_mean)
X_test = X_test.fillna(training_mean)
print(training_mean)如上所示:先进行数据集的划分,然后取训练数据单独进行平均值的求解
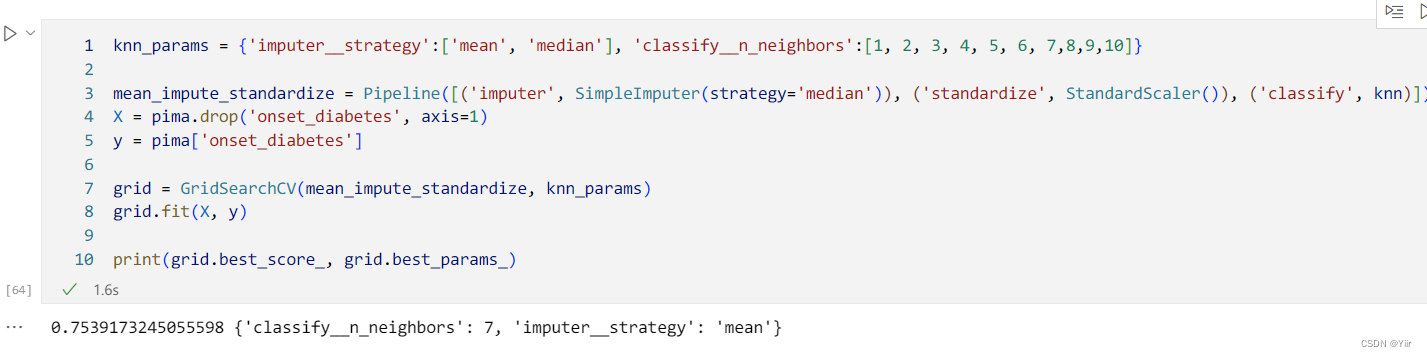
然后我们放入pipline里面,其实pipline很简单,就是在里面定义一定的方法,然后顺序执行,代码3.3 如下所示:
from sklearn.pipeline import Pipeline
knn_params = {'classify__n_neighbors':[1, 2, 3, 4, 5, 6, 7,8,9]}
# 必须重新定义参数以符合流水线
knn = KNeighborsClassifier() # 实例化KNN模型
mean_impute = Pipeline([('imputer', SimpleImputer(strategy='mean')), ('classify', knn)])
X = pima.drop('onset_diabetes', axis=1)
y = pima['onset_diabetes']
grid = GridSearchCV(mean_impute, knn_params)
grid.fit(X, y)
print(grid.best_score_, grid.best_params_)
mean_impute = Pipeline([('imputer', SimpleImputer(strategy='mean')), ('classify', knn)])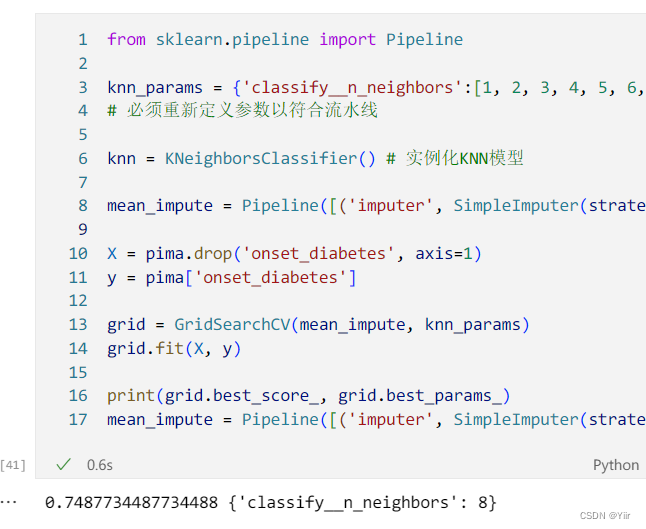
3.3 标准化与归一化
上面我们都忽视了一个很重要的部分,就是标准化与归一化!下面我们再进行标准化和归一化的操作。
标准化操作如下所示:
scaler=StandardScaler()
glucose_z_score_standardized=scaler.fit_transform(pima_imputed_mean)
glucose_z_score_standardized=pd.DataFrame(glucose_z_score_standardized,columns=pima_column_names)
glucose_z_score_standardized['plasma_glucose_concentration'].hist()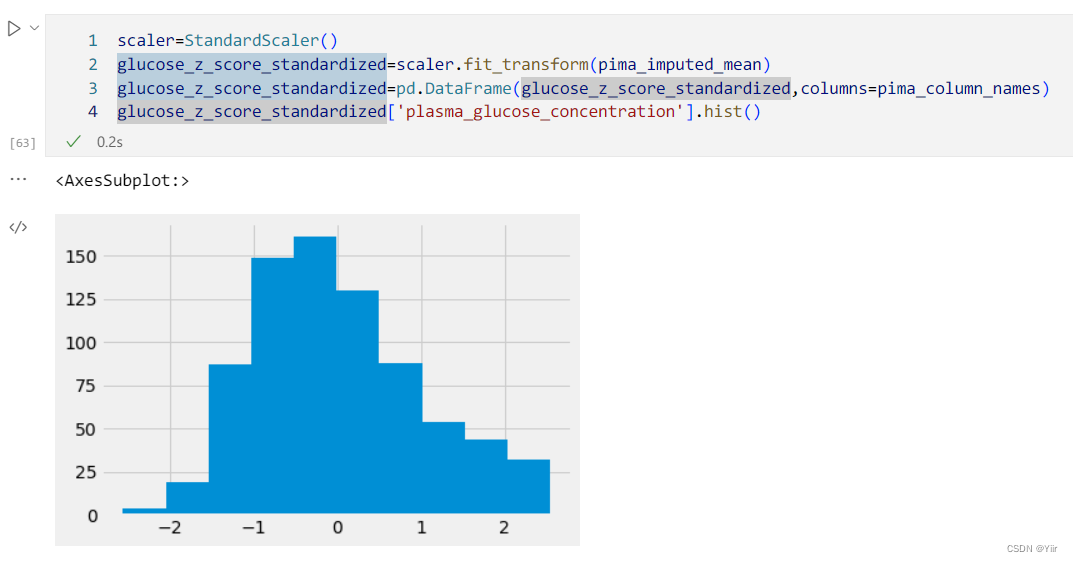
然后还是使用上面那个方法进行准确率测试,为0.75
如果用minmax的话,是0.76,又提升了一些

这里我们可以再稍微扩展一下知识:
列标准化有两种方式: z分数标准化和最大最小标准化,然后这两种标准化的方式有一些不同,第一种是用到了均值和方差,第二种是用到了最大值和最小值进行标准化。
分别用到的库函数是
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler行标准化是针对行进行的标准化,主要是让每一行都有相同的范数
用到的库函数是:
from sklearn.preprocessing import Normalizer # 行归一化算法受尺寸约束举例:
knn:因为依赖于欧几里得距离
k-means:因为依赖于欧几里得距离
逻辑回归、支持向量机、神经网络:如果使用梯度下降算法来进行权重学习的话,就受到尺寸的约束
主成分分析:特征向量将偏向于较大的列















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









