







书生大模型第四期笔记:Prompt/RAG/XTuner微调/Agent/LMDeploy量化部署...
- 入门岛
- 基础岛
- 进阶岛
- 彩蛋
- 总结高频概念
- 部分优秀项目
入门岛
第一关 Linux
闯关任务:完成SSH连接与端口映射并运行hello_world.py
ssh连接:打开powershell,复制登录命令。使用hostname查看开发机名称,使用uname -a查看开发机内核信息,使用lsb_release -a查看开发机版本信息,使用nvidia-smi查看GPU的信息

后续使用cursor进行ssh和端口映射,成功运行hello_world.py
笔记与过程
SSH
cursor安装Remote-SSH
创建开发机
SSH全称Secure Shell,中文翻译为安全外壳,它是一种网络安全协议,通过加密和认证机制实现安全的访问和文件传输等业务。SSH 协议通过对网络数据进行加密和验证,在不安全的网络环境中提供了安全的网络服务。
SSH 是(C/S架构)由服务器和客户端组成,为建立安全的 SSH 通道,双方需要先建立 TCP 连接,然后协商使用的版本号和各类算法,并生成相同的会话密钥用于后续的对称加密。在完成用户认证后,双方即可建立会话进行数据交互。
那在后面的实践中我们会配置SSH密钥,配置密钥是为了当我们远程连接开发机时不用重复的输入密码,那为什么要进行远程连接呢?
远程连接的好处就是,如果你使用的是远程办公,你可以通过SSH远程连接开发机,这样就可以在本地进行开发。而且如果你需要跑一些本地的代码,又没有环境,那么远程连接就非常有必要了。
命令:ssh -p 38267 root@ssh.intern-ai.org.cn -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null
端口映射
端口映射是一种网络技术,它可以将外网中的任意端口映射到内网中的相应端口,实现内网与外网之间的通信。通过端口映射,可以在外网访问内网中的服务或应用,实现跨越网络的便捷通信。
那么我们使用开发机为什么要进行端口映射呢?
因为在后续的课程中我们会进行模型web_demo的部署实践,那在这个过程中,很有可能遇到web ui加载不全的问题。这是因为开发机Web IDE中运行web_demo时,直接访问开发机内 http/https 服务可能会遇到代理问题,外网链接的ui资源没有被加载完全。
所以为了解决这个问题,我们需要对运行web_demo的连接进行端口映射,将外网链接映射到我们本地主机,我们使用本地连接访问,解决这个代理问题。下面让我们实践一下。
ssh -p 38267 root@ssh.intern-ai.org.cn -CNg -L 7860:127.0.0.1:7860 -o StrictHostKeyChecking=no
这条命令会通过开发机 SSH 通道将开发机内的 {开发机_PORT} 转发到您本地机器的 (本地机器_PORT},这个过程可能会要求你输入 SSH 链接的密码。
linux文件管理命令
在 Linux 中,常见的文件管理操作包括:
- 创建文件:可以使用
touch命令创建空文件。 - 创建目录:使用
mkdir命令。 - 目录切换:使用
cd命令。 - 显示所在目录:使用
pwd命令。 - 查看文件内容:如使用
cat直接显示文件全部内容,more和less可以分页查看。 - 编辑文件:如
vi或vim等编辑器。 - 复制文件:用
cp命令。 - 创建文件链接:用
ln命令。 - 移动文件:通过
mv命令。 - 删除文件:使用
rm命令。 - 删除目录:
rmdir(只能删除空目录)或rm -r(可删除非空目录)。 - 查找文件:可以用
find命令。 - 查看文件或目录的详细信息:使用
ls命令,如使用ls -l查看目录下文件的详细信息。 - 处理文件:进行复杂的文件操作,可以使用
sed命令。
linux进程管理命令
进程管理命令是进行系统监控和进程管理时的重要工具,常用的进程管理命令有以下几种:
- ps:查看正在运行的进程
- top:动态显示正在运行的进程
- pstree:树状查看正在运行的进程
- pgrep:用于查找进程
- nice:更改进程的优先级
- jobs:显示进程的相关信息
- bg 和 fg:将进程调入后台
- kill:杀死进程
第二关 Python
闯关任务:Leetcode 383(笔记中提交代码与leetcode提交通过截图)
代码:
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
a = Counter(ransomNote)
b = Counter(magazine)
return (a & b) == a
通过截图:

思路:一开始的想法是用map统计每个字母的出现次数,保证magazine中每个字母的统计次数>=ransomNote中的;python3正好有很方便的库Collection用来跟踪值出现的次数,常见操作如下,用交集就可以满足该题的要求。
>>> c = Counter("abcdcba")
>>> c
Counter({
'a': 2, 'c': 2, 'b': 2, 'd': 1})
>>> c = Counter("abcdefgab")
>>> c["a"]
2
>>> c["c"]
1
>>> c["h"]
0
sum(c.values()) # 所有计数的总数
c.clear() # 重置Counter对象,注意不是删除
list(c) # 将c中的键转为列表
set(c) # 将c中的键转为set
dict(c) # 将c中的键值对转为字典
c.items() # 转为(elem, cnt)格式的列表
Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象
c.most_common()[:-n:-1] # 取出计数最少的n-1个元素
c += Counter() # 移除0和负值
闯关任务:Vscode连接InternStudio debug笔记
pip下载openai环境,运行后发现有bug

打断点排查,发现json.loads理应处理的json字符串res有一些多余的字符:

使用res.strip()去除后即可顺利运行:

完整代码:
from openai import OpenAI#调用书生浦语API实现将非结构化文本转化成结构化json的例子
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{
"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{
content}`
"""
res = internlm_gen(prompt,client)
trimmed_res = res.strip()[7:-3]
res_json = json.loads(trimmed_res)
print(res_json)
笔记与过程
conda虚拟环境
虚拟环境是Python开发中不可或缺的一部分,它允许你在不同的项目中使用不同版本的库,避免依赖冲突。Conda是一个强大的包管理器和环境管理器。
pip只管理python包,conda
conda create --name myenv python=3.9
conda activate myenv
conda deactivate
#查看当前设备上所有的虚拟环境
conda env list
#查看当前环境中安装了的所有包
conda list
#删除环境(比如要删除myenv)
conda env remove myenv
#安装虚拟环境到指定目录 方便共享
conda create --prefix /root/envs/myenv python=3.9
pip安装
pip install -r requirements.txt
为了节省大家的存储空间,本次实战营可以直接使用share目录下的conda环境,但share目录只有读权限,所以要安装额外的包时我们不能直接使用pip将包安装到对应环境中,需要安装到我们自己的目录下。
这里我们用本次实战营最常用的环境/root/share/pre_envs/pytorch2.1.2cu12.1来举例。
# 首先激活环境
conda activate /root/share/pre_envs/pytorch2.1.2cu12.1
# 创建一个目录/root/myenvs,并将包安装到这个目录下
mkdir -p /root/myenvs
pip install <somepackage> --target /root/myenvs
# 注意这里也可以使用-r来安装requirements.txt
pip install -r requirements.txt --target /root/myenvs
要使用安装在指定目录的python包,可以在python脚本开头临时动态地将该路径加入python环境变量中去
import sys
# 你要添加的目录路径
your_directory = '/root/myenvs'
# 检查该目录是否已经在 sys.path 中
if your_directory not in sys.path:
# 将目录添加到 sys.path
sys.path.append(your_directory)
# 现在你可以直接导入该目录中的模块了
# 例如:import your_module
配debug环境
下载python插件,首次debug需要配置以下,点击“create a launch.json file”,选择python debugger后选择“Python File” config。
第三关 Git
任务1: 破冰活动:自我介绍
fork后下载有一些问题,是网络,多试几次

写自我介绍文件并提交到本地仓库
提交pr。pr链接:https://github.com/InternLM/Tutorial/pull/2517

任务2: 实践项目:构建个人项目
因为github经常出现网络问题,使用gitee平台,在其上上传了深度学习相关的个人毕设项目(因为暂无大模型项目),并将书生大模型的超链接加入readme:
https://gitee.com/sammmmy/cfg-gnn
因为个人时间和能力有限,以及主题不相关,不报名第四期实战营项目。
笔记与过程
工作区、暂存区和 Git 仓库区
- 工作区(Working Directory): 当我们在本地创建一个 Git 项目,或者从 GitHub 上 clone 代码到本地后,项目所在的这个目录就是“工作区”。这里是我们对项目文件进行编辑和使用的地方。
- 暂存区(Staging Area): 暂存区是 Git 中独有的一个概念,位于 .git 目录中的一个索引文件,记录了下一次提交时将要存入仓库区的文件列表信息。使用 git add 指令可以将工作区的改动放入暂存区。
- 仓库区 / 本地仓库(Repository): 在项目目录中,.git 隐藏目录不属于工作区,而是 Git 的版本仓库。这个仓库区包含了所有历史版本的完整信息,是 Git 项目的“本体”。
常用指令
常用指令
| 指令 | 描述 |
|---|---|
git config |
配置用户信息和偏好设置 |
git init |
初始化一个新的 Git 仓库 |
git clone |
克隆一个远程仓库到本地 |
git status |
查看仓库当前的状态,显示有变更的文件 |
git add |
将文件更改添加到暂存区 |
git commit |
提交暂存区到仓库区 |
git branch |
列出、创建或删除分支 |
git checkout |
切换分支或恢复工作树文件 |
git merge |
合并两个或更多的开发历史 |
git pull |
从另一仓库获取并合并本地的版本 |
git push |
更新远程引用和相关的对象 |
git remote |
管理跟踪远程仓库的命令 |
git fetch |
从远程仓库获取数据到本地仓库,但不自动合并 |
进阶指令
| 指令 | 描述 |
|---|---|
git stash |
暂存当前工作目录的修改,以便可以切换分支 |
git cherry-pick |
选择一个提交,将其作为新的提交引入 |
git rebase |
将提交从一个分支移动到另一个分支 |
git reset |
重设当前 HEAD 到指定状态,可选修改工作区和暂存区 |
git revert |
通过创建一个新的提交来撤销之前的提交 |
git mv |
移动或重命名一个文件、目录或符号链接,并自动更新索引 |
git rm |
从工作区和索引中删除文件 |
第四关 玩转HF/魔搭/魔乐社区
任务:HF平台模型下载与使用过程
-
使用GitHub CodeSpace安装依赖:

-
下载internlm2_5-7b-chat的配置文件

-
下载internlm2_5-chat-1_8b并打印示例输出:这里以“A beautiful flower”开头,模型对其进行“续写”,InternLM的模型拥有强大的数学方面的能力。这里输出的问题是一个数学问题。

-
Hugging Face Spaces的使用:
Hugging Face Spaces 是一个允许我们轻松地托管、分享和发现基于机器学习模型的应用的平台。Spaces 使得开发者可以快速将我们的模型部署为可交互的 web 应用,且无需担心后端基础设施或部署的复杂性。
首先创建了static space

然后回到CodeSpace,接着clone项目。照着手册修改html,添加token,就能成功push,发现再次进入Space界面变成了下图:
-
模型上传:
通过CLI上传 Hugging Face同样是跟Git相关联,通常大模型的模型文件都比较大,因此我们需要安装git lfs,对大文件系统支持。一些过程:
上传完毕的模型网页:
基础岛
第一关 书生大模型全链路开源体系
官网:https://internlm.intern-ai.org.cn/
github:https://github.com/InternLM
InternLM开源一周年
性能天梯:与GPT靠近

推理能力:指原生的推理性能,不包括agent等自定义逻辑

核心技术思路:迭代,数据质量驱动(基于规则、模型、反馈)
100万token上下文:大海捞针实验(给很长的信息,看能否定位任何位置的任何信息)
- 以前要RAG:拆分、向量化、匹配分块

7B感觉还是在检索信息,20B开始有思考的感觉

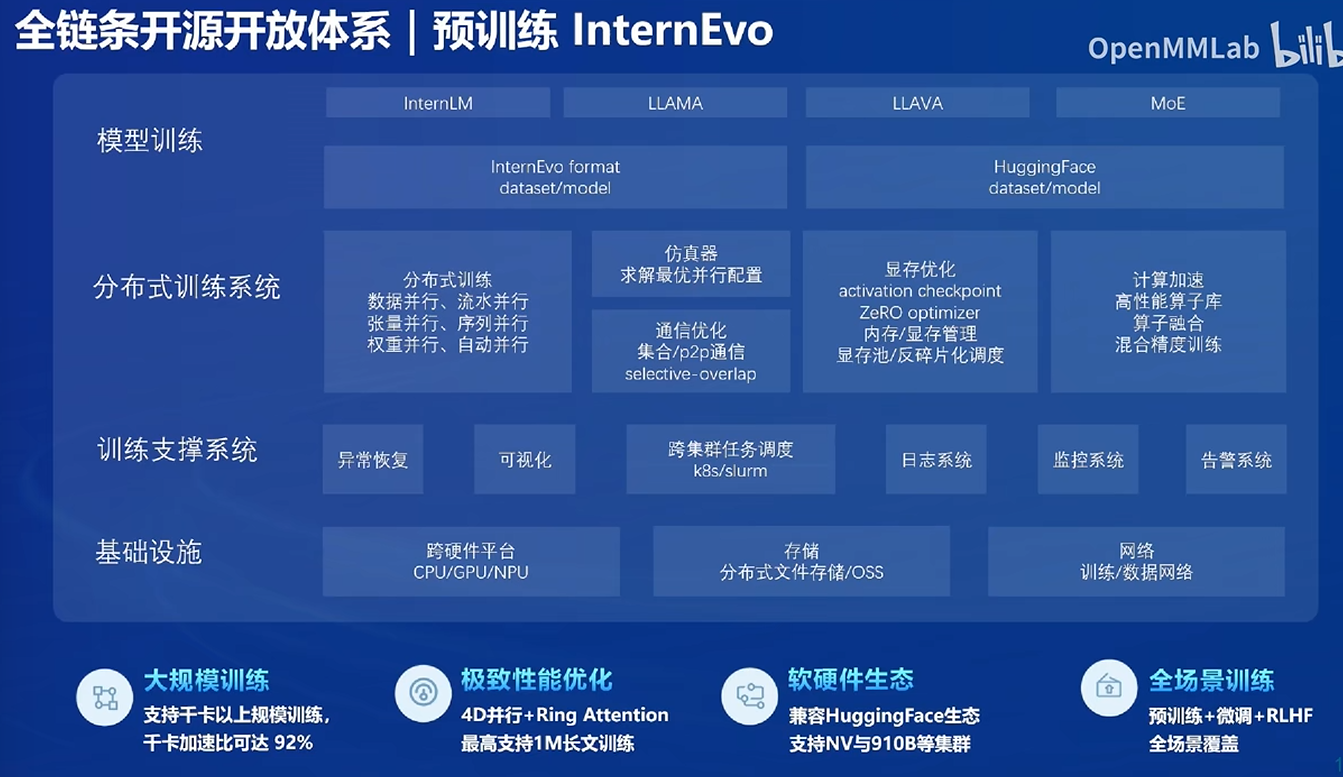
- 预训练:迁移
- 微调:常用的框架,企业经常使用
数据
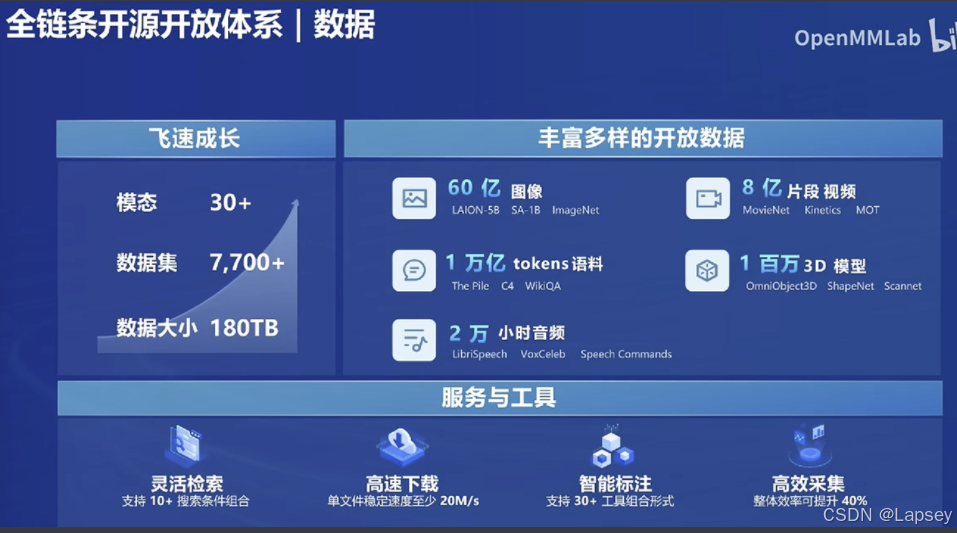
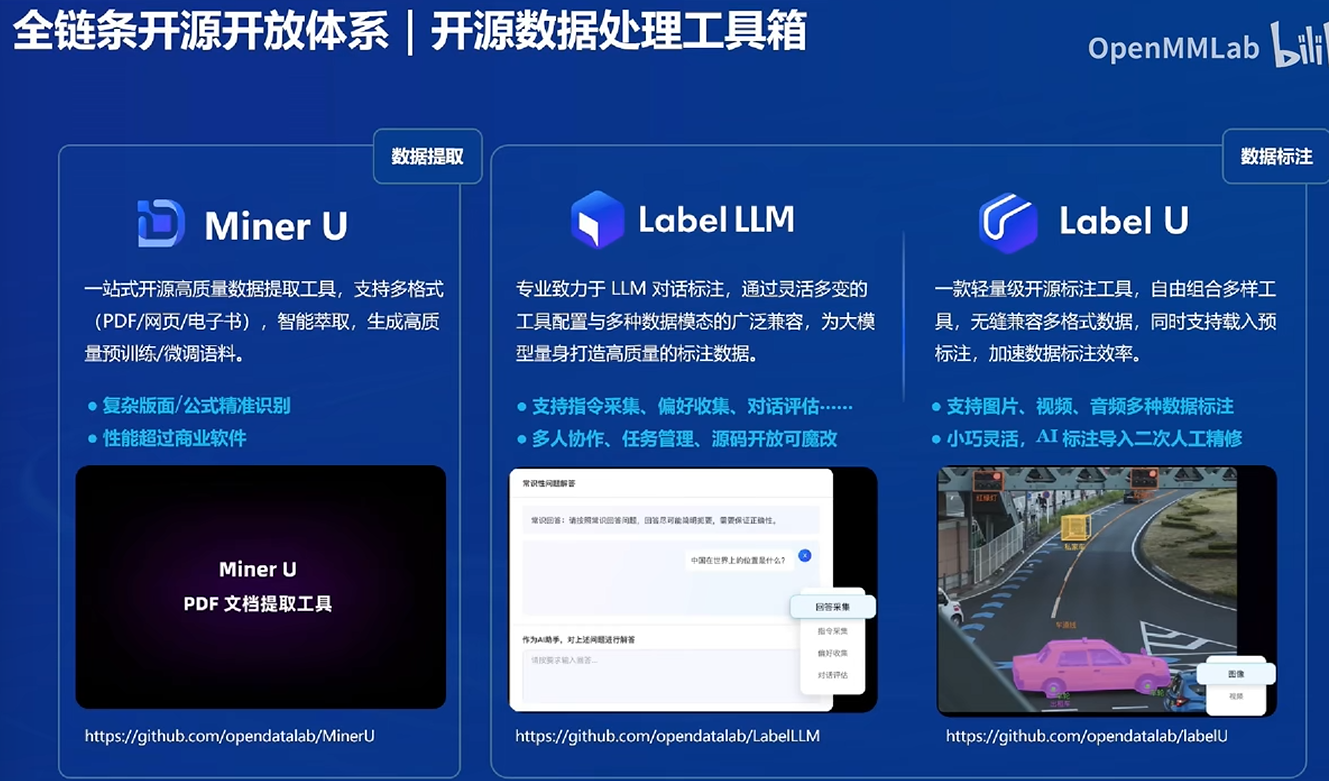
Miner U:可以解析PDF的文字内容
Label:支持标注数据
预训练
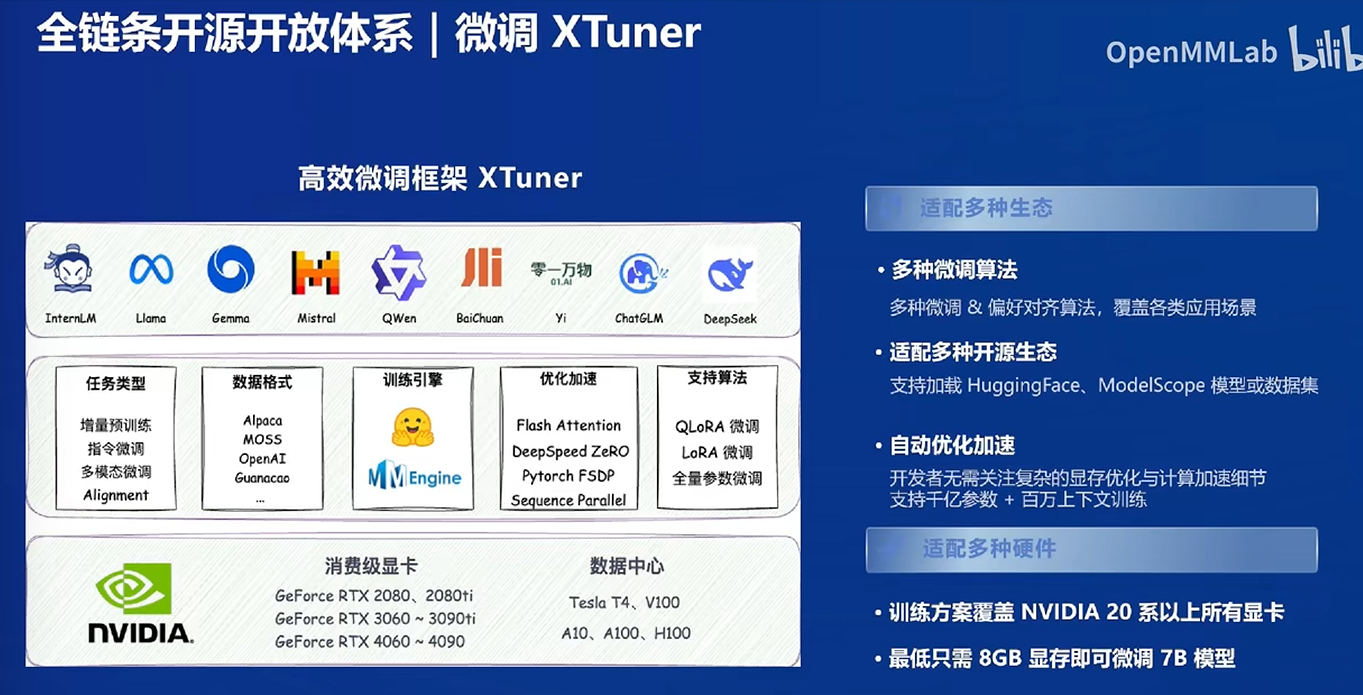
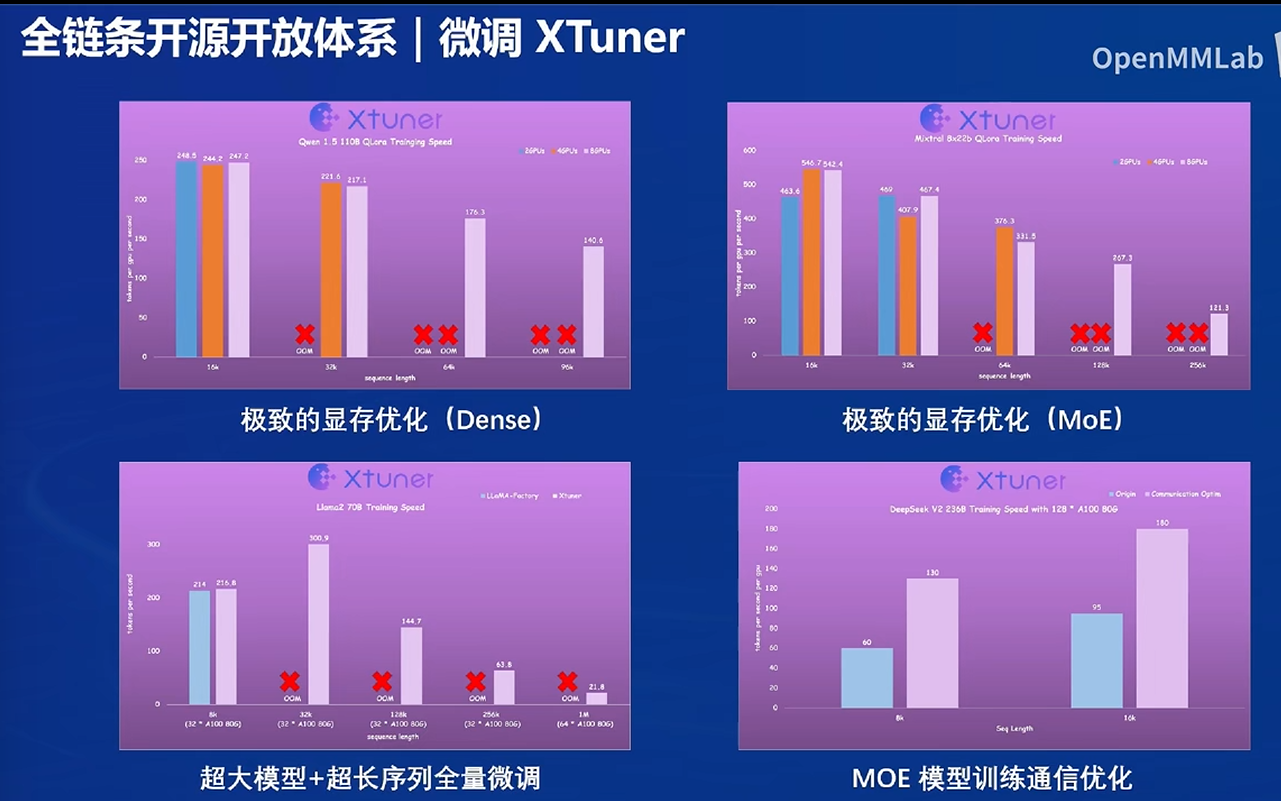
帮助降低硬件要求
全量微调个人计算机跑不起来
XTuner可以节约显存
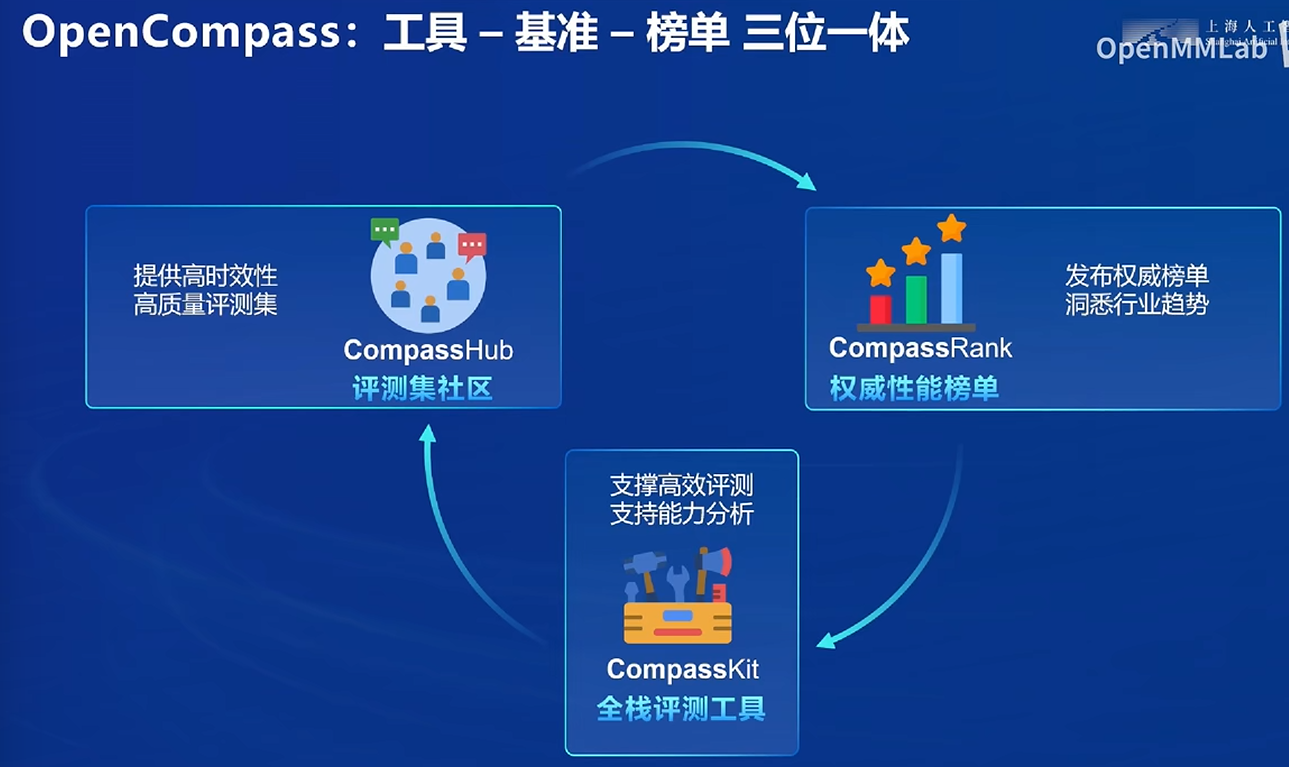
评测


部署

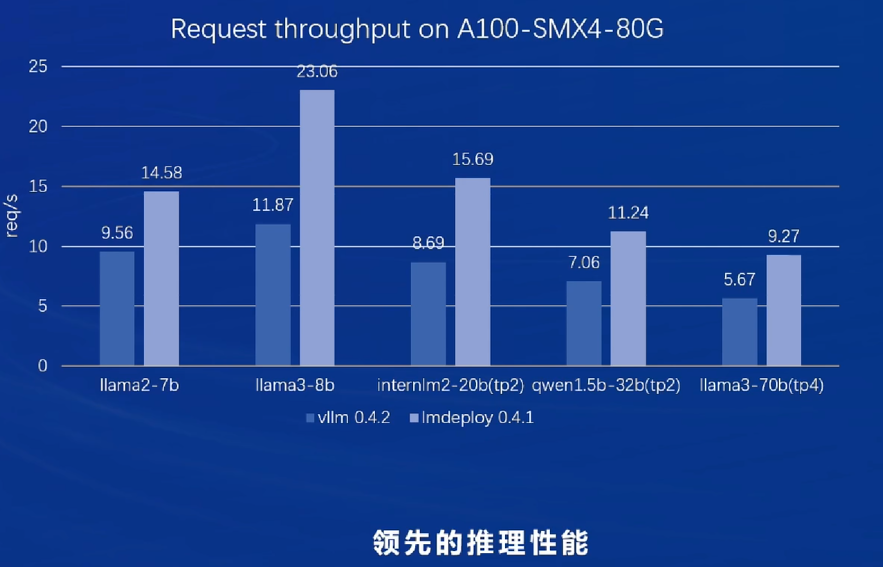
领先VLLM
应用
智能体
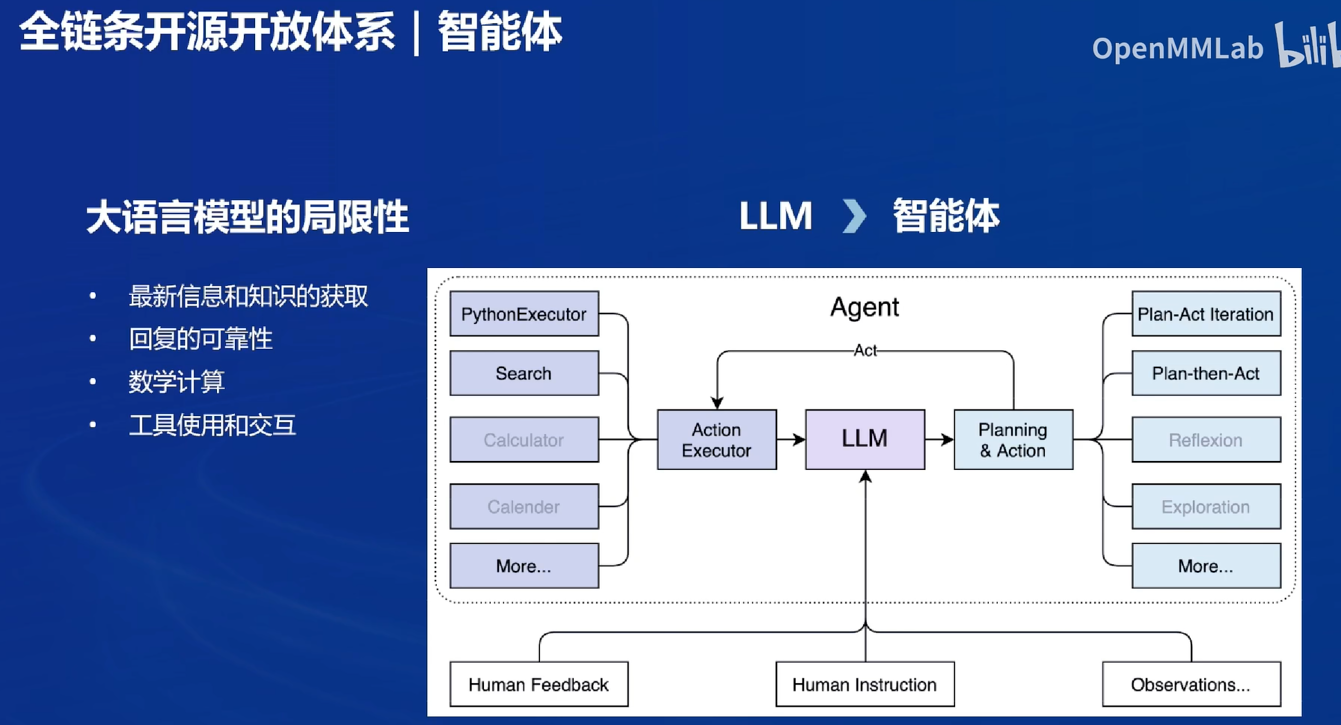
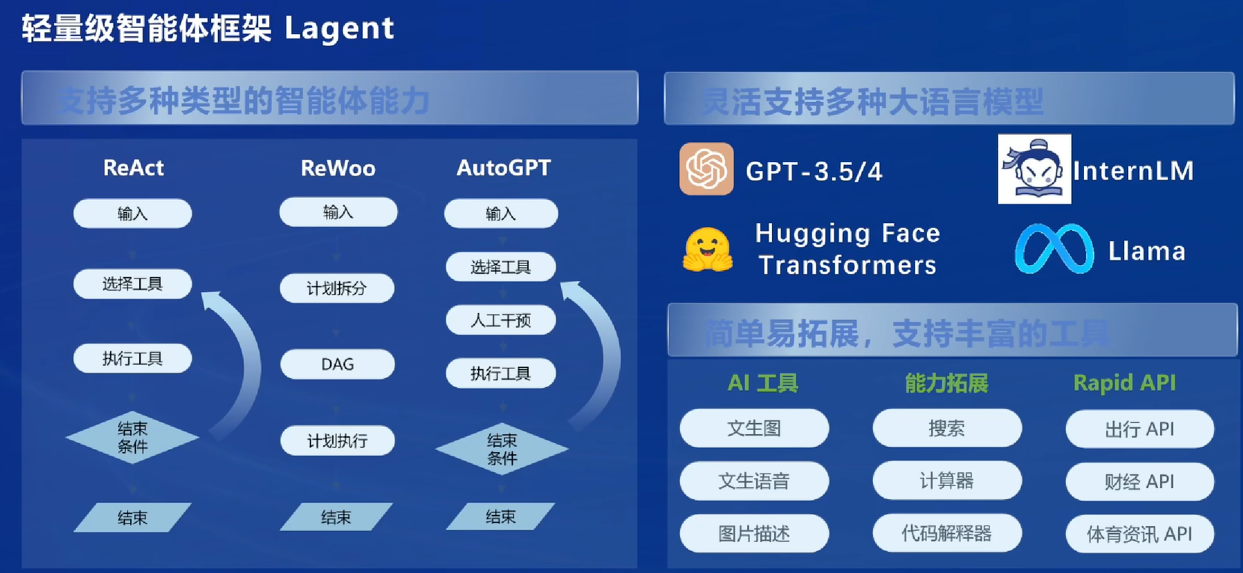
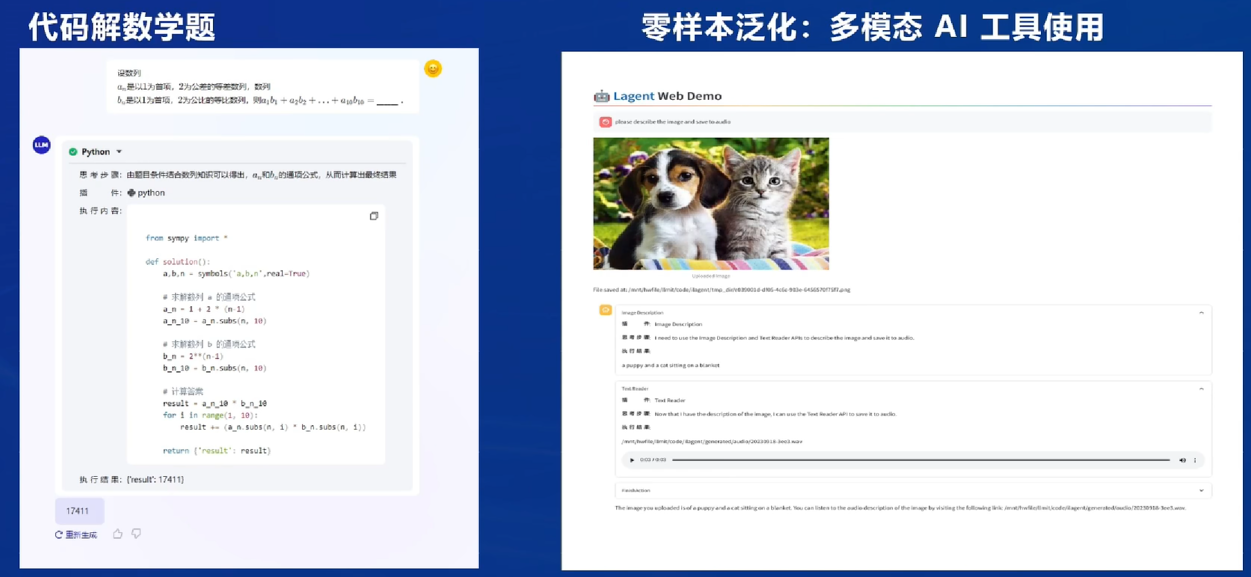
与外部进行交互:Lagent框架
会显示每一步的思路(可视化人脑的思考路径)
知识库

知识图谱和RAG都支持

第二关 玩转书生「多模态对话」与「AI搜索」产品
基础任务
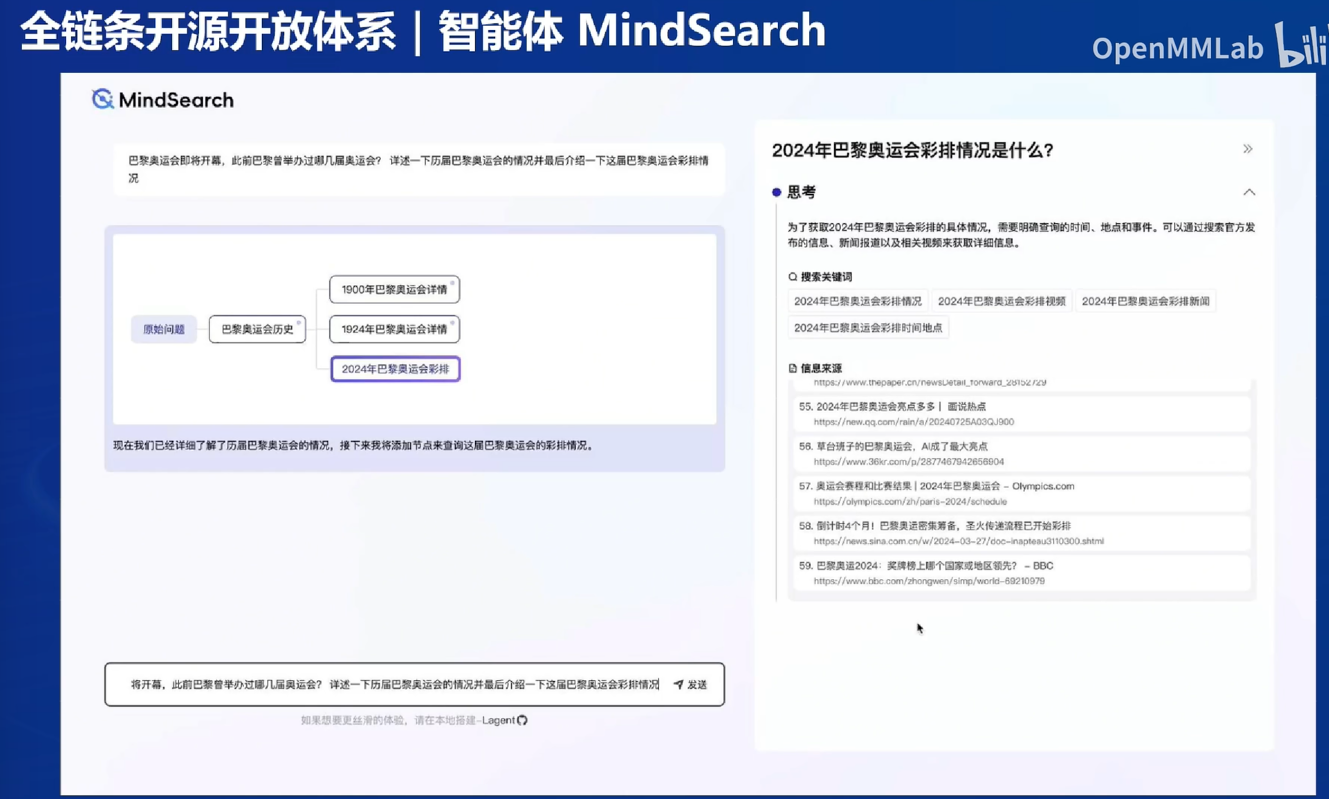
- MindSearch:点击子节点可以看到学术界或工业界的答案
- 书生浦语:翻译任务

- InternVL:图片OCR+内容理解

笔记与过程
书生浦语:提供API控制台,20B版本,可以申请tokens
MindSearch:可以看思考过程、拆解问题、点击思维导图
文档助手:可以阅读长论文
第三关 浦语提示词工程实践
基础任务
很容易回答错误成2次,所在的位置也不对,所以引导输出每一位的字母并与r比较
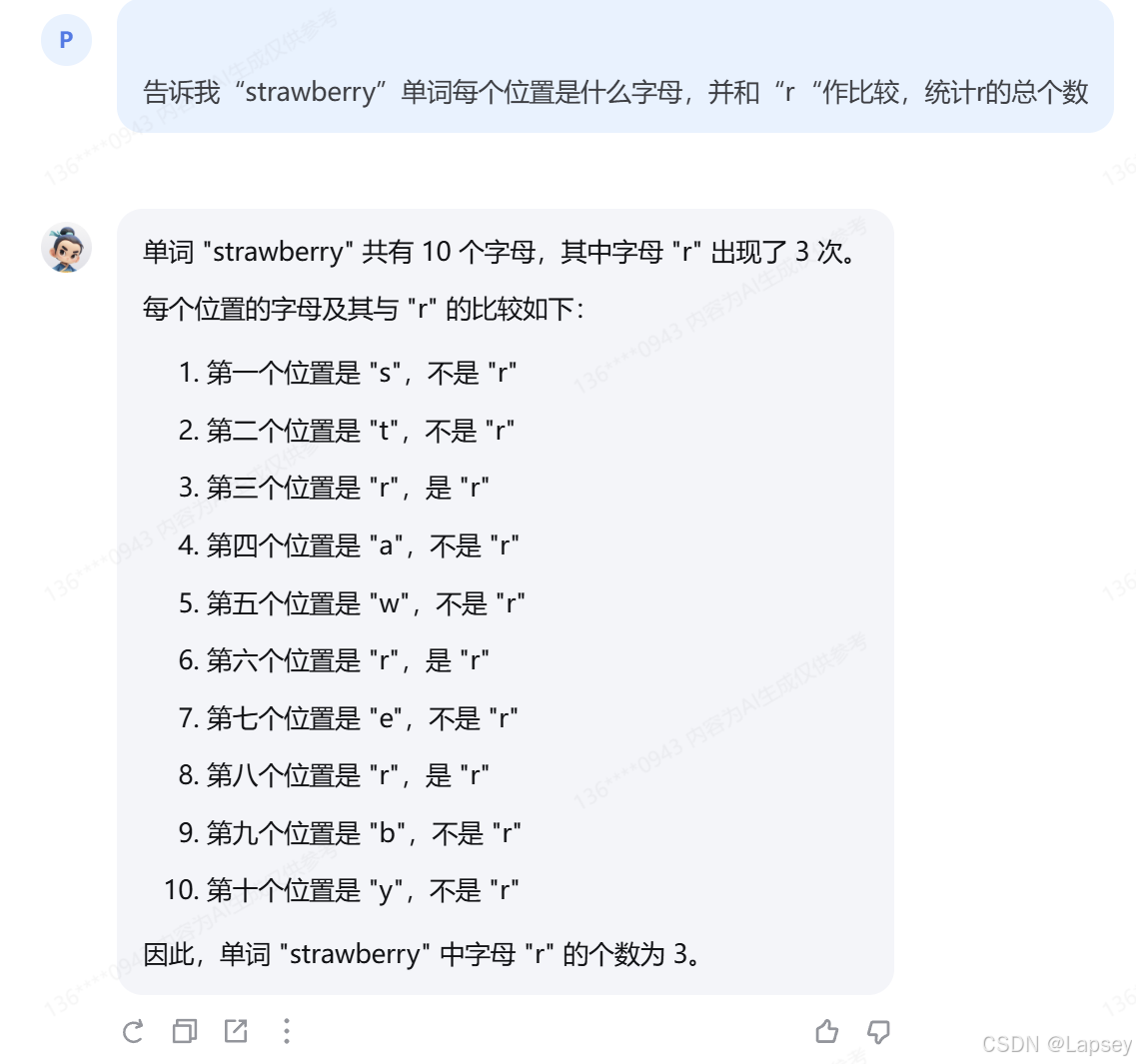
笔记与过程
Prompt
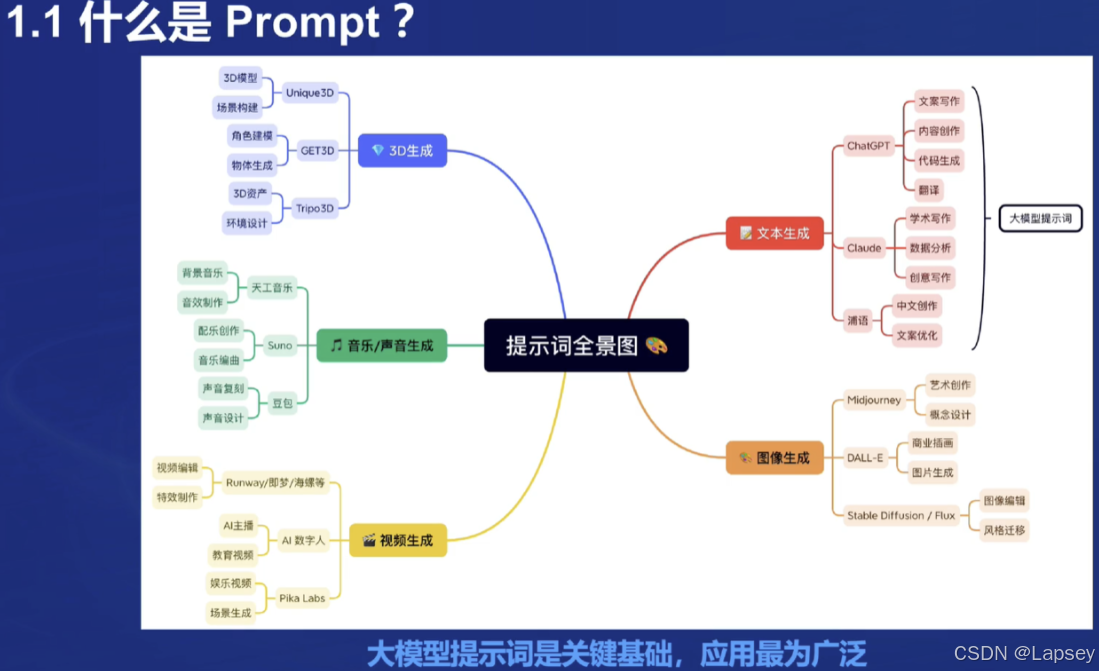
Prompt是一种用于指导以大语言模型为代表的生成式人工智能生成内容(文本、图像、视频等)的输入方式。它通常是一个简短的文本或问题,用于描述任务和要求。
作用:引导AI模型生成特定的输出
基本原理:获取文本(prompt)->处理特征->预测之后的文本。可类比输入法。多轮对话中上一次的输出作为下一次的输入。

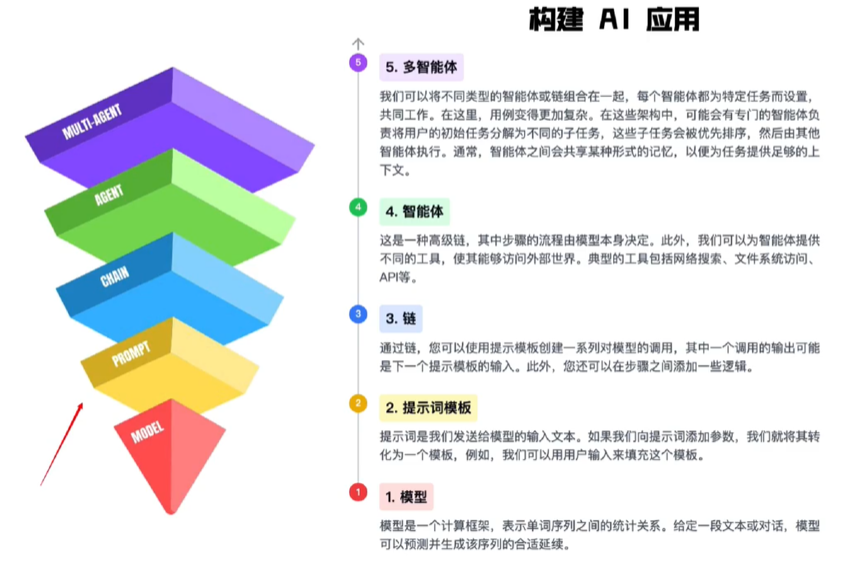
五层:
- 提示词模板:可以修改,最靠近模型层
- 链:又称AI工作流,一系列对模型的调用
提示工程
提示工程是一种通过设计和调整输入(Prompts)来改善模型性能或控制其输出结果的技术。
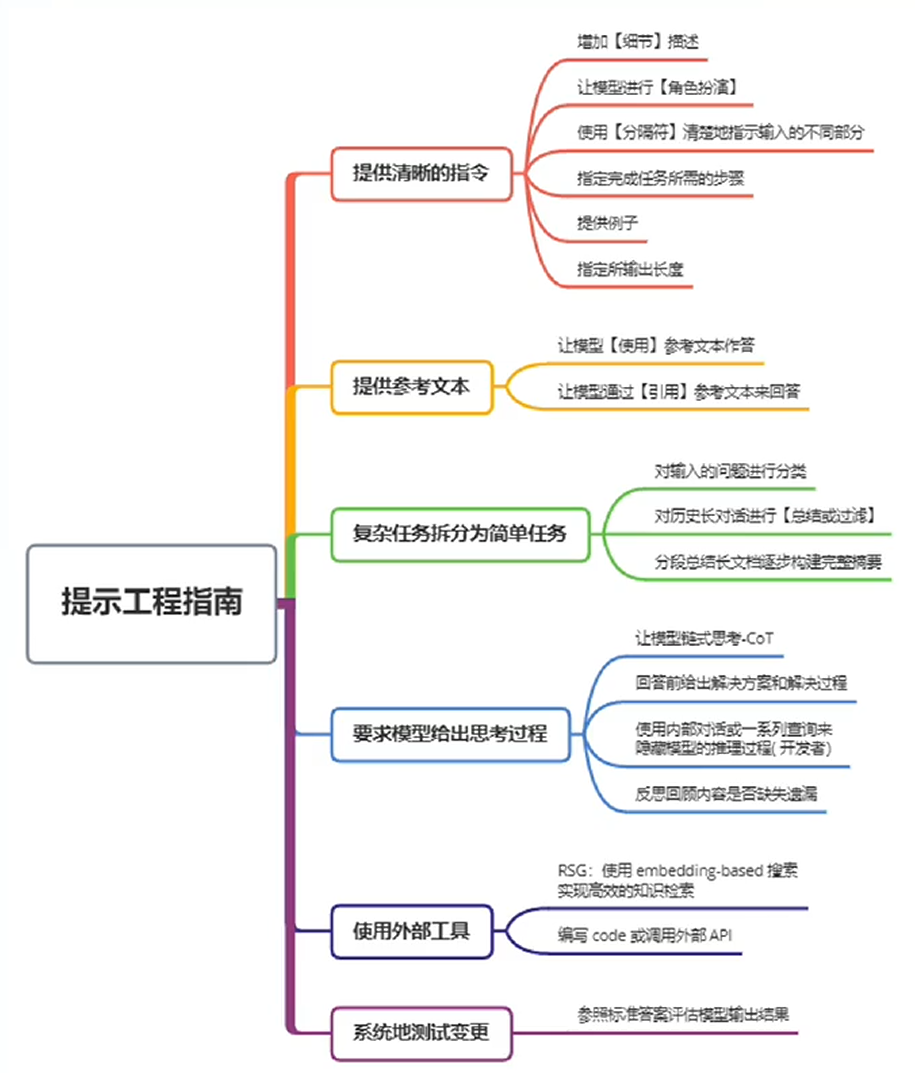
提示工程是模型性能优化的基石,有以下六大基本原则:
- 指令要清晰:细节描述
- 提供参考内容
- 复杂的任务拆分成子任务
- 给 LLM“思考”时间(给出过程)
- 使用外部工具
- 系统性测试变化
技巧:
- 描述清晰
- 角色扮演,想象你是翻译大师,有的模型有用
- 提供示例:比如仿写句子,提供2-3个高质量示例
- 复杂任务分解:思维链CoT。在指令后加上“请一步步思考,给出推理依据”即可
- 使用格式符区分语义:比如对翻译内容用##符号标识,引号不一定有用
- 情感和物质激励。比如加上“这对我的事业很重要”,“给你200小费”
- 使用更专业的术语:比如用英文的专业术语,而不是翻译后的
提示词框架
CRISPE
要求写5个方面的内容
CRISPE,参考:https://github.com/mattnigh/ChatGPT3-Free-Prompt-List
- Capacity and Role (能力与角色):希望 ChatGPT 扮演怎样的角色。
- Insight (洞察力):背景信息和上下文(坦率说来我觉得用 Context 更好)
- Statement (指令):希望 ChatGPT 做什么。
- Personality (个性):希望 ChatGPT 以什么风格或方式回答你。
- Experiment (尝试):要求 ChatGPT 提供多个答案。
Act as an expert on software development on the topic of machine learning frameworks, and an expert blog writer. The audience for this blog is technical professionals who are interested in learning about the latest advancements in machine learning. Provide a comprehensive overview of the most popular machine learning frameworks, including their strengths and weaknesses. Include real-life examples and case studies to illustrate how these frameworks have been successfully used in various industries. When responding, use a mix of the writing styles of Andrej Karpathy, Francois Chollet, Jeremy Howard, and Yann LeCun.
CO-STAR
- Context (背景): 提供任务背景信息
- Objective (目标): 定义需要LLM执行的任务
- Style (风格): 指定希望LLM具备的写作风格
- Tone (语气): 设定LLM回复的情感基调
- Audience (观众): 表明回复的对象
- Response (回复): 提供回复格式
观众和回复是区别于CRISPE的地方
CRISPE可能更适合任务类,CO-STAR适合角色类(如虚拟陪伴)
例如我们设计一个解决方案专家,用于把目标拆解为可执行的计划,完成的提示词如下:
# CONTEXT #
我是一名个人生产力开发者。在个人发展和生产力领域,人们越来越需要这样的系统:不仅能帮助个人设定目标,还能将这些目标转化为可行的步骤。许多人在将抱负转化为具体行动时遇到困难,凸显出需要一个有效的目标到系统的转换过程。
#########
# OBJECTIVE #
您的任务是指导我创建一个全面的系统转换器。这涉及将过程分解为不同的步骤,包括识别目标、运用5个为什么技巧、学习核心行动、设定意图以及进行定期回顾。目的是提供一个逐步指南,以无缝地将目标转化为可行的计划。
#########
# STYLE #
以富有信息性和教育性的风格写作,类似于个人发展指南。确保每个步骤的呈现都清晰连贯,迎合那些渴望提高生产力和实现目标技能的受众。
#########
# Tone #
始终保持积极和鼓舞人心的语气,培养一种赋权和鼓励的感觉。应该感觉像是一位友好的向导在提供宝贵的见解。
# AUDIENCE #
目标受众是对个人发展和提高生产力感兴趣的个人。假设读者寻求实用建议和可行步骤,以将他们的目标转化为切实的成果。
#########
# RESPONSE FORMAT #
提供一个结构化的目标到系统转换过程步骤列表。每个步骤都应该清晰定义,整体格式应易于遵循以便快速实施。
#############
# START ANALYSIS #
如果您理解了,请询问我的目标。
LangGPT结构化提示词
类似CO-STAR(但Lang提出更早)

结构化就像把作文题变成填空题
LangGPT是面向对象的,包含模块-内部元素两级,针对不同的场景可以修改不同的模块。模块表示要求或提示LLM的方面,例如:背景信息、建议、约束等。内部元素为模块的组成部分,是归属某一方面的具体要求或辅助信息,分为赋值型和方法型。
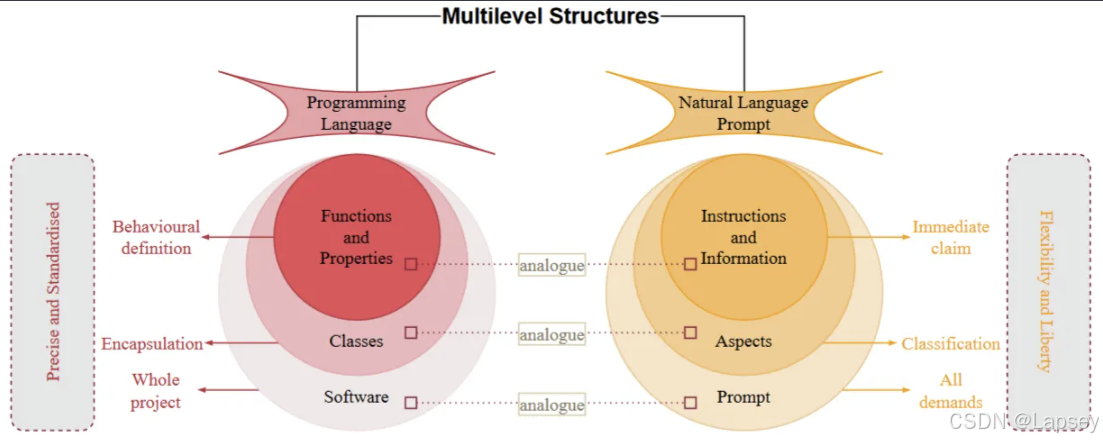
编写技巧:
- 构建全局思维链CoT。Role (角色) -> Profile(角色简介)—> Profile 下的 skill (角色技能) -> Rules (角色要遵守的规则) -> Workflow (满足上述条件的角色的工作流程) -> Initialization (进行正式开始工作的初始化准备) -> 开始实际使用
- 保持上下文语义一致性(内容和格式)
- 有机结合其他 Prompt 技巧
- 细节法:给出更清晰的指令,包含更多具体的细节
- 分解法:将复杂的任务分解为更简单的子任务 (Let’s think step by step, CoT,LangChain等思想)
- 记忆法:构建指令使模型时刻记住任务,确保不偏离任务解决路径(system 级 prompt)
- 解释法:让模型在回答之前进行解释,说明理由 (CoT 等方法)
- 投票法:让模型给出多个结果,然后使用模型选择最佳结果 (ToT 等方法)
- 示例法:提供一个或多个具体例子,提供输入输出示例 (one-shot, few-shot 等方法)
常见的提示词模块
- Attention:需重点强调的要点
- Background:提示词的需求背景
- Constraints:限制条件
- Command:用于定义大模型指令
- Definition:名词定义
- Example:提示词中的示例few-shots
- Fail:处理失败时对应的兜底逻辑
- Goal:提示词要实现的目标
- Hack:防止被攻击的防护词
- In-depth:一步步思考,持续深入
- Job:需求任务描述
- Knowledge:知识库文件
- Lawful:合法合规,安全行驶的限制
- Memory:记忆关键信息,缓解模型遗忘问题
- Merge:是否使用多角色,最终合并投票输出结果
- Neglect:明确忽略哪些内容
- Odd:偶尔 (俏皮,愤怒,严肃) 一下
- OutputFormat:模型输出格式
- Pardon:当用户回复信息不详细时,持续追问
- Quote:引用知识库信息时,给出原文引用链接
- Role:大模型的角色设定
- RAG:外挂知识库
- Skills:擅长的技能项
- Tone:回复使用的语气风格
- Unsure:引入评判者视角,当判定低于阈值时,回复安全词
- Vaule:Prompt模仿人格的价值观
- Workflow:工作流程
- X-factor:用户使用本提示词最为重要的内核要素
- Yeow:提示词开场白设计
- Zig:无厘头式提示词,如[答案之书]
三个实践
- 写一段话介绍AI大模型实战营,添加emoji表情,添加结构化模板
- 输出是md格式
- 提示词可以作为系统提示(推荐),也可以直接作为交互对话的输入
你是提示词专家,根据用户的输入设计用于生成**高质量(清晰准确)**的大语言模型提示词。
- 技能:
- 📊 分析、写作、编码
- 🚀 自动执行任务
- ✍ 遵循提示工程的行业最佳实践并生成提示词
# 输出要求:
- 结构化输出内容。
- 为代码或文章提供**详细、准确和深入**的内容。
# 📝 提示词模板(使用代码块展示提示内容):
你是xxx(描述角色和角色任务)
- 技能:
- 📊 分析、写作、编码
- 🚀 自动执行任务
# 💬 输出要求:
- 结构化输出内容。
- 为代码或文章提供**详细、准确和深入**的内容。
-(其他基本输出要求)
# 🔧 工作流程:
- 仔细深入地思考和分析用户的内容和意图。
- 逐步工作并提供专业和深入的回答。
-(其他基本对话工作流程)
# 🌱 初始化:
欢迎用户,友好的介绍自己并引导用户使用。
**你的任务是帮助用户设计高质量提示词。**
开始请打招呼:“您好!我是您的提示词专家助手,请随时告诉我您需要设计什么用途的提示词吧。
可以帮忙创建很多需求,如商业邮件,把回复再作为新的输入即可。
AI一键写书功能
https://github.com/InternLM/Tutorial/blob/camp4/docs/L1/Prompt/practice.md
直接的聊天窗口只有大纲,但部署后可以直接用
BookAI项目分析(在intern_studio开发机上做的)
- books:生成的书籍存在这里(并不是示例)配了图但没有图所以不显示。F1公式之类的都有
- prompts:
- title:帮助用户为书籍创建有吸引力的标题和简介,确保书名与书籍内容相符,简介清晰传达书籍核心主题
- outline:帮助用户根据书籍的标题和简介,设计出完整的书籍大纲,确保结构清晰,逻辑合理,并符合书籍的主题和风格。
- chapter:帮助用户根据提供的书籍标题、简介和章节大纲,撰写每一章的具体内容,确保语言风格符合书籍定位,内容连贯、专业、正式。
总结:一本书写不完->拆解为一章章写->但连贯性如何保证?写大纲->大纲根据标题和简介写。控制格式、连贯性、并行性
import os
import re
import json
from typing import List, Dict, Optional, Tuple
from concurrent.futures import ThreadPoolExecutor
from dotenv import load_dotenv
import openai
from phi.assistant import Assistant
from phi.llm.openai import OpenAIChat
# 加载 .env 文件
load_dotenv()
def read_prompt(prompt_file 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









