








回归分析预测简介与适用场景
回归分析预测是在分析自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型.
适用场景:样本数量较少,自变量与因变量间的变化具有明显的逻辑关系.
视频链接
参考书籍
- 线性模型的理论及其应用
- 近代回归分析
- SPSS统计分析大全
- 试验设计与数据分析
线性回归模型的分类
- 简单(一元)线性回归(一个自变量)
- 多重(多元)线性回归(多个自变量)
线性回归的前提条件
- 线性:通过 绘制散点图观察自变量与因变量之间是否具有线性关系 .
- 独立性
- 正态性:建立的模型会有一个随机项(随机因素,误差e),随机项会将模型假设为正态分布.
(由于随机因素,结果呈现正态性) - 方差性分析
相关关系:
自变量的取值一定时,因变量的取值带有一定的随机项的两个变量之间的关系.
相关关系是一种非确定关系.
对具有相关关系的两个变量进行统计分析的方法叫回归分析.
线性回归的经验回归方程
X: 自变量或者预报变量
Y: 因变量或者响应变量
Y的值由 X能够决定的部分f(X) 以及 其他未考虑的因素e (要求e的均值为0,整体的误差在0附近) 组成,得到如下模型:
Y
=
f
(
X
)
+
e
,
E
(
e
)
=
0
Y=f(X)+e, \quad E(e)=0
Y=f(X)+e,E(e)=0
Y=f(X)+e, \quad E(e)=0
一元线性回归模型的建立
线性回归模型: 线性函数加一个误差.
(1)确定模型
当
f
(
X
)
=
β
0
+
β
1
X
f(X)=\beta_{0}+\beta_{1} X
f(X)=β0+β1X 为一元线性函数时, 一元线性回归的经验回归方程为
Y
=
β
0
+
β
1
X
+
e
Y=\beta_{0}+\beta_{1} X+e
Y=β0+β1X+e .
其中,常数项
β
0
\beta_{0}
β0 是直线的截距,
β
1
\beta_{1}
β1 是直线的斜率,
β
0
\beta_{0}
β0 和
β
1
\beta_{1}
β1 都称为回归系数,随机因素
e
e
e 满足
E
(
e
)
=
0
E(e)=0
E(e)=0 .
Y称为线性回归模型或线性回归方程.
f(X)=\beta_{0}+\beta_{1} X
Y=\beta_{0}+\beta_{1} X+e
\beta_{0}
\beta_{1}
e
E(e)=0
(2)观测数据
假设有n组数据
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi) ,如果Y与X满足回归系数时,则
(
x
i
,
y
i
)
(x_{i}, y_{i})
(xi,yi) 满足
y
i
=
β
0
+
β
1
x
i
+
e
i
,
i
=
1
,
…
,
n
y_{i}=\beta_{0}+\beta_{1} x_{i}+e_{i}, \quad i=1, \ldots, n
yi=β0+β1xi+ei,i=1,…,n,
其中,每组数据的误差
e
i
e_{i}
ei不一样.
(x_{i}, y_{i})
y_{i}=\beta_{0}+\beta_{1} x_{i}+e_{i}, \quad i=1, \ldots, n
e_{i}
(3)确定未知参数估计值
根据 (2) 得到的方程组,应用统计方法,可以得到 β 0 \beta_{0} β0 和 β 1 \beta_{1} β1 的估计值 β 0 ^ \hat{\beta_{0}} β0^ 和 β 1 ^ \hat{\beta_{1}} β1^ .
未知参数估计值 β 0 ^ \hat{\beta_{0}} β0^ 和 β 1 ^ \hat{\beta_{1}} β1^ 的求解采用最小二乘法.
\beta_{0}
\beta_{1}
\hat{\beta_{0}}
\hat{\beta_{1}}
最小二乘法
找参数
β
\beta
β 的估计,使得偏差向量
e
=
y
−
X
β
e=y-X \boldsymbol{\beta}
e=y−Xβ 的长度平方
∥
y
−
X
β
∥
2
\|y-X \beta\|^{2}
∥y−Xβ∥2 最小.
令
Q
(
β
)
=
∥
e
∥
2
=
∥
y
−
X
β
∥
2
=
(
y
−
X
β
)
′
(
y
−
X
β
)
Q(\beta)=\|e\|^{2}=\|y-X \beta\|^{2}=(y-X \beta)^{\prime}(y-X \beta)
Q(β)=∥e∥2=∥y−Xβ∥2=(y−Xβ)′(y−Xβ) .
将上式展开,对
β
\beta
β 求偏导数,另其取值为0,得到线性方程组(正则方程):
X
′
X
β
=
X
′
y
X^{\prime} X \beta=X^{\prime} y
X′Xβ=X′y
X
′
X
X^{\prime} X
X′X 的秩为p,则这个线性方程组的唯一解为:
β
^
=
(
X
′
X
)
−
1
X
′
y
\hat{\beta}=\left(X^{\prime} X\right)^{-1} X^{\prime} y
β^=(X′X)−1X′y
记
β
^
=
(
β
^
0
,
β
^
1
)
′
\hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}\right)^{\prime}
β^=(β^0,β^1)′ ,并带入
Y
=
β
0
+
β
1
X
1
+
e
Y=\beta_{0}+\beta_{1} X_{1}+e
Y=β0+β1X1+e .
去除误差项
e
e
e ,得到
Y
^
=
β
^
0
+
β
^
1
X
1
\hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}
Y^=β^0+β^1X1
上述方程还要进一步做统计分析,确定是否描述了因变量与自变量的真实关系.
\beta
e=y-X \boldsymbol{\beta}
\|y-X \beta\|^{2}
Q(\beta)=\|e\|^{2}=\|y-X \beta\|^{2}=(y-X \beta)^{\prime}(y-X \beta)
X^{\prime} X \beta=X^{\prime} y
X^{\prime} X
\hat{\beta}=\left(X^{\prime} X\right)^{-1} X^{\prime} y
\hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}\right)^{\prime}
Y=\beta_{0}+\beta_{1} X_{1}+e
e
\hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}
(4)求经验回归方程
将 (3) 求得的未知参数估计值
β
0
^
\hat{\beta_{0}}
β0^ 和
β
1
^
\hat{\beta_{1}}
β1^ 带入线性回归模型,略去误差项,得
y
i
=
β
0
^
+
β
1
^
X
y_{i}=\hat{\beta_{0}}+\hat{\beta_{1}} X
yi=β0^+β1^X
\hat{\beta_{0}}
\hat{\beta_{1}}
y_{i}=\hat{\beta_{0}}+\hat{\beta_{1}} X
多元线性回归模型的建立
模型建立流程:
(1)确定模型
多元线性回归模型的一般形式为:
Y
=
β
0
+
β
1
X
1
+
⋯
+
β
p
−
1
X
p
−
1
+
e
Y=\beta_{0}+\beta_{1} X_{1}+\cdots+\beta_{p-1} X_{p-1}+e
Y=β0+β1X1+⋯+βp−1Xp−1+e
其中,
β
0
\beta_{0}
β0 为常数项,
β
1
,
⋯
,
β
p
−
1
\beta_{1}, \cdots, \beta_{p-1}
β1,⋯,βp−1 为回归系数,
e
e
e 为随机误差.
Y=\beta_{0}+\beta_{1} X_{1}+\cdots+\beta_{p-1} X_{p-1}+e
\beta_{0}
\beta_{1}, \cdots, \beta_{p-1}
e
(2)观测数据
假设对
Y
,
X
1
,
⋯
,
X
p
−
1
Y, X_{1}, \cdots , X_{p-1}
Y,X1,⋯,Xp−1 得到了n组观测值,
y
i
,
x
i
1
,
⋯
,
x
i
,
p
−
1
,
i
=
1
,
2
,
⋯
,
n
y_{i}, x_{i 1}, \cdots, x_{i, p-1}, i=1,2, \cdots, n
yi,xi1,⋯,xi,p−1,i=1,2,⋯,n 满足
y
i
=
β
0
+
x
i
1
β
1
+
⋯
+
x
i
,
p
−
1
β
p
−
1
+
e
i
,
i
=
1
,
2
,
⋯
,
n
y_{i}=\beta_{0}+x_{i 1} \beta_{1}+\cdots+x_{i, p-1} \beta_{p-1}+e_{i}, i=1,2, \cdots, n
yi=β0+xi1β1+⋯+xi,p−1βp−1+ei,i=1,2,⋯,n ,
其中,
e
i
e_{i}
ei 为随机误差.
为了方便,我们通过n组实际观察数据而引入矩阵记号
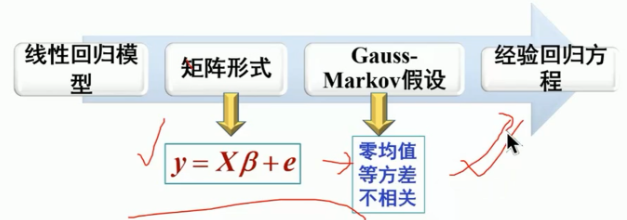
多元线性回归的矩阵形式:
y
=
X
β
+
e
,
y=X \beta+e,
y=Xβ+e,
其中,
y
=
[
y
1
y
2
⋮
y
n
]
,
X
=
[
1
x
11
⋯
x
1
,
p
−
1
1
x
21
⋯
x
2
,
p
−
1
⋮
⋮
⋮
⋮
1
x
n
1
⋯
x
n
,
p
−
1
]
,
β
=
[
β
0
β
1
⋮
β
p
−
1
]
,
e
=
[
e
1
e
2
⋮
e
n
]
\boldsymbol{y}=\left[\begin{array}{c} y_{1} \\ y_{2} \\ \vdots \\ y_{n} \end{array}\right], \boldsymbol{X}=\left[\begin{array}{cccc} 1 & x_{11} & \cdots & x_{1, p-1} \\ 1 & x_{21} & \cdots & x_{2, p-1} \\ \vdots & \vdots & \vdots & \vdots \\ 1 & x_{n 1} & \cdots & x_{n, p-1} \end{array}\right], \boldsymbol{\beta}=\left[\begin{array}{c} \beta_{0} \\ \beta_{1} \\ \vdots \\ \beta_{p-1} \end{array}\right], \boldsymbol{e}=\left[\begin{array}{c} e_{1} \\ e_{2} \\ \vdots \\ e_{n} \end{array}\right]
y=⎣
⎡y1y2⋮yn⎦
⎤,X=⎣
⎡11⋮1x11x21⋮xn1⋯⋯⋮⋯x1,p−1x2,p−1⋮xn,p−1⎦
⎤,β=⎣
⎡β0β1⋮βp−1⎦
⎤,e=⎣
⎡e1e2⋮en⎦
⎤
y为观测向量,X为已知矩阵(称为 设计矩阵 ),
β
\beta
β 为未知参数向量,
e
e
e 为随机误差向量.(要对变量进行备注说明)
Y, X_{1}, \cdots , X_{p-1}
y_{i}, x_{i 1}, \cdots, x_{i, p-1}, i=1,2, \cdots, n
y_{i}=\beta_{0}+x_{i 1} \beta_{1}+\cdots+x_{i, p-1} \beta_{p-1}+e_{i}, i=1,2, \cdots, n
e_{i}
y=X \beta+e,
\boldsymbol{y}=\left[\begin{array}{c}
y_{1} \\
y_{2} \\
\vdots \\
y_{n}
\end{array}\right], \boldsymbol{X}=\left[\begin{array}{cccc}
1 & x_{11} & \cdots & x_{1, p-1} \\
1 & x_{21} & \cdots & x_{2, p-1} \\
\vdots & \vdots & \vdots & \vdots \\
1 & x_{n 1} & \cdots & x_{n, p-1}
\end{array}\right], \boldsymbol{\beta}=\left[\begin{array}{c}
\beta_{0} \\
\beta_{1} \\
\vdots \\
\beta_{p-1}
\end{array}\right], \boldsymbol{e}=\left[\begin{array}{c}
e_{1} \\
e_{2} \\
\vdots \\
e_{n}
\end{array}\right]
(3)Guass-Markov假设:
误差项 e e e 的常用假设:
- 零均值:
E
(
e
i
)
=
0
,
i
=
1
,
2
,
⋯
,
n
E\left(e_{i}\right)=0, i=1,2, \cdots, n
E(ei)=0,i=1,2,⋯,n
- 说明观测值大于或小于均值完全是随机性的
- 等方差:
Var
(
e
i
)
=
σ
2
,
i
=
1
,
2
,
⋯
,
n
\operatorname{Var}\left(e_{i}\right)=\sigma^{2}, i=1,2, \cdots, n
Var(ei)=σ2,i=1,2,⋯,n
- 说明不同次的观测在均值附近的波动的程度是一样的
- 不相关:
Cov
(
e
i
,
e
j
)
=
0
,
i
≠
j
,
i
,
j
=
1
,
2
,
⋯
,
n
\operatorname{Cov}\left(e_{i}, e_{j}\right)=0, i \neq j, i, j=1,2, \cdots, n
Cov(ei,ej)=0,i=j,i,j=1,2,⋯,n
- 说明不同次的观测是不相关的.
E\left(e_{i}\right)=0, i=1,2, \cdots, n
\operatorname{Var}\left(e_{i}\right)=\sigma^{2}, i=1,2, \cdots, n
\operatorname{Cov}\left(e_{i}, e_{j}\right)=0, i \neq j, i, j=1,2, \cdots, n
(4)确定回归系数
最小二乘法
散点图呈现出线性关系,可以用最小二乘法估计线性回归方程
线性关系指的是两个变量之间存在一次方函数关系
找参数
β
\beta
β 的估计,使得偏差向量
e
=
y
−
X
β
e=y-X \boldsymbol{\beta}
e=y−Xβ 的长度平方
∥
y
−
X
β
∥
2
\|y-X \beta\|^{2}
∥y−Xβ∥2 最小.
Q
(
β
)
=
∥
e
∥
2
=
∥
y
−
X
β
∥
2
=
(
y
−
X
β
)
′
(
y
−
X
β
)
Q(\beta)=\|e\|^{2}=\|y-X \beta\|^{2}=(y-X \beta)^{\prime}(y-X \beta)
Q(β)=∥e∥2=∥y−Xβ∥2=(y−Xβ)′(y−Xβ)
上式展开,对
β
\beta
β求偏导数,另其为0,得到线性方程组(正则方程):
X
′
X
β
=
X
′
y
X^{\prime} X \beta=X^{\prime} y
X′Xβ=X′y
X
′
X
X^{\prime} X
X′X的秩为p,则这个线性方程组的唯一解
β
^
=
(
X
′
X
)
−
1
X
′
y
\hat{\beta}=\left(X^{\prime} X\right)^{-1} X^{\prime} y
β^=(X′X)−1X′y
记 β ^ = ( β ^ 0 , β ^ 1 , ⋯ , β ^ p − 1 ) ′ \hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \cdots, \hat{\beta}_{p-1}\right)^{\prime} β^=(β^0,β^1,⋯,β^p−1)′ 并带入 Y = β 0 + β 1 X 1 + ⋯ + β p − 1 X p − 1 + e . Y=\beta_{0}+\beta_{1} X_{1}+\cdots+\beta_{p-1} X_{p-1}+e . Y=β0+β1X1+⋯+βp−1Xp−1+e.
去除误差项,得到
Y
^
=
β
^
0
+
β
^
1
X
1
+
⋯
+
β
^
p
−
1
X
p
−
1
\hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1}
Y^=β^0+β^1X1+⋯+β^p−1Xp−1
上述方程还要进一步做统计分析,确定是否描述了因变量与自变量的真实关系.
\beta
e=y-X \boldsymbol{\beta}
\|y-X \beta\|^{2}
Q(\beta)=\|e\|^{2}=\|y-X \beta\|^{2}=(y-X \beta)^{\prime}(y-X \beta)
\beta
X^{\prime} X \beta=X^{\prime} y
X^{\prime} X
\hat{\beta}=\left(X^{\prime} X\right)^{-1} X^{\prime} y
\hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \cdots, \hat{\beta}_{p-1}\right)^{\prime} Y=\beta_{0}+\beta_{1} X_{1}+\cdots+\beta_{p-1} X_{p-1}+e .
\hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1}
(5)求经验回归方程
假设
β
^
=
(
β
^
0
,
β
^
1
,
⋯
,
β
^
p
−
1
)
′
\hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \cdots, \hat{\beta}_{p-1}\right)^{\prime}
β^=(β^0,β^1,⋯,β^p−1)′ 为
β
\beta
β 的一种估计,则经验回归方程为
Y
=
β
^
0
+
β
^
1
X
1
+
⋯
+
β
^
p
−
1
X
p
−
1
Y=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1}
Y=β^0+β^1X1+⋯+β^p−1Xp−1
经验:说明回归方程是基于前面的n次观测数据得到的
\hat{\beta}=\left(\hat{\beta}_{0}, \hat{\beta}_{1}, \cdots, \hat{\beta}_{p-1}\right)^{\prime}
\beta
Y=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1}
非线性模型
线性模型用到非线性情况下,可以通过变换函数,变化之后再绘制散点图,观察是否具有线性关系.
一些非线性模型可以适当变换转为线性模型

原始数据处理
原始数据中心化
每个回归自变量减去它们的平均值,称为中心化.
原模型:
y
i
=
β
0
+
x
i
1
β
1
+
⋯
+
x
i
,
p
−
1
β
p
−
1
+
e
i
,
i
=
1
,
2
,
⋯
,
n
y_{i}=\beta_{0}+x_{i 1} \beta_{1}+\cdots+x_{i, p-1} \beta_{p-1}+e_{i}, i=1,2, \cdots, n
yi=β0+xi1β1+⋯+xi,p−1βp−1+ei,i=1,2,⋯,n
改写为:
y
i
=
α
+
(
x
i
1
−
x
ˉ
1
)
β
1
+
⋯
+
(
x
i
,
p
−
1
−
x
ˉ
p
−
1
)
β
p
−
1
+
e
i
,
i
=
1
,
⋯
,
n
y_{i}=\alpha+\left(x_{i 1}-\bar{x}_{1}\right) \beta_{1}+\cdots+\left(x_{i, p-1}-\bar{x}_{p-1}\right) \beta_{p-1}+e_{i}, i=1, \cdots, n
yi=α+(xi1−xˉ1)β1+⋯+(xi,p−1−xˉp−1)βp−1+ei,i=1,⋯,n
其中, α = β 0 + x ˉ 1 β 1 + ⋯ + x ˉ p − 1 β p − 1 \alpha=\beta_{0}+\bar{x}_{1} \beta_{1}+\cdots+\bar{x}_{p-1} \beta_{p-1} α=β0+xˉ1β1+⋯+xˉp−1βp−1 , x ˉ j = 1 n ∑ i = 1 n x i j \bar{x}_{j}=\frac{1}{n} \sum_{i=1}^{n} {x}_{i j} xˉj=n1∑i=1nxij
记
X
c
=
[
x
11
−
x
ˉ
1
x
12
−
x
ˉ
2
⋯
x
1
,
p
−
1
−
x
ˉ
p
−
1
x
21
−
x
ˉ
1
x
22
−
x
ˉ
2
⋯
x
2
,
p
−
1
−
x
ˉ
p
−
1
⋮
⋮
⋮
x
n
1
−
x
ˉ
1
x
n
2
−
x
ˉ
2
⋯
x
n
,
p
−
1
−
x
ˉ
p
−
1
]
\boldsymbol{X}_{c}=\left[\begin{array}{cccc} x_{11}-\bar{x}_{1} & x_{12}-\bar{x}_{2} & \cdots & x_{1, p-1}-\bar{x}_{p-1} \\ x_{21}-\bar{x}_{1} & x_{22}-\bar{x}_{2} & \cdots & x_{2, p-1}-\bar{x}_{p-1} \\ \vdots & \vdots & & \vdots \\ x_{n 1}-\bar{x}_{1} & x_{n 2}-\bar{x}_{2} & \cdots & x_{n, p-1}-\bar{x}_{p-1} \end{array}\right]
Xc=⎣
⎡x11−xˉ1x21−xˉ1⋮xn1−xˉ1x12−xˉ2x22−xˉ2⋮xn2−xˉ2⋯⋯⋯x1,p−1−xˉp−1x2,p−1−xˉp−1⋮xn,p−1−xˉp−1⎦
⎤
模型的矩阵形式:
y
=
α
1
n
+
X
c
β
+
e
y=\alpha \mathbf{1}_{n}+X_{c} \beta+e
y=α1n+Xcβ+e
回归系数为:
β
′
=
(
α
,
β
1
,
⋯
,
β
p
−
1
)
\beta^{\prime}=\left(\alpha, \beta_{1}, \cdots, \beta_{p-1}\right)
β′=(α,β1,⋯,βp−1)
设计矩阵:
X
c
X_{c}
Xc
X
c
X_{c}
Xc的每个列向量的元素和为0
1
′
X
c
=
0
X
c
′
1
=
0
\begin{array}{l} 1^{\prime} X_{c}={0} \\ X_{c}^{\prime} 1=0 \end{array}
1′Xc=0Xc′1=0
正则方程变形为:
[
n
0
0
X
c
′
X
c
]
[
α
β
]
=
[
1
n
′
y
X
c
′
y
]
\left[\begin{array}{cc} n & 0 \\ 0 & \boldsymbol{X}_{c}^{\prime} \boldsymbol{X}_{c} \end{array}\right]\left[\begin{array}{l} \alpha \\ \beta \end{array}\right]=\left[\begin{array}{l} 1_{n}^{\prime} \boldsymbol{y} \\ \boldsymbol{X}_{c}^{\prime} \boldsymbol{y} \end{array}\right]
[n00Xc′Xc][αβ]=[1n′yXc′y]
回归参数的最小二乘估计:
{
α
^
=
y
ˉ
β
^
=
(
X
c
′
X
c
)
−
1
X
c
′
y
\left\{\begin{array}{l} \hat{\alpha}=\bar{y} \\ \hat{\beta}=\left(\boldsymbol{X}_{c}^{\prime} \boldsymbol{X}_{c}\right)^{-1} \boldsymbol{X}_{c}^{\prime} \boldsymbol{y} \end{array}\right.
{α^=yˉβ^=(Xc′Xc)−1Xc′y
说明:
经过中心化的线性回归模型,回归常数项的最小二乘估计总是等于因变量的观测平均值。
回归系数的最小二乘估计相当于从线性回归模型 y = X c β + e y=X_{c} \beta+e y=Xcβ+e ,按原来的方法计算得到的。
目的,把常数项和回归系数分离开来了 。
y_{i}=\beta_{0}+x_{i 1} \beta_{1}+\cdots+x_{i, p-1} \beta_{p-1}+e_{i}, i=1,2, \cdots, n
y_{i}=\alpha+\left(x_{i 1}-\bar{x}_{1}\right) \beta_{1}+\cdots+\left(x_{i, p-1}-\bar{x}_{p-1}\right) \beta_{p-1}+e_{i}, i=1, \cdots, n
\alpha=\beta_{0}+\bar{x}_{1} \beta_{1}+\cdots+\bar{x}_{p-1} \beta_{p-1} \bar{x}_{j}=\frac{1}{n} \sum_{i=1}^{n} {x}_{i j}
\boldsymbol{X}_{c}=\left[\begin{array}{cccc}
x_{11}-\bar{x}_{1} & x_{12}-\bar{x}_{2} & \cdots & x_{1, p-1}-\bar{x}_{p-1} \\
x_{21}-\bar{x}_{1} & x_{22}-\bar{x}_{2} & \cdots & x_{2, p-1}-\bar{x}_{p-1} \\
\vdots & \vdots & & \vdots \\
x_{n 1}-\bar{x}_{1} & x_{n 2}-\bar{x}_{2} & \cdots & x_{n, p-1}-\bar{x}_{p-1}
\end{array}\right]
y=\alpha \mathbf{1}_{n}+X_{c} \beta+e
\beta^{\prime}=\left(\alpha, \beta_{1}, \cdots, \beta_{p-1}\right)
X_{c}
X_{c}
\begin{array}{l}
1^{\prime} X_{c}={0} \\
X_{c}^{\prime} 1=0
\end{array}
\left[\begin{array}{cc}
n & 0 \\
0 & \boldsymbol{X}_{c}^{\prime} \boldsymbol{X}_{c}
\end{array}\right]\left[\begin{array}{l}
\alpha \\
\beta
\end{array}\right]=\left[\begin{array}{l}
1_{n}^{\prime} \boldsymbol{y} \\
\boldsymbol{X}_{c}^{\prime} \boldsymbol{y}
\end{array}\right]
\left\{\begin{array}{l}
\hat{\alpha}=\bar{y} \\
\hat{\beta}=\left(\boldsymbol{X}_{c}^{\prime} \boldsymbol{X}_{c}\right)^{-1} \boldsymbol{X}_{c}^{\prime} \boldsymbol{y}
\end{array}\right.
原始数据的标准化
记
s
j
2
=
∑
i
=
1
n
(
x
i
j
−
x
ˉ
j
)
2
,
j
=
1
,
⋯
,
p
−
1
s_{j}^{2}=\sum_{i=1}^{n}\left(x_{i j}-\bar{x}_{j}\right)^{2}, j=1, \cdots, p-1
sj2=i=1∑n(xij−xˉj)2,j=1,⋯,p−1
令
z
i
j
=
x
i
j
−
x
ˉ
j
s
j
z_{i j}=\frac{x_{i j}-\bar{x}_{j}}{s_{j}}
zij=sjxij−xˉj(中心化除以
s
j
s_{j}
sj为标准化)
设计矩阵:
Z
=
(
z
i
j
)
Z = (z_{i j})
Z=(zij)
新设计矩阵的性质:
1
′
Z
=
0
R
=
Z
′
Z
=
(
r
i
j
)
.
\begin{array}{l} \mathbf{1}^{\prime} \boldsymbol{Z}=\mathbf{0} \\ \boldsymbol{R}=\boldsymbol{Z}^{\prime} \boldsymbol{Z}=\left(r_{i j}\right) . \end{array}
1′Z=0R=Z′Z=(rij).
r
i
j
=
∑
k
=
1
n
(
x
k
i
−
x
ˉ
i
)
(
x
k
j
−
x
ˉ
j
)
∣
i
s
j
,
i
,
j
=
1
,
⋯
,
p
−
1
r_{i j}=\frac{\sum_{k=1}^{n}\left(x_{k i}-\bar{x}_{i}\right)\left(x_{k j}-\bar{x}_{j}\right)}{\left.\right|_{i} s_{j}}, i, j=1, \cdots, p-1
rij=∣isj∑k=1n(xki−xˉi)(xkj−xˉj),i,j=1,⋯,p−1
R是回归自变量的相关阵
好处:
用R可以分析自变量间的相关关系;
消去了回归自变量单位和取值范围的差异,便于统计分析。
s_{j}^{2}=\sum_{i=1}^{n}\left(x_{i j}-\bar{x}_{j}\right)^{2}, j=1, \cdots, p-1
z_{i j}=\frac{x_{i j}-\bar{x}_{j}}{s_{j}}
Z = (z_{i j})
\begin{array}{l}
\mathbf{1}^{\prime} \boldsymbol{Z}=\mathbf{0} \\
\boldsymbol{R}=\boldsymbol{Z}^{\prime} \boldsymbol{Z}=\left(r_{i j}\right) .
\end{array}
r_{i j}=\frac{\sum_{k=1}^{n}\left(x_{k i}-\bar{x}_{i}\right)\left(x_{k j}-\bar{x}_{j}\right)}{\left.\right|_{i} s_{j}}, i, j=1, \cdots, p-1
经验回归方程:
非中心化:
Y
^
=
β
^
0
+
β
^
1
X
1
+
⋯
+
β
^
p
−
1
X
p
−
1
\begin{array}{l} \hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1} \end{array}
Y^=β^0+β^1X1+⋯+β^p−1Xp−1
中心化:
Y
^
=
γ
^
0
+
β
^
1
(
X
1
−
x
ˉ
1
)
+
⋯
+
β
^
p
−
1
(
X
p
−
1
−
x
ˉ
p
−
1
)
\hat{Y}=\hat{\gamma}_{0}+\hat{\beta}_{1}\left(X_{1}-\bar{x}_{1}\right)+\cdots+\hat{\beta}_{p-1}\left(X_{p-1}-\bar{x}_{p-1}\right)
Y^=γ^0+β^1(X1−xˉ1)+⋯+β^p−1(Xp−1−xˉp−1)
标准化:
Y
^
=
α
^
0
+
(
X
1
−
x
ˉ
1
s
0
)
β
^
1
+
⋯
+
(
X
p
−
1
−
x
ˉ
p
−
1
s
2
)
β
^
p
−
1
\hat{Y}=\hat{\alpha}_{0}+\left(\frac{X_{1}-\bar{x}_{1}}{s_{0}}\right) \hat{\beta}_{1}+\cdots+\left(\frac{X_{p-1}-\bar{x}_{p-1}}{s_{2}}\right) \hat{\beta}_{p-1}
Y^=α^0+(s0X1−xˉ1)β^1+⋯+(s2Xp−1−xˉp−1)β^p−1
\begin{array}{l}
\hat{Y}=\hat{\beta}_{0}+\hat{\beta}_{1} X_{1}+\cdots+\hat{\beta}_{p-1} X_{p-1}
\end{array}
\hat{Y}=\hat{\gamma}_{0}+\hat{\beta}_{1}\left(X_{1}-\bar{x}_{1}\right)+\cdots+\hat{\beta}_{p-1}\left(X_{p-1}-\bar{x}_{p-1}\right)
\hat{Y}=\hat{\alpha}_{0}+\left(\frac{X_{1}-\bar{x}_{1}}{s_{0}}\right) \hat{\beta}_{1}+\cdots+\left(\frac{X_{p-1}-\bar{x}_{p-1}}{s_{2}}\right) \hat{\beta}_{p-1}

模型评价
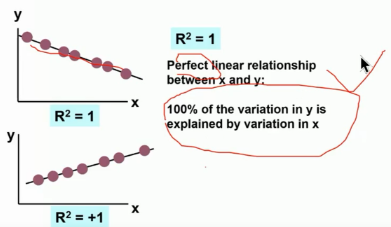
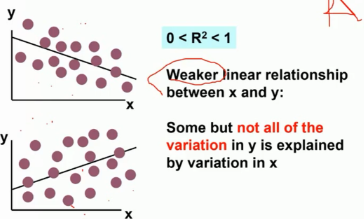
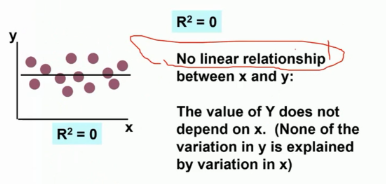
判定系数
R
2
=
S
S
R
S
S
T
,
0
≤
R
2
≤
1
R^{2} = \frac{SSR}{SST}, 0 \le R^{2} \le 1
R2=SSTSSR,0≤R2≤1
R
2
R^{2}
R2 度量了回归自变量
x
1
,
⋯
,
x
p
−
1
x_{1}, \cdots, x_{p-1}
x1,⋯,xp−1 对因变量Y的拟合程度的好坏.
R
2
R^{2}
R2值越大,表明Y与诸X有较大的相依关系.
S
S
T
=
S
S
E
+
S
S
R
SST = SSE + SSR
SST=SSE+SSR
- SST: 总平方和
- S S T = ∑ i = 1 n ( y i − y ˉ ) 2 S S T=\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2} SST=∑i=1n(yi−yˉ)2
- SSE: 残差平方和
- SSR: 回归平方和
R^{2} = \frac{SSR}{SST}, 0 \le R^{2} \le 1
R^{2}
x_{1}, \cdots, x_{p-1}
R^{2}
SST = SSE + SSR
S S T=\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}
假设检验与预测
- 经验回归方程是否真正刻画了因变量与自变量之间的关系?
- 回归方程的显著性检验
- 因变量和所有自变量之间是否存在显著的关系?
- 回归系数的显著性检验
- 异常点检验
回归方程的显著性检验
正态线性回归模型:
y
i
=
β
0
+
x
i
1
β
1
+
⋯
+
x
i
,
p
−
1
β
p
−
1
+
e
i
e
i
∼
N
(
0
,
σ
2
)
,
i
=
1
,
⋯
,
n
\begin{array}{l} y_{i}=\beta_{0}+x_{i 1} \beta_{1}+\cdots+x_{i, p-1} \beta_{p-1}+e_{i} \\ e_{i} \sim N\left(0, \sigma^{2}\right), i=1, \cdots, n \end{array}
yi=β0+xi1β1+⋯+xi,p−1βp−1+eiei∼N(0,σ2),i=1,⋯,n
检验假设:所有回归系数都等于0
H
:
β
1
=
⋯
=
β
p
−
1
=
0
H: \beta_{1} = \cdots= \beta_{p-1} = 0
H:β1=⋯=βp−1=0
拒绝原假设:
则至少一个 β i ≠ 0 \beta_{i} ≠ 0 βi=0 , Y线性依赖于某一个自变量X;也有可能依赖于所有自变量 X 1 , ⋯ , X p − 1 X_{1}, \cdots, X_{p-1} X1,⋯,Xp−1
接受原假设:
则所有 β i = 0 \beta_{i}=0 βi=0,相对误差而言,所有自变量对因变量Y的影响是不重要的。
系数全部为0,没有任何意义
检验回归方程是否存在
p为变量的个数,n为数据的个数
m
=
p
−
1
m = p-1
m=p−1,检验假设
H
:
β
1
=
⋯
=
β
p
−
1
=
0
H: \beta_{1} = \cdots = \beta_{p-1} = 0
H:β1=⋯=βp−1=0
统计量为
F
回
=
S
S
R
/
(
p
−
1
)
R
S
S
/
(
n
−
p
)
F_{\text {回}}=\frac{S S R /(p-1)}{R S S /(n-p)}
F回=RSS/(n−p)SSR/(p−1)
当原假设成立时,
F
回
∼
F
p
−
1
,
n
−
p
F_{\text {回 }} \sim \boldsymbol{F}_{p-1, n-p}
F回 ∼Fp−1,n−p
对给定的水平
α
\alpha
α,
F
回
>
F
p
−
1
,
n
−
p
(
α
)
F_{\text {回 }} > \boldsymbol{F}_{p-1, n-p}(\alpha )
F回 >Fp−1,n−p(α)时,拒绝原假设,否则就接收H.
F
回
F_{\text {回 }}
F回 较大时,拒绝原假设,较小时,接收原假设.
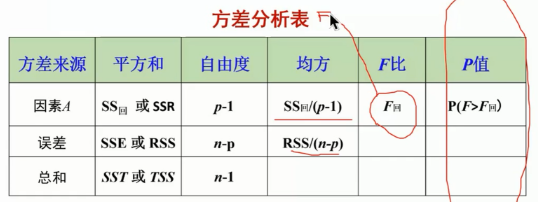
P值越接近0,检验结果越显著,拒绝原假设.(主要看P值)
接收假设
H : β 1 = ⋯ = β p − 1 = 0 H: \beta_{1} = \cdots = \beta_{p-1} = 0 H:β1=⋯=βp−1=0
意味着: 和模型的误差相比,各自变量对Y的影响不重要。
模型误差较大,即使回归自变量有影响,相比较大的模型误差,这种影响也被抵消掉了
(缩小误差: 检查是否漏掉相关自变量; Y对一些回归自变量有非线性相依关系) 回归自变量对Y的影响确实很小
不能建立Y对诸自变量的线性回归
拒接假设
意味着:从整体上看, Y依赖于自变量 X 1 , X 2 , ⋯ , X p − 1 X_{1}, X_{2}, \cdots, X_{p-1} X1,X2,⋯,Xp−1,但是,并不能排除某些自变量的系数 β i \beta_{i} βi为0,即Y不依赖于某些自变量
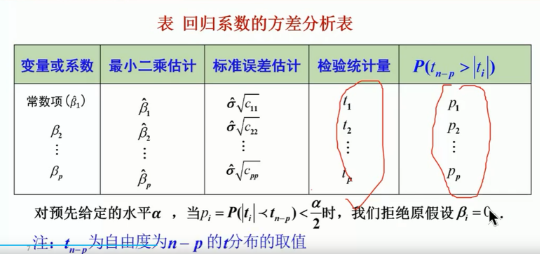
回归系数的显著性检验
H
i
:
β
i
=
0
,
1
≤
i
≤
p
−
1
H_{i}: \beta_{i} = 0, 1 \le i \le p-1
Hi:βi=0,1≤i≤p−1
对固定的 i,
1
≤
i
≤
p
−
1
1 \le i \le p-1
1≤i≤p−1
做如下检验假设
H
i
:
β
i
=
0
H_{i}: \beta_{i} = 0
Hi:βi=0
检验统计量:
t
i
=
β
^
i
σ
^
c
i
i
∼
t
n
−
p
t_{i}=\frac{\hat{\beta}_{i}}{\hat{\sigma} \sqrt{c_{i i}}} \sim t_{n-p}
ti=σ^ciiβ^i∼tn−p
其中,
(
X
′
X
)
−
1
=
(
c
i
j
)
\left(X^{\prime} X\right)^{-1}=\left(c_{i j}\right)
(X′X)−1=(cij),
β
^
i
∼
N
(
β
i
,
σ
2
c
i
i
)
\hat{\beta}_{i} \sim N\left(\beta_{i}, \sigma^{2} c_{i i}\right)
β^i∼N(βi,σ2cii)
t检验统计量就是最小二乘估计与其标准误差估计的商.
异常点检验


复共线性
复共线性: 回归自变量之间存在着近视线性关系.
复共线性对最小二乘估计的影响:
一些大型线性回归问题(自变量较多), 最小二乘估计有时表现不理想
- 有些 回归系数的绝对值异常大
- 回归系数的符号与实际意义相违背
度量复共线性严重程度
方阵 X ′ X X^{\prime} X X′X的条件数: 最大特征值与最小特征值的比值
k = λ 1 λ p k=\frac{\lambda_{1}}{\lambda_{p}} k=λpλ1
最大特征值放在上面
k<100, 认为复共线性很小;
100 ≤ k < 1000, 存在中等程度或较强的复共线性;
k > 1000, 存在严重的复共线性
处理复共线性,具有复共线性的变量去掉其中一个.
方差膨胀因子
方差膨胀因子( Variance Inflation Factor,VIF):
VIF越大,表示共线性越严重。
VIF一般不应该大于5,
当VIF>10时,提示有严重的多重共线性存在
复共线性解决方案
自变量间趋势存在复共线性,直接采用多重回归得到的模型肯定是不可信的,此时可以用下面的办法解决
(1) 增大样本含量,能部分解决复共线性问题。
(2) 把多种自变量筛选的方法绪合起来组成拟合模型。建立一个“最优”的逐步回归方程,迫同时丢失一部分可利用的信息
(3) 从专业知识出发进行判断,去除专业上认为次要的,或者是缺失值比较多、测量误差较大的共线性因子。
(4) 进行主成分分析,提取公因子代替原变量进行回归分析。v
回归诊断(判断假设是否可行)
回归诊断研究的问题:
前边讨论问题:假设模型误差满足Gauss-Markov假设,或服从正态分布
问题1: 我们所考察的实际数据是否满足前边给出误差的假设?
因为从模型误差的假设,所以从分析它们的估计量(残差)的角度来解决称之为残差分析。
问题2: 诊断对统计推断(参数估计和预测)有异常大影响的数据?
考察每组数据对参数估计的影响大小,称之为影响分析。

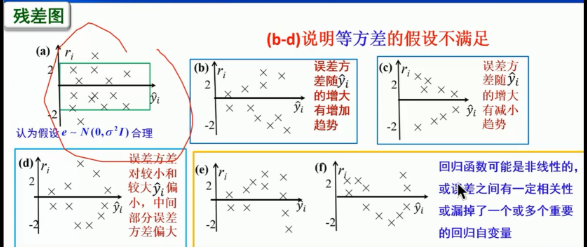
残差一般分布在一定的范围内, 残差具有趋势的不合理
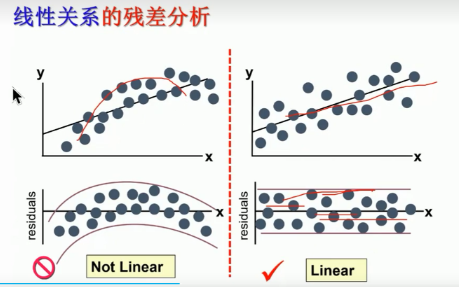
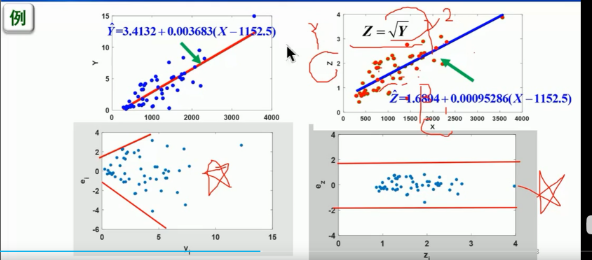
不合理可以变化函数进行尝试(平方,开根号等等)
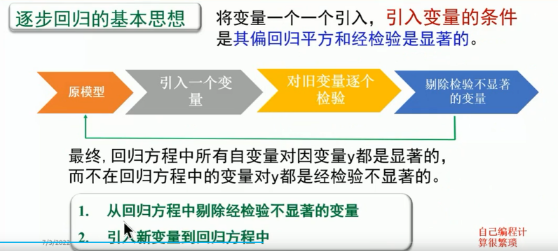
逐步回归




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









