






如何使用倒排索引和基本布尔检索模型来处理一个查询呢?
先以一个简单“ 与” 查询(
simple conjunctive query
)为例:
Brutus AND Calpurnia.
可以使用图
1-3
所示的倒排索引进行如下操作:
(1) 在词典中定位 Brutus;
(2) 返回其倒排记录表;
(3) 在词典中定位Calpurnia;
(4) 返回其倒排记录表;
(5) 对两个倒排记录表求交集,如图1-5 所示。

在这里,交集(intersection)操作非常关键,必须快速将倒排记录表求交集以尽快找到哪些文档同时包括两个词项.

该算法对于倒排记录表集(即待合并的两个倒排记录表)的大小而言是线性的.
每一步比较两个位置指针所指向的文档
ID
,如果两者一样,则将该
ID
输出到结果表中,然后同时将两个指针后移一位。
如果两个文档
ID
不同,则将较小的
ID
所对应的指针后移。
假设两个倒排记录表的大小分别是
x
和
y
,那么上述求交集的过程需要
O(
x+y
)
次操作。
查询的时间复杂度为Θ(N),其中N 是文档集合中文档的数目
和线性扫描相比,这种索引方法并没有带来Θ意义上时间复杂度的提高,而最多只是一个常数级别的变化.
但是,实际当中这个常数很大。如果要使用上述合并算法,那么倒排记录表必须按照全局的统一指标进行排序。通过文档
ID
的数值进行排序是一个简单的实现方法。
可以对上述合并算法进行扩展,使之能够用于处理更复杂的查询:
(Brutus OR Caesar) AND NOT Calpurnia
查询优化(
query optimization
)指的是如何通过组织查询的处理过程来使处理工作量最小
.
对布尔查询进行优化要考虑的一个主要因素是倒排记录表的访问顺序。
考虑一个对多个词项进行“ 与” 操作的查询
,
例如:
Brutus AND Caesar AND
Calpurnia
.
对每个词项,必须取出其对应的倒排记录表,然后将它们合并。
一个
启发式
的
想法
是,按照词项的文档频率(也就是倒排记录表的长度)从小到大依次进行处理
,
如果先合并两个最短的倒排记录表,那么所有中间结果的大小都不会超过最短的倒排记录表
.
因此,对于图
1-3
对应的倒排记录表将按照如下顺序来处理查询(
1-3
):
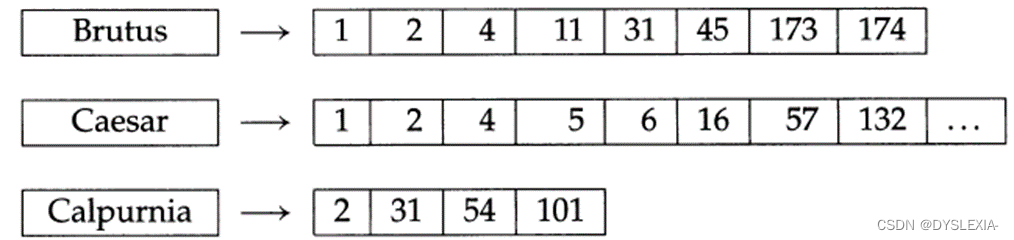
(Calpurnia AND Brutus) AND Caesar
这也给出了在词典中保存文档频率的一个充分理由,即它可以在访问之前用于决定倒排记录表的访问次序。

















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











