







🌟欢迎来到 我的博客 —— 探索技术的无限可能!
本文使用工具
Anaconda下载安装与使用
Jupyter Notebook的使用
pytorch配置
Jupyter notebook
Pycharm
本文使用数据集
机器学习实验所需内容.zip
pytorch配置
Jupyter notebook
1、打开 Anaconda Prompt(anaconda 3)
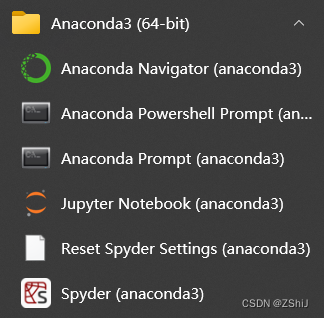
2、在终端输入:conda create -n torch python=3.9
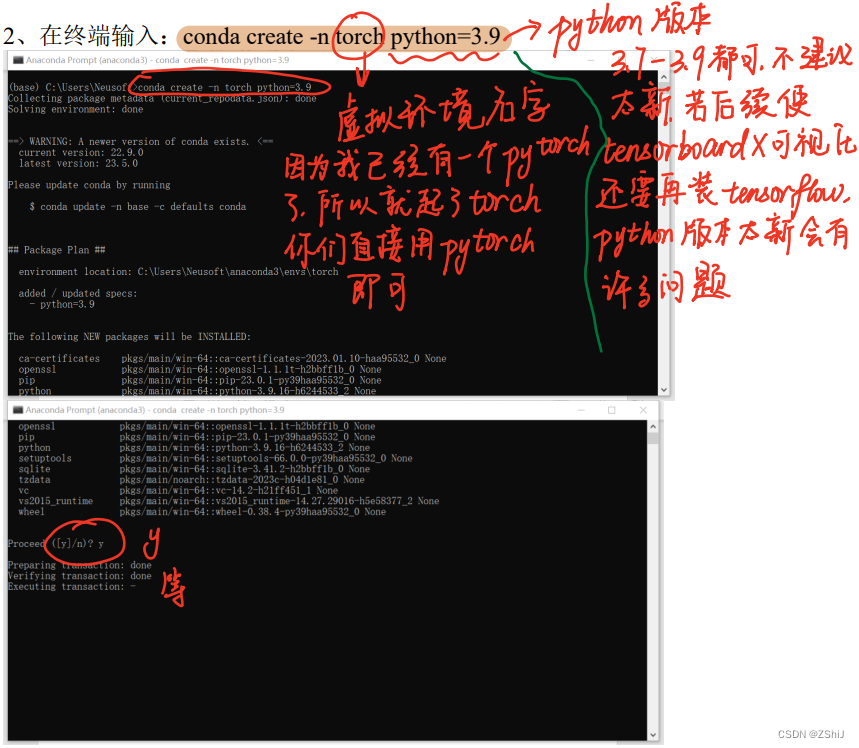
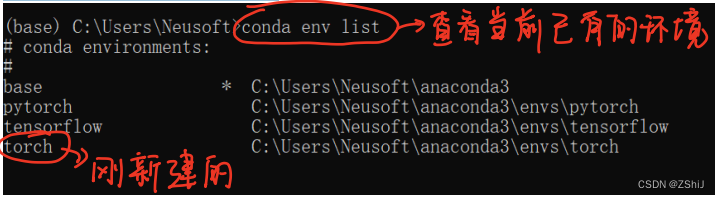
3、查看环境确认创建成功
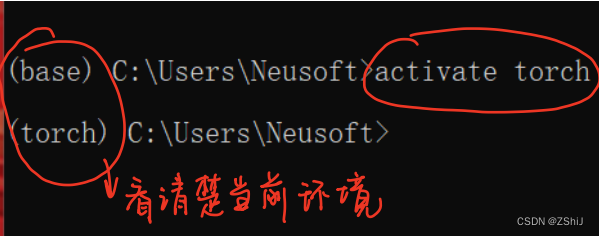
4、激活虚拟环境:activate torch
5、创建内核:conda install -n torch ipykernel
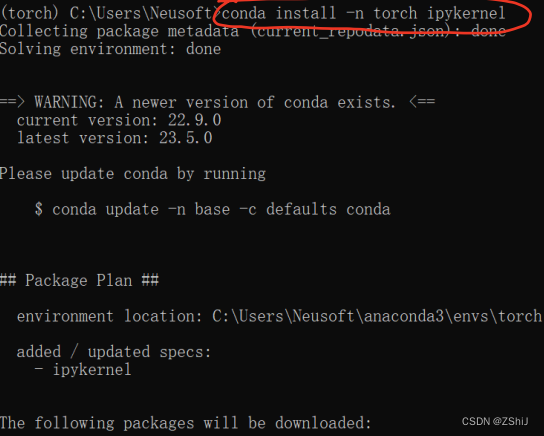
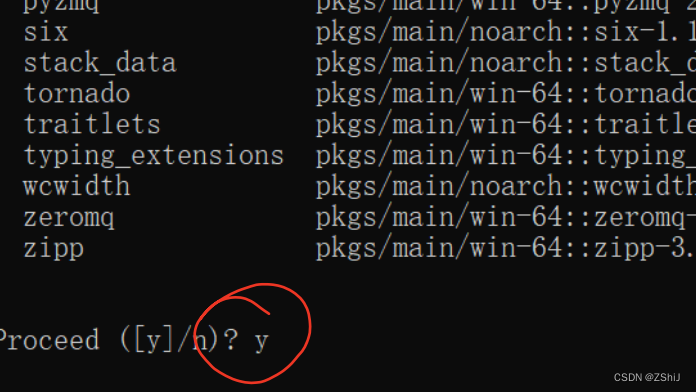
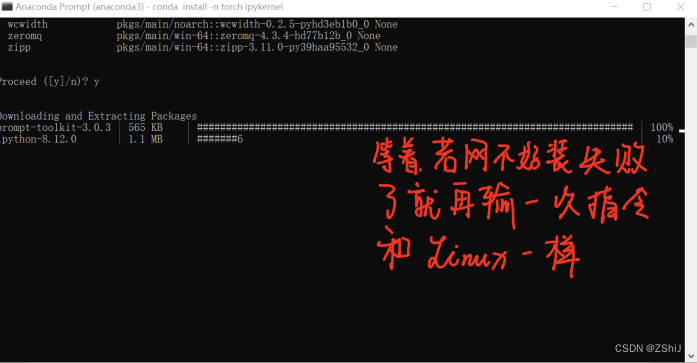

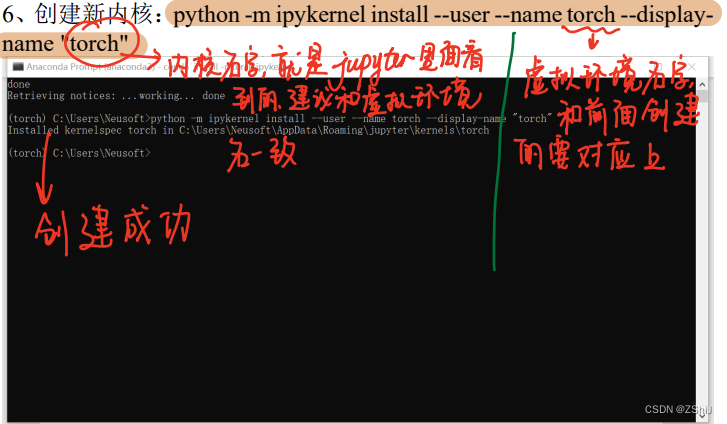
6、创建新内核:python -m ipykernel install --user --name torch --display-name "torch"
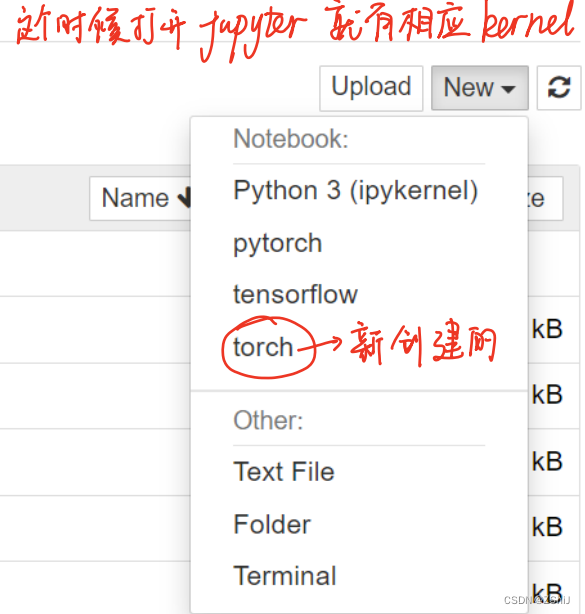
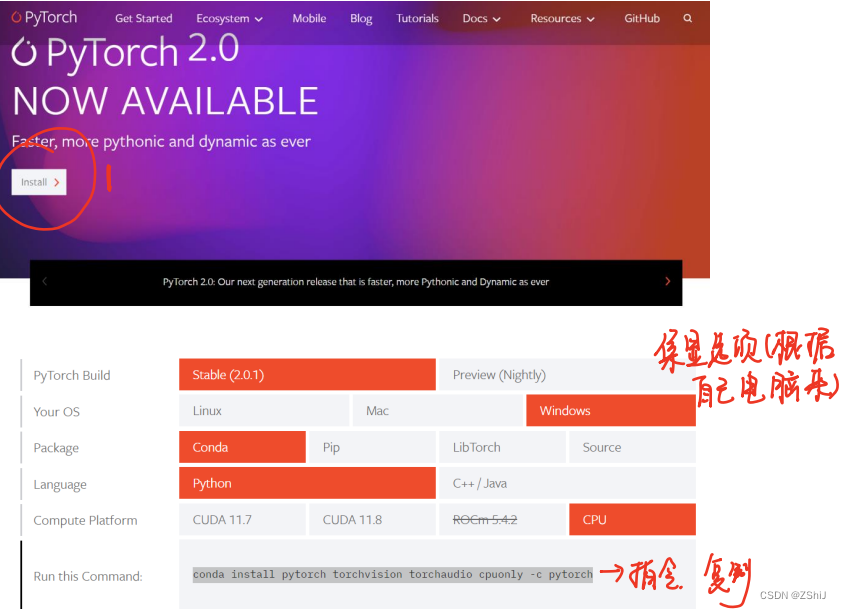
7、安装 pytorch:https://pytorch.org/
进入 pytorch 官网,选择合适的版本安装,并复制安装指令

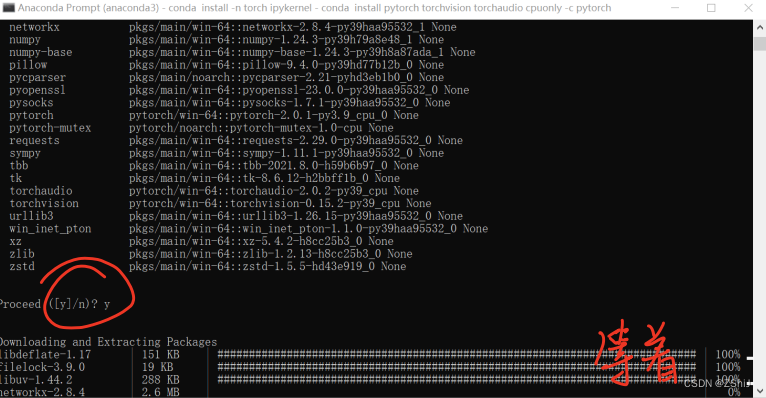

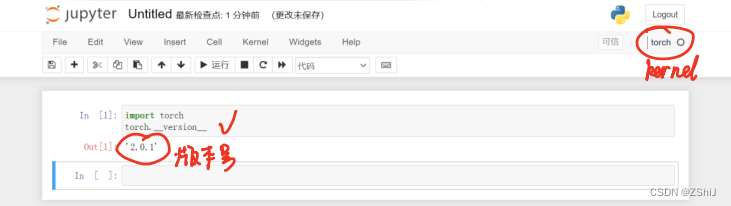
8、检查安装是否成功
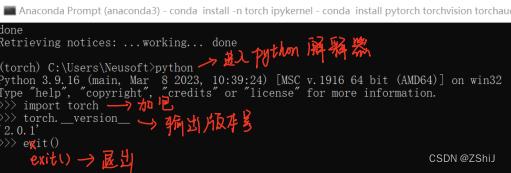
方法2
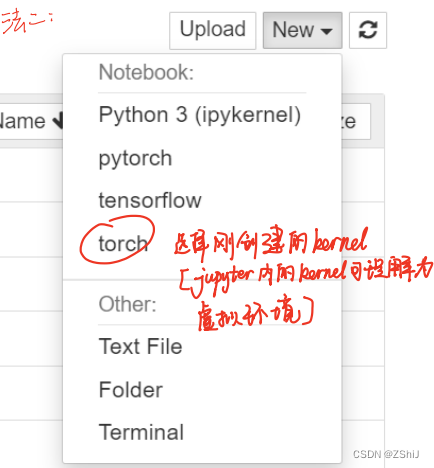
Pycharm
1、选择环境
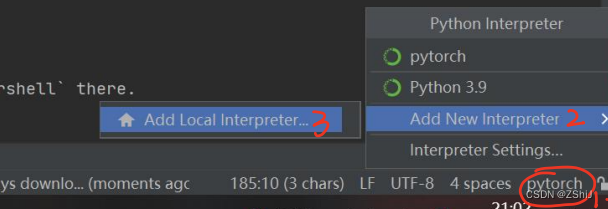
2、选择 torch 环境解释器
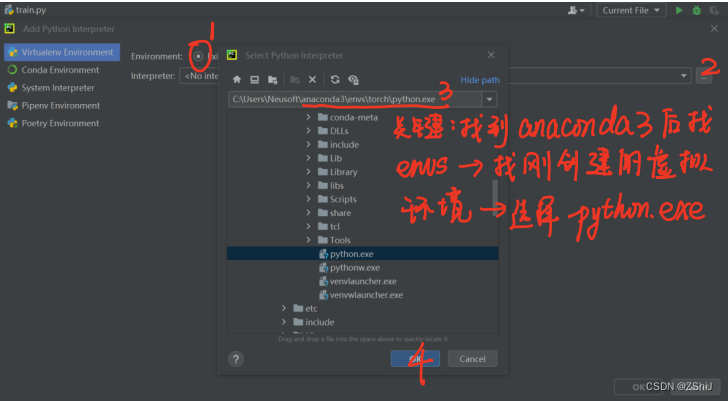
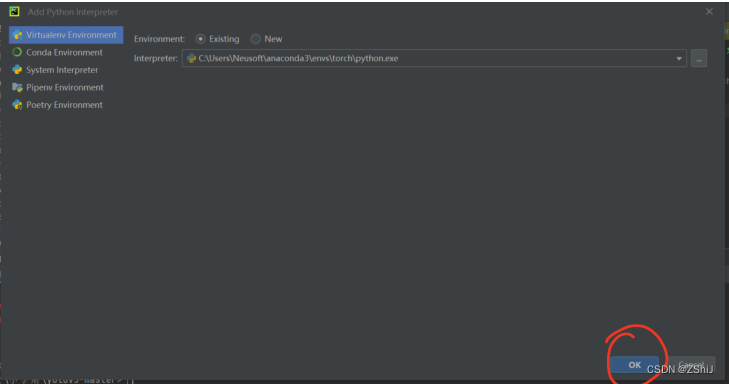
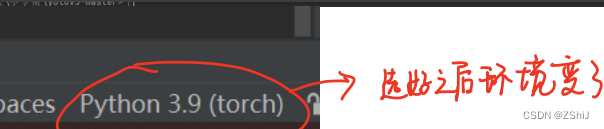
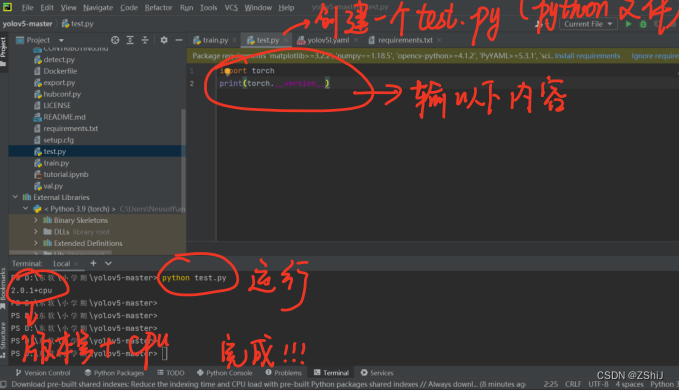
3、测试
独显安装参考(就是先装好CUDA和cudnn,然后剩下的和集显一样,
先创建好虚拟环境和相应的 kernel,然后安装):Pytorch环境配置(anaconda安装+独显+CUDA+cuDNN)
数据集介绍
给定数据集MNIST,Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
MNIST是一个计算机视觉数据集,它包含各种手写数字图片0,1,2,…,9
MNIST数据集包含:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。训练数据集和测试数据集都包含有一张手写的数字,和对应的标签,训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels;测试数据集的图片是 mnist.test.images ,训练数据集的标签是 mnist.test.labels每一张图片都是28*28像素(784个像素点),可以用点矩阵来表示每张图片
MNIST手写体识别
(一) 加包
import torch # 导入PyTorch库,用于构建和训练神经网络模型。
import torch.nn as nn # 导入PyTorch的神经网络模块,用于定义神经网络的层和模型。
import torch.nn.functional as F # 导入PyTorch的函数式接口模块,包含一些常用的非线性激活函数和损失函数。
import torch.optim as optim # 导入PyTorch的优化器模块,用于定义和实现不同的优化算法。
from torchvision import datasets, transforms # 从torchvision库中导入数据集和数据处理的功能。
import time # 导入Python的time模块,用于计时和时间相关的操作。
from matplotlib import pyplot as plt # 从matplotlib库中导入绘图功能,用于可视化数据和结果。

图1:加包
(二) 数据预处理
这段代码主要涉及数据预处理和数据加载的过程。
pipline_train和pipline_test是数据预处理的管道,通过transforms.Compose方法将多个预处理操作组合在一起。将transforms.RandomRotation添加到训练数据预处理中来进行随机旋转图片。使用transforms.Resize调整图片的尺寸,确保在将图片转化为Tensor格式之前调整好。将transforms.Normalize的参数从元组形式改为单个值形式,以便适应PyTorch 1.2.0版本及以上的要求。
train_set和test_set是使用MNIST数据集构建的训练集和测试集对象,参数说明如下:root=“./data”:数据集存储的根目录。train=True(对应train_set)或train=False(对应test_set):指定加载训练集还是测试集。download=True:如果数据集不存在,则自动从互联网上下载。transform=pipline_train(对应train_set)或transform=pipline_test(对应test_set):应用之前定义的数据预处理管道。
trainloader和testloader是数据加载器,用于将数据集分批次加载到模型进行训练和测试。torch.utils.data.DataLoader用于构建数据加载器。batch_size控制每个批次的样本数量。将trainloader和testloader中的shuffle参数设置为布尔值,指示是否对数据进行洗牌操作。
pipline_train = transforms.Compose([
#随机旋转图片
transforms.RandomRotation(10),
#将图片尺寸resize到32x32
transforms.Resize((32, 32)),
#将图片转化为Tensor格式
transforms.ToTensor(),
#正则化(当模型出现过拟合的情况时,用来降低模型的复杂度)
transforms.Normalize((0.1307,),(0.3081,))
])
pipline_test = transforms.Compose([
#将图片尺寸resize到32x32
transforms.Resize((32, 32)),
#将图片转化为Tensor格式
transforms.ToTensor(),
# 正则化
transforms.Normalize((0.1307,),(0.3081,))
])
#下载数据集 使用MNIST数据集构建的训练集和测试集对象
train_set = datasets.MNIST(root="./data", train=True, download=True, transform=pipline_train)
test_set = datasets.MNIST(root="./data", train=False, download=True, transform=pipline_test)
#加载数据集 torch.utils.data.DataLoader用于构建数据加载器
trainloader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(test_set, batch_size=32, shuffle=False)

图2:数据预处理

图3:下载数据集
(三) 搭建网络
这段代码定义了一个名为Net的神经网络模型类,模型包含了卷积层、激活函数、最大池化层、全连接层和Dropout层。
__init__(self)函数是模型类的初始化函数,通过卷积、激活、池化定义模型的层和参数。
forward(self, x)函数是模型类的前向传播函数,定义数据在模型中的流动方式。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1) # 输入通道数为1,输出通道数为16,卷积核大小为3,步长为1,填充为1
self.relu = nn.ReLU() # ReLU激活函数
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2) # 最大池化层,池化核大小为2,步长为2
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1) # 输入通道数为16,输出通道数为32,卷积核大小为3,步长为1,填充为1
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) # 输入通道数为32,输出通道数为64,卷积核大小为3,步长为1,填充为1
self.fc = nn.Linear(64 * 4 * 4, 10) # 全连接层,输入大小为64*4*4,输出大小为10
self.dropout = nn.Dropout(0.5) # Dropout层,丢弃概率为0.5
def forward(self, x):
x = self.conv1(x) # 卷积层1
x = self.relu(x) # ReLU激活函数
x = self.maxpool(x) # 最大池化层
x = self.conv2(x) # 卷积层2
x = self.relu(x) # ReLU激活函数
x = self.maxpool(x) # 最大池化层
x = self.conv3(x) # 卷积层3
x = self.relu(x) # ReLU激活函数
x = self.maxpool(x) # 最大池化层
x = x.view(-1, 64 * 4 * 4) # 展开成一维向量
x = self.dropout(x) # Dropout层
x = self.fc(x) # 全连接层
output = F.log_softmax(x, dim=1) # 使用log_softmax函数进行分类
return output

图4:搭建网络
(四) 计算、优化
使用Adam优化器,对模型的参数进行优化,学习率为0.001。这是一种常用的优化器,适用于大多数深度学习任务。
使用SGD优化器,对模型的参数进行优化,学习率为0.001,动量为0.9,权重衰减为0.00004。SGD是随机梯度下降的一种变体,动量和权重衰减可以帮助加速模型训练和提高泛化能力。这里给出了两个优化器的选择,可以根据实际情况选择其中之一进行使用。
我选择是的SGD优化器。
#创建模型,部署GPU或CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Net().to(device)
#定义优化器,这里给了两个优化器,大家可以结合上课讲的感受一下优劣(运行的时候选择其一即可)
# 使用Adam优化器
# optimizer = optim.Adam(model.parameters(), lr=0.001)
# 使用SGD优化器,设置学习率为0.001,动量为0.9,权重衰减为0.00004
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.00004)

图5:创建模型,选择优化器
(五) 训练
定义train_runner函数用于使用指定的优化器在给定数据集上训练模型。
先通过model.train(): 将模型设置为训练模式,启用批标准化(BatchNormalization)和随机失活(Dropout)功能。接着初始化计数器以及遍历 trainloader数据集。最后以元组的形式返回最终的损失、准确率和 top-5 准确率。
def train_runner(model, device, trainloader, optimizer, epoch):
#训练模型, 启用 BatchNormalization 和 Dropout, 将BatchNormalization和Dropout置为True
model.train()
total = 0 # 初始化总样本数为0
corrects = 0.0 # 初始化正确预测的样本数为0.0
correct_5 = 0.0 # 初始化 top-5 准确率的样本数为0.0
#enumerate迭代已加载的数据集,同时获取数据和数据下标
for i, data in enumerate(trainloader, 0):
inputs, labels = data # 将迭代得到的数据和标签分别赋值给 inputs 和 labels
#把模型部署到device上
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()#初始化梯度为0
outputs = model(inputs)#把数据喂给模型
#计算acc和top-5 error
_, preds = torch.max(outputs.data, 1)#top-1 根据模型的输出,获取预测结果中的最大值及其对应的索引,即 top-1 预测结果。
maxk = max((1,5))#top-5 设置最大的 top-k 值为1和5中较大的一个
_, pred_5 = outputs.topk(maxk, 1, True, True)#top-5 根据模型的输出,获取前k个最大值及其对应的索引,即 top-5 预测结果。
total += labels.size(0)# 累加总样本数,通过标签的大小得到当前批次的样本数
corrects += float(torch.sum(preds == labels.data))# 累加正确预测的样本数,通过判断预测结果和标签是否相等来计算正确预测的数量。
for k in range(maxk):#遍历 top-k 值
#累加 top-k 准确率的样本数,通过判断 top-k 预测结果和标签是否相等来计算准确预测的数量
correct_5 += float(torch.sum(pred_5[:, k] == labels.data))
#计算损失和
#多分类情况通常使用cross_entropy(交叉熵损失函数), 而对于二分类问题, 通常使用sigmod
loss = F.cross_entropy(outputs, labels)
loss.backward()#反向传播
optimizer.step()#更新参数
if i % 1000 == 0:
#loss.item()表示当前loss的数值
print("Train Epoch{} \t Loss: {:.6f}, accuracy: {:.6f}%, top-5: {:.6f}%".format(epoch, loss.item(), 100*(corrects/total), 100*(correct_5/total)))
Loss.append(loss.item())
Accuracy.append(corrects/total)
return loss.item(), corrects/total, correct_5/total

图6:train_runner函数
(六) 测试
test_runner函数用于在给定数据集上验证模型的性能。
先通过model.eval()将模型设置为评估模式,禁用批标准化(BatchNormalization)和随机失活(Dropout)功能。接着初始化统计变量,使用 torch.no_grad() 包装,确保在评估模式下不会计算梯度或进行反向传播。遍历 testloader 中的测试数据和标签以及计算准确率和 top-5 准确率。最后打印验证结果,包括平均损失、准确率和 top-5 准确率。
def test_runner(model, device, testloader):
#模型验证, 必须要写, 否则只要有输入数据, 即使不训练, 它也会改变权值
#因为调用eval()将不启用 BatchNormalization 和 Dropout, BatchNormalization和Dropout置为False
model.eval()
#统计模型正确率, 设置初始值
corrects = 0.0 # 记录正确预测的样本数
correct_5 = 0.0 # 记录在前5个预测中正确的样本数
test_loss = 0.0 # 记录测试损失的累加值
total = 0 # 记录总样本数
#torch.no_grad将不会计算梯度, 也不会进行反向传播
with torch.no_grad():
for data, labels in testloader:
data, labels = data.to(device), labels.to(device)
#把测试数据喂给模型
outputs = model(data)
#计算测试损失
loss = F.cross_entropy(outputs, labels)
test_loss += loss.item() * data.size(0)
#计算acc和top-5
_, preds = torch.max(outputs.data, 1) # top-1 根据模型的输出,获取预测结果中的最大值及其对应的索引
maxk = max((1, 5)) # top-5 设置最大的 top-k 值为1和5中较大的一个
_, pred_5 = outputs.topk(maxk, 1, True, True) # top-5 根据模型的输出,获取前k个最大值及其对应的概率
total += labels.size(0)# 将当前批次中的样本数添加到总计数中
corrects += float(torch.sum(preds == labels.data))#通过将预测类别与真实标签进行比较,计算正确预测的数量
correct_5 += float(torch.sum(pred_5[:, 0] == labels.data))#通过将 top-5 预测与真实标签进行比较,计算正确 top-5 预测的数量。
#打印结果:平均损失、准确率和 top-5 准确率。
print("test_avarage_loss: {:.6f}, accuracy: {:.6f}%, top-5: {:.6f}%".format(test_loss/total, 100*(corrects/total), 100*(correct_5/total)))

图7:test_runner函数
(七) 主函数调用
初始化训练过程的相关变量:epoch表示训练的总轮数,Loss、Accuracy和 Accuracy_5用于记录训练过程中的损失、准确率和top-5准确率。
进行训练循环,从第1轮到第epoch(5)轮:调用train_runner函数进行模型训练,并获取训练过程中的损失、准确率和top-5准确率,并且将损失、准确率和 top-5 准确率记录到对应的列表中。
最后使用matplotlib进行可视化,绘制损失曲线、准确率曲线、top-5 准确率曲线,显示图片并将图片保存为 “zhan.png”。
# 调用
epoch = 5# 训练的总轮数
Loss = []# 记录训练过程中的损失
Accuracy = []# 记录训练过程中的准确率
Accuracy_5 = []# 记录训练过程中的top-5 准确率
for epoch in range(1, epoch+1):## 开始训练循环,每个 epoch 迭代一次
# 打印当前时间作为训练开始时间
print("start_time",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())))
# 调用 train_runner 函数进行模型训练
loss, acc, acc_5 = train_runner(model, device, trainloader, optimizer, epoch)
# 将训练过程中的损失、准确率和 top-5 准确率记录下来
Loss.append(loss)
Accuracy.append(acc)
Accuracy_5.append(acc_5)
# 调用 test_runner 函数进行模型验证
test_runner(model, device, testloader)
# 打印当前时间作为训练一次结束的时间
print("end_time: ",time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),'\n')
# 打印 "Finished Training" 表示训练结束
print('Finished Training')
# matplotlib画图# 绘制训练过程中的损失、准确率和 top-5 准确率曲线
plt.figure(figsize=(10, 8))
plt.subplot(3, 1, 1)
plt.plot(Loss, label='Loss')
plt.title('Loss')# 损失曲线
plt.legend()# 绘制图例
plt.subplot(3, 1, 2)
plt.plot(Accuracy, label='Accuracy')
plt.title('Accuracy')# 准确率曲线
plt.legend()# 绘制图例
plt.subplot(3, 1, 3)
plt.plot(Accuracy_5, label='Accuracy_5')
plt.title('Accuracy_5')# top-5 准确率曲线
plt.legend()# 绘制图例
plt.savefig("zhan.png") # 保存图像
plt.tight_layout()# 自动调整子图参数,使之填充整个图像区域
plt.show()# 显示图像

图8:主函数

图9:打印模型训练验证结果

图10:训练过程中的损失、准确率和 top-5 准确率曲线(zhan.png)
异常问题与解决方案
异常问题1: No module named 'pyparsing’
解决方案:%pip install pyparsing但是失败了,最后重新启动内核便可以使用更新的包了。

图11:解决方法
异常问题2:TypeError:super(type, obj) : obj must be an instance or subtype of type。其实是找不到名字为LeNet()的类。

图12:异常问题
解决方案:通过查看之前的代码,发现定义的是名为Net的神经网络模型类,所以将LeNet()修改为Net()便可以运行了。

图13:解决方法
异常问题3:模型训练验证结果和绘制的损失、准确率和 top-5 准确率曲线不一致。

图14:异常问题
解决方案:每一次都要重新启动并重新运行,重新启动后数据和曲线一致。
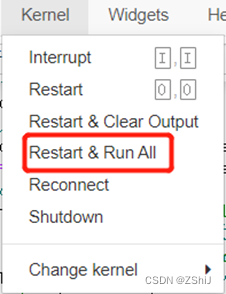
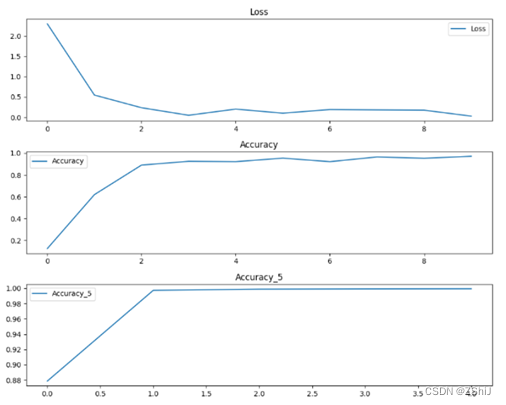
图15:解决方法

















 8689
8689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











