






研究方法:
开发技术
前端:vue.js
后端:jdk1.8+maven+springboot+mybatis
数据库:mysql5.7
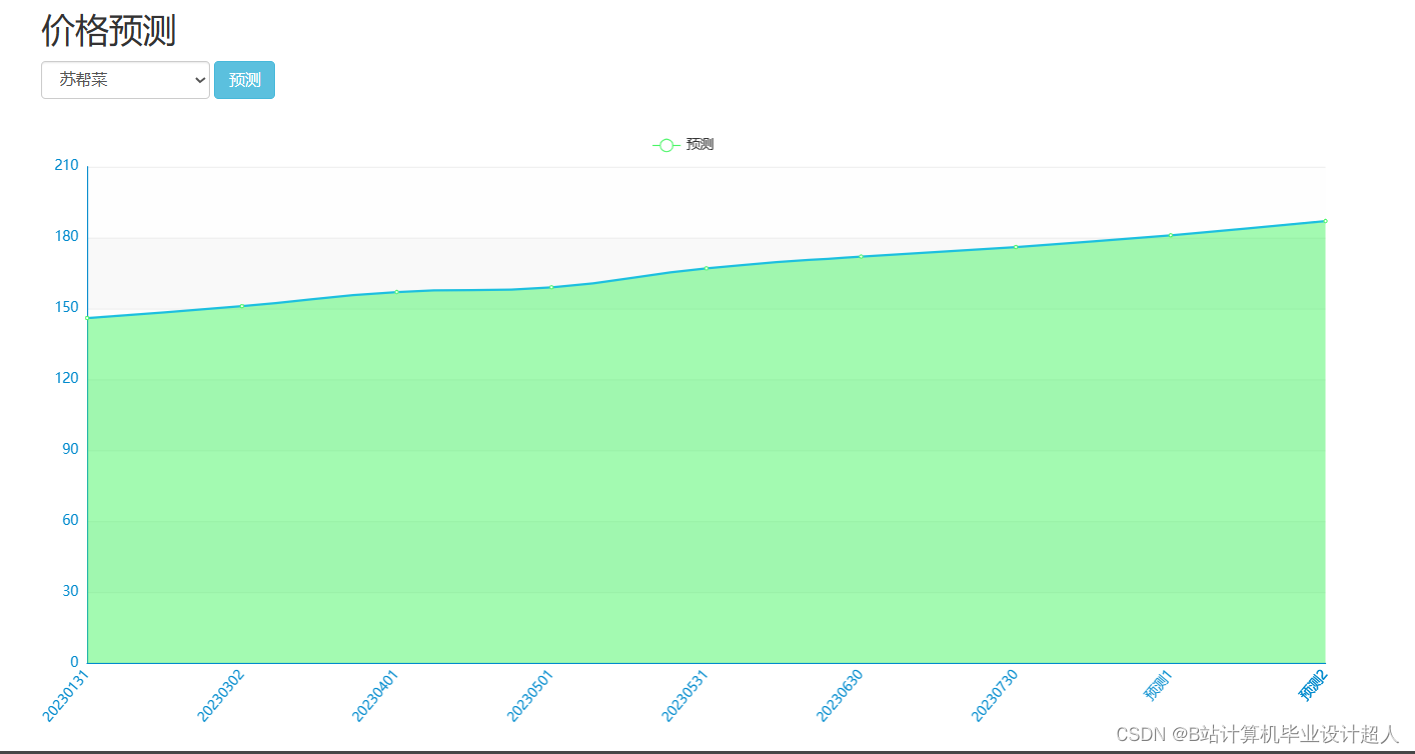
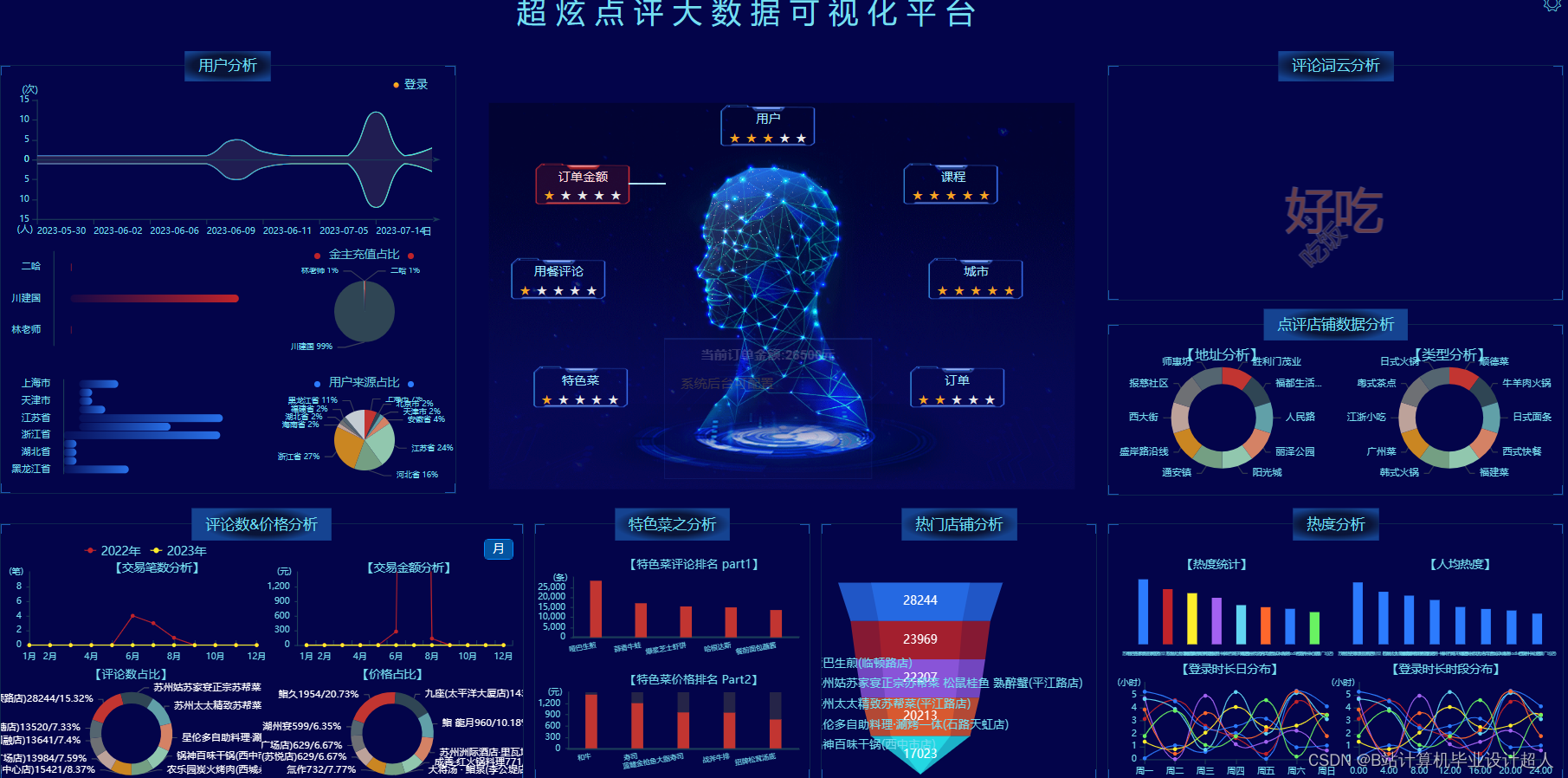
算法(机器学习、深度学习):Python实现协同过滤算法(基于用户、基于物品全部实现)、基于神经网络的混合CF推荐算法进行推荐、Python实现lstm情感分析(美食评论)
爬虫:python、requests、chrome_driver
实现思路
①订单支付调用支付宝沙箱支付模式,可以在页面通过账号+密码的方式支付,也可以使用手机扫码支付;
②用户评论使用lstm情感分析机器学习算法进行数据分析,对情感倾向、准确率进行直观显示;
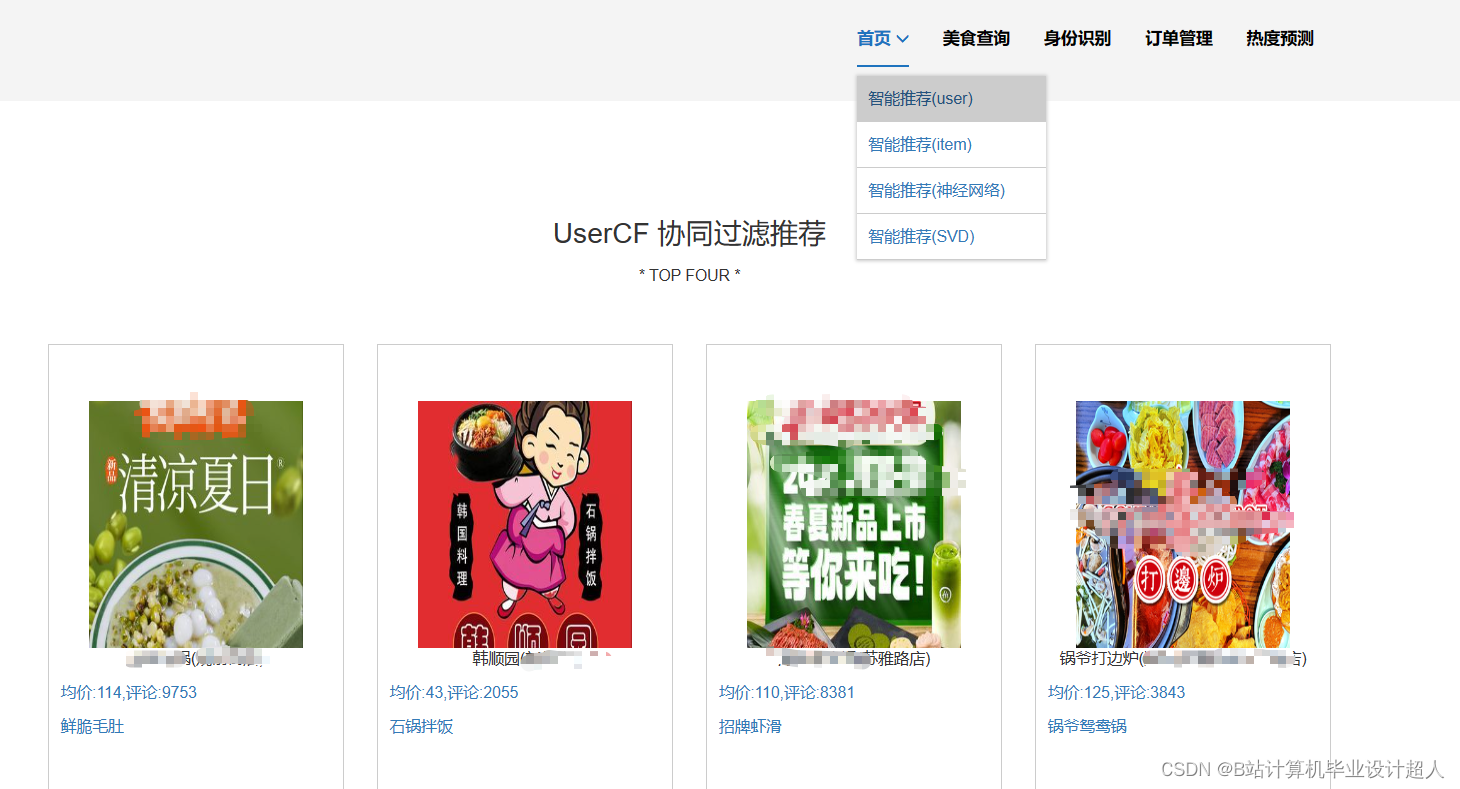
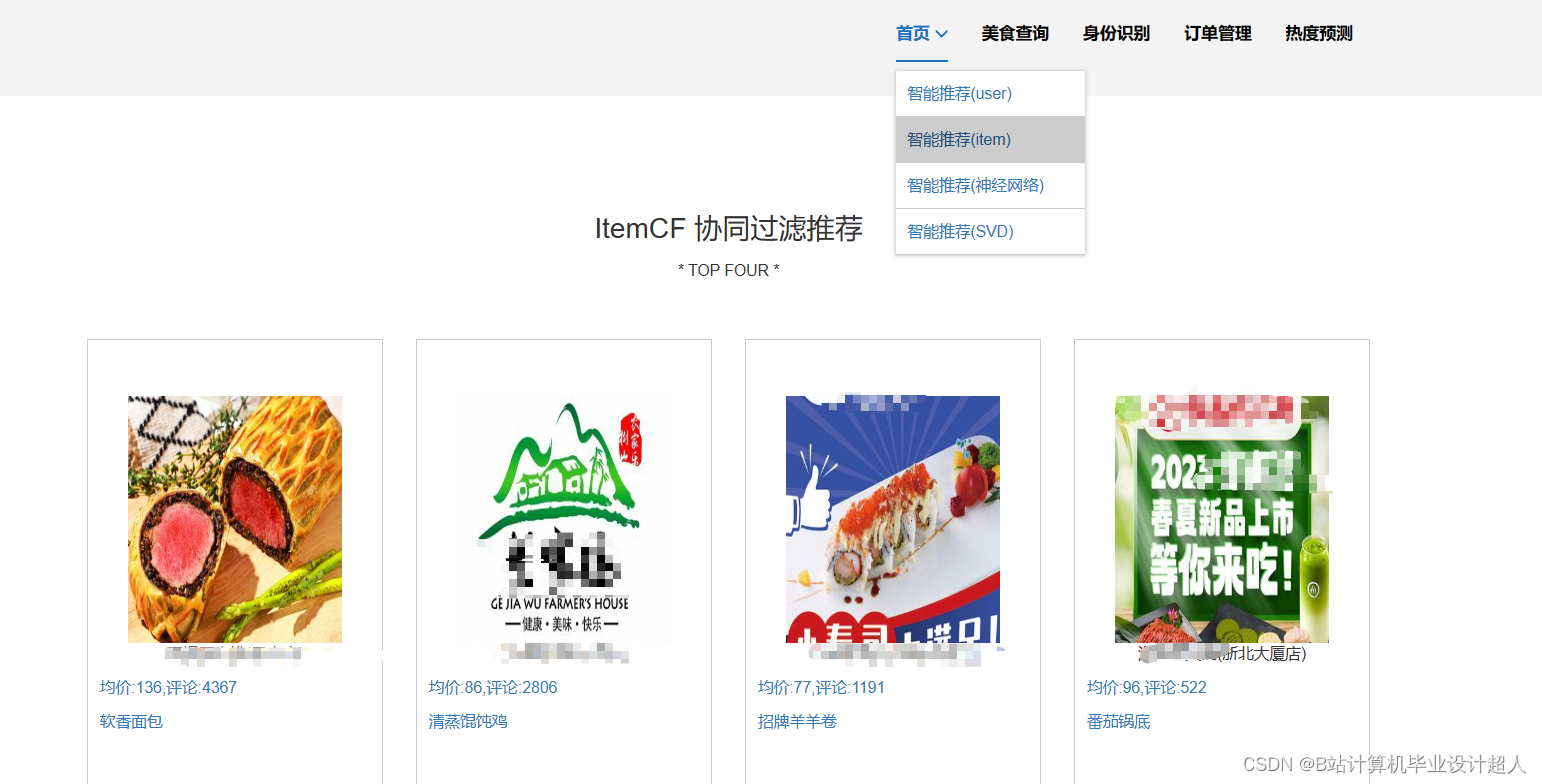
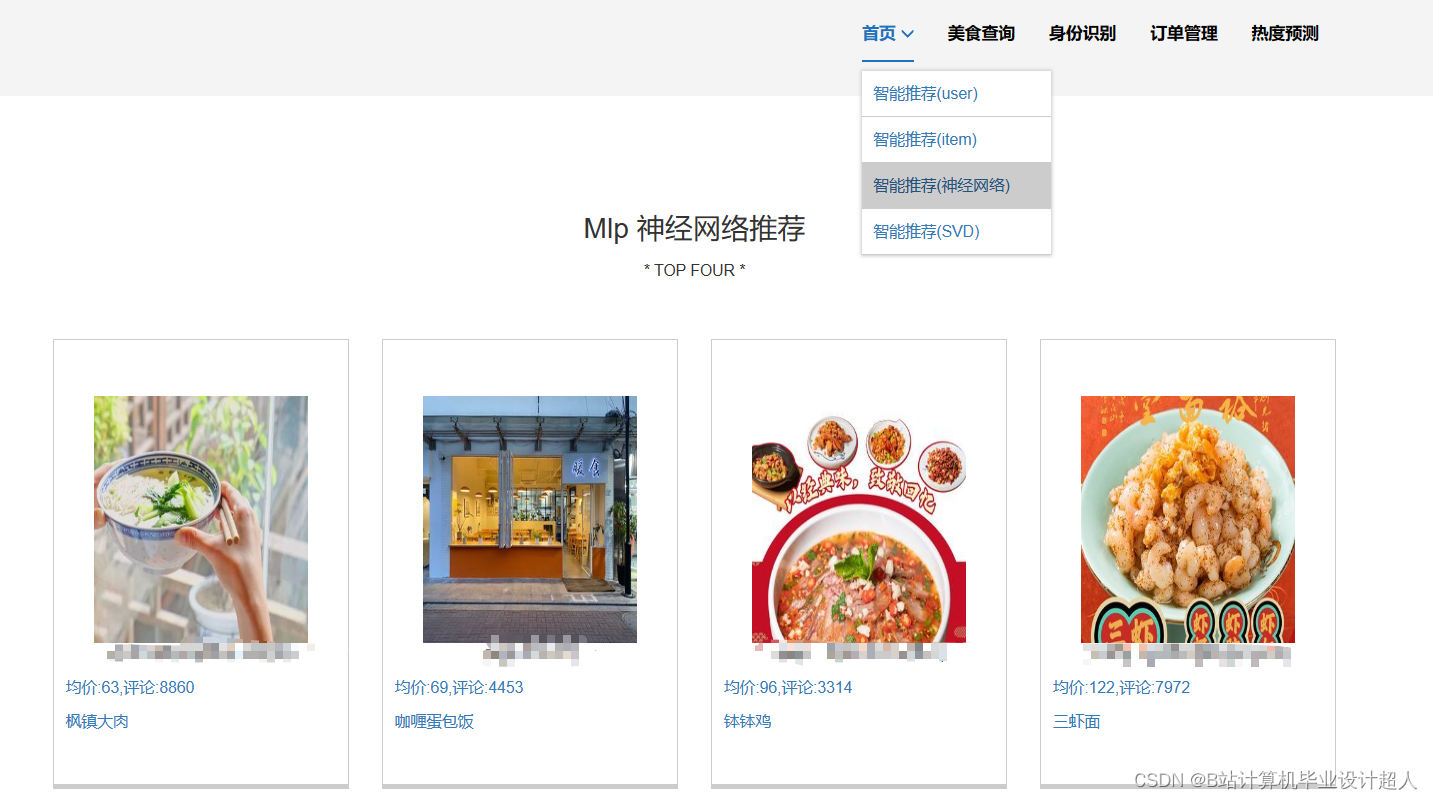
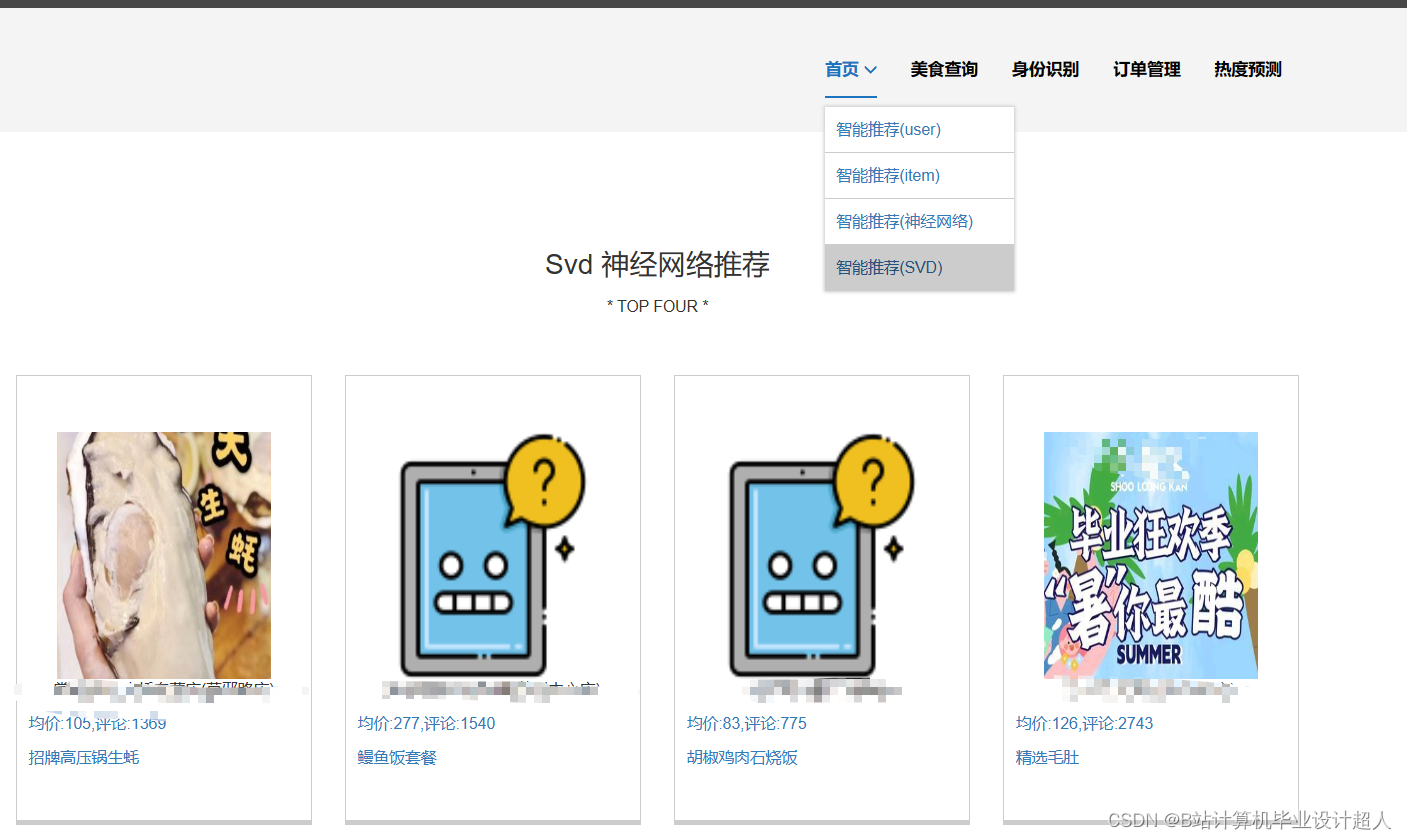
③基于协同过滤算法进行美食推荐,有基于物品的推荐实现,也有基于物品实现的推进;基于神经网络的混合CF推荐算法进行美食推荐;
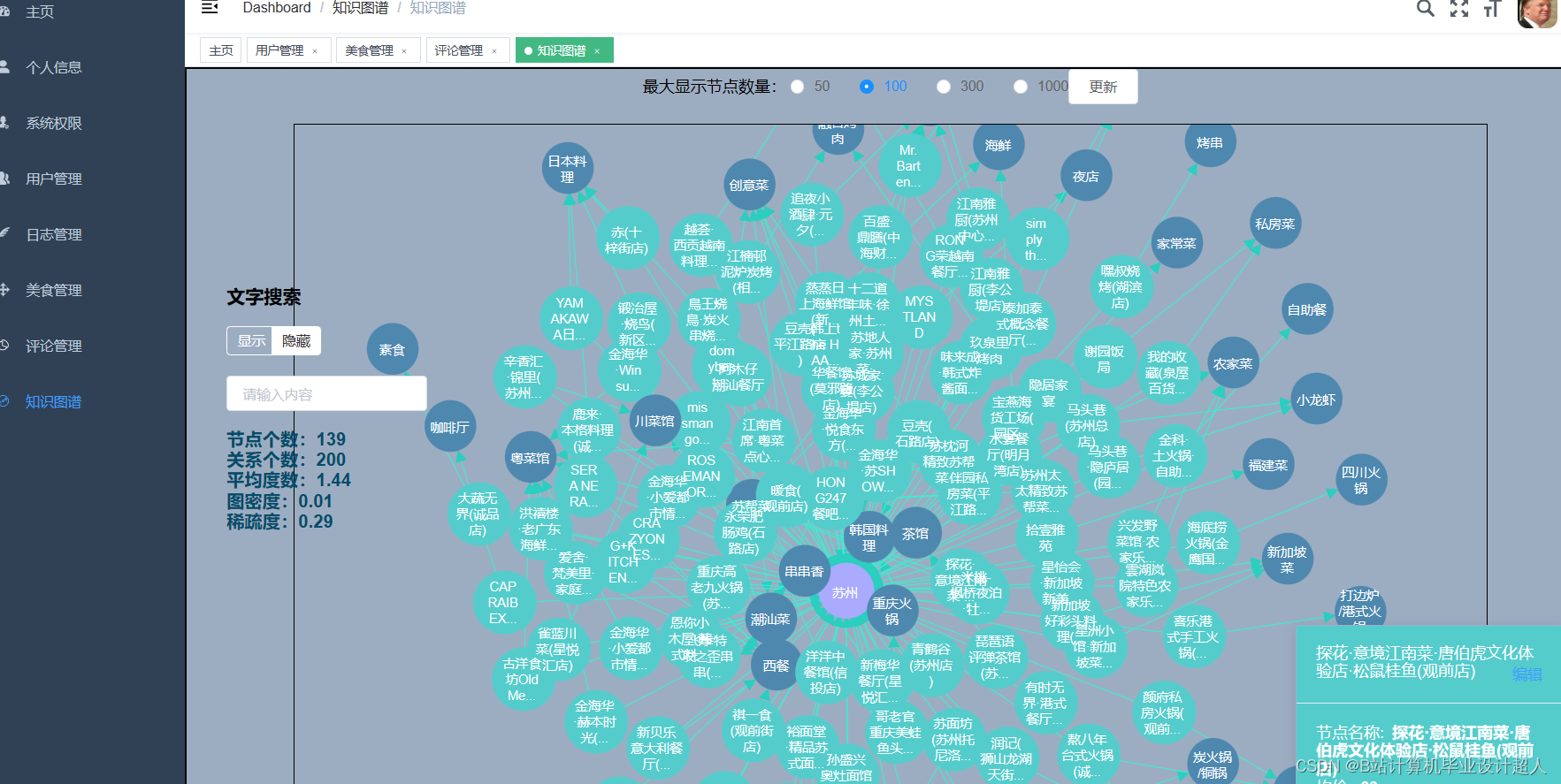
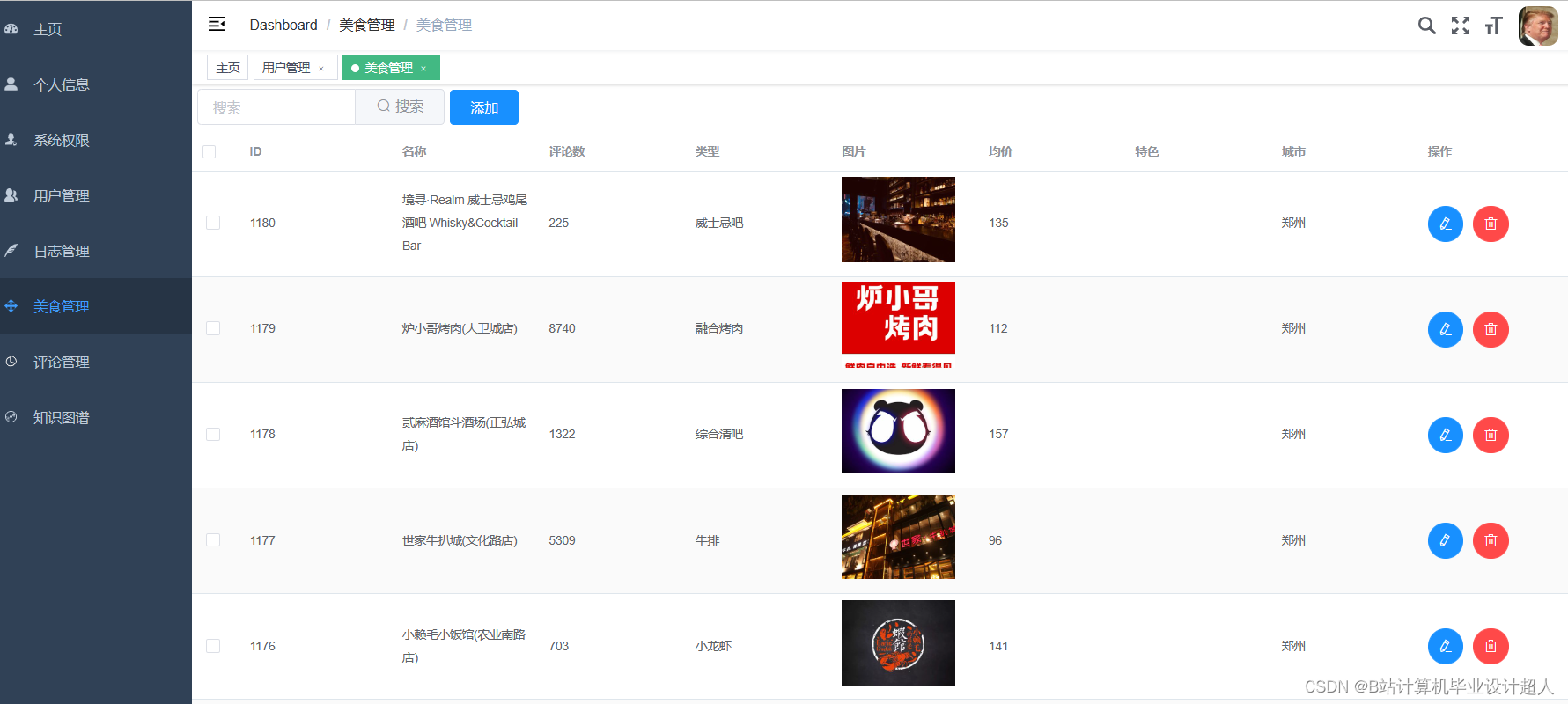
④使用Python爬虫技术爬取美食数据,对数据进行清洗,存储到mysql为数据分析、可视化提供数据集;
















 223
223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









