






题目:
A deep learning method to detect prescription and use disorder from electronic health records
摘要:
本研究的目的是开发一种结合深度学习的方法,利用结构化和非结构化EHR数据预测某类药物处方和use disorder。结果表明,预测某类药物处方是可能的,f1评分为0.88±0.003,aucc - roc为0.93±0.002。我们还构建了预测use disorder诊断的模型,f1评分为0.82±0.05, AUCROC为0.94±0.008。随着某类药物在美国的流行持续增长,在患者治疗过程中使用这种模型将有助于医疗工作者控制局势。
数据集:
使用MIMIC-III数据集,该数据集包含与53,423个不同的重症监护病房(ICU)入院相关的数据。
1、获取某类药物处方预测模型数据集
构建一个二元分类模型,可以利用患者的EHR数据预测患者是否可能被开某类药物。使用一个包含30种某类药物的列表,我们解析MIMICIII数据集,以识别给患者开过这些药物的所有住院id (hadm_id)。这些是积极的例子,而其余的hadm_id(患者未被开某类药物)则被认为是消极的例子。
对于每个HADM_ID,我们从MIMIC-III中检索3种类型的数据(如果该患者在住院期间可用):
- 结构化静态数据:该数据包括患者在一次入院期间保持不变的特征。例如特征包括患者的性别、种族、婚姻状况、宗教等。
- 结构化时变数据:这些数据包括患者在住院过程中典型变化的信息。这些事件包括执行的过程和实验室测试,以及输入/输出事件。
- 非结构化临床注释:该数据包括医疗工作者在治疗患者时撰写的注释。
对于每个属于积极的例子的入院患者,确定第一次开出某类药物处方的日期和时间。我们考虑的输入特征包括MIMIC-III EHR在该时间点之前记录的有关患者的所有信息。在进行标记化之前,我们使用包含完整药物名称的正则表达式删除临床记录和正例的输入事件中提及某类药物的任何内容,以确保在我们的特征空间中不会出现信息泄漏。然而,这不能解释药物拼写错误和缩写,这些通过人工检查在临床记录中很少发生。
任何出现在MIMIC-III数据集少于1%的特性都被删除。我们为8个特征类别中的每一个引入了一个额外的“UNKNOWN”特性来解释缺失的数据。
对于消极的例子,考虑MIMIC-III EHR中包含的关于该患者入院的所有信息。在测试时,对于未知患者,我们考虑其电子病历中的所有信息来做出相关预测。确保在积极和消极的训练集上,每个病人只有一个住院机会。这使得某类药物处方预测发生在单一住院时间框架内。
2、获取某类药物use disorder预测模型数据集
在MIMIC-III中,任何一组ICD9编码被诊断的患者的hadm_id均为阳性,其余的hadm_id均为阴性。使用结构化静态数据、结构化时变数据和非结构化临床记录作为模型的输入。由于12个ICD-9代码没有出现在每个患者的输入特征中,我们希望模型能够学习对诊断use disorder很重要的特征。
Model construction and training
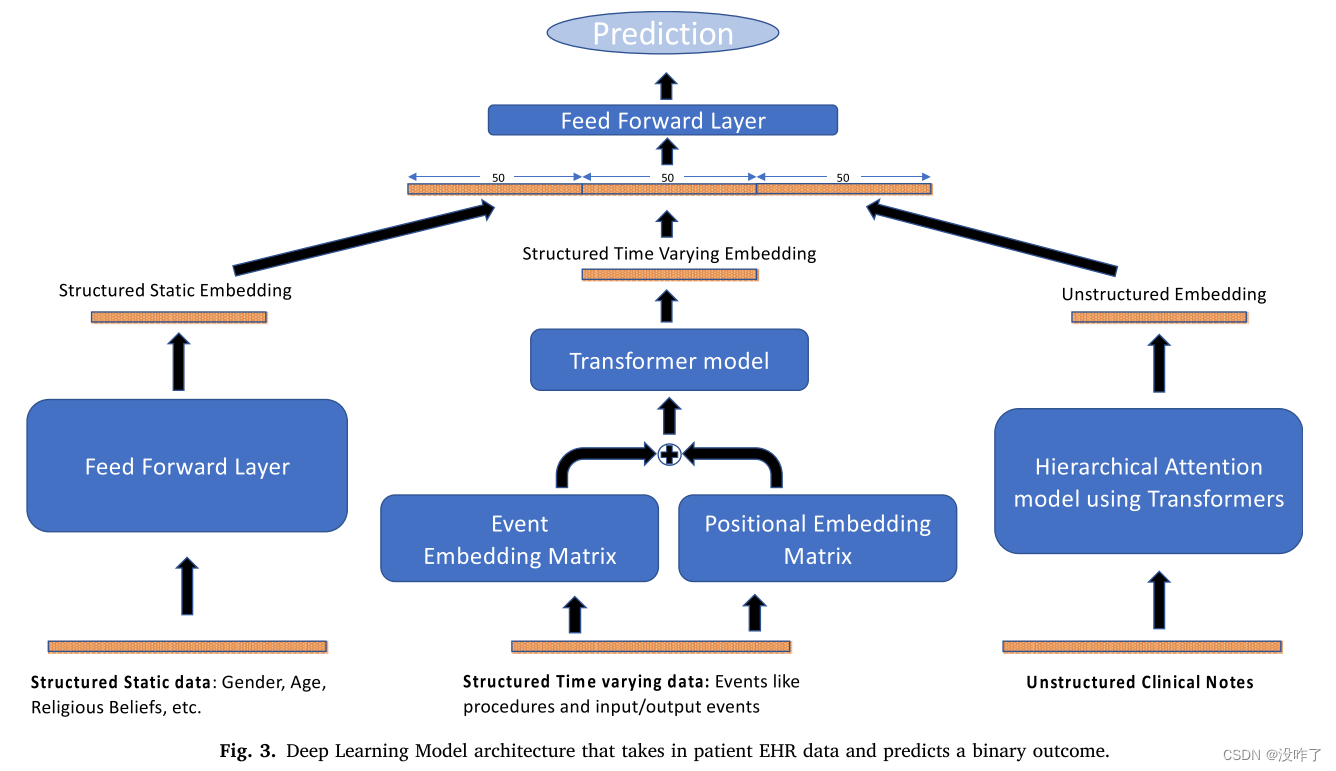
最后一个组件共同处理来自前3个组件的信息。为每一种数据类型计算的嵌入大小相等(1 × 50),以确保跨不同模态的信息具有相同的表示。
1、Structured Static component:
The structured static data containing categorical features was converted to indicator variables. 然后,将每个患者入院的一个包含45个特征的向量通过前馈层转换为大小为50的“结构化静态嵌入”
2、Structured time Varying component:
The events in the structured time varying data were first sorted chronologically for every patient admission, following which each event was converted into a one hot encoding. We selected a maximum of 150 most recent events for every patient and appended a start and end token.
在所有患者中,我们确定了4483个独特的事件,每个患者的平均事件数为125。基于此,我们为每个患者选择了最多150个最近的事件。事件嵌入层和位置嵌入层的维数均为50。位置嵌入被包含在模型架构中,因为我们觉得一个事件相对于序列中其他事件的相对位置是预测所需结果的一个重要信号。Transformer层包含2个注意头,2个编码器和解码器层,以及一个512维的前馈层,输出上下文事件嵌入。
3、Unstructured component:
每个入院病人的记录首先按时间顺序排序,并将他们最近的40份记录(如果是积极的例子,则是在某类药物处方之前或use disorder诊断之前,如果是消极的则是最后的40份记录)输入到Hierarchical Transformer Model. Note embeddings were obtained using ClinicalBERT and a Note Level Transformer. The note embeddings were then passed through a Patient Level Transformer Layer that aggregated information across the 40 notes of a single patient admission. The output was taken as the “Unstructured Embedding”.
为了为分层转换器模型准备数据,我们首先使用词片标记器对每个注释进行标记,然后将标记化的注释分割为510个标记的剪接,并附加一个标记[CLS]和[SEP]标记到每个剪接的开始和结束(BERT模型接受的最大输入序列大小为512)。
接下来,我们为每个note选择多达10个note的拼接(结果是每个note最多有5100个标记),并使用ClinicalBERT为各自的拼接获得嵌入。我们通过前馈网络将拼接BERT嵌入的维数降至50。我们这样做是为了减少以下层的内存需求。
在添加位置嵌入后,将减少的BERT嵌入通过两个连续的变压器层。
- 第一个Transformer在特定的注释中使用跨拼接的注意。它为第一个剪接的[CLS]标记计算上下文化的嵌入,该标记被作为注释嵌入。
- 第二种变压器模型采用前一层计算的最多40个note的note嵌入,并使用注意力计算所有note的上下文化嵌入。
采用随机梯度下降(学习率为0.005,动量为0.9)和二元交叉熵损失(Bi - nary Cross Entropy Loss)对深度学习模型进行15个时代的训练,训练对象为10个批次的gpu。由于深度学习模型具有非凸目标函数,因此在同一数据集上进行训练时,它们的表现略有不同。因此,对于这两个任务中的每一个,训练了一个模型10次,并报告了测试集上的性能指标,作为跨越10个模型的平均值±标准差。
4、Aggregation component:
前三个组件的嵌入最终连接在一起,并通过前馈层得到对感兴趣的二元变量的预测。
- 首先通过对负样本进行欠采样,为每个任务创建一个包含等量样本的平衡数据集。
- 接下来,我们留出数据的一个随机子集(10%)作为测试集,并使用剩余的数据来训练和验证分类模型。
- 除了平衡测试集,还创建了一个不平衡测试集,该测试集反映了Mimic-III中每个任务的总正负样本的分布情况。
- 将数据集分割为训练集、验证集和测试集后,对数据进行一次热编码和缺失值填充的预处理,以避免数据泄漏。
- 为每个任务训练了10个不同的模型,并将测试集上的性能指标报告为均值±标准差。
Model and data insights:
我们对每一种任务组合(某类药物处方和use disorder)和数据类型(结构化静态数据、结构化时变数据和非结构化临床记录)的逻辑回归(loggreg)模型进行了训练,以提供模型和数据见解。
- 根据结构化静态数据和结构化时变数据中类别特征的存在与否训练LogReg模型。
- 对于非结构化临床注释,文本数据首先被标记为ungram、biggram和triggram特征,转换为小写,并用二进制向量表示,然后用于训练LogReg模型。
- 在构建这些二进制向量时,考虑了临床记录中20,000个最常见的ngram。
- 此外,我们展示了两种基线LogReg模型的结果,一种模型只训练患者EHRs的结构化部分,而另一种模型也纳入了非结构化的临床文本,结果证明了在预测过程中纳入临床注释的重要性。
总结与讨论:
Prediction of prescribing:我们没有发现过去的研究集中于基于EHRs预测某类药物处方的可能性。因此,本工作通过显示F1评分为0.88±0.003,aucc - roc评分为0.93±0.002,为填补这一空白做出了重要贡献。
Prediction of use Disorder:我们在aucc - roc和F1值方面优于之前的工作,但开展的药物依赖研究往往在研究周期、样本量、定义、数据库的类型和结构化文档,以及因此在这些研究中建立的模型性能的一些差异可能使模型不能直接比较。
Our Deep Learning models overcome known limitations in the field,之前的很多研究依赖于临床专家的领域知识来进行特征工程。这通常需要大量的工作,并且可能非常麻烦和昂贵。在我们的深度学习模型中,特征是作为训练过程的一部分自动学习的,这提供了一种廉价的方法来识别感兴趣的医疗结果。研究人员还经常对电子病历的结构化部分构建预测模型,忽略非结构化部分,在本文中,我们利用来自NLP的最新模型,建立了能够同时包含电子病历结构化和非结构化部分信息的模型,以作出明智的决策。
本文中提到的方法有一定的局限性:
- 研究人员提到,ICD编码可能会低估表现出目标分类的患者的实际数量,这是由于故意缺乏记录,或者在其他情况下,处方方试图避免对某类药物问题患者进行污名化。因此,一些有某类药物问题的患者可能会被忽视。这可能会在我们的训练数据中导致一些错误的否定,从而损害模型的泛化性。
- 模型性能只满足测试集上获得的相同的数据分布作为训练数据。这可能只是模型在一般设置中的部分表现。理想情况下,我们还希望在非分布的测试数据集上评估模型,但由于很难获得另一个数据集进行评估,这在本研究中是不可能的,但仍然是未来工作的主题。
- 由于创建该工具的诊所和可能采用该工具的目标诊所之间的人口差异和程序差异,在采用该工具时可能存在一些障碍。另一个值得注意的重要一点是,尽管在大多数指标上,深度学习模型的表现优于各自的LogReg基线,但深度学习模型的召回率较低,这可能会在某些情况下带来风险,如无法识别高风险个体就意味着死亡。需要进一步的研究来建立克服这一缺点的模型。
- Mimic-III的数据来自重症监护室,倾向于危重患者。这种数据偏差的程度将作为未来工作的一部分进行评估。














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









