






下载地址:
链接:https://pan.baidu.com/s/1c04UZvwRrPGpoei2Js8tkA
提取码:gen8
--来自百度网盘超级会员V5的分享
一、安装
1、通过以上下载链接下载TscanCode
2、双击打开TscanCodeV2.14.24.windows.exe
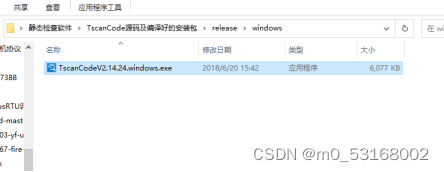
3、等待安装包准备就绪

4、点击下一步
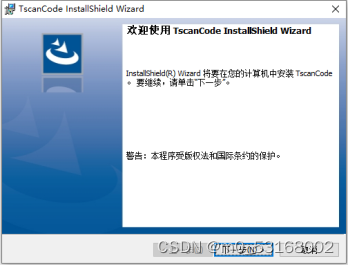
5、点击更改以更改安装路径
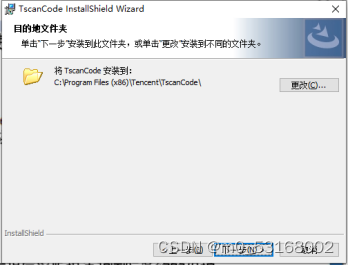
6、点击下拉菜单选择路径
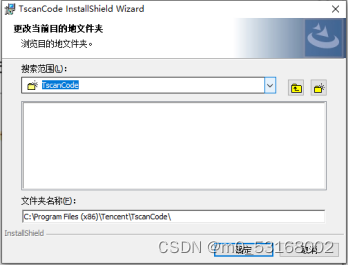
7、选择D盘
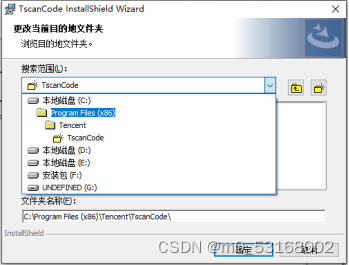
8、点击新建文件夹按钮新建一个文件夹,然后重命名为“TscanCode”

9、双击打开TscanCode文件夹,点击确定

10、点击下一步进行安装
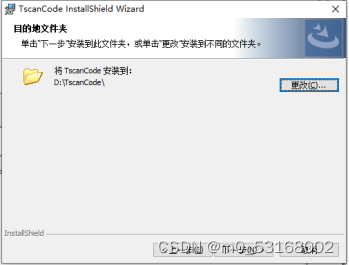
11、安装完成后,点击完成按钮退出安装程序
二、使用
- 双击打开TscanCode

2、点击设置可以对检查规则进行选择

3、软件默认选择了基础规则包的全部规则,用户可以查看或者取消勾选其中的任意规则;扩展规则包以及可以错误规则包可以自行选择勾选。
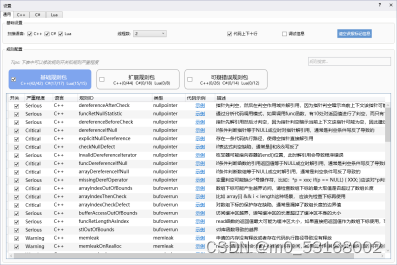
4、设置好规则后点击关闭,进入主界面点击扫描文件夹

5、找到要进项静态检查的文件根目录,点击选择文件夹
6、点击开始扫描,开始进行本项目的静态检查

7、等待检查完毕
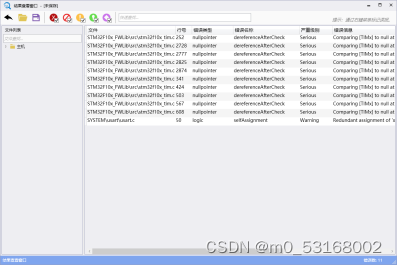
8、检查完成后会弹出一个新的结果查看窗口,窗口中会显示错误信息
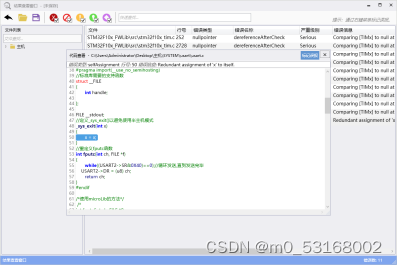
9、双击其中的一个错误可以对错误内容进行查看
选包建议:
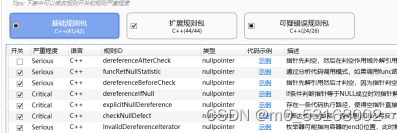
建议使用基础规则包时将dereferenceAfterCheck规则取消勾选,这条规则是用来判断在使用指针时是否判断指针为空,但是在大多数的项目工程中对于结构体指针并不会进行这样的判断,这会导致大量的误判报告,如果确实需要检查可勾选此项。
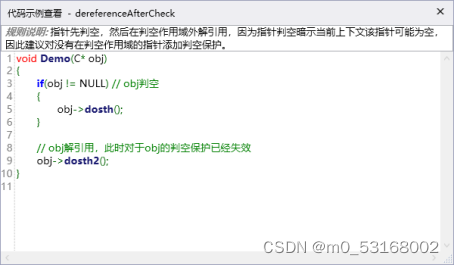
dereferenceAfterCheck描述:指针先判空,然后在判空作用域外解引用,因为指针判空暗示当前上下文该指针可能为空,因此建议对没有在判空作用域的指针添加判空保护。
dereferenceAfterCheck示例:
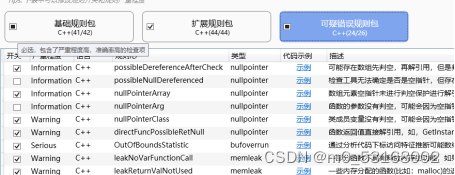
在勾线可以错误规则包时候建议取消勾选nullPointerArg规则和possibleNullDereferenced规则,nullPointerArg规则是用来判断函数返回值赋值给指针时是否为空,出现这种错误通常是因为函数定义为void类型,但这样的错误编译器会有相应的提示,所以可以取消勾选;对于possibleNullDereferenced规则同nullPointerArg规则类似,以下是软件中对二者的描述。
| 规则名 | 规则描述 |
| nullPointerArg | 函数的参数没有判空,可能会因为空指针带来宕机等严重问题。 |
| possibleNullDereferenced | 检查工具无法确定是否是空指针,但存在这个可能需要人工确定,如:char *p = GetSomePointer();工具未能找到GetSomePointer()函数的实现或无法确定该函数是否不可能返回空,所以对指针p解引用就会报该错误。 |
小技巧:
在使用工程模板时,通常底层代码是不需要修改的,建议不要将用户代码文件与底层代码文件放置于同一个文件夹中,在进行代码静态检查是选择用户文件夹进行只对用户代码的静态检查以提高静态检查的效率。















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









