






1、项目介绍
技术栈:
Python语言、Vue前端框架、Flask后端框架、深度学习LSTM算法、 豆瓣电影、Echarts 可视化分析、scrapy爬虫、影评情感分析、MySQL数据库、双协同过滤推荐算法(基于用户和基于物品)
2、项目界面
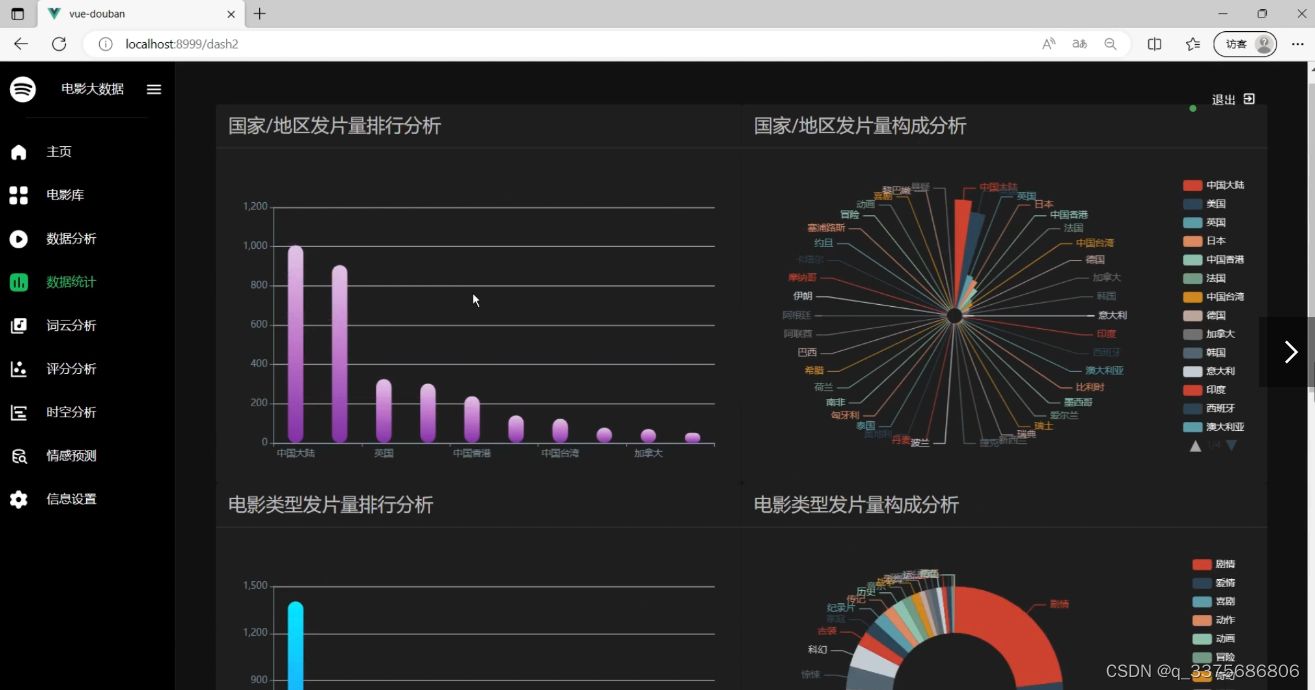
(1)电影数据可视化分析—柱状图、南丁格尔玫
3、项目说明
电影数据采集分析推荐系统是一个基于Python语言、Vue前端框架和Flask后端框架开发的应用。系统利用scrapy爬虫技术从豆瓣电影网站上获取电影相关数据,并结合MySQL数据库进行存储和管理。
在数据采集完成后,系统利用深度学习LSTM算法对电影影评进行情感分析,以了解用户对电影的评价和情感倾向。这有助于推荐系统根据用户的喜好和情感偏好为其提供个性化的电影推荐。
为了更好地展示和分析电影数据,系统还使用Echarts可视化分析工具,将采集到的数据以图表的形式进行展示,帮助用户更直观地理解电影的相关信息和趋势。
而在为用户提供电影推荐时,系统采用协同过滤推荐算法,通过分析用户的历史行为和其他用户的喜好,找出相似的用户或电影,从而给出个性化的推荐结果。
总之,电影数据采集分析推荐系统是一个综合运用了Python语言、Vue前端框架、Flask后端框架、深度学习LSTM算法、豆瓣电影、Echarts可视化分析、scrapy爬虫、影评情感分析、MySQL数据库和协同过滤推荐算法的应用。通过数据采集、情感分析和个性化推荐,该系统为用户提供了更好的电影观影体验。
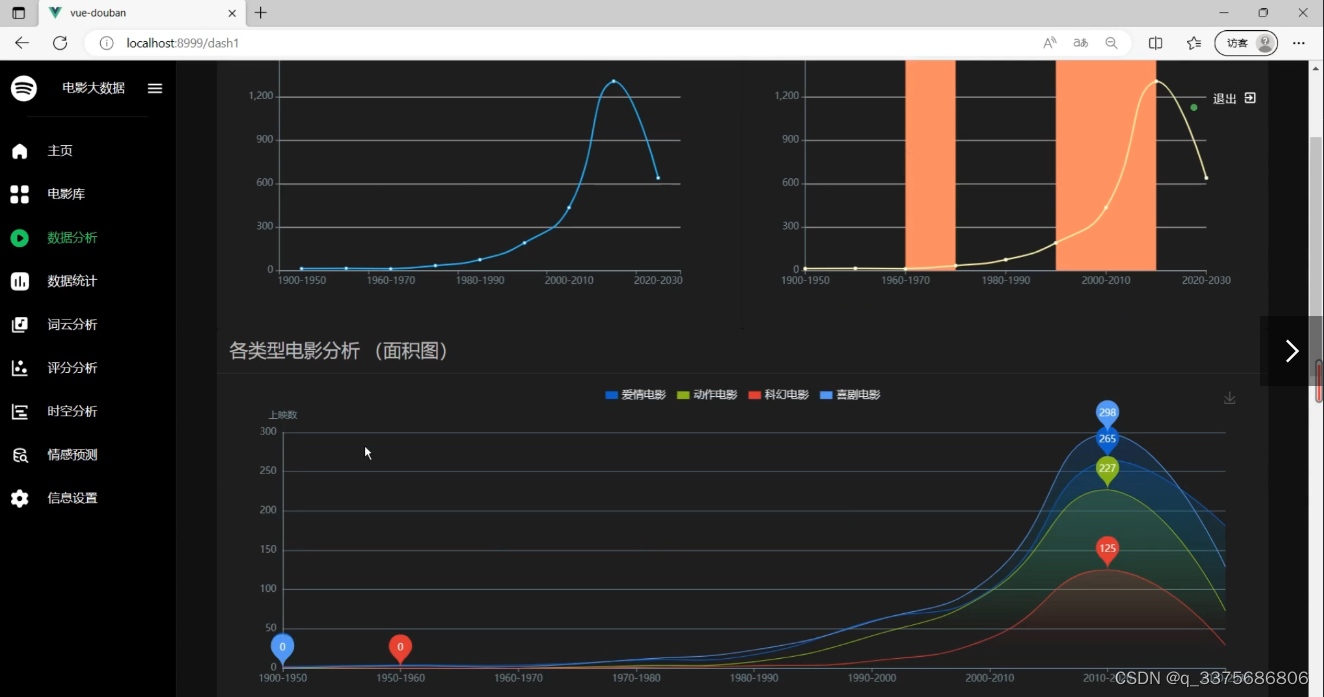
(2)电影数据可视化分析—面积图、曲线图
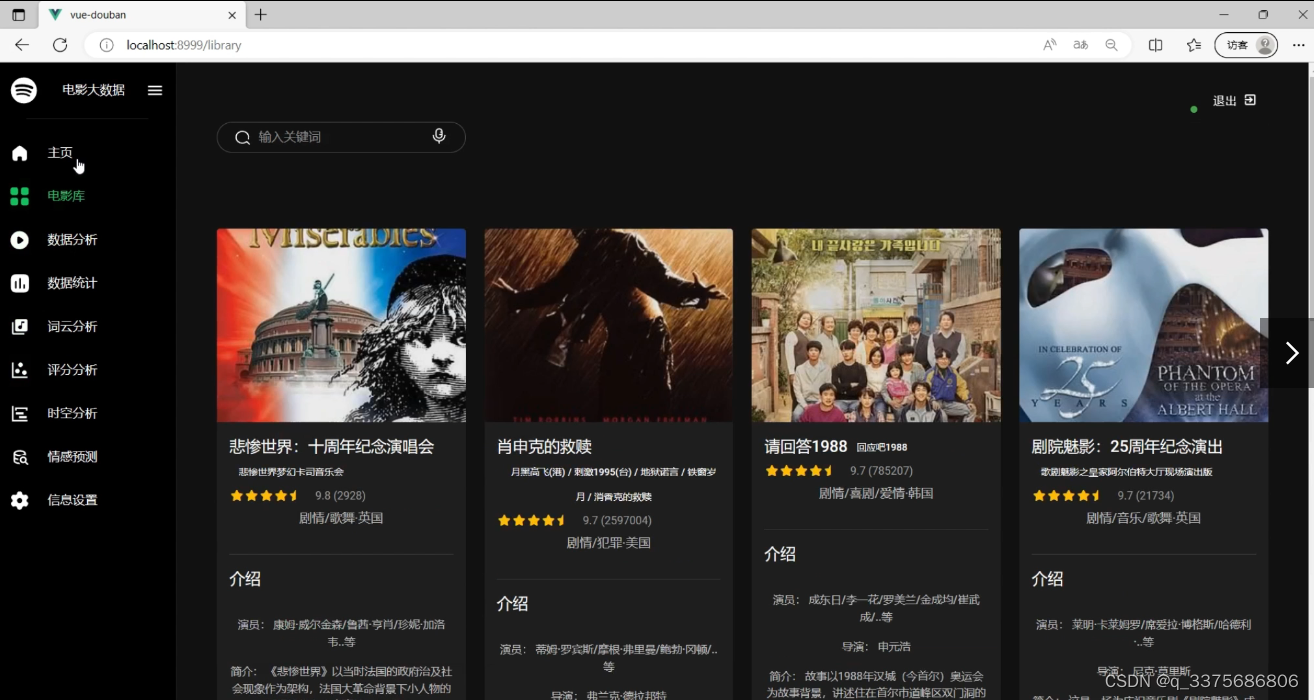
(3)电影数据展示
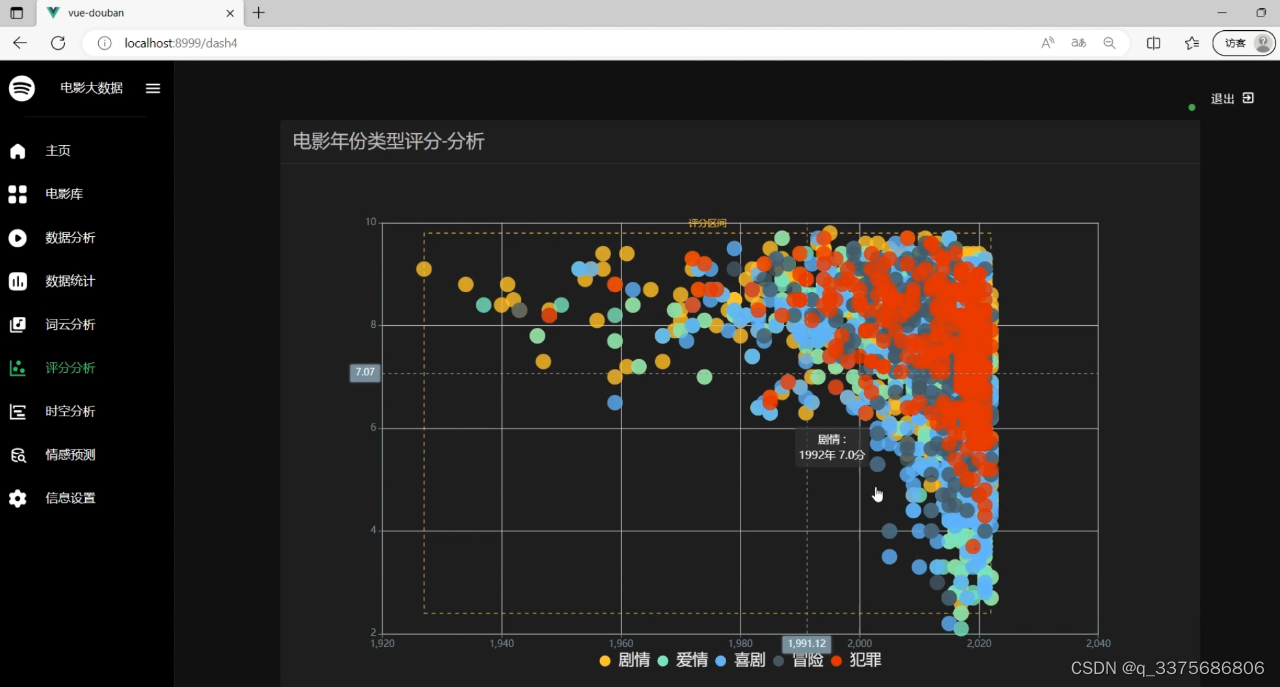
(4)电影年份类型评分分析(散点图)
(5)深度学习LSTM算法情感分析
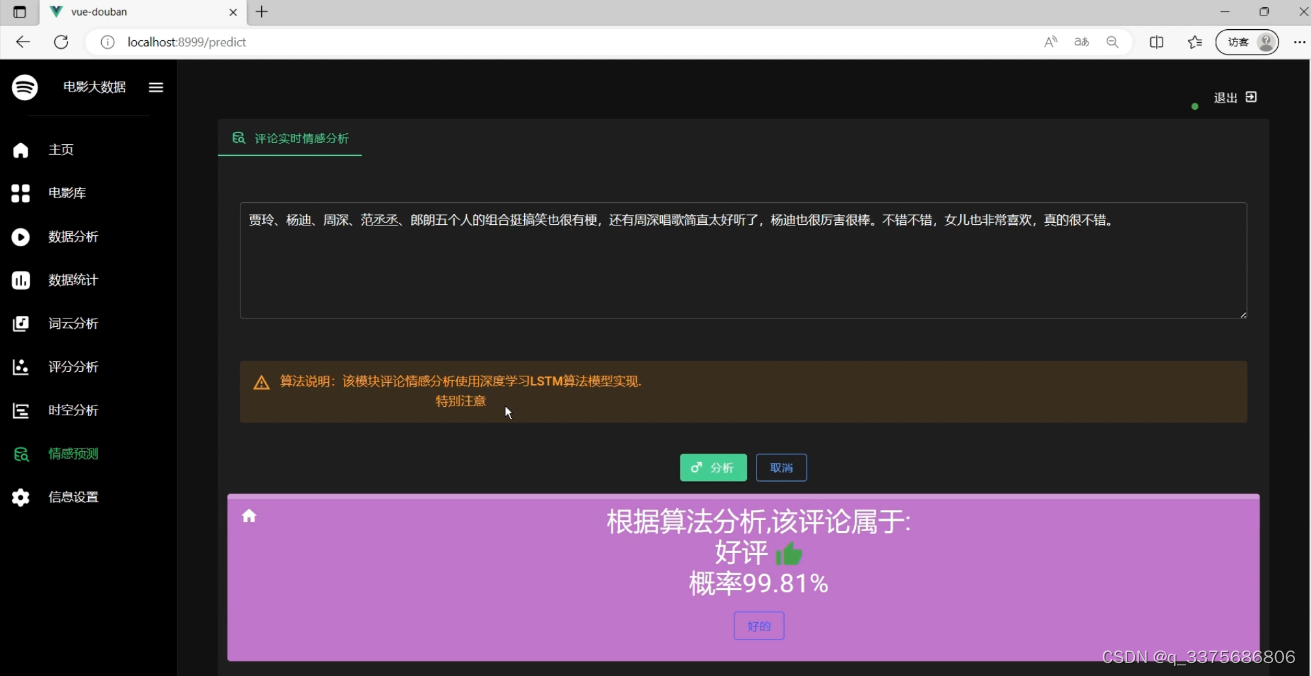
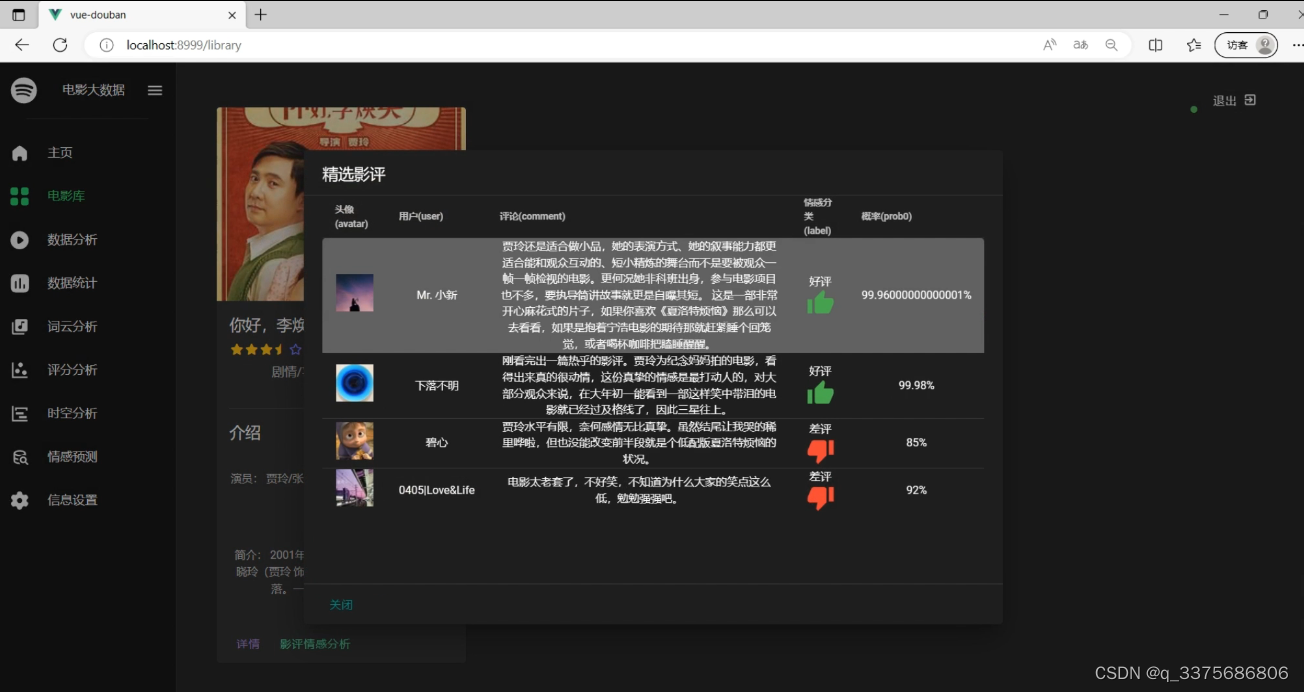
(6)影评情感分析
(7)注册登录界面
瑰图















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









