







Spark Streaming实时写入HBase
0–适用框架
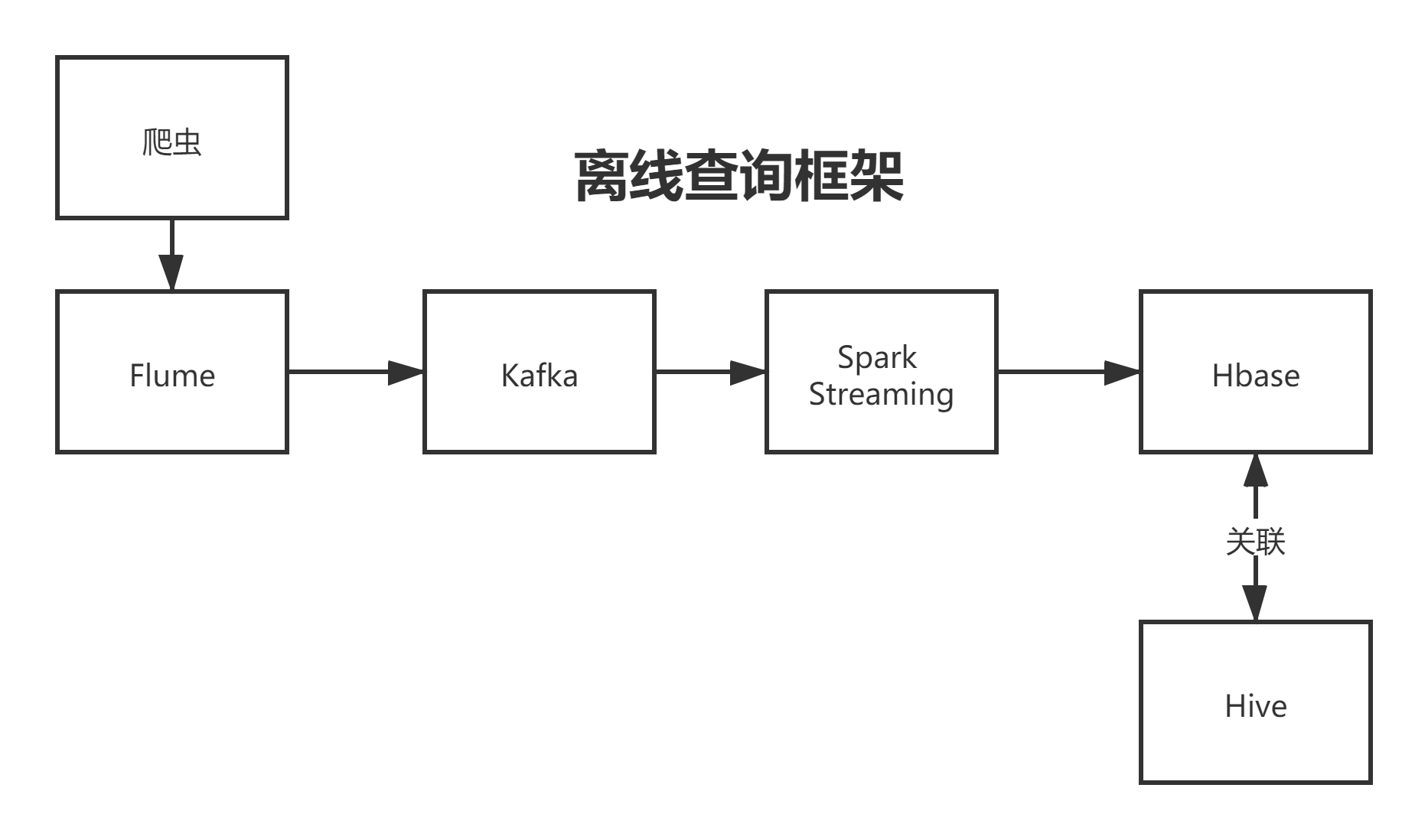
1-代码解析
1-1 Kafka部分
//定义一个主题数组,内可包含多个主题,此处只有一个
val kafkaTopic = Array("mytopic")
//bootstrap.servers kafka的服务节点和端口号,用于连接kafka
//key.deserializer 网络传输要序列化对吧,接受则要反序列化,这里指定反序列化的类
//value.deserializer 指定反序列化的类
//group.id 消费者组ID,ID相同的消费者在同一个组
//enable.auto.commit kafka是否自动提交偏移量,这里填否,交由Spark管理
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> "server1:9092,server2:9092,server3:9092",
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"->classOf[StringDeserializer],
"group.id"->"1",
"enable.auto.commit"->(false : java.lang.Boolean)
)
//将Kafka主题的信息转为Dstream
val inputStream:InputDStream[ConsumerRecord[String,String]]= KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent, Subscribe[String,String](kafkaTopic,kafkaParams))
//只要其中的value值
val dataDStream = inputStream.map(record =>(record.key,record.value)).map(_._2)
1-2 Hbase部分
转储外部数据库的正确方式应该为以下两种
一、
通常,创建连接对象有时间和资源开销。因此,为每条记录创建和销毁连接对象可能会产生不必要的高开销,并且会显着降低系统的整体吞吐量。更好的解决方案是使用 rdd.foreachPartition- 创建单个连接对象并使用该连接发送 RDD 分区中的所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这分摊了许多记录的连接创建开销。
二、
最后,这可以通过跨多个 RDD/batch 重用连接对象来进一步优化。可以维护一个静态的连接对象池,当多个批次的 RDD 被推送到外部系统时可以重用,从而进一步减少开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
三、
所以HBase部分代码应该如下,怎么清洗的数据可以看博主的爬虫篇,这里不作赘述
dataDStream.foreachRDD{y=>y.foreachPartition {k=>
//hbase配置
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum","10.206.0.6,10.206.0.7,10.206.0.17")
hbaseConf.set("hbase.property.clientPort","2181")
val tableName = TableName.valueOf("StockInfo")
val conn = ConnectionFactory.createConnection(hbaseConf)
val table = conn.getTable(tableName)
//加载列表
val list = new java.util.ArrayList[Put]
k.foreach{x=>
//清洗数据
val data = parseObject(x).getJSONObject("data")
val market = data.getString("market")
val code = data.getString("code")
val name = data.getString("name")
val day_klines = data.getJSONArray("klines")
day_klines.forEach{data=>{
val s = data.toString.split(",")
val date = s(0)
val open = s(1)
val end = s(2)
val highest = s(3)
val lowest = s(4)
val ts = s(5)
val tn = s(6)
val zf = s(7)
val zdf = s(8)
val zde = s(9)
val ch= s(10)
//确认字段
val putin = new Put(Bytes.toBytes(market+"."+code+"."+date))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockname"), Bytes.toBytes(name))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockmarket"), Bytes.toBytes(market))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockcode"), Bytes.toBytes(code))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockdate"), Bytes.toBytes(date))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockopen"), Bytes.toBytes(open))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockend"), Bytes.toBytes(end))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("highest"), Bytes.toBytes(highest))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("lowest"), Bytes.toBytes(lowest))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("ts"), Bytes.toBytes(ts))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("tn"), Bytes.toBytes(tn))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zf"), Bytes.toBytes(zf))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zdf"), Bytes.toBytes(zdf))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zde"), Bytes.toBytes(zde))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("ch"), Bytes.toBytes(ch))
//加进列表
list.add(putin)
}}}
//加载
try{
Try(table.put(list)).getOrElse(table.close())
}catch {
case e:Exception=>e.printStackTrace()
}finally {
/*
最后别忘了关闭连接,否则集群资源将会耗尽,
Hbase的zookeeper节点连接数到达一定数量也会拒绝你连接
忘记关闭连接的结果就是,最后Spark Streaming连接不上HBase了
导致失败
*/
table.close()
conn.close()
}
}}
2-代码源码
package ln
import com.alibaba.fastjson.JSON.parseObject
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{BufferedMutatorParams, ConnectionFactory, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.streaming._
import org.apache.spark.SparkConf
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import java.util.concurrent.ExecutorService
import scala.util.Try
object SparkStreamTest {
Logger.getLogger("org").setLevel(Level.ERROR);
def main(args: Array[String]): Unit = {
//spark配置
println("2021-10-23 09:39:09")
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("StreamingKafkaTest")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint("hdfs://server2:9000/spark-checkpoint")
//kafka配置
val kafkaTopic = Array("mytopic")
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> "server1:9092,server2:9092,server3:9092",
"key.deserializer"->classOf[StringDeserializer],
"value.deserializer"->classOf[StringDeserializer],
"group.id"->"1",
"enable.auto.commit"->(false : java.lang.Boolean)
)
val inputStream:InputDStream[ConsumerRecord[String,String]]= KafkaUtils.createDirectStream[String,String](ssc, LocationStrategies.PreferConsistent, Subscribe[String,String](kafkaTopic,kafkaParams))
val dataDStream = inputStream.map(record =>(record.key,record.value)).map(_._2)
//清洗加载
dataDStream.foreachRDD{y=>y.foreachPartition {k=>
//hbase配置
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum","10.206.0.6,10.206.0.7,10.206.0.17")
hbaseConf.set("hbase.property.clientPort","2181")
val tableName = TableName.valueOf("StockInfo")
val conn = ConnectionFactory.createConnection(hbaseConf)
val table = conn.getTable(tableName)
//加载列表
val list = new java.util.ArrayList[Put]
k.foreach{x=>
//清洗数据
val data = parseObject(x).getJSONObject("data")
val market = data.getString("market")
val code = data.getString("code")
val name = data.getString("name")
val day_klines = data.getJSONArray("klines")
day_klines.forEach{data=>{
val s = data.toString.split(",")
val date = s(0)
val open = s(1)
val end = s(2)
val highest = s(3)
val lowest = s(4)
val ts = s(5)
val tn = s(6)
val zf = s(7)
val zdf = s(8)
val zde = s(9)
val ch= s(10)
//确认字段
val putin = new Put(Bytes.toBytes(market+"."+code+"."+date))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockname"), Bytes.toBytes(name))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockmarket"), Bytes.toBytes(market))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockcode"), Bytes.toBytes(code))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockdate"), Bytes.toBytes(date))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockopen"), Bytes.toBytes(open))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("stockend"), Bytes.toBytes(end))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("highest"), Bytes.toBytes(highest))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("lowest"), Bytes.toBytes(lowest))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("ts"), Bytes.toBytes(ts))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("tn"), Bytes.toBytes(tn))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zf"), Bytes.toBytes(zf))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zdf"), Bytes.toBytes(zdf))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("zde"), Bytes.toBytes(zde))
putin.addColumn(Bytes.toBytes("info"), Bytes.toBytes("ch"), Bytes.toBytes(ch))
//加进列表
list.add(putin)
}}}
//加载
try{
Try(table.put(list)).getOrElse(table.close())
}catch {
case e:Exception=>e.printStackTrace()
}finally {
table.close()
conn.close()
}
}}
dataDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
3-pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkProgram</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.12.10</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.12</version>
</dependency>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
<!--...............................................................................................................-->
<!--以上是基础依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.4.13</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.4.13</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











