







起源与发展
单进程时代(第一阶段)
简单可以理解为一条线操作,一个人同一时间只能做一件事,做完一件事做下一件事。
此时是没有CPU调度器的,全部是由CPU自己在处理
所以此时CPU面临两个问题:
1.CPU同一时刻只能做一个任务并且顺序执行,一个任务一个任务处理
2.阻塞会浪费CPU的处理时间
多进程/线程时代(第二阶段)
这时运行的原理是微观上把每一个进程都分到一个时间片上,时间片很短可能只有几ms,但是宏观上看1s内就相当于同时进行了多个进程,这就是实现了进程的并发。
此时是由CPU调度器的,这也就解决了上面的阻塞问题,如果一个进程阻塞CPU,可以把它切换到其他进程中。
但是此时又有问题:
进程的创建、切换、销毁都会占用很长时间,如何提高CPU的利用率?
1.高内存占用
2.调度的高消耗CPU
协程提高CPU利用率
线程分为“内核态”线程和“用户态”线程。他们是一对一绑定的关系,但是CPU只能看到内核线程,也叫做线程,用户线程叫做协程。
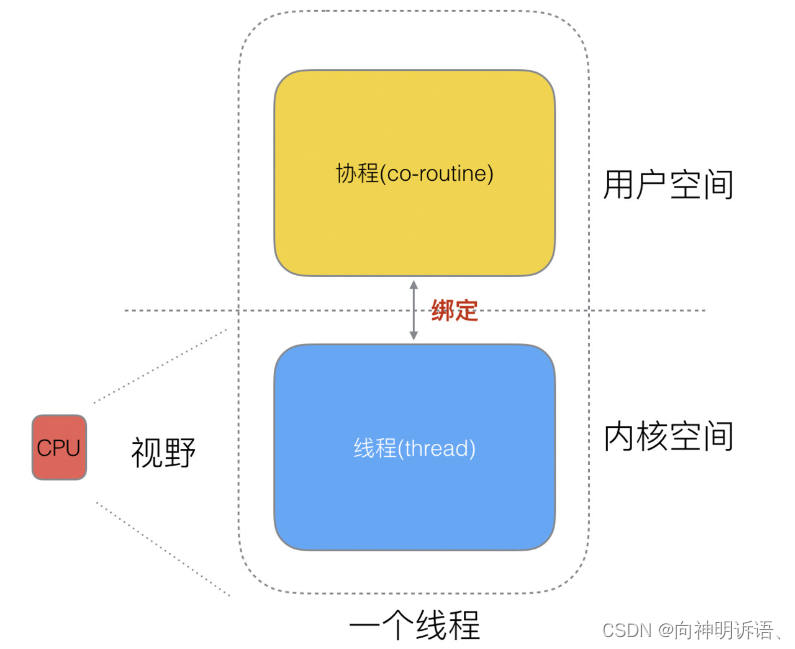
协程和线程的映射关系
N:1关系
N 个协程绑定 1 个线程,优点就是协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。但也有很大的缺点,1 个进程的所有协程都绑定在 1 个线程上
缺点:
1.某个程序用不了硬件的多核加速能力
2.一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
1:1关系
1 个协程绑定 1 个线程,这种最容易实现。协程的调度都由 CPU 完成了,不存在 N:1 缺点,
缺点:
协程的创建、删除和切换的代价都由 CPU 完成,有点略显昂贵了。
M:N关系
M 个协程绑定 1 个线程,是 N:1 和 1:1 类型的结合,克服了以上 2 种模型的缺点,但实现起来最为复杂。
协程跟线程是有区别的,线程由 CPU 调度是抢占式的,协程由用户态调度是协作式的,一个协程让出 CPU 后,才执行下一个协程。
GO语言的协程goroutine
Go 中,协程被称为 goroutine,它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配。
Goroutine 特点:
1.占用内存更小(几 kb)
2.调度更灵活 (runtime 调度)
GMP模型
- G(Goroutine): 即Go协程,每个go关键字都会创建一个协程。 M
- (Machine): 工作线程,在Go中称为Machine。
- P(Processor): 处理器(Go中定义的一个摡念,不是指CPU),包含运行Go代码的必要资源,也有调度goroutine的能力。

解释一下上面的图是干啥的
1.有个全局队列和本地队列,他们都是用来存放等待运行的G(也就是go协程),但是优先加到P的本地队列,加满了会取本地队列中的一半加到全局里,且本地G不超过256个
2.M代表的是线程,线程想要运行任务就需要获取一个P(Goroutine调度器)。
总结:我理解的简单来说就是线程是一个工程,协程是主要干活的工人,调度器就是指挥工人的监工,看哪里多,哪里少。
P和M个数问题
1、P 的数量:
由启动时环境变量 $GOMAXPROCS 或者是由 runtime 的方法 GOMAXPROCS() 决定。这意味着在程序执行的任意时刻都只有 $GOMAXPROCS 个 goroutine 在同时运行。
P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
2、M 的数量:
go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000. 但是内核很难支持这么多的线程数,所以这个限制可以忽略。
runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量
一个 M 阻塞了,会创建新的 M。
M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,就会去创建新的 M。
总结:M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
Gotoutine调度策略
1.队列轮转
每个P维护着一个包含G的队列,不考虑G进入系统调用或IO操作的情况下,P周期性的将G调度到M中执行,执行一小段时间,将上下文保存下来,然后将G放到队列尾部,然后从队列中重新取出一个G进行调度。
除了每个P维护的G队列以外,还有一个全局的队列,每个P会周期性的查看全局队列中是否有G待运行并将期调度到M中执行,全局队列中G的来源,主要有从系统调用中恢复的G。之所以P会周期性的查看全局队列,也是为了防止全局队列中的G被饿死。
2.系统调用

如图所示,当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。而M0由于陷入系统调用而进被阻塞,M1接替M0的工作,只要P不空闲,就可以保证充分利用CPU。
M1的来源有可能是M的缓存池,也可能是新建的。当G0系统调用结束后,跟据M0是否能获取到P,将会将G0做不同的处理:
如果有空闲的P,则获取一个P,继续执行G0。
如果没有空闲的P,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
3.工作量窃取
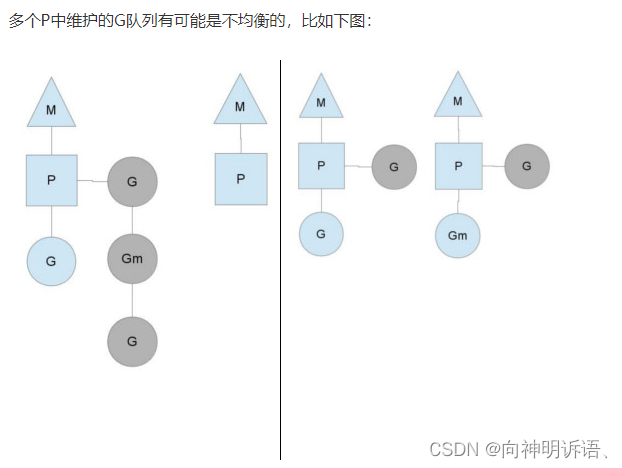
竖线左侧中右边的P已经将G全部执行完,然后去查询全局队列,全局队列中也没有G,而另一个M中除了正在运行的G外,队列中还有3个G待运行。此时,空闲的P会将其他P中的G偷取一部分过来,一般每次偷取一半。偷取完如右图所示。














 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









