









文章目录
一、论文介绍


个性化图像生成中的平衡问题:现有的zero-shot adapters方法(如IP-Adapter和OminiControl)在生成个性化图像时,难以平衡保留参考图像内容和遵循文本提示的要求。生成的图像往往只是复制个性化内容,而不是根据文本提示进行调整。
设计缺陷:现有的adapters在将个性化图像与文本描述结合时存在设计缺陷,导致生成的图像无法充分利用基础文本到图像扩散模型的概念理解能力。
Conceptrol框架:提出了一个简单但有效的框架Conceptrol,用于增强zero-shot adapters的性能,而无需增加计算开销。
注意力机制优化:通过分析注意力机制,Conceptrol利用基础扩散模型中的特定注意力块来生成文本概念掩码,并将其应用于参考图像的注意力图中,从而更好地结合个性化内容和文本提示。
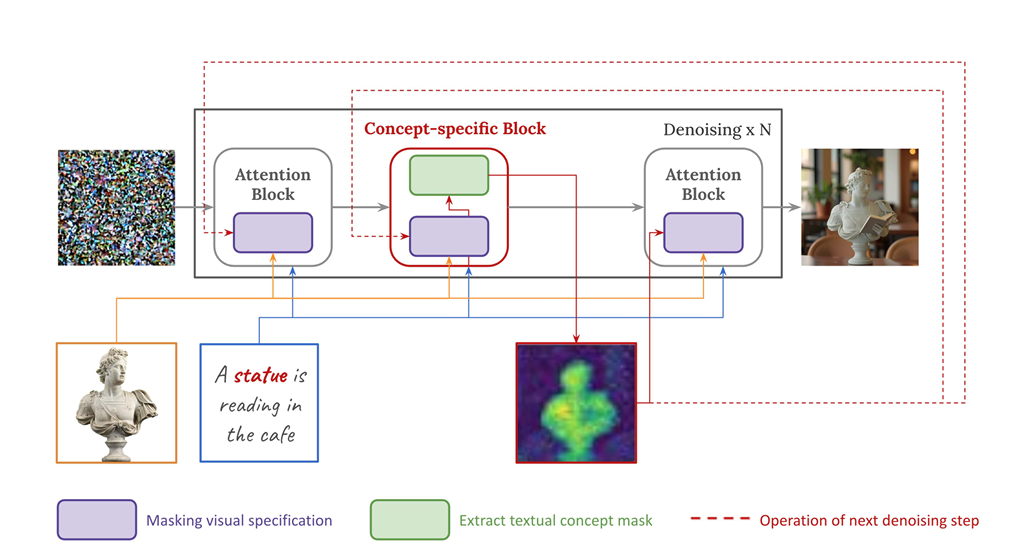
代码的设计:设计了一个新的processor
对于输入的图像特征,在图像的注意力结果之后,用一个mask对注意力的结果进行修改
这个mask是用对应概念的文本嵌入的QK注意力计算得到的(文本的QK计算得到的注意力概率)
维度是怎么对齐的呢?
1:4096:1 2:4096:320
采用广播机制,将第一个矩阵的维度进行扩充,然后相当于对每个像素点(4096)都乘以了一个数
特征图的可视化结果是对QK得到的注意力的结果,然后取特定的文本token所在的位置的注意力图,然后取均值。(4096*77)
二、项目部署
Conceptrol项目的github链接
需要下载的权重
这里跑的是sd1.5的
huggingface下载ipadapter的权重
然后下载一个SD1.5的模型权重就OK了
huggingfacesd1.5的模型权重
三、效果展示
3.1ipadapter plus sd1.5的效果
需要将图像编码器的路径改为自己下载放置的路径
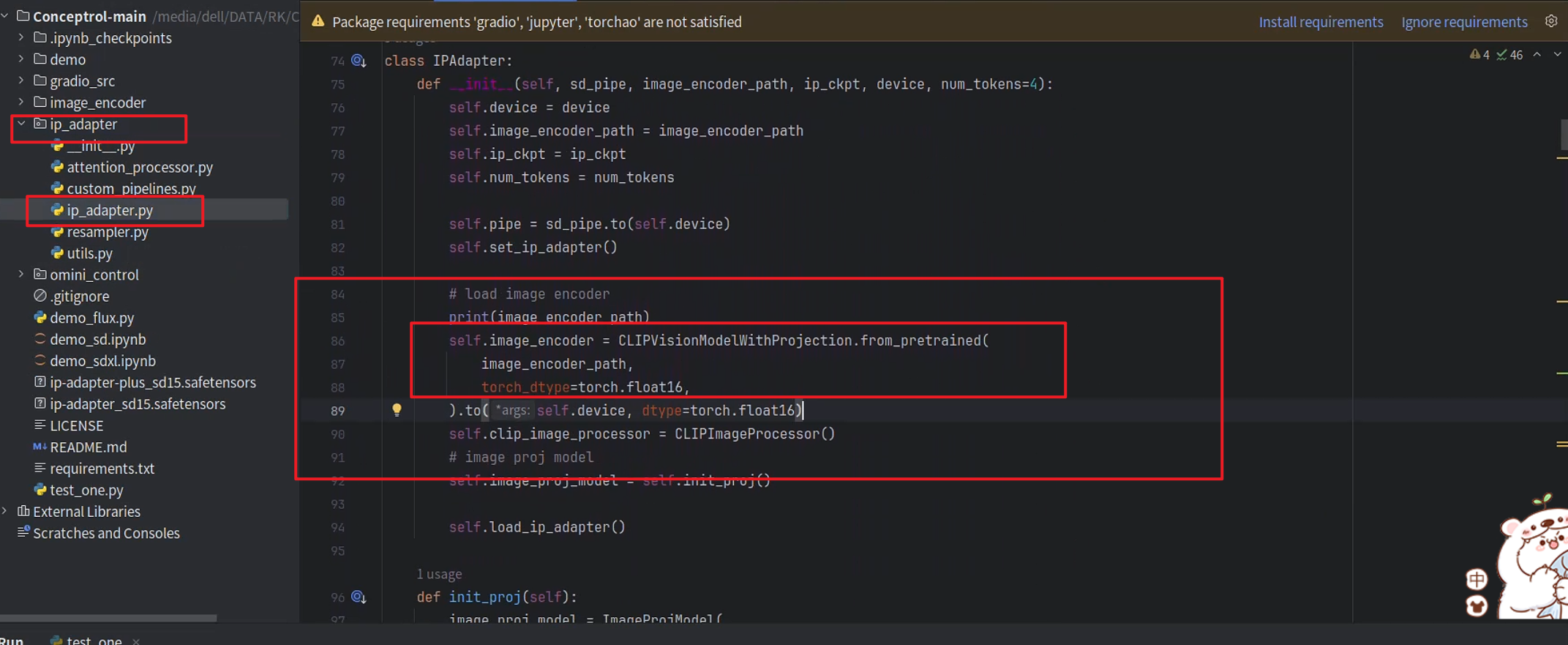
from PIL import Image
import torch
from ip_adapter import ConceptrolIPAdapterPlus, IPAdapterPlus
from ip_adapter.custom_pipelines import StableDiffusionCustomPipeline
def image_grid(imgs, rows, cols, res=256):
assert len(imgs) == rows*cols
w, h = imgs[0].size
h_res = int(res * h / w)
grid = Image.new('RGB', size=(cols*res, rows*h_res))
for i, img in enumerate(imgs):
grid.paste(img.resize((res, h_res)), box=(i%cols*res, i//cols*h_res))
return grid
squirrel_image = Image.open("/media/dell/DATA/RK/ComfyUI/input/s0038____1108_01_query_1_img_000160_1683446137098_06380306087744766.jpeg.jpg")
food_image = Image.open("/media/dell/DATA/RK/ComfyUI/input/s0049____1110_01_query_0_img_000019_1684092427918_07281314802461102.jpg.jpg")
image_grid([squirrel_image, food_image], 1, 2)
image_grid([book_image, statue_image], 1, 2)
base_model_path = "/media/dell/DATA/RK/pretrained_model/stable-diffusion-v1-5"
ip_adapter_path = "/media/dell/DATA/RK/Conceptrol-main/ip-adapter-plus_sd15.safetensors"
image_encoder_path = "/media/dell/DATA/RK/Conceptrol-main/image_encoder"
device = "cuda"
pipe = StableDiffusionCustomPipeline.from_pretrained(
base_model_path,
torch_dtype=torch.float16,
feature_extractor=None,
safety_checker=None
)
ip_pipe = IPAdapterPlus(pipe, image_encoder_path, ip_adapter_path, device, num_tokens=16)
prompt = "A squirrel is eating the food in the cafe, best quality, high quality"
negative_prompt = "deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality"
images = [squirrel_image]
concepts = ["a squirrel"]
ip_book = ip_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
images = [food_image]
concepts = ["the food"]
ip_statue = ip_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
images = [squirrel_image, food_image]
concepts = ["a squirrel", "the food"]
ip_compositional = ip_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
print("Left to Right: [Reference of Book, Reference of Statue, Use Book, Use Statue, Use Book and Statue]")
ip_results = image_grid([squirrel_image, food_image, ip_book[0], ip_statue[0], ip_compositional[0]], 1, 5)
ip_results

3.2ipadapter plus sd1.5 plus concept的效果
这里需要再下载一个视觉编码器
openai/clip-vit-base-patch32
然后将图像编码器的路径和tokenizer的路径改为自己下载的位置
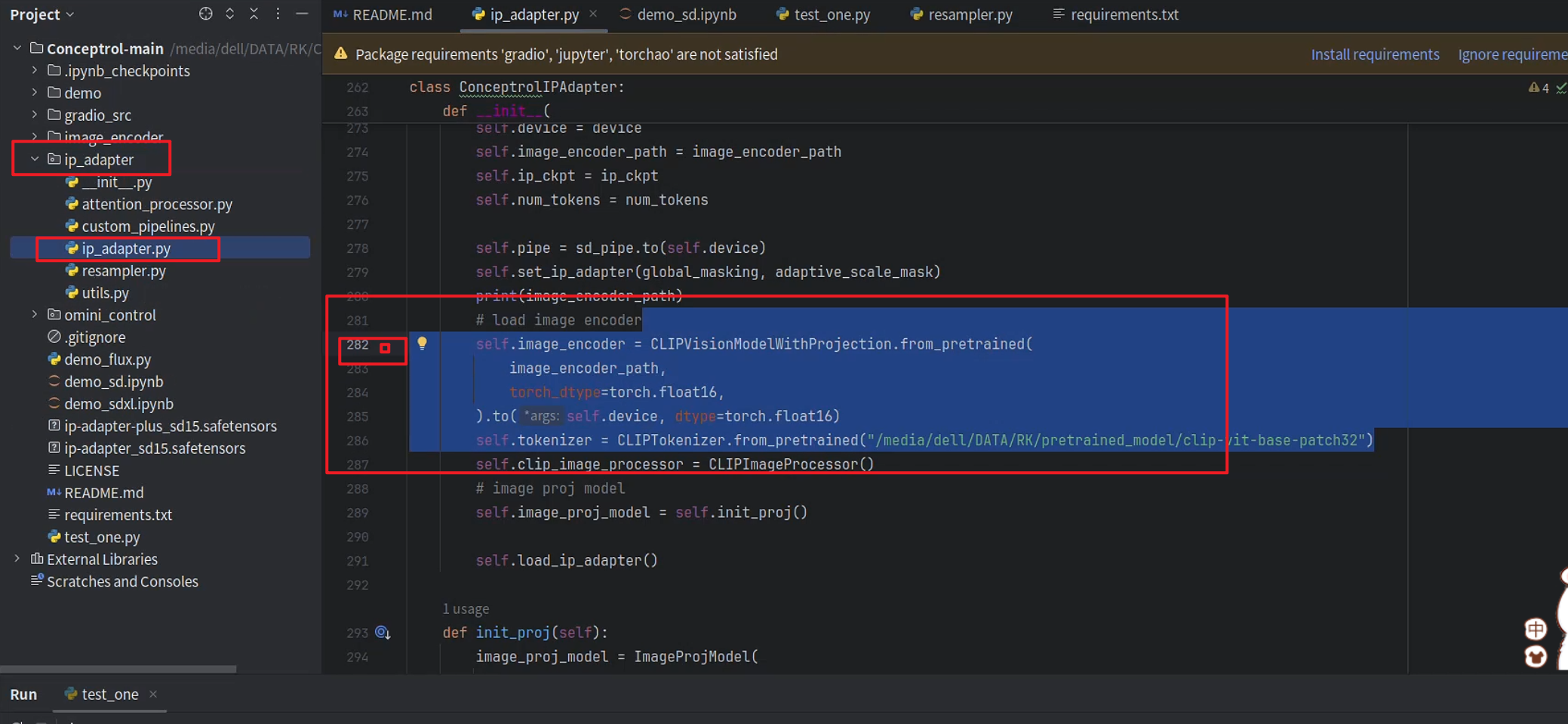
self.image_encoder = CLIPVisionModelWithProjection.from_pretrained(
image_encoder_path,
torch_dtype=torch.float16,
).to(self.device, dtype=torch.float16)
self.tokenizer = CLIPTokenizer.from_pretrained("/media/dell/DATA/RK/pretrained_model/clip-vit-base-patch32")
prompt = "A squirrel is eating the food in the cafe, best quality, high quality"
negative_prompt = "deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality"
images = [squirrel_image]
concepts = ["a squirrel"]
conceptrol_squirrel = conceptrol_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
images = [food_image]
concepts = ["the food"]
conceptrol_food = conceptrol_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
images = [squirrel_image, food_image]
concepts = ["a squirrel", "the food"]
conceptrol_compositional = conceptrol_pipe.generate(prompt=prompt, pil_images=images, subjects=concepts, num_samples=1, num_inference_steps=50,
scale=0.6, negative_prompt=negative_prompt, control_guidance_start=0.0, seed=42)
print("Left to Right: [Reference of Book, Reference of Statue, Use Book, Use Statue, Use Book and Statue]")
conceptrol_results = image_grid([squirrel_image, food_image, conceptrol_squirrel[0], conceptrol_food[0], conceptrol_compositional[0]], 1, 5)
conceptrol_results

3.3两者结果的比较:原本的ipadapter、加了concept的ipadapter

可以看到,加了作者提出的方法,参考图像的特征会专注于各自的个体之中(比如上图的,参考图像中松鼠和食物,可以看到,ipadapter最后一张图混淆了两者的特征,但是本文的方法相对保持了输入的特征)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









