








前言
系列文章目录
[Python]目录
视频及资料和课件
链接:https://pan.baidu.com/s/1LCv_qyWslwB-MYw56fjbDg?pwd=1234
提取码:1234
引入包
import pandas as pd
1. Series() – 创建 Series 对象
【Pandas中Series的属性、方法、常用操作以及使用示例】
2. DataFrame() – 创建 DataFrame 对象
【Pandas中DataFrame的属性、方法、常用操作以及使用示例】
3. read_csv() – 读取 csv 文件
filepath_or_buffer – csv 文件对应的路径
使用 filepath_or_buffer 指定需要打开的 csv 文件的路径。
data = pd.read_csv('./数据文件/距离最小的三个点.csv')
print(data)
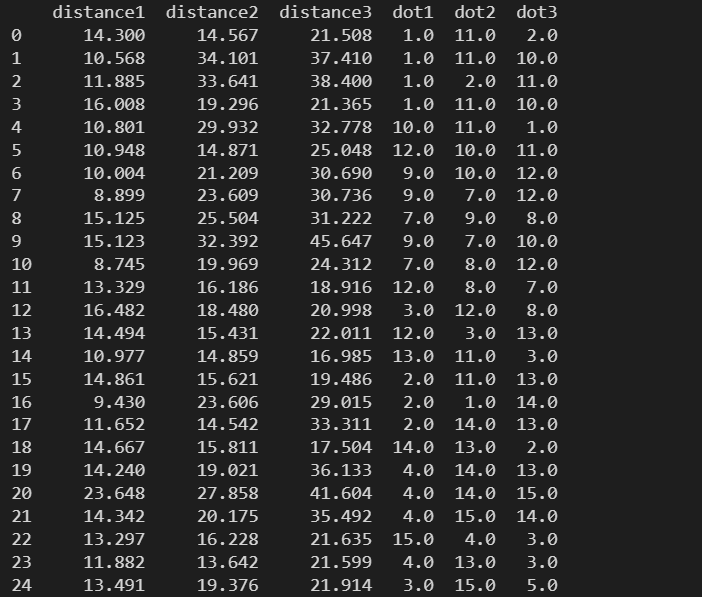
sep – 指定分隔符
csv 文件默认的分隔符为 ,,可以使用 sep 指定数据之间的分隔符
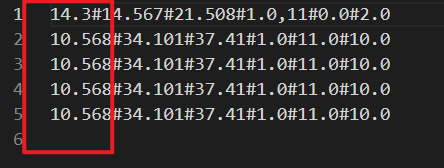
csv文件中的数据:
distance1#distance2#distance3#dot1#dot2#dot3
14.3#14.567#21.508#1.0,11#0,2.0
10.568#34.101#37.41#1.0#11.0#10.0
第二行中2.0前的逗号没有进行修改
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data

header – 指定第几行为列名
使用 header 指定 csv 文件中的第几行数据作为表的列名。默认 header = 0,即表的第一行为列名;header = None 表示不指定表中的数据为列名,用于数据中不存在列名的情况。
data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#'
)
print(data)

data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#',
header=0
)
print(data)
csv文件中的数据:
distance1#distance2#distance3#dot1#dot2#dot3
14.3#14.567#21.508#1.0,11#0#2.0
10.568#34.101#37.41#1.0#11.0#10.0
10.568#34.101#37.41#1.0#11.0#10.0
10.568#34.101#37.41#1.0#11.0#10.0
10.568#34.101#37.41#1.0#11.0#10.0
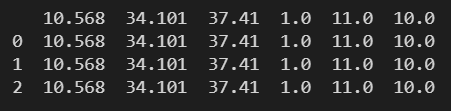
data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#',
header=2
)
print(data)
被指定为列名的行以前的数据都不会出现在数据表中。
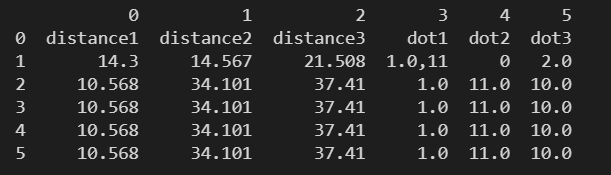
data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#',
header=None
)
print(data)
header=None,如果不指定列名,会自动默认分配一个 0 ~ (n-1) 的数字索引为列名。
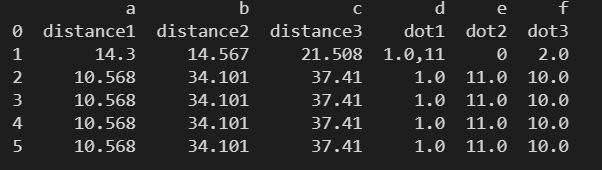
names – 指定列名
使用 names 可以自己指定列名,需要保证自己指定的列名不能存在重复。
data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#',
header=None,
names=['a','b','c','d','e','f']
)
print(data)
注意:
如果自己指定了列名,会覆盖原有的列名。
data = pd.read_csv(
'./数据文件/距离最小的三个点.csv',
sep='#',
header=0,
names=['a','b','c','d','e','f']
)
print(data)
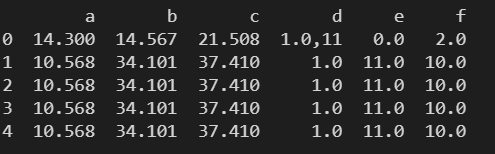
4. read_excel() – 读取 excel 文件
filepath – excel 文件对应的路径
使用 filepath 指定需要打开的 excel 文件的路径。
data = pd.read_excel('./数据文件/信表节点的坐标.xlsx')
print(data)
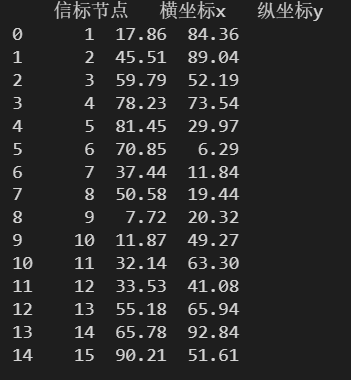
header – 指定第几行为列名
使用 header 指定 excel 文件中的第几行数据作为表的列名。默认 header = 0,即表的第一行为列名;header = None 表示不指定表中的数据为列名,用于数据中不存在列名的情况。
data = pd.read_excel('./数据文件/信表节点的坐标.xlsx')
print(data)
data = pd.read_excel(
'./数据文件/信表节点的坐标.xlsx',
header = 0
)
print(data)
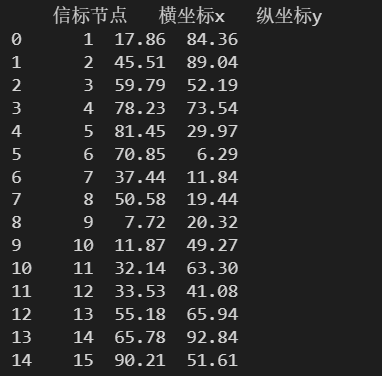
data = pd.read_excel(
'./数据文件/信表节点的坐标.xlsx',
header = 2
)
print(data)
被指定为列名的行以前的数据都不会出现在数据表中。
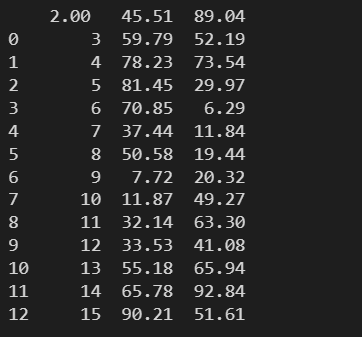
data = pd.read_excel(
'./数据文件/信表节点的坐标.xlsx',
header = None
)
print(data)
header=None,如果不指定列名,会自动默认分配一个 0 ~ (n-1) 的数字索引为列名。
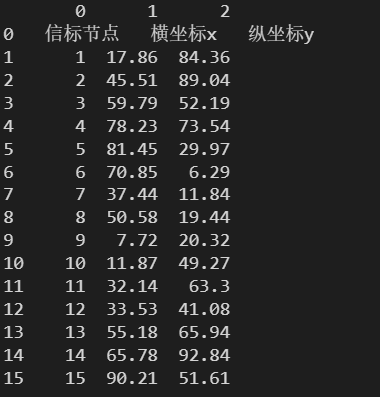
names – 指定列名
使用 names 可以自己指定列名,需要保证自己指定的列名不能存在重复。
data = pd.read_excel(
'./数据文件/信表节点的坐标.xlsx',
header = None,
names = ['a', 'b', 'c']
)
print(data)
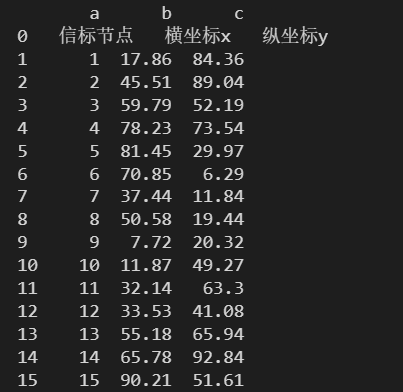
注意:
如果自己指定了列名,会覆盖原有的列名。
data = pd.read_excel(
'./数据文件/信表节点的坐标.xlsx',
header = 0,
names = ['a', 'b', 'c']
)
print(data)
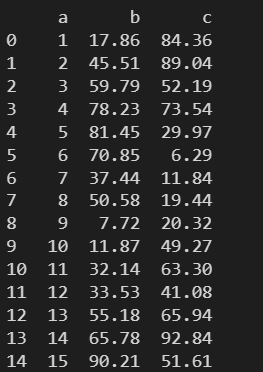
5. to_csv() – 导出数据到 csv 格式的文件中
to_csv() 将 DataFrame 对象中的数据导出数据到 csv 格式的文件中。
path_ro_buf – 导出到的文件的路径
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_csv('./数据文件/data1.csv')
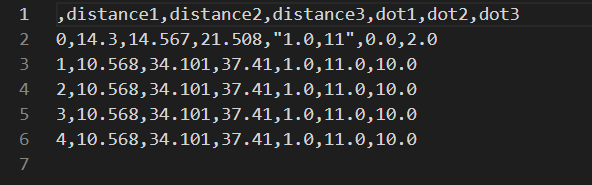
sep – 指定分隔符
csv 文件的数据分隔符默认为 ,,可以使用 sep 进行修改。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_csv(
'./数据文件/data1.csv',
sep='#'
)
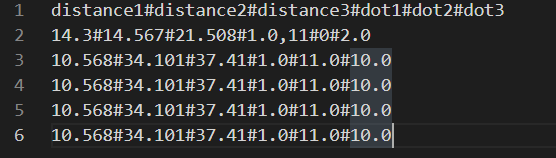
header – 是否保留列名
默认取值为 True,即保留列名。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_csv(
'./数据文件/data1.csv',
sep='#',
header = False
)
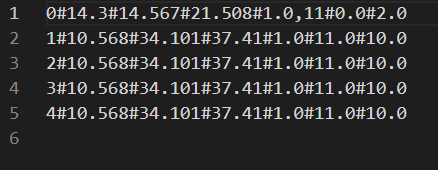
index – 是否保留行索引
默认取值为 True,即保留行索引。
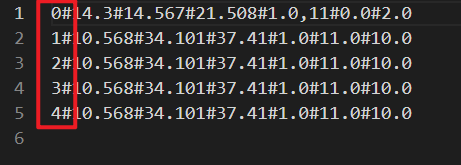
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_csv(
'./数据文件/data1.csv',
sep='#',
header = False,
index=False
)
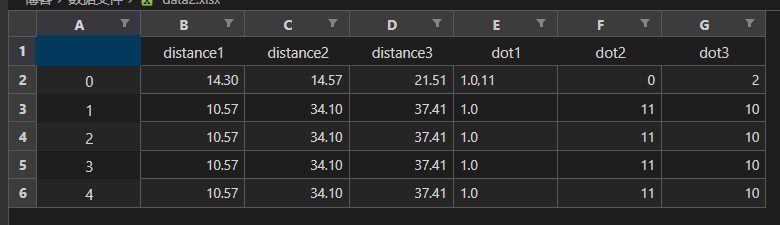
6. to_excel() – 导出数据到 excel 格式的文件中
to_excel() 将 DataFrame 对象中的数据导出数据到 excel 格式的文件中。
excel_writer – 导出到的文件的路径
使用 excel_writer 指定导出到的文件的路径。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_excel('./数据文件/data2.xlsx')
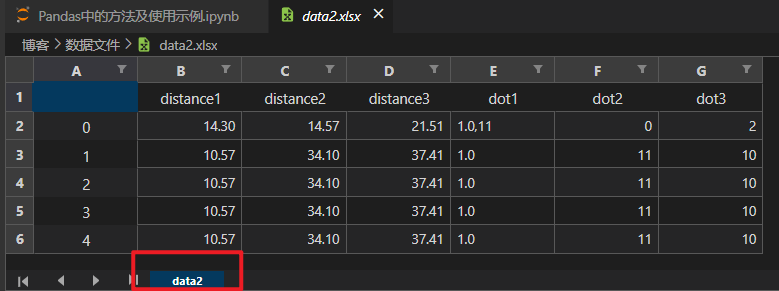
sheet_name – 指定表名
使用 sheet_name 指定 excel 表格的表名。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_excel(
'./数据文件/data2.xlsx',
sheet_name='data2'
)
header – 是否保留列名
默认取值为 True,即保留列名。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_excel(
'./数据文件/data2.xlsx',
sheet_name='data2',
header=False
)
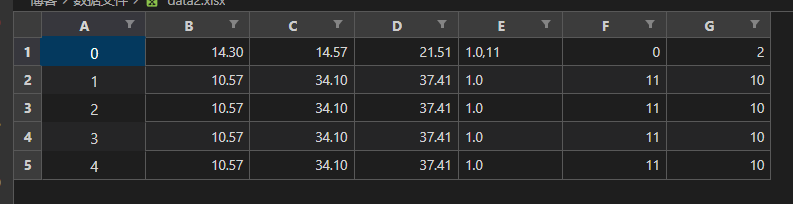
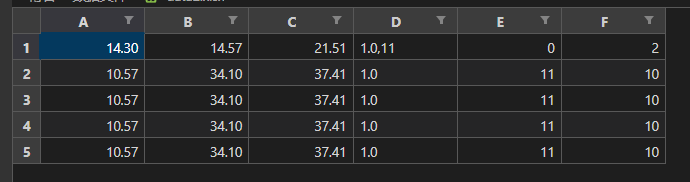
index – 是否保留行索引
默认取值为 True,即保留行索引。
data = pd.read_csv('./数据文件/距离最小的三个点.csv', sep='#')
print(data)
data.to_excel(
'./数据文件/data2.xlsx',
sheet_name='data2',
header=False,
index=False
)
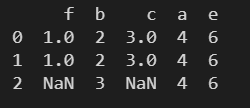
7. merge() – 表格的连接
left、right – 指定左表右表
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([4, 3, 6], index=['a', 'b', 'e']),
pd.Series([4, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(pd.merge(df1, df2))
两个表中都 b 列,根据 b 列进行内连接。连接后重复列保留一个

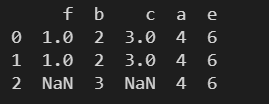
how – 连接方式
使用 how 指定连接方式。
- left:左连接
- right:右连接
- outer:外连接
- inner:内连接(默认)
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([4, 3, 6], index=['a', 'b', 'e']),
pd.Series([4, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(pd.merge(df1, df2, how='outer'))
on – 指定连接依据的列名
两个表连接时,依据的列的列名相同时,使用 on 指定连接所依据的列名。
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([4, 3, 6], index=['a', 'b', 'e']),
pd.Series([4, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(pd.merge(df1, df2, how='outer', on='b'))
left_on、right_on – 左右表连接时各自依据的列名
- left_on:连接时,左表所依据的列的列名
- right_on:连接时,右表所依据的列的列名
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['a', 'b', 'e']),
pd.Series([1, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(
pd.merge(
df1,
df2,
how='outer',
left_on='f',
right_on='a'
)
)
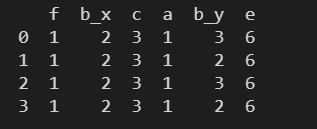
suffixes – 为左右表中重复列名定义后缀
使用 suffixes 为左右表中重复列名定义后缀,使得连接两个表后可以区分相同列名的列来自左表还是右表。
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['a', 'b', 'e']),
pd.Series([1, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(
pd.merge(
df1,
df2,
how='outer',
left_on='f',
right_on='a',
suffixes=('1', '2')
)
)

8. concat() – 表格的拼接
concat() 一般用于表格的纵向拼接。
axis – 拼接的方向
- axis = 0:纵向拼接表(默认)
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['a', 'b', 'e']),
pd.Series([1, 2, 6], index=['a', 'b', 'e'])
]
df2 = pd.DataFrame(l2)
print(
pd.concat([df1, df2])
)
列索引不一致
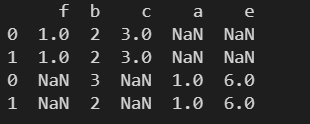
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['f', 'b', 'c']),
pd.Series([1, 2, 6], index=['f', 'b', 'c'])
]
df2 = pd.DataFrame(l2)
print(
pd.concat([df1, df2])
)
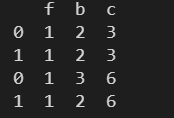
- axis = 1:横向拼接表
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['f', 'b', 'c']),
pd.Series([1, 2, 6], index=['f', 'b', 'c'])
]
df2 = pd.DataFrame(l2)
print(
pd.concat([df1, df2], axis=1)
)
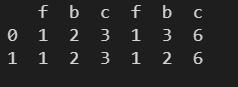
l1 = [
pd.Series([1, 2, 3], index=['f', 'b', 'c']),
pd.Series([1, 2, 3], index=['f', 'b', 'c'])
]
df1 = pd.DataFrame(l1)
l2 = [
pd.Series([1, 3, 6], index=['f', 'b', 'c']),
pd.Series([1, 2, 6], index=['f', 'b', 'c'])
]
df2 = pd.DataFrame(l2)
df2.index = [2,3]
print(
pd.concat([df1, df2], axis=1)
)
行索引不一致
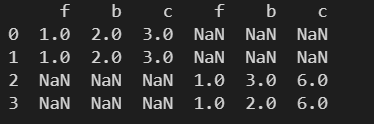
9. get_dummies() – 对离散数据进行独热编码
对表中的取值为离散数据的列进行独热编码,将离散类型的信息转化为使用独热编码进行表示的形式。
data – 需要进行处理的表
l1 = [
pd.Series(['a', 12], index=['f', 'g']),
pd.Series(['b', 11], index=['f', 'g']),
pd.Series(['a', 12], index=['f', 'g'])
]
df1 = pd.DataFrame(l1)
print(
pd.get_dummies(df1)
)
f 列中的数据为离散型的数据,可以使用 get_dummies() 对该列进行独热编码。
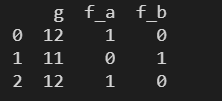
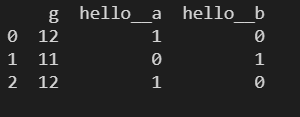
prefix – 设置列名的前缀
使用 prefix 设置进行独热编码的列的列名的前缀,默认值为 None
l1 = [
pd.Series(['a', 12], index=['f', 'g']),
pd.Series(['b', 11], index=['f', 'g']),
pd.Series(['a', 12], index=['f', 'g'])
]
df1 = pd.DataFrame(l1)
print(
pd.get_dummies(df1, prefix='hello_')
)














 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









