






目录
1. 概述(注解+创建业务层对象+创建接口+调用业务层实现)
2.3. @RequestMapping("")——设定前缀链接
2.6. 用于生成API文档的注解 @Api(value =" ",tag={" "})——类名上
2.7. ApiOperation("") ——对特定api进行简要描述的记录 (方法名上)
2.8. @ApiParam(" ")——对主要属性的描述记录
3.2. 创建控制器类并且调用业务层(Service)进行具体实现
2.3. 拓展知识(@Valid 和 @Validated)
2.4. 业务层实现类——调用Mapper(Dao)查看或修改数据,并返回对应数据类型给Controller控制层
三.DAO(Mapper)持久层——包含了对数据库的复杂操作方法
2.1 继承BaseMapper<实体类>(记得@Repository注入)
3.1. 对XML文件的声明和DOCTYPE定义,格式都是固定且一致的
3.2. 命名空间定义:制定了该配置文件所对应的java的Mapper接口
3.10. ——只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR
3.11. —— 动态更新:会删掉额外的逗号,(用于update语句中)
4.3. 步骤3:勾选配置使用技术 (Mysql,web,Mybatis,lombok)
4.4. 步骤4:pom.xml补全依赖(手动在pom.xml中配置添加)
4.7. 步骤7:创建Dao接口(extends BaseMapper)
1.1. @Data(必备:开启setter,getter等方法)
1.2. @Tostring(类)(自动生成 toString() 方法)
1.3. @NoArgsConstructor 和 @AllArgsConstructor(必备:生成构造函数)
1.4. @Accessors(chain = true)——启动链式调用(必备)
1.5. @TableName(“数据库名”,autoResultMap = true)(必备)
1.6.@EqualsAndHashCode(callSuper = false)(提供equals()和hashCode()方法)
1.7. @ApiModel("对象名称")(API注解文档)
1.8. @ToBuilder(toBuilder = true)(创建副本)
1. @TableId(value = "id", type = IdType.AUTO)
2. @TableField(value = " ",fill = ,exist = false,select = false)
5.@JsonFormat(pattern = "yyyy-MM-dd")
7. @DateTimeFormat(pattern = "yyyy-MM-dd")
9. 逻辑删除(deleted)@TableLogic——记得在数据库中加入deleted列
3.3. LambdaQueryWrapper——更好地避免前面的属性书写错误
6.3. 将每个模型类的主键ID策略都设置为assign_id.
6.5. 开启日志输出到控制台:(application.properties)
总结
- DAO面向表,Service面向业务。后端开发时先数据库设计出所有表,然后对每一张表设计出DAO层,然后根据具体的业务逻辑进一步封装DAO层成一个Service层,对外提供成一个服务。
- 在具体的项目中,其流程为:Controller层调用Service层的方法,Service层调用Dao层中的方法,其中调用的参数是使用Entity层进行传递的。总的来说这样每层做什么的分类只是为了使业务逻辑更加清晰,写代码更加方便,所以有时候也需要根据具体情况来,但是大体的都是这样处理的,因为它其实就是提供一种规则,让你把相同类型的代码放在一起,这样就形成了层次,从而达到分层解耦、复用、便于测试和维护的目的。
一. Controller(控制层)——接口
1. 概述(注解+创建业务层对象+创建接口+调用业务层实现)
Controler层:(控制层 )控制业务逻辑
Controller层负责具体的业务模块流程的控制,其实就是与前台互交,把前台传进来的参数进行处理,controller层主要调用Service层里面的接口控制具体的业务流程,控制的配置也需要在配置文件中进行。
注:Controler负责请求转发,接受页面过来的参数,传给Service处理,接到返回值,再传给页面。
2. 常用注解
2.1. @RestController
声明此类是restful风格的控制器
2.1.1. @GetMapping(" ")——从服务器取出资源(一项或多项)
详情见HTML && Servlet && JSP 的 五 Springboot 中对参数值的获取
@PathVariable

@RequestParm

2.1.2. @PostMapping() —— 在服务器创建一个新资源(添加)

2.1.3. @PutMapping() —— 在服务器更新资源 (修改)

2.1.4. @DeleteMapping() —— 从服务器删除资源 (删除)

2.2. Restful风格参数传递
2.2.1. @PathVariable
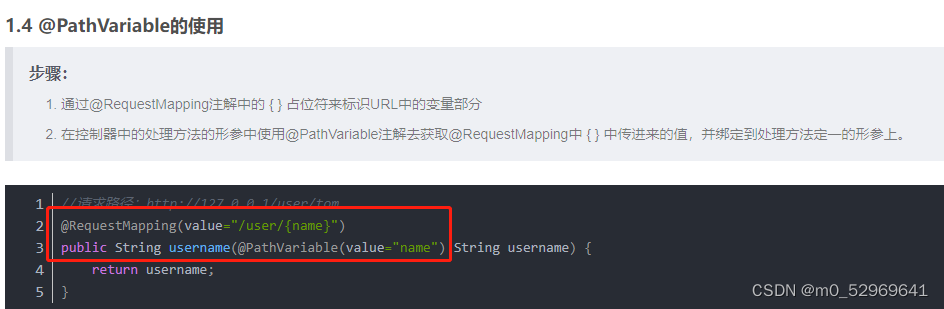
对应postman里的输入:直接在链接后面加上/{id}

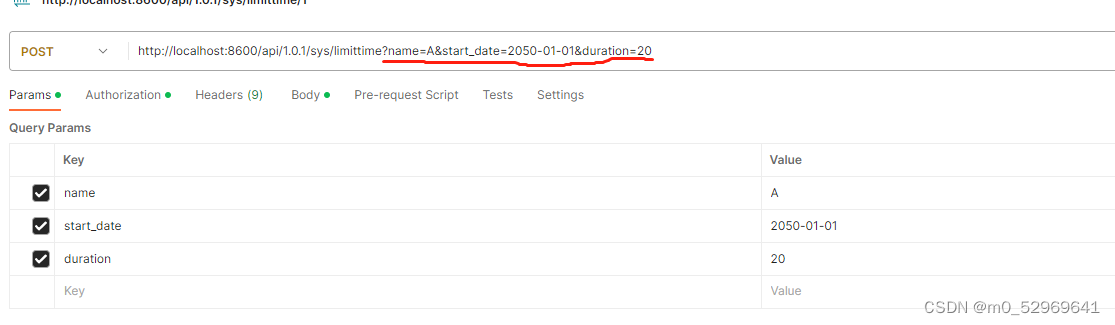
2.2.2.@RequestParam

对应postman里的输入:
http://localhost:8600/api/1.0.1/sys/limittime?name=A&start_date=2050-01-01&duration=20
2.2.3. @RequestBody —— JSON格式


对应postman:(Body ——> raw——> json)

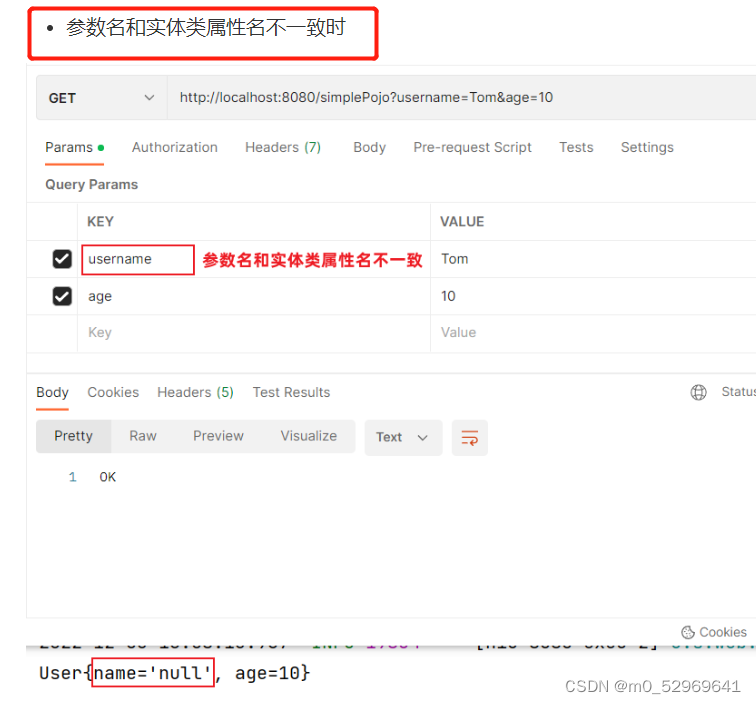
重点:对于@RequestBody传入的数据,也就是json数据,在实体类中定义为驼峰形式,但是用postMan测试时候要转变为_小写形式,否则数据会传入失败
例如:startDate(实体类定义) —— start_date(postman中要这样传入)
补充:
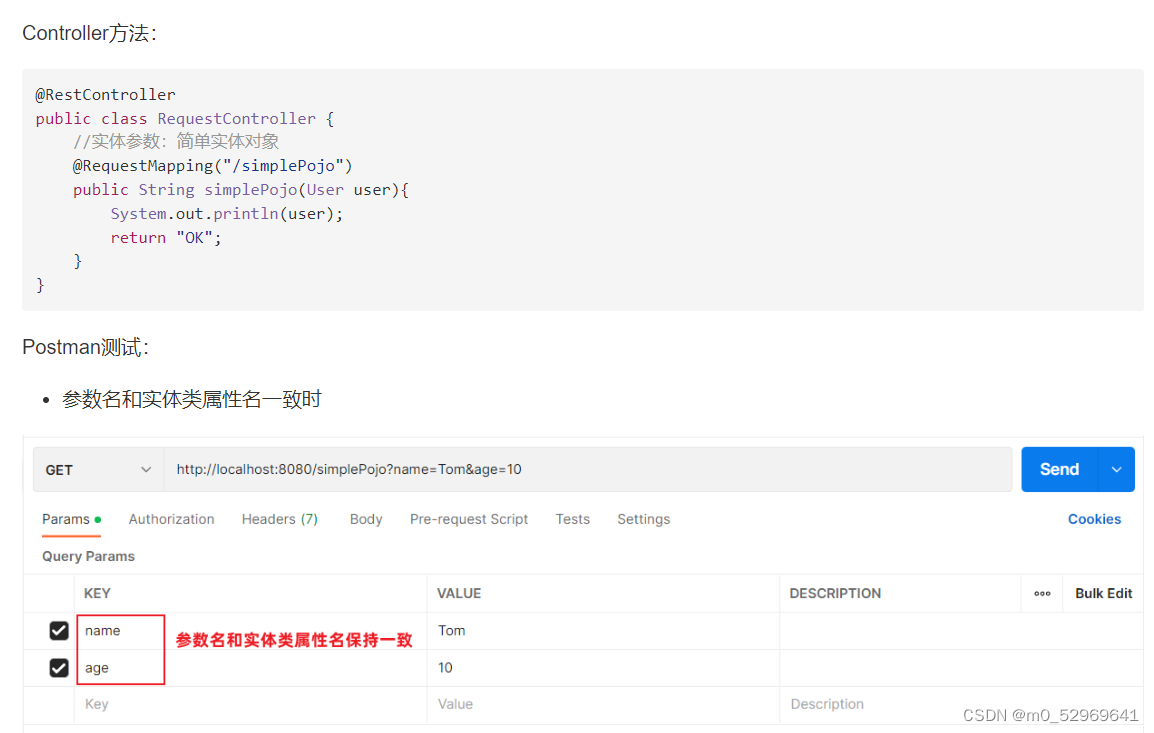
1. 参数名与形参变量名相同:


2. 参数名与形参变量名不相同:@RequestParam
@RestController
public class RequestController {
// http://localhost:8080/simpleParam?name=Tom&age=20
// 请求参数名:name
//springboot方式
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam("name") String username , Integer age ){
System.out.println(username+" : "+age);
return "OK";
}
}注意事项:
@RequestParam中的required属性默认为true(默认值也是true),代表该请求参数必须传递,如果不传递将报错
如果该参数是可选的,可以将required属性设置为false
@RequestMapping("/simpleParam")
public String simpleParam(@RequestParam(name = "name", required = false) String username, Integer age){
System.out.println(username+ ":" + age);
return "OK";
}3. 实体参数

2.3. @RequestMapping("")——设定前缀链接

2.4. @Slf4j——自动生成日志记录器

在上面的示例中,@Slf4j 注解为 MyClass 类生成了一个名为 log 的日志记录器字段。该日志记录器可以使用不同的日志级别(如 info、warn 和 error)编写日志语句。SLF4J 使用的实际日志记录实现可以单独进行配置,这样你可以在不修改代码的情况下切换不同的日志记录框架(如 Logback、Log4j)。
2.5. 对应的日志注解
2.5.1. @OperationRequesBodyLog

2.5.2. 记录操作的比较日志

2.6. 用于生成API文档的注解 @Api(value =" ",tag={" "})——类名上

作用:
@Api(value = "豁免资料控制器", tags = {"豁免资料管理"}) 是一个用于 API 文档生成的注解,它提供了关于豁免资料控制器的信息。让我们逐步分析该注解的作用:
1. @Api: 这是 Swagger(一种用于构建、文档化和消费 RESTful Web 服务的工具)库中的注解,用于指定 API 的相关信息。
2. value = "豁免资料控制器": 这是 @Api 注解的一个属性,指定了豁免资料控制器的名称或标题,即"豁免资料控制器"。它可以用于在生成的 API 文档中标识该控制器。
3. tags = {"豁免资料管理"}: 这是 @Api 注解的另一个属性,指定了控制器的标签。在这个例子中,标签为"豁免资料管理"。标签用于对 API 进行分类或分组,方便在文档中进行导航和查找。
综上所述,@Api(value = "豁免资料控制器", tags = {"豁免资料管理"}) 注解的作用是为豁免资料控制器提供相关的信息,包括控制器的名称或标题以及标签。这些信息将被 Swagger 库用于生成 API 文档,使得文档能够清晰地描述和组织豁免资料控制器的功能。
2.7. ApiOperation("") ——对特定api进行简要描述的记录 (方法名上)

在api文档中会展示该操作的描述
2.8. @ApiParam(" ")——对主要属性的描述记录

3. 代码
3.1. 第一步注解:
@RestController
@RequestMapping("/inpCaseRecord")
上面两个基本必备,再加上日志记录注解和API文档注解(不必须):
选择1:@Slf4j
对应:
1. @OperationRequestBodyLog(name = "新增檔案記錄", fields = {"檔案記錄編號-inpFileCode", "車牌編號-plateNo"}, isReturn = true)
2. 操作比较日志:
@OperationCompareLog(name = "編輯角色", fields = {"name"}, mapper = "com.boardware.inspection.core.admin.mapper.IRoleMapper")

3.2. 创建控制器类并且调用业务层(Service)进行具体实现
注意在业务层对象上加入@Resource或者@Autowired进行注入
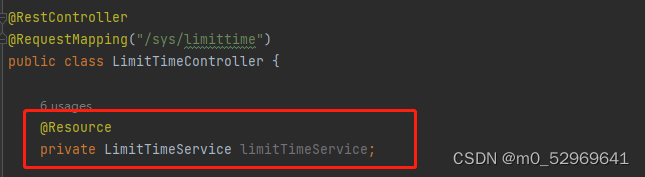
3.3.创建接口,调用业务层方法进行实现

3.4. 汇总
@RestController
@RequestMapping("/sys/limittime")
public class LimitTimeController {
@Resource
private LimitTimeService limitTimeService;
@GetMapping("/{id}")
public LimitTimeModel get(@PathVariable("id") Integer id) {
return limitTimeService.selectByKey(id);
}
//获取全部
@GetMapping("/page/all")
@AnonymousResource
public RTableDataInfo<LimitTimeModel> page() {
return limitTimeService.selectall();
}
//根据名称获取
@GetMapping("/page")
public RTableDataInfo<LimitTimeModel> page(@RequestParam String name) {
return limitTimeService.query(name);
}
@AnonymousResource
@OperationRequestBodyLog(name = "新增期限日期", fields = {"編號-id", "類型-name", "生效日期-startDate", "期限-duration"})
@PostMapping
public void add(@RequestBody LimitTimeModel model) {
limitTimeService.add(model);
}
@OperationRequestBodyLog(name = "編輯期限日期", fields = {"編號-id", "類型-name", "生效日期-startDate", "期限-duration"})
@PutMapping
public void edit(@RequestBody LimitTimeModel model) {
limitTimeService.edit(model);
}
@AnonymousResource
@OperationRequestBodyLog(name = "删除期限日期", fields = {"編號-id", "類型-name", "生效日期-startDate", "期限-duration"}, isReturn = true)
@DeleteMapping("/{id}")
public LimitTimeModel del(@PathVariable("id") Integer id) {
return limitTimeService.del(id);
}
}比较日志和主体操作日志(类上加@Slf4j注解)
/**
* 角色详情
* @param id
* @return
*/
@GetMapping("/admin/role/{id}")
public RoleModel roleDetailList(@PathVariable Integer id) {
return adminService.getRoleDetailList(id);
}
/**
* 新增角色
* @param roleVo
*/
@OperationRequestBodyLog(name = "新增角色", fields = {"name"})
@PostMapping("/admin/role")
public RoleModel addRoleDetail(@RequestBody RoleVo roleVo) {
return adminService.addRoleDetail(roleVo);
}Api文档记录
@Api(value = "豁免资料控制器", tags = {"豁免资料管理"})
@RestController
@RequestMapping("/exemption")
public class AdminExemptionController extends BaseController {
@Autowired
private IAdminExemptionService sysExemptionService;
/**
* 获取豁免资料详细信息
*/
@ApiOperation("获取豁免资料详细信息")
@GetMapping(value = "/{id}")
public AdminExemptionModel getInfo(@ApiParam("主键") @PathVariable("id") Long id) {
return sysExemptionService.getById(id);
}二.业务层
1.概述(先接口再实现)
Service层:(业务层 )控制业务
Service层叫服务层,被称为服务,主要负责业务模块的逻辑应用设计。和DAO层一样都是先设计放接口的类,再创建实现的类,然后在配置文件中进行配置其实现的关联。接下来就可以在service层调用接口进行业务逻辑应用的处理。
注:封装Service层的业务逻辑有利于业务逻辑的独立性和重复利用性。
2. 业务层接口
2.1. 业务层接口继承IService <对应实体类>

相应的实现类也要继承IService类并且实现接口
@Service
public class InpCaseRecordDocServiceImpl extends ServiceImpl<InpCaseRecordDocMapper, InpCaseRecordDocModel> implements IInpCaseRecordDocService 
2.2. 业务层接口完整代码(都只是样式结构,不能跑)
@Validated
public interface ISysDeadlineConfService {
@Validated({Default.class, IGroups.ADD.class})
void add(@Valid @NotNull SysDeadlineConfModel model);
@Validated({Default.class, IGroups.MOD.class})
void edit(@Valid @NotNull SysDeadlineConfModel model);
SysDeadlineConfModel del(Integer id);
RTableDataInfo<SysDeadlineConfModel> query(DeadlinePageSearchVo search);
@Validated
Long queryDeadline(@NotNull LocalDate date, @NotNull DeadlineEnums type);
@Validated
SysDeadlineConfModel selectByKey(@NotNull @Min(1) Integer id);
}
2.3. 拓展知识(@Valid 和 @Validated)
@Valid:可以用在方法、构造函数、方法参数和成员属性(field)上。——不能分组
@Validated:用在类、方法和方法参数上。但不能用于成员属性(field)。——可以分组
(如果@Validated注解在成员属性上,则会报不适用于field的错误。)
@Valid用法:
用法1:在实体类中写检验条件,在控制器方法的成员属性中加@Valid 表示需要进行检验
@Data
public class User implements Serializable {
//用户名
@NotBlank(message = "请输入名称")
@Length(message = "名称不能超过个 {max} 字符", max = 10)
private String username;
//年龄
@NotNull(message = "请输入年龄")
@Range(message = "年龄范围为 {min} 到 {max} 之间", min = 1, max = 100)
private String age;
}@RestController
public class UserController {
public static final Logger logger = LoggerFactory.getLogger(UserController.class.getName());
@PostMapping("/add")
@ResponseBody
public String add(@Validated User user, BindingResult bindingResult){
if(bindingResult.hasErrors()){
List<ObjectError> allErrors = bindingResult.getAllErrors();
allErrors.forEach( v ->{
logger.error(v.getObjectName()+"======"+v.getDefaultMessage());
});
return "添加失败";
}
return "添加成功";
}
}用法2:直接在控制器或者业务层接口参数前加@Valid并加入相应检验的注解
void add(@Valid @NotNull SysDeadlineConfModel model);单独使用@Validated(不需要在每个前面都加@Valid)
@Validated
Long queryDeadline(@NotNull LocalDate date, @NotNull DeadlineEnums type);@Validated实现分组校验
1. 分组接口
public interface Group {
interface Update{};
interface FindAll{};
}2. 配置分组检验
public class User implements Serializable {
//用户名
@NotBlank(message = "请输入用户名不能为空",groups = {Group.FindAll.class})
@Length(message = "名称不能超过个 {max} 字符", max = 10 ,groups = {Group.FindAll.class})
private String username;
//年龄
@NotBlank(message = "请输入年龄不能为空",groups = {Group.Update.class})
@Range(message = "年龄范围为 {min} 到 {max} 之间", min = 1, max = 100,groups = {Group.Update.class})
private String age;
}3. 加入对应参数
//注意@Validated有参数 value中写分组名称
public String add(@Validated(value = {Group.Update.class}) User user, BindingResult bindingResult)或者:接口中加入对应参数
@Validated({Default.class, IGroups.ADD.class})
void add(@Valid @NotNull SysDeadlineConfModel model);@Valid实现嵌套
注: 嵌套检测就是在一个User类中,存在另外一个User2类的属性。嵌套检测User同时也检测User2。
需要在User1 里面的User2中加@Valid才会对User2进行校验
User1:
@Data
public class User implements Serializable {
//用户名
@NotBlank(message = "请输入用户名不能为空1")
private String username;
//年龄
@NotBlank(message = "请输入年龄不能为空1")
private String age;
@Valid
@NotNull(message = "user2不能为空1")
private User2 user2;
}
}User2:
@Data
public class User2 implements Serializable {
//用户名
@Length(message = "名称不能超过个 {max} 字符2", max = 10 )
private String username2;
//年龄
@Range(message = "年龄范围为 {min} 到 {max} 之间2", min = 1, max = 100)
private String age2;
}
业务层接口或控制层:
public String add(@Valid User user, BindingResult bindingResult)2.4. 业务层实现类——调用Mapper(Dao)查看或修改数据,并返回对应数据类型给Controller控制层
@Service
public class LimitTimeServiceImpI implements LimitTimeService {
@Resource
private LimitTimeMapper limitTimeMapper;
@Override
public void add(LimitTimeModel model) {
preOperate(model);
model.setDeleted(0);
var userId = TokenUtil.forceLoginUser().getId();
model.setCreateBy(userId);
model.setUpdateBy(userId);
limitTimeMapper.insert(model);
}
@Override
public void edit(LimitTimeModel model) {
// 生效日期不能小於當前日期
BwEvents.ifTrueThrow400(DateUtils.checkRange(model.getStartDate(), LocalDate.now()), "生效日期不能小於當前日期");
var userId = TokenUtil.forceLoginUser().getId();
model.setUpdateBy(userId);
limitTimeMapper.updateById(model);
}
@Override
public LimitTimeModel del(Integer id) {
var model = selectByKey(id);
limitTimeMapper.deleteById(id);
return model;
}
@Override
public RTableDataInfo<LimitTimeModel> query(String name) {
PageUtils.startPage();
var searchResult = limitTimeMapper.search(name);
return RTableDataInfo.build(searchResult);
}
@Override
public RTableDataInfo<LimitTimeModel> selectall() {
PageUtils.startPage();
var searchResult = limitTimeMapper.search(null);
return RTableDataInfo.build(searchResult);
}
@Override
public LimitTimeModel selectByKey(Integer id) {
return limitTimeMapper.selectById(id);
}
private void preOperate(LimitTimeModel model){
// 生效日期不能小於當前日期
BwEvents.ifTrueThrow400(DateUtils.checkRange(model.getStartDate(), LocalDate.now()), "生效日期不能小於當前日期");
// 是否重複
var isRepeat = limitTimeMapper.repeatCheck(model);
BwEvents.ifTrueThrow400(isRepeat, "存在重複生效日期");
}
}
2.5. 添加事务:@Transactional
@Slf4j
@Service
public class DeptServiceImpl implements DeptService {
@Autowired
private DeptMapper deptMapper;
@Autowired
private EmpMapper empMapper;
@Override
@Transactional //当前方法添加了事务管理
public void delete(Integer id){
//根据部门id删除部门信息
deptMapper.deleteById(id);
//模拟:异常发生
int i = 1/0;
//删除部门下的所有员工信息
empMapper.deleteByDeptId(id);
}
}2.6. 总结:
1. 接口使用@Valid和@Validated对输入的参数进行限制
2. 接口继承IService,实现类继承加实现
public interface IInpCaseRecordService extends IService<InpCaseRecordModel> {@Service
public class InpCaseRecordDocServiceImpl extends ServiceImpl<InpCaseRecordDocMapper, InpCaseRecordDocModel> implements IInpCaseRecordDocService 注意:业务层继承IService和Dao(Mapper)层继承BaseMapper<数据表>功能类似,不过IService里有BaseMapper里面的所有功能。
最大的区别可能就在于一个在持久层,一个在业务层,哪个适合用哪个
三.DAO(Mapper)持久层——包含了对数据库的复杂操作方法
1. 概述
DAO层:(持久层)主要与数据库进行交互
DAO层叫数据访问层,全称为data access object,属于一种比较底层,比较基础的操作,主要是做数据持久层的工作,主要与数据库进行交互。具体到对于某个表的增删改查,也就是说某个DAO一定是和数据库的某一张表一一对应的,其中封装了增删改查基本操作,建议DAO只做原子操作,增删改查。
注:DAO 层的数据源和数据库连接的参数都是在配置文件中进行配置的。
2.代码
2.1 继承BaseMapper<实体类>(记得@Repository注入)
2.2. @Parm
这个注解是为SQL语句中参数赋值而服务的。
@Param的作用就是给参数命名,比如在mapper里面某方法A(int id),当添加注解后A(@Param("userId") int id),也就是说外部想要取出传入的id值,只需要取它的参数名userId就可以了。将参数值传入SQL语句中,通过#{userId}进行取值给SQL的参数赋值。
@Param(name) 中的name 与配置文件中的#{name} 中的name对应

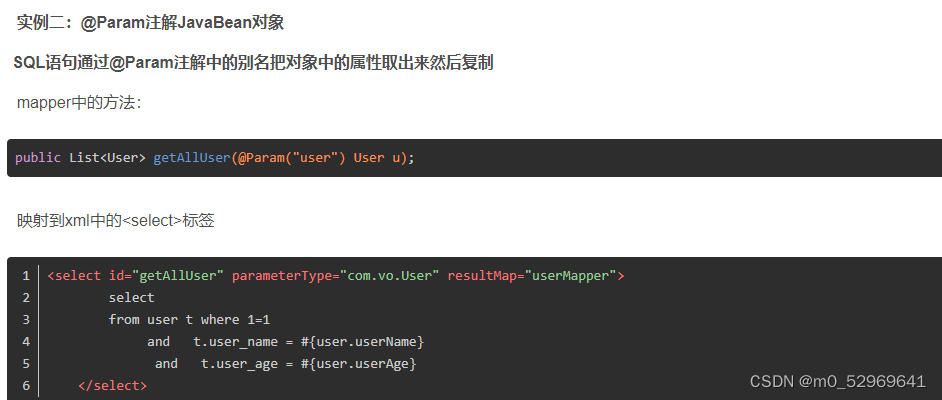

注意:
1. 养成习惯,每个传入的值前都加入@Param并且名字与属性名相同
例如: @Param(id) integer id
2. 多个参数的时候一定要使用@Param去给参数命名,但是如果参数过多,就直接传入实体类(参数集合)
2.3. 直接自定义查询(#{}获取可以防止sql注入)
@Repository
public interface AdminExemptionMapper extends BaseMapper<AdminExemptionModel> {
@Select("select * from admin_exemption where is_deleted = 0 and end_date >= #{start} order by start_date asc")
List<AdminExemptionModel> selectTargetExemption(@Param("start") LocalDate start);
}
@Update("update emp set username=#{username}, name=#{name}, gender=#{gender}, image=#{image}, job=#{job}, entrydate=#{entrydate}, dept_id=#{deptId}, update_time=#{updateTime} where id=#{id}")
public void update(Emp emp)@Select @Insert @Update @Delete
@Options(useGeneratedKeys = true,keyProperty = "id")可以拿到新插入数据的主键值
——emp.getDeptId()
@Mapper
public interface EmpMapper {
//会自动将生成的主键值,赋值给emp对象的id属性
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into emp(username, name, gender, image, job, entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")
public void insert(Emp emp);
}@SpringBootTest
class SpringbootMybatisCrudApplicationTests {
@Autowired
private EmpMapper empMapper;
@Test
public void testInsert(){
//创建员工对象
Emp emp = new Emp();
emp.setUsername("jack");
emp.setName("杰克");
emp.setImage("1.jpg");
emp.setGender((short)1);
emp.setJob((short)1);
emp.setEntrydate(LocalDate.of(2000,1,1));
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
emp.setDeptId(1);
//调用添加方法
empMapper.insert(emp);
System.out.println(emp.getDeptId());
}
}2.4. 代码样式
@Repository
public interface UserMapper extends BaseMapper<UserModel>{
List<LegworkUserVo> getLegworkUserList(@Param("loginName") String loginName);
UserModel getUserByUsername(@Param("username") String username);
UserModel getUserById(@Param("id") Integer id);
}3. 映射文件(XML)

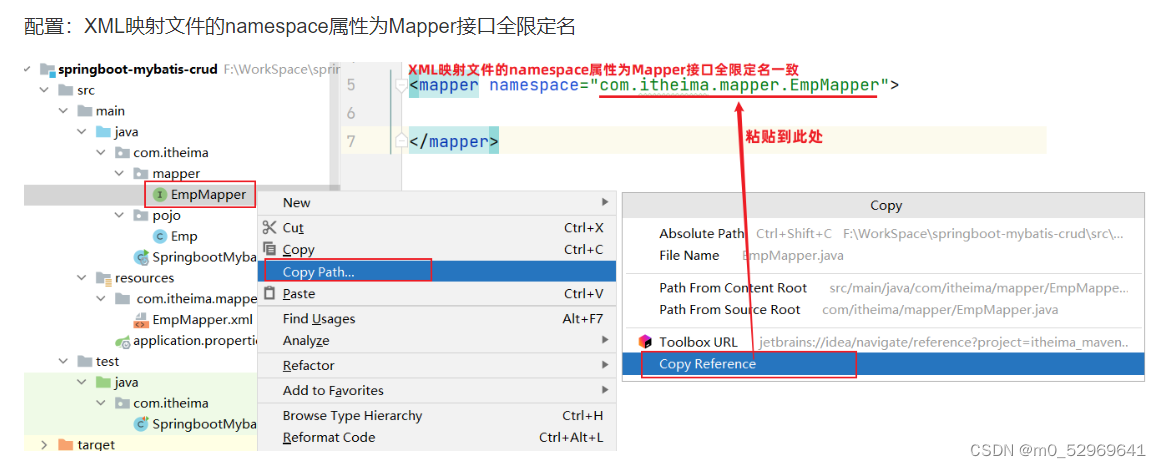
3.1. 对XML文件的声明和DOCTYPE定义,格式都是固定且一致的
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">3.2. 命名空间定义:制定了该配置文件所对应的java的Mapper接口
<mapper namespace="com.boardware.inspection.core.inp.mapper.InpRecordMapper">
3.3. 结果映射
<id> 元素:用于标识实体对象的主键属性,并且一个 <resultMap> 元素中只能有一个 <id> 元素。它表示该属性对应数据库表中的主键列。在查询结果映射时, MyBatis 使用 <id> 元素来确定实体对象的主键属性,并将查询结果中的主键列值赋值给该属性。
<result> 元素:用于定义普通的属性映射关系,可以映射表中的任意列,包括主键列。
在一个 <resultMap> 元素中,可以有多个 <result> 元素用于映射不同的列和属性。column 数据库中的列名 property: 实体类中的列名
(注意下面写sql语句时候需要用column中的列名)
定义结果映射:通过 <resultMap> 可以将查询结果的列映射到实体类的属性上,从而将数据库表的数据转换为对应的 Java 对象。每个 <result> 标签都定义了一列的映射关系,其中 column 属性表示数据库表的列名,property 属性表示实体类的属性名。
如果不配置该映射,MyBatis 将使用默认的映射规则进行结果映射。默认情况下,MyBatis 会将数据库查询结果的列名与实体类的属性名进行自动映射,前提是它们的名称相匹配。
但是,如果数据库表的列名与实体类的属性名不完全匹配,或者有特殊的映射需求(例如数据库中的 create_time 列映射到实体类的 createTime 属性),那么默认的映射规则可能无法正确映射查询结果,导致结果映射失败。(映射失败可能导致数据库查询结果无法正确赋值给java实体类属性值,导致java实体类属性值为null或者错误)
<resultMap id="BaseResultMap" type="com.boardware.inspection.core.inp.entity.InpRecordModel">
<id column="id" property="id" />
<result column="veh_id" property="vehId" />
<result column="plate_no" property="plateNo" />
<result column="plate_type" property="plateType" />
<result column="veh_type" property="vehType" />
<result column="veh_brand" property="vehBrand" />
<result column="veh_color" property="vehColor" />
<result column="inp_time" property="inpTime" />
<result column="inp_source" property="inpSource" />
<result column="inp_property" property="inpProperty" />
<result column="inp_area" property="inpArea" />
<result column="inp_location" property="inpLocation" />
</resultMap>3.4. 重复片段定义
<sql id="Base_Column_List">
id, veh_id, plate_no, plate_type, veh_type, veh_brand, veh_color, inp_time, inp_source
</sql> <select id="selectListById" resultType="com.boardware.inspection.core.inp.entity.InpRecordModel">
select <include refid="Base_Column_List" /> from inspction_record where id in
<foreach collection="ids" item="ids" index="i" open="(" separator="," close=")">
#{ids}
</foreach>
</select>
3.5.if test
1. top n函数:返回符合条件的结果中的前n条。select top 1 id 表示只选择第一条记录的 id 列。
2. <if test="plateNo != null and plateNo != '' "> 对于string变量来说,例如:string a = '',表示a指向了空字符串的内存空间
而string a = null 中的a并没有指向任何的内存空间,在堆中也没有开辟内存空间
因此,要判断string变量是否为我们认为的空(不单为null还应该为指向空字符串),因此需要plateNo != null and plateNo != '',对于其他类型
的变量则只需要判断其是否为null即可
3. <if test="plateNo != null and plateNo != ''"> 表示如果 plateNo 参数不为空且不为空字符串时才会执行该条件判断块内的内容。
即满足了相应条件,后面的and才会加上的意思,也就是在where inp_employee = #{inpEmployee} and inp_time = #{inpTime}后面加上
and plate_no = #{plateNo}
字符串类型: <if test="plateNo != null and plateNo != '' ">
其他类型:< if test = " id != null>
注意: if test = “ ” 和#{ } 里面的参数都是传入数据中的参数而不是原数据库中的参数
<select id="selectOneIdByAppRequest" resultType="java.lang.Integer">
select top 1 id from inspction_record where
inp_employee = #{inpEmployee} and inp_time = #{inpTime}
<if test="plateNo != null and plateNo != ''">
and plate_no = #{plateNo}
</if>
<if test="vid != null">
and veh_id = #{vid}
</if>
</select>
3.6. <![CDATA[ ]]>
<select id="selectLastOne" resultType="java.lang.Integer">
select top 1 t.id from
(select id,inp_time,
(case when inp_time = #{inpTime} and id <![CDATA[ < ]]> #{id} then '0' else '1' end) as inx
from inspction_record where id <![CDATA[ <> ]]> #{id} and status <![CDATA[ <> ]]> 5
and inp_time <![CDATA[ >= ]]> #{inpTime}
<!--写xml文件时特殊字符例如“<“ ” >“ ”<=“ ” >=”会被转义,但是我们不希望它被转义就需要用<![CDATA[ ]]>标签来解决
3.7. case when
(case when inp_time = #{inpTime} and id <![CDATA[ < ]]> #{id} then '0' else '1' end) as inx
3.8. for each
<select id="selectListById" resultType="com.boardware.inspection.core.inp.entity.InpRecordModel">
select <include refid="Base_Column_List" /> from inspction_record where id in
<foreach collection="ids" item="ids" index="i" open="(" separator="," close=")">
#{ids}
</foreach>
</select>
<!--
你可以传递一个 list 实例或者 array 数组作为参数对象传给 MyBatis。当你这么做的时候,MyBatis 会自动将它包装在一个 Map 中,用名称作为键。
list 实例将会以 list 作为键,而 array 数组实例将会以 array 作为键
foreach 元素的属性主要有 item,index,collection,open,separator,closeitem:表示集合中每一个元素进行迭代时的别名
index:指定一个名字,用于表示在迭代过程中,每次迭代到的位置(也就是索引i)
open:表示该语句以什么开始
separator:表示在每次进行迭代之间以什么符号作为分隔符
close:表示以什么结束
在使用 foreach 时最关键的也是最容易出错的就是 collection 属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下 3 种情况如果传入的是单参数且参数类型是一个 List 时,collection 属性值为 list
如果传入的是单参数且参数类型是一个 array 数组时,collection 的属性值为 array
如果传入的参数是多个时,可以把它们封装成一个 Map,collection 的属性值为 Map 的键
如果传入的参数是多个时,也可以把它们封装成一个 Object
3.9. like——字符串匹配
<if test="plateNo != null and plateNo != ''">
and plate_no like CONCAT('%',#{plateNo},'%')
</if>1.CONCAT('%',#{inpLocation},'%'):是一个字符串连接函数,用于构建查询条件中的模式。
通过将 %、#{inpLocation} 和 % 连接在一起,形成类似 %text% 的模式,其中 text 是从参数 inpLocation 获取的值。
2. like的用法:
LIKE '%text%':匹配包含 "text" 字符串的任意位置,前后可以有零个或多个字符。
LIKE 'text%':匹配以 "text" 开头的字符串。
LIKE '%text':匹配以 "text" 结尾的字符串。
LIKE '_text_':匹配以任意单个字符开头和结尾,并且中间有且仅有 "text" 的字符串。3. 用concat这个方法可以防止sql注入
3.10. <where> ——只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR
<select id="list" resultType="com.itheima.pojo.Emp">
select * from emp
<where>
<!-- if做为where标签的子元素 -->
<if test="name != null">
and name like concat('%',#{name},'%')
</if>
<if test="gender != null">
and gender = #{gender}
</if>
<if test="begin != null and end != null">
and entrydate between #{begin} and #{end}
</if>
</where>
order by update_time desc
</select>3.11. <set>—— 动态更新:会删掉额外的逗号,(用于update语句中)
<update id="update">
update emp
<!-- 使用set标签,代替update语句中的set关键字 -->
<set>
<if test="username != null">
username=#{username},
</if>
<if test="name != null">
name=#{name},
</if>
<if test="deptId != null">
dept_id=#{deptId},
</if>
<if test="updateTime != null">
update_time=#{updateTime}
</if>
</set>
where id=#{id}
</update>4. 创建流程
4.1.步骤1:创建数据库及表
4.2. 步骤2:创建SpringBoot工程

4.3. 步骤3:勾选配置使用技术 (Mysql,web,Mybatis,lombok)

4.4. 步骤4:pom.xml补全依赖(手动在pom.xml中配置添加)
如果我们想用druid连接池,还需加上如下依赖
<dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency>
如果需要使用@data等类似注解需要添加依赖:
<!-- 在springboot的父工程中,已经集成了lombok并指定了版本号,故当前引入依赖时不需要指定version --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency>
4.5. 步骤5:添加MP的相关配置信息
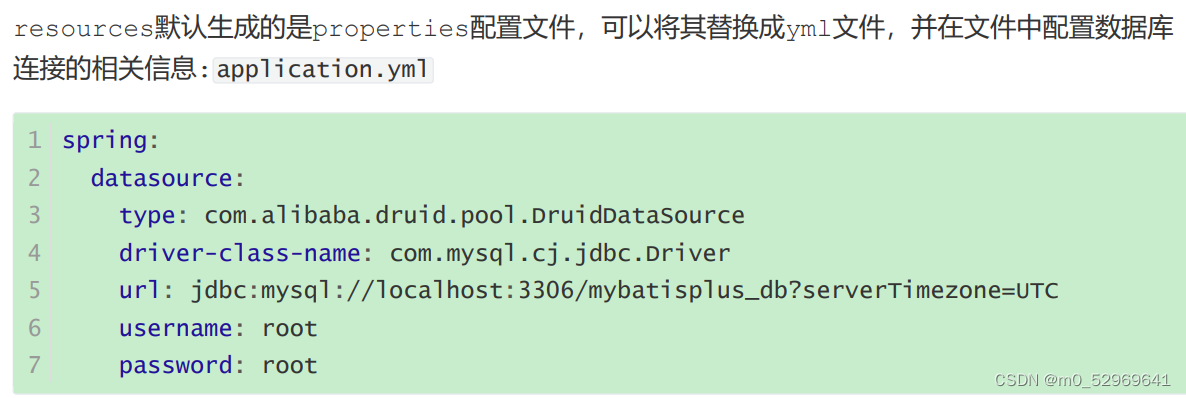
或者:
在application.properties中:
1. 默认连接池:
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=12342. durid连接池:
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis
spring.datasource.druid.username=root
spring.datasource.druid.password=12344.6. 步骤6:根据数据库表创建实体类
4.7. 步骤7:创建Dao接口(extends BaseMapper)

注意:Dao接口继承BaseMapper后,BaseMapper内置的方法直接使用,而非内置的方法需要在此接口定义,然后在对应的xml文件中配置:
@Mapper
public interface LimitTimeMapper extends BaseMapper<LimitTimeModel> {
//方式1:在xml中配置search方法;
List<LimitTimeModel> search(String name);
//方式2:
@Select("select id, name, age, gender, phone from user")
public List<User> list();
@Delete("delete from emp where id = #{id}")//使用#{key}方式获取方法中的参数值
public void delete(Integer id);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.boardware.inspection.core.admin.mapper.LimitTimeMapper">
<select id="search" resultType="com.boardware.inspection.core.admin.entity.LimitTimeModel">
select * from time_limit
<where>
(deleted = 0 or deleted is null)
<if test="name != null and name != ''">
and name = #{name}
</if>
</where>
order by start_date desc
</select>
</mapper>4.8.步骤8:编写引导类(需要加@Mapper)

4.9. 步骤9:编写测试类
四.Entity层: (实体层 )数据库在项目中的类
entity层存放一些普通javabean,其中有一些属性及其getter和setter方法的类,没有业务逻辑,也不允许有业务方法,也不能携带有connection之类的方法。
1. 类上注解
1.1. @Data(必备:开启setter,getter等方法)
自动生成类的一些常用方法,如 toString()、equals()、hashCode()、getter 和 setter 方法。
@Data
public class Person {
private String name;
private int age;
private String address;
}public class Main {
public static void main(String[] args) {
Person person = new Person();
person.setName("John").setAge(25).setAddress("123 Main St");
System.out.println(person.getName()); // 输出: John
System.out.println(person.getAge()); // 输出: 25
System.out.println(person.getAddress()); // 输出: 123 Main St
System.out.println(person.toString()); // 输出: Person(name=John, age=25, address=123 Main St)
}
}1.2. @Tostring(类)(自动生成 toString() 方法)
自动生成 toString() 方法
@Data
@ToString
public class Person {
private String name;
private int age;
private String address;
}通过 @ToString 注解,编译器会为 Person 类生成以下 toString() 方法:
@Override
public String toString() {
return "Person(name=" + name + ", age=" + age + ", address=" + address + ")";
}public class Main {
public static void main(String[] args) {
Person person = new Person();
person.setName("John");
person.setAge(25);
person.setAddress("123 Main St");
System.out.println(person.toString());
}
}输出结果:
Person(name=John, age=25, address=123 Main St)
1.3. @NoArgsConstructor 和 @AllArgsConstructor(必备:生成构造函数)
@NoArgsConstructor: 自动生成无参构造。(Java编译器会自动生成无参构造但是当人为设定了有参构造后就不会自动生成无参构造,但是使用了这个注解生成的无参构造不会因为已经含有有参构造而消失)
@AllArgsConstructor:自动生成包含所有参数的构造函数
@RequiredArgsConstructor:自动生成包含被@NonNull或者final修饰的字段作为参数的构造函数
1.4. @Accessors(chain = true)——启动链式调用(必备)
import lombok.Data;
import lombok.experimental.Accessors;
@Data
@Accessors(chain = true)
public class Person {
private String name;
private int age;
private String address;
}在上述示例中,@Data 注解用于自动生成getter和setter方法,而 @Accessors(chain = true) 注解则启用了链式调用。
Person person = new Person()
.setName("Alice")
.setAge(25)
.setAddress("123 Main Street");请注意,@Accessors(chain = true) 注解只对具有 @Data 注解的类中的setter方法生效。如果你仅使用 @Accessors(chain = true) 注解而没有 @Data 注解,则链式调用将不起作用。
1.5. @TableName(“数据库名”,autoResultMap = true)(必备)
@TableName(“admin_exemption”)
- 数据库表名:admin_exemption 是将实体类 AdminExemption 映射到的数据库表名。使用 @TableName 注解后,MyBatis-Plus 将根据该注解的值来确定实体类对应的数据库表。在进行数据库操作时,MyBatis-Plus 将使用指定的表名。
- 实体类映射:通过使用 @TableName 注解,你可以确保实体类与数据库表之间的映射关系准确无误。默认情况下,MyBatis-Plus 使用实体类的类名作为数据库表名,并将驼峰命名法转换为下划线命名法(例如,AdminExemption 类映射到 admin_exemption 表)。但是,如果你希望使用不同的表名进行映射,可以使用 @TableName 注解显式指定。
autoResultMap = true表示自动生成结果映射,结果映射是将查询结果映射到实体类属性的过程。
映射规则:
实体类驼峰命名法:userName 映射到数据库表的 user_name列
1.6.@EqualsAndHashCode(callSuper = false)(提供equals()和hashCode()方法)
- @EqualsAndHashCode:这个注解为类提供了equals()和hashCode()方法
- 如果callSuper = false 表示排除父类的属性即通过设置callSuper参数为false,可以仅比较当前类的属性而不包括父类的属性。
- 换句话说,就是在使用其提供的equals判断两个类是否相同时只考虑自己的属性,自己属性和别人相同,不管父类如何都是返回true
- 如果需要比较父类的属性需要设置callSuper = true
import lombok.EqualsAndHashCode;
@EqualsAndHashCode(callSuper = false)
public class Person {
private String name;
private int age;
// 其他属性和方法省略
}Person person1 = new Person();
person1.setName("Alice");
person1.setAge(25);
Person person2 = new Person();
person2.setName("Alice");
person2.setAge(25);
boolean isEqual = person1.equals(person2);
int hashCode = person.hashCode();
- 在这个例子中,isEqual 变量将被设置为 true,因为 person1 和 person2 的 name 和 age 属性相同。
- 自动生成的 hashCode() 方法使用了当前类中的属性进行计算,因此你应该确保在生成哈希码时所依据的属性是准确且恰当的。
1.7. @ApiModel("对象名称")(API注解文档)
@ApiModel("豁免资料业务对象"):在API文档中将该模型标记为“豁免资料业务对象”,有助于开发人员和API使用者更好地理解该对象的用途和含义
1.8. @ToBuilder(toBuilder = true)(创建副本)
@Data
@Builder(toBuilder = true)
public class Person {
private String name;
private int age;
// 其他字段和方法
}在上述示例中,Person 类使用了 @Builder(toBuilder = true) 注解。这将自动生成一个建造者模式的构造器,并启用 toBuilder() 方法。
使用该注解后,可以通过以下方式创建 Person 对象:
Person person = Person.builder()
.name("John")
.age(25)
.build();同时,由于启用了 toBuilder() 方法,还可以通过以下方式创建 Person 对象的副本并修改属性:
Person modifiedPerson = person.toBuilder()
.name("Alice")
.build();2. 属性注解
1. @TableId(value = "id", type = IdType.AUTO)
@ApiModelProperty("资料主键")
@TableId(value = "id", type = IdType.AUTO)
private Integer id;@TableId注解是专门用在主键上的注解,如果数据库中的主键字段名和实体中的属性名,不一样且不是驼峰之类的对应关系,可以在实体中表示主键的属性上加@Tableid注解
- value = "id":指的是此主键字段对应的数据库表中的列名,即显式配置了实体类中的id字段和数据库表中的列名为id的列配对;
- type = IdType.AUTO:指定主键的生成策略。IdType.AUTO 表示由数据库自动生成主键值。具体的生成策略可能根据不同的数据库而有所不同,常见的策略有自增长(如MySQL的自增长主键)或序列(如Oracle的序列),也就是说在数据库中加入auto_increment
- 需要注意的是:数据库中对应的id列也要设置auto_increment(自增)
分布式ID是什么?
- 当数据量足够大的时候,一台数据库服务器存储不下,这个时候就需要多台数据库服务器进行存储,比如订单表就有可能被存储在不同的服务器上
- 如果用数据库表的自增主键,因为在两台服务器上所以会出现冲突 这个时候就需要一个全局唯一ID,这个ID就是分布式ID。
其他自增:
- type = IdType.AUTO:适合在数据库服务器只有1台的情况下使用,不可作为分布式ID使用
- ASSIGN_UUID:可以在分布式的情况下使用,而且能够保证唯一,但是生成的主键是32位的字符 串,长度过长占用空间而且还不能排序,查询性能也慢(主键类型为String)
- ASSIGN_ID:可以在分布式的情况下使用,生成的是Long类型的数字,可以排序性能也高,但是 生成的策略和服务器时间有关,如果修改了系统时间就有可能导致出现重复主键(主键类型为Long)
2. @TableField(value = " ",fill = ,exist = false,select = false)
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;value= "create_time": 显式配置此字段映射到数据库中名为“create_time"的列
fill =
- FieldFill.INSERT: 插入时自动填充
- FieldFill.UPDATE:更新时自动填充
- INSERT_UPDATE:插入和更新时自动填充
- 如果没有主动设置,通常情况下,当使用 LocalDateTime 类型的字段进行插入操作时,持久化框架或ORM工具会自动将当前的日期和时间赋值给该字段。例如 private LocalDateTime createTime; 当执行插入操作时无需model.setCreateTime(LocalDateTime.now())它会自行将LocalDateTime.now()插入到列表中。
- 其他的一般需要主动set,例如在插入数据的函数中加入model.setCreateBy(1)去设置createBy的值
@TableField(value = "create_by", fill = FieldFill.INSERT)
private Integer createBy;@Override
public void add(LimitTimeModel model) {
preOperate(model);
model.setDeleted(0);
var userId = TokenUtil.forceLoginUser().getId();
model.setCreateBy(userId);
model.setUpdateBy(userId);
limitTimeMapper.insert(model);
}补充:
@TableField(exist = false)
private boolean isCancelInert;当使用 @TableField(exist=false) 注解时,它表示该字段在数据库表中不存在,但仍然在实体类中存在,用于表示业务逻辑或其他用途。( 默认 true 存在,false 不存在 )
@TableField(value = "sensitive_data", select = false)
private String sensitiveData;逻辑上的查询删除: 当我们使用Mybatis框架中的查询语句查询时,它会将输出结果的select * 转化为不包含“含有select = false 的”的 select * 。
@TableName("tbl_user")
public class User {
用于模型类与表名的显性配置
3.@ApiModelProperty("描述信息")
@ApiModelProperty 注解用于为数据模型中的属性添加描述信息,以便生成清晰的接口文档,帮助开发者理解每个属性的含义和用途。
4. @Excel(name = " " )
@Excel(name = "豁免建議書編號")
private String proposalNo;
@Excel(name = "豁免開始日期", width = 30, dateFormat = "yyyy-MM-dd")
private LocalDate startDate;在 Excel 导入或导出时将该属性与 Excel 文件中的列 "豁免建議書編號" 进行映射。
这样,在导入 Excel 文件时,库或框架会根据列名进行匹配,并将列中的数据正确地映射到实体类的属性中。在导出时,该注解可以确保相应的属性值被写入到 Excel 文件的指定列中。
@Excel(name = "豁免開始日期", width = 30, dateFormat = "yyyy-MM-dd"):
@Excel 是一种可能由 Excel 导入/导出库或框架提供的注解,用于指定 Excel 文件中的列名或列头信息。
- name = "豁免開始日期" 表示该属性在 Excel 文件中对应的列名为 "豁免開始日期"。
- width = 30 表示在导出时,该列的宽度为 30 个字符。
- dateFormat = "yyyy-MM-dd" 表示在导入和导出时,对日期类型的属性进行格式化操作,以指定日期的显示格式为 "yyyy-MM-dd"。
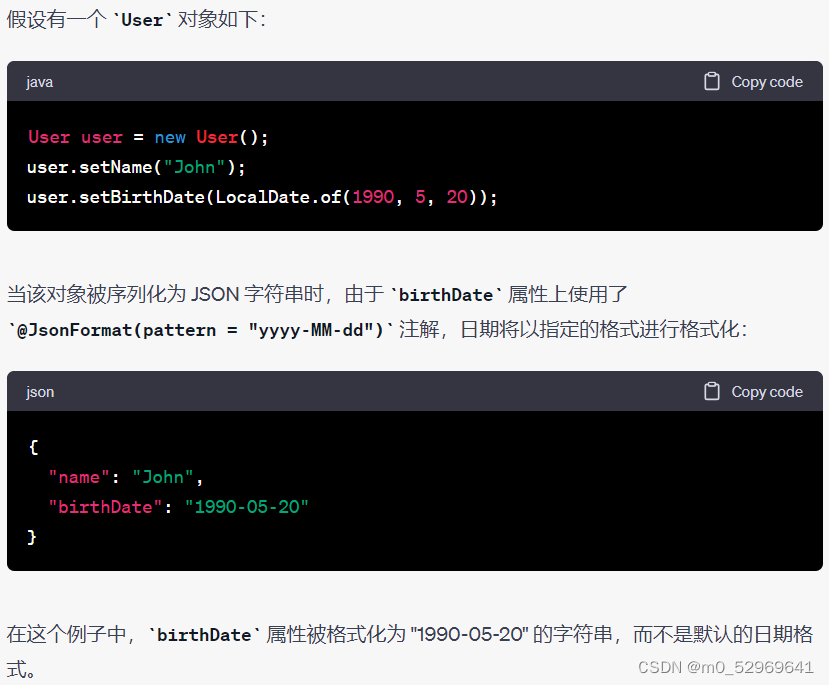
5.@JsonFormat(pattern = "yyyy-MM-dd")
@JsonFormat(pattern = "yyyy-MM-dd")
@Excel(name = "豁免開始日期", width = 30, dateFormat = "yyyy-MM-dd")
@ApiModelProperty("豁免開始日期")
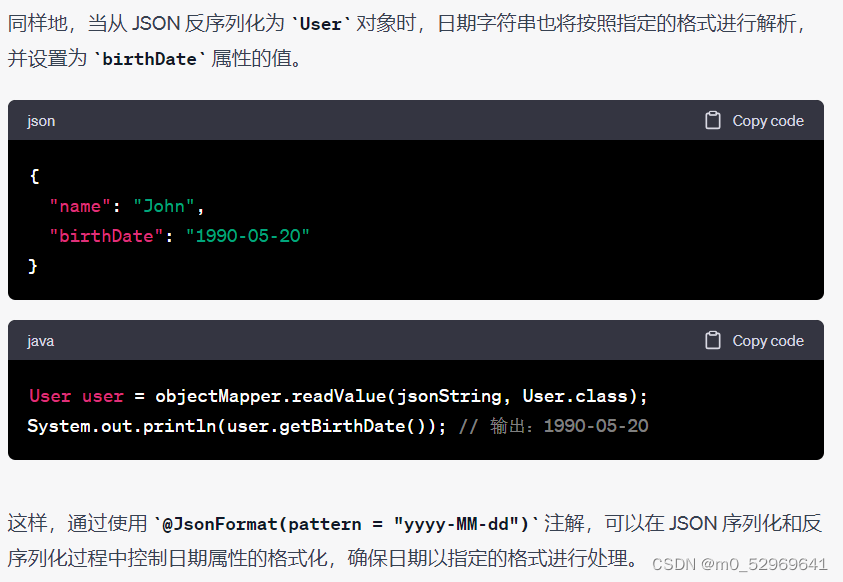
private LocalDate startDate;@JsonFormat 注解用于控制日期属性的序列化和反序列化,以便将日期对象转换为指定格式的字符串或从字符串解析为日期对象。
6. @JsonProperty
@JsonProperty("pro_type")
@Excel(name = "職稱類型")
@ApiModelProperty("職稱類型")
private Integer proType;@JsonProperty 注解用于将属性名映射到 JSON 中的键名,以便在对象序列化为 JSON 字符串或从 JSON 字符串反序列化为对象时,使用指定的键名。
在给定的示例中,@JsonProperty("pro_type") 注解指定了属性 proType 在 JSON 中对应的键名为 "pro_type"。
例如,如果有一个名为 proType 的属性,类型为 Integer,使用 @JsonProperty("pro_type") 注解可以确保在序列化为 JSON 或从 JSON 反序列化时,该属性与 "pro_type" 键名进行映射。
7. @DateTimeFormat(pattern = "yyyy-MM-dd")
@JsonProperty("start_date")
@JsonFormat(pattern = "yyyy-MM-dd")
@DateTimeFormat(pattern = "yyyy-MM-dd")
@Excel(name = "代任開始日期", width = 30, dateFormat = "yyyy-MM-dd")
@ApiModelProperty("代任開始日期")
private LocalDate startDate;@DateTimeFormat 注解用于将请求参数中的日期字符串按照指定的格式进行解析,并绑定到对应的日期属性上。
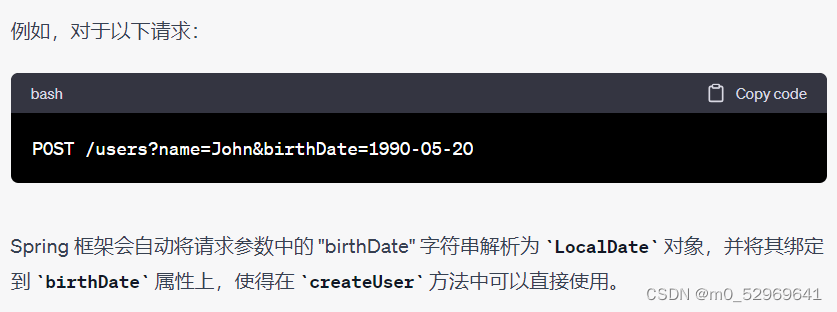
8. 校验注解
8.1. 非NULL型
@Null —— 强制为NULL
@NotNull —— 强制不能为NULL
@NotEmpty —— 它要求字符串不为 null 且长度大于0,集合或数组不为 null 且包含至少一个元素。(不去除空格)
@NotBlank —— 用于验证字符串类型的对象是否非空且去除空格后长度大于0。它要求字符串不为 null 且除去前后空格后的长度大于0。(出去空格)
@Null(message = "必须为null")
private String username;
@NotNull(message = "必须不为null")
private String username;
@NotBlank(message = "必须不为空(不能全是空白)")
private String username;
@NotEmpty(message = "必须不为null且不为空(可以全是空白)")
private String username;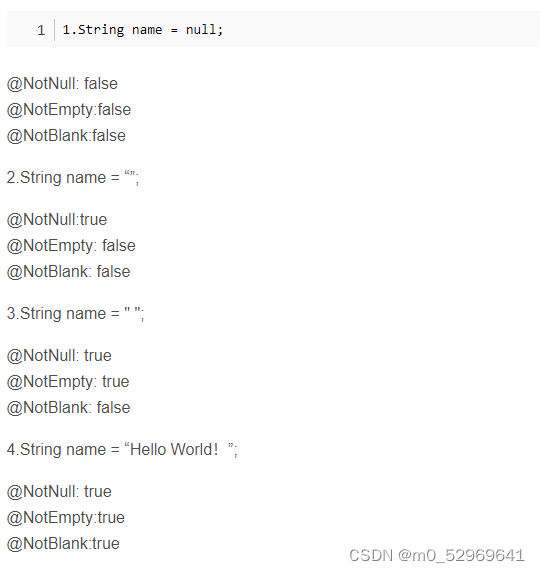
8.2. 限制范围
@Size:用于验证字符串、集合或数组类型的对象的长度是否在指定范围内。可以指定最小长度和最大长度。
@Size(min = 6, max = 20)
private String password;
@Size(min = 1, max = 5)
private List<String> hobbies;@Min 和 @Max:用于验证数值类型的对象是否在指定的最小值和最大值范围内。
@Min(value = 18, message = "必须大于等于18")
private int age;
//也可以写成
@Min(10)
@Max(value = 18, message = "必须小于等于18")
private int age;
@DecimalMin(value = "150", message = "必须大于等于150")
private BigDecimal height;
@DecimalMax(value = "300", message = "必须大于等于300")
private BigDecimal height;
@Range(max = 80, min = 18, message = "必须大于等于18或小于等于80")
private int age;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Past(message = "必须为过去的时间")
private Date createDate;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Future(message = "必须为未来的时间")
private Date createDate;@Length(max = 11, min = 7, message = "长度必须大于等于7或小于等于11")
private String mobile;
@Size(max = 11, min = 7, message = "长度必须大于等于7或小于等于11")
private String mobile;
@Digits(integer=3,fraction = 2,message = "整数位上限为3位,小数位上限为2位")
private BigDecimal height;
@Pattern(regexp = "\\d{11}",message = "必须为数字,并且长度为11")
private String mobile;
@Email(message = "必须是邮箱")
private String email;
8.3.分组
@TableField("deadline")
@NotNull(groups = {IGroups.ADD.class, IGroups.MOD.class})
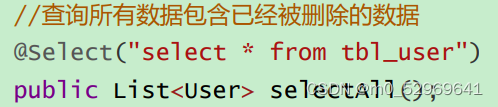
private Long deadline;9. 逻辑删除(deleted)@TableLogic——记得在数据库中加入deleted列
@TableLogic(value="0",delval="1")
//value为正常数据的值,delval为删除数据的值
private Integer deleted;作用:MP的逻辑删除会将所有的查询都添加一个未被删除的条件,也就是只在MP查询才会生效
如果想把已经删除的数据都查询出来该如何实现呢?(用自己的查询而不是MP内置的查询)
这里也告诉我们:在自己写查询语句时要加上deleted = 0;
3. 代码样例
注意:如果对象需要在网络中进行传输,或进行持久化储存或进行深度复刻,需要实现Serializable类并且定义serialVersionUID字段
implements Serializable 是 Java 中的一个接口实现,用于表示一个类可以被序列化。
序列化是指将对象转换为字节流的过程,以便在网络上传输或将其存储到持久化存储器(如磁盘)中。通过实现 Serializable 接口,可以将对象转换为字节序列,使其能够在不同的环境中进行传输和存储。
以下是一些 implements Serializable 的作用:
- 对象的持久化:实现 Serializable 接口的类的对象可以被序列化并存储到文件或数据库中,以便在后续的读取和使用。
- 分布式系统通信:在分布式系统中,对象需要在网络中传输。通过序列化,可以将对象转换为字节流,以便在网络中传输,并在接收端重新反序列化为对象。
- 对象的深度复制:通过序列化和反序列化,可以实现对象的深度复制。即通过将对象序列化为字节流,然后再反序列化为一个新的对象,从而创建一个原始对象的独立副本。
// 一个用于传输的消息对象
public class Message implements Serializable {
private static final long serialVersionUID = 1L;
private String content;
// 构造方法、getter 和 setter 方法省略
}package com.boardware.inspection.core.admin.entity;
import com.baomidou.mybatisplus.annotation.*;
import com.boardware.inspection.core.admin.enums.DeadlineEnums;
import com.boardware.inspection.core.commons.IGroups;
import com.boardware.inspection.core.commons.annotation.CompareField;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Null;
import java.time.LocalDate;
import java.time.LocalDateTime;
/**
* @author coby.chen
* @date 2023/4/3 19:46
* @description 系統上限配置
**/
@AllArgsConstructor
@NoArgsConstructor
@Data
@Builder(toBuilder = true)
@TableName("sys_deadline_conf")
public class SysDeadlineConfModel {
@NotNull(groups = IGroups.MOD.class)
@Null(groups = IGroups.ADD.class)
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
@CompareField(name = "期限")
@TableField("deadline")
@NotNull(groups = {IGroups.ADD.class, IGroups.MOD.class})
private Long deadline;
@CompareField(name = "類型", enums = DeadlineEnums.class)
@TableField("deadline_type")
@NotNull(groups = {IGroups.ADD.class, IGroups.MOD.class})
private DeadlineEnums deadlineType;
@TableField("deadline_desc")
private String deadlineDesc;
@CompareField(name = "生效日期")
@NotNull(groups = {IGroups.ADD.class, IGroups.MOD.class})
@TableField("begin_date")
private LocalDate beginDate;
@Null
@TableField(value = "create_time", fill = FieldFill.INSERT)
private LocalDateTime createTime;
@Null
@TableField(value = "create_by", fill = FieldFill.INSERT)
private Integer createBy;
@Null
@TableField(value = "update_time", fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;
@Null
@TableField(value = "update_by", fill = FieldFill.INSERT_UPDATE)
private Integer updateBy;
@Null
@TableField("deleted")
@TableLogic(delval = "1", value = "0")
private Integer deleted;
}
4. 数据库中样式:
特点:添加comment(便于查看)
create table dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
deleted int default 0 comment '逻辑删除',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-- 部门表测试数据
insert into dept (id, name, create_time, update_time)
values (1, '学工部', now(), now()),
(2, '教研部', now(), now()),
(3, '咨询部', now(), now()),
(4, '就业部', now(), now()),
(5, '人事部', now(), now());五. View层(视图层):负责前台jsp页面的表示
此层与控制层结合比较紧密,需要二者结合起来协同工发。View层主要负责前台jsp页面的表示
六.其他
1. 继承IService(业务层)
public interface IInpCaseRecordService extends IService<InpCaseRecordModel> {@Service
public class InpCaseRecordDocServiceImpl extends ServiceImpl<InpCaseRecordDocMapper, InpCaseRecordDocModel> implements IInpCaseRecordDocService 1.1. 方法
//userService是接口UserService的实现类
//查询所有
userService .list();
//查询数量
userService .count();
//根据ID查list集合
userService .listByIds();
//根据ID删除
userService .removeById();
userService .removeByIds();
//修改
userService .update();
//新增
userService .save();1.2. 插入数据(save+saveOrUpdate)

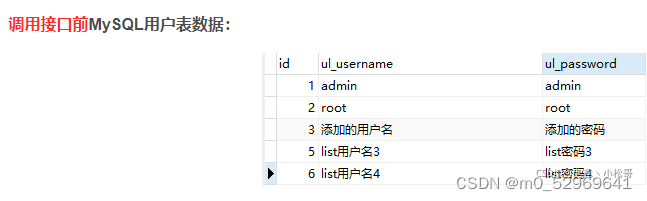
更新+添加用户信息:

或者
/** 注解TableId()——更新+添加用户信息 */
//浏览器访问 http://localhost:8085/user-login-bean/addSaveOrUpdateUserInfo/qe用户名/qe密码
@RequestMapping("/addSaveOrUpdateUserInfo/{username}/{password}")
//username 和 password 的值,从URL中获取
public boolean addSaveOrUpdateUserInfo(@PathVariable("username") String username,@PathVariable("password") String password){
//创建更新条件构造器对象
UpdateWrapper<UserLoginBean> updateWrapper = new UpdateWrapper<>();
//eq 等于:"ul_userName"(用户名)为"admin"的用户信息存在就更新记录为"qe用户名",不存在就添加一条用户名记录"admin"
//eq 等于:"ul_password"(密码)为"admin"的用户信息存在就更新记录"qe密码",不存在就添加一条密码记录"admin"
updateWrapper.eq("ul_username","admin");
updateWrapper.eq("ul_password","admin");
//saveOrUpdate()是mybatis-plus封装好的,需要实体类自增ID使用 注解@TableId(),
//第一个参数是:实体对象数据,第二个参数是:更新条件构造器对象,返回布尔类型
return userLoginService.saveOrUpdate(new UserLoginBean("操作后"+username,"操作后"+password),updateWrapper);
}说明:saveOrUpdate() 判断ID是否存在,如果ID不存在执行新增,如果ID存在则先执行查询语句,然后进行修改。
详细:当前用户表中存在了用户名"admin"和密码"admin",如果访问此接口,那么首先会判断指定的qe(k,v)的用户名和密码是否已存在。
——已存在时:获取URL的新用户名值和新密码值,执行UPDATE更新操作。
——不存在时:获取URL的新用户名值和新密码值,执行INSERT添加操作。

批量传入:
1.3. 删除数据(remove)
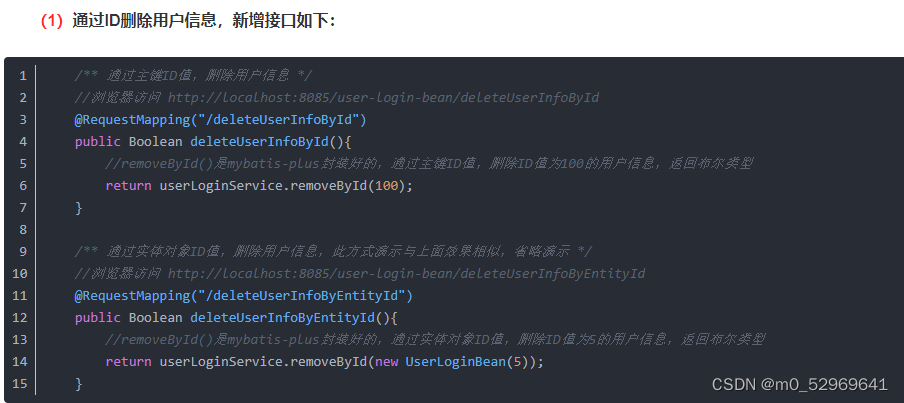
removeById()也可以传入一个数据对象,但是对象中必须包含ID,例如用@RequestBody传入json对象,则json中一定要含有id,否则删除不了
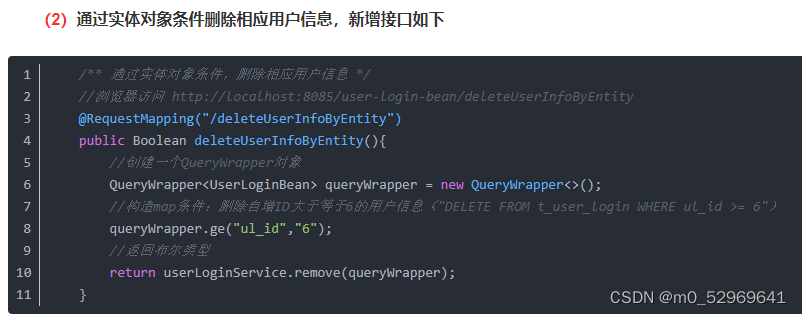
(3)通过Map集合条件,删除相应用户信息,新增接口如下:
每一个put语句相当于mysql中的and
/** 通过Map集合条件,删除相应用户信息 */
//浏览器访问 http://localhost:8085/user-login-bean/deleteUserInfoByMap
@RequestMapping("/deleteUserInfoByMap")
public Boolean deleteUserInfoByMap() {
//创建Map集合,装载条件数据
HashMap<String, Object> hashMap = new HashMap<>();
//构造map条件,(DELETE FROM t_user_login WHERE ul_id = 2 AND ul_password = "2更新后qe密码" AND ul_username = "2更新后root")
//每一个put()等同于一个MySQL的并且"AND"
hashMap.put("ul_id",2);
hashMap.put("ul_username","2更新后root");
hashMap.put("ul_password","2更新后qe密码");
//返回布尔类型
return userLoginService.removeByMap(hashMap);
}
1.4. 更新数据(Update)

(2)通过 UpdateWrapper 条件,更新用户信息 需要设置 sqlset,新增接口如下:
/** 通过 UpdateWrapper 条件,更新用户信息 需要设置 sqlset */
//浏览器访问 http://localhost:8085/user-login-bean/updateUserInfoBySqlSet
@RequestMapping("/updateUserInfoBySqlSet")
public Boolean updateUserInfoBySqlSet(){
//创建 UpdateWrapper 对象
UpdateWrapper<UserLoginBean> updateWrapper = new UpdateWrapper<>();
//构造条件
updateWrapper
.eq("ul_username","更新用户名root") // ul_username = '更新用户名root'
.eq("ul_password","更新密码root") // ul_password = '更新密码root'
//更新的set参数值
.setSql("ul_username = 'update用户名',ul_password = 'update密码'");
/** 以上构造条件,效果等同于以下单独set() */
// updateWrapper
// .eq("ul_username","更新用户名root")
// .eq("ul_password","更新密码root")
// .set("ul_username","update用户名")
// .set("ul_password","update密码");
//返回布尔类型
return userLoginService.update(updateWrapper);
}
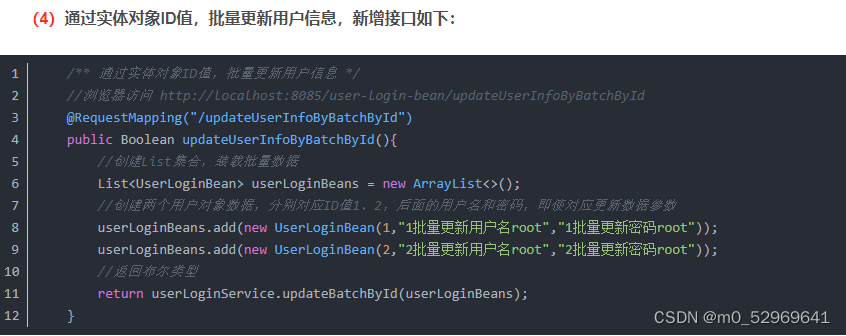
2. Mapper(持久层)——继承BaseMapper
2.1. 插入数据——insert(model)
// 插入一条记录
int insert(T entity);
UserEntity user = new UserEntity();
user.setName("John");
user.setAge(25);
user.setEmail("john@example.com");
userMapper.insert(user);2.2. 删除数据——delete
前面的int返回值是 删除的记录条数,例如deleteById可能为1或0
// 根据 ID 删除
int deleteById(Serializable id);
// 根据 columnMap 条件,删除记录(columnMap 表字段map对象)
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 根据 entity 条件,删除记录
// queryWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 删除(根据ID 批量删除)
// idList 主键ID列表(不能为 null 以及 empty)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
详细使用:
1. 根据id删除——直接id作为参数即可(*)
int deleteById(Serializable id);
// 示例用法
int id = 2;
int result = userMapper.deleteById(id);
System.out.println("删除记录数:" + result);//删除记录数:1参数类型为什么是一个序列化类(Serializable)?

2. 根据ColumnMap条件删除记录(批量删除)
相当于删除age = 22 的记录(每个put相当于where后的一个and)
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
// 示例用法
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("age", 22);
int result = userMapper.deleteByMap(columnMap);
System.out.println("删除记录数:" + result);3. 根据QueryWrapper条件删除记录(重点:批量删除)
int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
// 示例用法
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("gender", "Female");
int result = userMapper.delete(queryWrapper);
System.out.println("删除记录数:" + result);4. 根据id批量删除
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
// 示例用法
List<Integer> idList = Arrays.asList(1, 2);
int result = userMapper.deleteBatchIds(idList);
System.out.println("删除记录数:" + result);2.3. 修改数据
1. 根据id修改
传入的参数可以为一个id值也可以为一个类,但是类中必须包含id这个属性
int updateById(@Param(Constants.ENTITY) T entity);
// 示例用法
UserEntity user = userMapper.selectById(1);
user.setAge(30);
int result = userMapper.updateById(user);
System.out.println("更新记录数:" + result);2. 根据entity条件修改(批量修改)
理解:
第一步:先通过筛选条件筛选出name = John的user
第二步:创建一个user对象将Age设定为35
最后执行的结果是:满足条件的user的年龄都被修改为35,其他的保持不变,也就是说只有显式设置的字段才会被修改,也就是只有user.set属性()才会修改,其他的不会被修改
说明:修改的时候,只修改实体对象中有值的字段。
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper);
// 示例用法
QueryWrapper<UserEntity> updateWrapper = new QueryWrapper<>();
updateWrapper.eq("name", "John");
UserEntity user = new UserEntity();
user.setAge(35);
int result = userMapper.update(user, updateWrapper);
System.out.println("更新记录数:" + result);2.4. 查询相关
1. 根据ID查询——返回查询对象
T user = userMapper.selectById(1);
System.out.println("查询结果:" + user);2. selectList——根据entity条件查询全部记录
// 查询所有
List<User> userList = userDao.selectList(null);QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.like("name", "A");
List<T> users = userMapper.selectList(queryWrapper);
System.out.println("查询结果:" + users);3. 根据id批量查询
List<T> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
System.out.println("查询结果:" + users);4. 根据ColumnMap条件查询——selectByMap(columnMap)
Map<String, Object> columnMap = new HashMap<>();
columnMap.put("age", 25);
List<T> users = userMapper.selectByMap(columnMap);
System.out.println("查询结果:" + users);5. 查询一条记录——selectOne
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("gender", "Female");
T user = userMapper.selectOne(queryWrapper);
System.out.println("查询结果:" + user);6. 查询总记录条数
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);
Integer count = userMapper.selectCount(queryWrapper);
System.out.println("查询结果:" + count);7. 分页查询 selectPage
// 创建查询条件
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.ge("age", 30).orderByDesc("age");
// 创建分页对象,查询第一页,每页两条记录
IPage<UserEntity> page = new Page<>(1, 2);
// 执行分页查询
IPage<UserEntity> resultPage = userMapper.selectPage(page, queryWrapper);
// 输出分页结果
System.out.println("总记录数:" + resultPage.getTotal());
System.out.println("当前页码:" + resultPage.getCurrent());
System.out.println("每页记录数:" + resultPage.getSize());
System.out.println("总页数:" + resultPage.getPages());
System.out.println("是否有上一页:" + resultPage.hasPrevious());
System.out.println("是否有下一页:" + resultPage.hasNext());
List<UserEntity> userList = resultPage.getRecords();
for (UserEntity user : userList) {
System.out.println(user);
}总记录数:4
当前页码:1
每页记录数:2
总页数:2
是否有上一页:false
是否有下一页:true
UserEntity{id=5, name='Eve', age=45}
UserEntity{id=4, name='David', age=40}3. QueryWrapper常用条件
3.1. 通用条件
- eq(column, value):等于,设置字段名column等于指定的值value的查询条件。
- ne(column, value):不等于,设置字段名column不等于指定的值value的查询条件。
- gt(column, value):大于,设置字段名column大于指定的值value的查询条件。
- ge(column, value):大于等于,设置字段名column大于等于指定的值value的查询条件。
- lt(column, value):小于,设置字段名column小于指定的值value的查询条件。
- le(column, value):小于等于,设置字段名column小于等于指定的值value的查询条件。
- between(column,value1,value2);

- like(column, value):模糊匹配,设置字段名column的值包含指定的字符或字符模式value的查询条件。
- likeLeft(column, value):设置字段名column的值以value的值开头(下列表示:查询表中name属性的值以J开头的用户信息,使用like进行模糊查询)

- likeRight(column, value): 以value结尾
- in(column, values):包含于,设置字段名column的值在给定值列表values中的查询条件。
- notIn(column, values):不包含于,设置字段名column的值不在给定值列表values中的查询条件。
- isNull(column):为空,设置字段名column的值为空的查询条件。
- isNotNull(column):不为空,设置字段名column的值不为空的查询条件。
- orderByAsc(column):升序排序,按字段名column进行升序排序。
- orderByDesc(column):降序排序,按字段名column进行降序排序
- or() : 或者
lqw.lt(User::getAge, 10).or().gt(User::getAge, 30);

3.2. QueryWrapper格式
格式:
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 25);拓展:
UpdateWrapper:和QueryWrapper相似,主要用于更新,但是可以被QueryWrapper替代
也就是说里面既可以用QueryWrapper也可以用UpdateWrapper
UpdateWrapper<UserEntity> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name", "Alice");
UserEntity updateUser = new UserEntity();
updateUser.setAge(30);
int rows = userMapper.update(updateUser, updateWrapper);
System.out.println("更新影响的行数:" + rows);3.3. LambdaQueryWrapper——更好地避免前面的属性书写错误
LambdaQueryWrapper<UserEntity> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(UserEntity::getName, "Alice")
.gt(UserEntity::getAge, 25);
List<UserEntity> userList = userMapper.selectList(queryWrapper);
for (UserEntity user : userList) {
System.out.println(user);
}3.4. 对于NULL的判断

等价于:
3.5. 查询指定字段(select)
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.select(User::getId,User::getName,User::getAge);
List<User> userList = userDao.selectList(lqw);
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("id","name","age");
List<User> userList = userDao.selectList(lqw);
SELECT id,name,age FROM user
3.6. 聚合查询
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("count(*) as count");
//SELECT count(*) as count FROM user
lqw.select("max(age) as maxAge");
//SELECT max(age) as maxAge FROM user
lqw.select("min(age) as minAge");
//SELECT min(age) as minAge FROM user
lqw.select("sum(age) as sumAge");
//SELECT sum(age) as sumAge FROM user
lqw.select("avg(age) as avgAge");
//SELECT avg(age) as avgAge FROM user
List<Map<String, Object>> userList = userDao.selectMaps(lqw);
3.7. 分组查询
QueryWrapper<User> lqw = new QueryWrapper<User>();
lqw.select("count(*) as count,tel");
lqw.groupBy("tel");
List<Map<String, Object>> list = userDao.selectMaps(lqw);

4. 分页知识Ipage
1. 基础知识
分页是一种常见的数据展示和查询方式,它将大量数据按照固定的页数进行划分,每次只显示一页的数据。分页的意义在于:
- 提高用户体验:当处理大量数据时,一次性展示所有数据可能会导致页面加载缓慢或卡顿。通过分页,可以将数据分成多个页面,用户可以按需加载和浏览数据,提高用户的浏览体验。
- 减少数据传输量:分页查询只返回当前页的数据,而不是一次性返回全部数据。这样可以减少网络传输量,加快数据的获取速度,特别是在网络条件较差的情况下。
- 优化系统性能:对于大规模数据的查询和处理,将数据分页加载可以减轻数据库或应用服务器的负担,提高系统的响应速度和整体性能。
IPage<Student> page = new Page<>(3,10);
其中的3和10一般是用户输入,返回的是符合条件的总记录中的第3页的10条信息(如果用户不输入需要我们设置一个默认值)
// 创建分页对象,每页显示10条记录,查询第3页
IPage<Student> page = new Page<>(3, 10);
// 执行分页查询
IPage<Student> resultPage = studentMapper.selectPage(page, null);
// 输出分页结果
System.out.println("总记录数:" + resultPage.getTotal());
System.out.println("当前页码:" + resultPage.getCurrent());
System.out.println("每页记录数:" + resultPage.getSize());
System.out.println("总页数:" + resultPage.getPages());
System.out.println("是否有上一页:" + resultPage.hasPrevious());
System.out.println("是否有下一页:" + resultPage.hasNext());
List<Student> studentList = resultPage.getRecords();
for (Student student : studentList) {
System.out.println(student);
}总记录数:1000
当前页码:3
每页记录数:10
总页数:100
是否有上一页:true
是否有下一页:true
Student{id=21, name='Alice', age=18}
Student{id=22, name='Bob', age=19}
...
Student{id=30, name='Zoe', age=17}2. 分页查询使用
// 创建查询条件
QueryWrapper<UserEntity> queryWrapper = new QueryWrapper<>();
queryWrapper.ge("age", 30).orderByDesc("age");
// 创建分页对象,查询第一页,每页两条记录
IPage<UserEntity> page = new Page<>(1, 2);
// 执行分页查询
IPage<UserEntity> resultPage = userMapper.selectPage(page, queryWrapper);
// 输出分页结果
System.out.println("总记录数:" + resultPage.getTotal());
System.out.println("当前页码:" + resultPage.getCurrent());
System.out.println("每页记录数:" + resultPage.getSize());
System.out.println("总页数:" + resultPage.getPages());
System.out.println("是否有上一页:" + resultPage.hasPrevious());
System.out.println("是否有下一页:" + resultPage.hasNext());
List<UserEntity> userList = resultPage.getRecords();
for (UserEntity user : userList) {
System.out.println(user);
}总记录数:4
当前页码:1
每页记录数:2
总页数:2
是否有上一页:false
是否有下一页:true
UserEntity{id=5, name='Eve', age=45}
UserEntity{id=4, name='David', age=40}3. 讲解




@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//1 创建MybatisPlusInterceptor拦截器对象
MybatisPlusInterceptor mpInterceptor=new MybatisPlusInterceptor();
//2 添加分页拦截器
mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mpInterceptor;
}
}
要使用分页技术就必须配置分页拦截器,分页拦截器会对所有的sql语句进行拦截,满足条件的分页语句会被拦截下来,然后按照selectPage提供的Ipage对此sql语句进行条件增加然后再搜索,从而实现返回分页(也就是返回数据的不同)

4. 代码
public IPage<RoleModel> getRoleList(String name, Integer status, Integer page, Integer perPage) {
List<PermissionModel> permissions = permissionMapper.selectListWithRoleId();
LambdaQueryWrapper<RoleModel> queryWrapper = Wrappers.lambdaQuery(RoleModel.class);
// 分页默认值
if (BwObjectUtils.isEmpty(page) || BwObjectUtils.isEmpty(perPage)) {
page = 1;
//先将返回值转为string,再用NumberUtils.toInt方法转为整形,这里如果字符串解析失败返回默认值0
perPage = NumberUtils.toInt(roleMapper.selectCount(queryWrapper).toString());
}
queryWrapper.ne(RoleModel::getStatus, 2);
if (BwObjectUtils.isNotEmpty(name)) {
queryWrapper.like(RoleModel::getName, name);
}
if (status != null) {
queryWrapper.eq(RoleModel::getStatus, status);
}
queryWrapper.orderByDesc(RoleModel::getCreateTime);
Page<RoleModel> rolePage = new Page<>(page, perPage);
IPage<RoleModel> ipage = roleMapper.selectPage(rolePage, queryWrapper);
List<RoleModel> roleModelList = ipage.getRecords();
roleModelList.forEach(v -> {
List<PermissionModel> permissionList = permissions.stream().filter(r -> r.getRoleId().equals(v.getId())).collect(Collectors.toList());
v.setPermissionList(permissionList);
});
ipage.setRecords(roleModelList);
return ipage;
} roleModelList.forEach(v -> {
List<PermissionModel> permissionList = permissions.stream().filter(r -> r.getRoleId().equals(v.getId())).collect(Collectors.toList());
v.setPermissionList(permissionList);
});
- 使用 forEach 方法遍历 roleModelList 中的每个角色对象,用变量 v 表示当前遍历到的角色对象。
- 在遍历过程中,使用 Stream API 的 filter 方法对 permissions 列表进行筛选。通过传入的 lambda 表达式 r -> r.getRoleId().equals(v.getId()),筛选出具有与当前角色对象ID相匹配的权限对象。
- 使用 collect 方法将筛选出的权限对象收集到一个新的列表中,通过 Collectors.toList() 指定收集为列表类型。
- 将收集到的权限列表 permissionList 设置给当前的角色对象 v,通过 v.setPermissionList(permissionList) 进行赋值操作。
5. 对数据统一组合
对前面业务层函数返回的数据进行统一封装
例如下列:首先进行分页配置,导致后续的查询会自动进行分页,最后将 结果传给RTableDateInfo.build统一构造成RTableDataInfo类型
@Override
public RTableDataInfo<LimitTimeModel> query(String name) {
PageUtils.startPage();
var searchResult = limitTimeMapper.search(name);
return RTableDataInfo.build(searchResult);
}package com.boardware.inspection.common.core.page;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.github.pagehelper.PageInfo;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
import java.util.List;
/**
* 表格分页数据对象(支持泛型)
*
* @author Lion Li
*/
@Data
@NoArgsConstructor
@ApiModel("分页响应对象")
public class RTableDataInfo<T> implements Serializable {
private static final long serialVersionUID = 1L;
@ApiModelProperty("列表大小")
private long size;
@ApiModelProperty("总记录数")
private long total;
@ApiModelProperty("列表数据")
private List<T> records;
/**
* 分页
*
* @param records 列表数据
* @param total 总记录数
*/
public RTableDataInfo(List<T> records, long total) {
this.records = records;
this.total = total;
}
public static <T> RTableDataInfo<T> build(IPage<T> page) {
RTableDataInfo<T> rspData = new RTableDataInfo<>();
rspData.setRecords(page.getRecords());
rspData.setTotal(page.getTotal());
rspData.setSize(page.getRecords().size());
return rspData;
}
public static <T> RTableDataInfo<T> build(List<T> list) {
RTableDataInfo<T> rspData = new RTableDataInfo<>();
rspData.setRecords(list);
rspData.setSize(list.size());
rspData.setTotal(new PageInfo(list).getTotal());
return rspData;
}
public static <T> RTableDataInfo<T> build(List<T> list, long total) {
RTableDataInfo<T> rspData = new RTableDataInfo<>();
rspData.setRecords(list);
rspData.setSize(list.size());
rspData.setTotal(total);
return rspData;
}
public static <T> RTableDataInfo<T> build() {
RTableDataInfo<T> rspData = new RTableDataInfo<>();
return rspData;
}
}
6. Springboot项目配置
6.1. 取消log打印
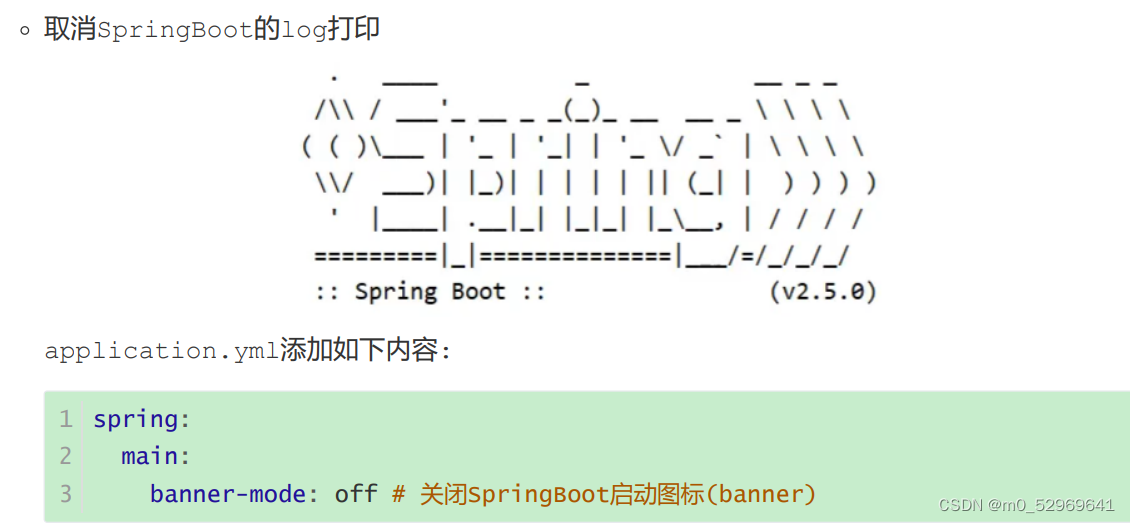
spring:
main:
banner-mode: off # 关闭SpringBoot启动图标(banner)6.2. 取消MybatisPlus启动banner图标

# mybatis-plus日志控制台输出
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
banner: off # 关闭mybatisplus启动图标6.3. 将每个模型类的主键ID策略都设置为assign_id.
mybatis-plus:
global-config:
db-config:
id-type: assign_id
6.4. 每个表都配置逻辑删除(deleted)
mybatis-plus:
global-config:
db-config:
# 逻辑删除字段名
logic-delete-field: deleted
# 逻辑删除字面值:未删除为0
logic-not-delete-value: 0
# 逻辑删除字面值:删除为1
logic-delete-value: 1
6.5. 开启日志输出到控制台:(application.properties)
#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl6.6. 开启事务管理日志
说明:可以在application.yml配置文件中开启事务管理日志,这样就可以在控制看到和事务相关的日志信息了
#spring事务管理日志
logging:
level:
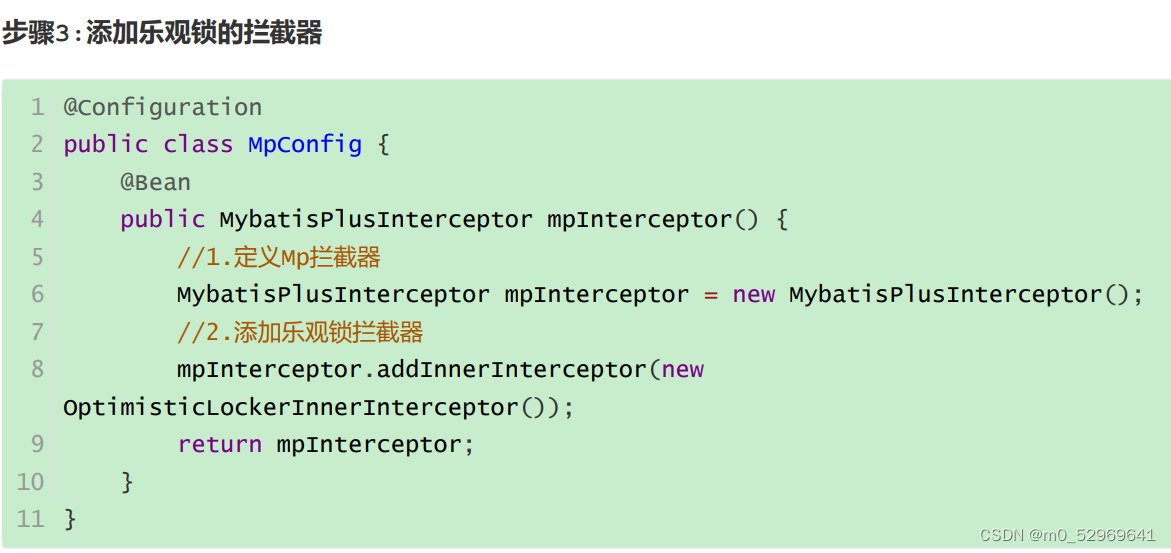
org.springframework.jdbc.support.JdbcTransactionManager: debug7.乐观锁(添加version列)









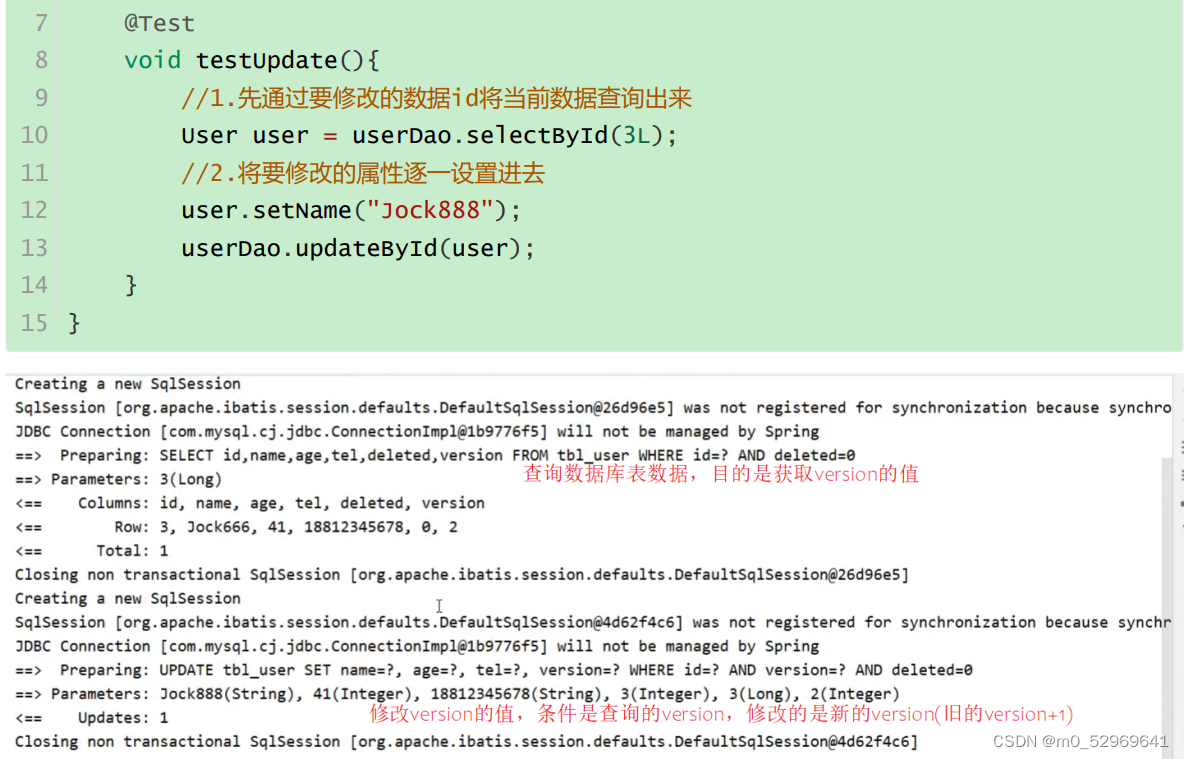
所以要想实现乐观锁,首先第一步应该是拿到表中的version,然后拿version当条件在将version 加1更新回到数据库表中,所以我们在查询的时候,需要对其进行查询
下图中可以看出:查询并不会修改version的值,而只有修改操作会修改version的值
实验:


8. 连接池(druid)
没有使用数据库连接池:
- 客户端执行SQL语句:要先创建一个新的连接对象,然后执行SQL语句,SQL语句执行后又需要关闭连接对象从而释放资源,每次执行SQL时都需要创建连接、销毁链接,这种频繁的重复创建销毁的过程是比较耗费计算机的性能。

替换默认连接池为durid连接池 :
1. 在pom.xml文件中引入依赖
<dependency> <!-- Druid连接池依赖 --> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.2.8</version> </dependency>2. 在application.properties中引入数据库连接配置
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.druid.username=root spring.datasource.druid.password=1234 或者 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/mybatis spring.datasource.username=root spring.datasource.password=1234
9. 防止sql注入(#{}——预编译)
SQL注入:是通过操作输入的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法。
由于没有对用户输入进行充分检查,而SQL又是拼接而成,在用户输入参数时,在参数中添加一些SQL关键字,达到改变SQL运行结果的目的,也可以完成恶意攻击。

10. Mybatis多表查询映射配置
首先分析问题:
当我们进行多表查询时,返回的结果集一定是两个表中的数据,那么我们总不能再准备一个(包含两个表中所有字段的)POJO来映射这次返回的结果。
这时,我们可以考虑让第一个表的POJO包含第二个表的POJO(其实就是:为第一个表的POJO增加一个属性,类型就为第二个表的POJO);然后通过MyBatis提供的手动映射的方式,将结果集 分别 封装到对应的对象中去
10.1. 一对一关系(association)
实体类OrderVo中含有另一个实体类User
1. 第一个resultMap:
- id —— 你想要查询出来的封装结果的别名
- type: 较大的类的实体名(此处OrderVo包含User,所以此处type为ordervo)
2. 第二个association:
- property:较小的类的实体名user
- javatype:较小类的class name 注意为class的名字(User)
public class OrderVo {
private Integer id;
private Integer uid;
private String number;
private Timestamp createtime;
private String des;
private User user;//订单中的用户信息可以放在这个user属性中
}
<resultMap id="resultMap_order_user" type="ordervo">
<id column="id" property="id"/>
<result column="uid" property="uid"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<association property="user" javaType="User">
<id column="id" property="id"/>
<result column="username" property="username"/>
</association>
</resultMap>
<!-- 查询出来的字段有:订单id,该订单的用户id,订单编号,订单创建时间,订单简介,对应用户的id,用户名-->
<select id="findOrderUserList" resultMap="resultMap_order_user">
SELECT o.id,o.uid,o.number,o.createtime,o.des,u.id,u.username
FROM t_orders o JOIN t_user u ON o.uid=u.id
</select>
10.2. 一对多关系查询(collection)
包含另一个类的列表(也可以是另一个类的id)
collection:
1. properity: 对应的列表name——orderList
2. ofType: 值为该集合的泛型类型
public class User {
private Integer id;
private String username;
private String password;
private String email;
private String remark;
private List<OrderVo> orderList;
}
<!-- 查询出来的字段有:用户的id,用户名,密码,邮箱,说明,用户的订单id,订单对应的用户id,订单的简介-->
<select id="findUserOrder" resultMap="result_user_orders">
SELECT u.id as uid,u.username,u.password,u.email,u.remark,o.id,o.uid,o.des
FROM t_user u INNER JOIN t_orders o ON u.id=o.uid
</select>
<resultMap id="result_user_orders" type="User">
<id column="uid" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="email" property="email"/>
<result column="remark" property="remark"/>
<collection property="orderList" ofType="OrderVo">
<id property="id" column="id"/>
<result property="uid" column="uid"/>
<result property="des" column="des"/>
</collection>
</resultMap>
10.3. 多对多关系查询
要实现多对多的关系,那么一定会有一个第三张表作为关系表
我们要把多对多的关系理解为一个双向的一对多:表一中的一条数据对应关系表中的多条记录,表二中的一条数据也对应关系表中的多条记录
两个POJO中分别包含对方对象List的引用
案例:查询每一个角色分别对应哪些用户
(一个用户可以有多个角色,一个角色中可以有多个用户)
public class Role {
private Integer id;
private String name;
private String keyword;
private List<User> userList;
}
<!-- 查询出来的字段有:角色的id,角色名,角色描述,对应用户的id,用户名,密码,邮箱-->
<select id="findRoleUserList" resultMap="result_role_users">
SELECT r.id as rid,r.name,r.keyword,u.id as uid,u.username,u.password,u.email
FROM t_role r LEFT JOIN t_role_user ru ON r.id=ru.role_id
LEFT JOIN t_user u ON ru.user_id=u.id
</select>
<resultMap id="result_role_users" type="role">
<id column="rid" property="id"/>
<result column="name" property="name"/>
<result column="keyword" property="keyword"/>
<collection property="userList" ofType="User">
<id column="id" property="uid"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="email" property="email"/>
</collection>
</resultMap>
public class User {
private Integer id;
private String username;
private String password;
private String email;
private String remark;
private List<Role> roleList;
}
<!-- 查询出来的字段有:用户的id,用户名,密码,邮箱,说明,对应角色的id,角色名,角色简介-->
<select id="findUserRoleList" resultMap="result_user_roles">
SELECT u.id as uid,u.username,u.password,u.email,u.remark,r.id as rid,r.name,r.keyword
WHERE t_user u LEFT JOIN t_role_user ru ON u.id=ru.user_id
LEFT JOIN t_role r ON ru.role_id=r.id
</select>
<resultMap id="result_user_roles" type="user">
<id column="uid" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="email" property="email"/>
<result column="remark" property="remark"/>
<collection property="roleList" ofType="role">
<id column="rid" property="id"/>
<result column="name" property="name"/>
<result column="keyword" property="keyword"/>
</collection>
</resultMap>
11. 公共字段自动填充(@TableField)
对于数据库一些数据,例如create_time,createByUser等,每次对数据修改都需要修改这类数据,很繁琐,因此用MP提供的公共字段填充功能
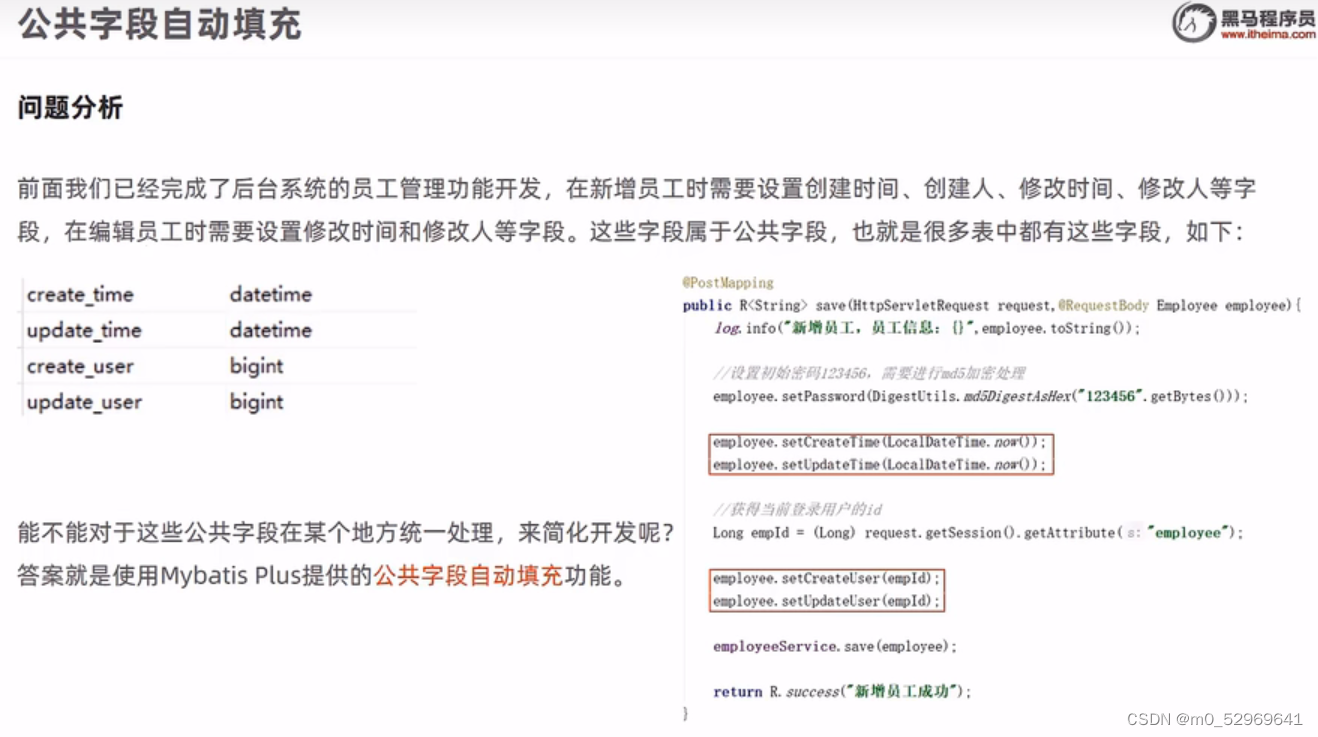


2. 继承并实现insertFill和updateFill
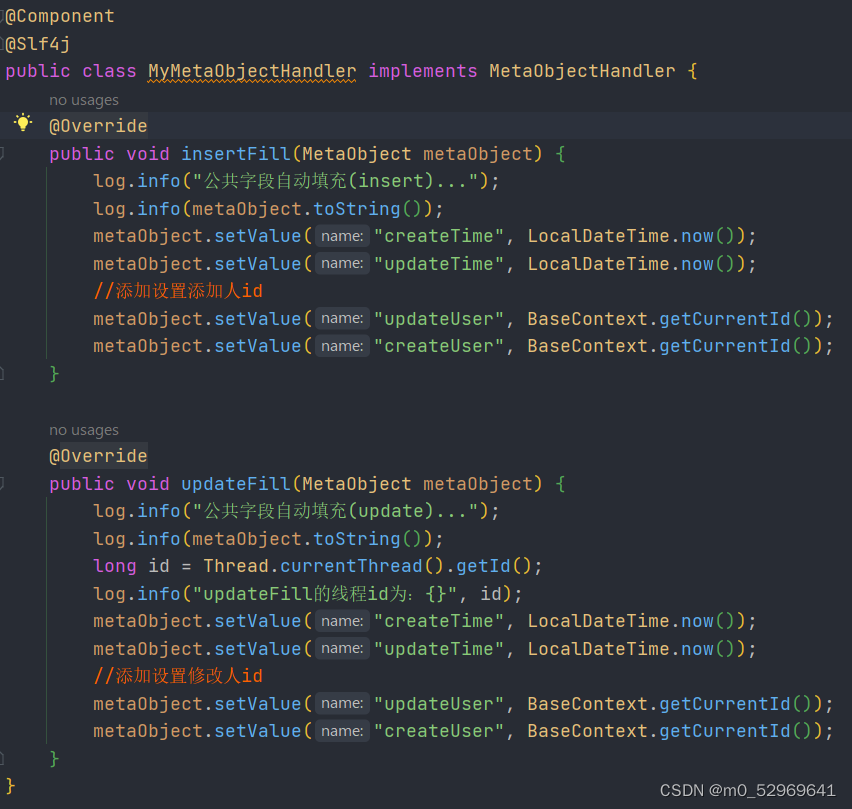
同一个线程公用一份变量副本,在线程中某个函数中设置变量,在该线程中另一个函数可以使用在同一线程中设置的变量



public class BaseContext {
private static ThreadLocal<Long> threadLocal = new ThreadLocal<>();
public static void setCurrentId(Long id) {
threadLocal.set(id);
}
public static Long getCurrentId() {
return threadLocal.get();
}
}在过滤器
//根据session来获取之前我们存的id值
Long empId = (Long) request.getSession().getAttribute("employee");
//使用BaseContext封装id,也就是将这个变量封装到线程上去
BaseContext.setCurrentId(empId);














 4874
4874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









