






易错点
sql三范式
- 第一范式(1NF):确保每个列都是不可分割的原子值。
- 第二范式(2NF):在满足1NF的基础上,确保每个非主键列完全依赖于主键。
- 第三范式(3NF):在满足2NF的基础上,确保每个非主键列直接依赖于主键,不存在传递依赖
3,类成员函数可以不写形参,在函数内使用类成员变量。不然的话,在main函数中new一个对象后,调用函数还得传入形参,这样的话对象中的形参其实就没有用上。
private:
T a;
T b;
public:
Calculator(T a, T b) :a(a), b(b) {};
T addFun() {
return a + b;
}
T jianFun() {
return a - b;
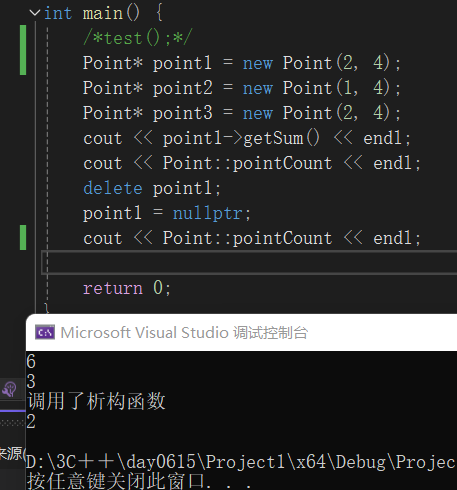
}4,在这个程序中要想在main函数看到析构函数的效果就得用new来创建对象,如果单独创建一个函数来创建对象,那这些对象是在栈中
void test() {
Point point01(2, 4);
Point point02(3, 4);
Point point03(2, 8);
Point point04(2, 9);
cout << point01.getSum() << endl;
cout << Point::pointCount << endl;
}
int main() {
test();
/*Point* point1 = new Point(2, 4);
Point* point2 = new Point(1, 4);
Point* point3 = new Point(2, 4);
cout << point1->getSum() << endl;
cout << Point::pointCount << endl;
delete point1;
point1 = nullptr;
cout << Point::pointCount << endl;*/
return 0;
}
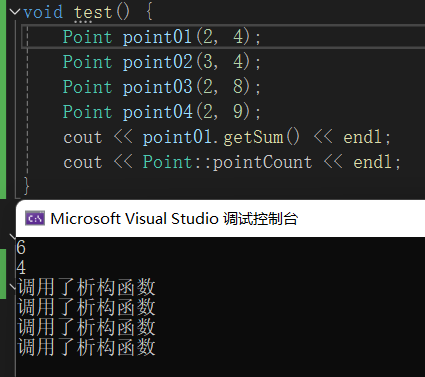
5,匿名对象
匿名对象,创建出来立马就会被构造与析构,所以这里count的值为0;如果使用另外的方式创建对象,那么count就会加1,因为其他对象析构函数要等到test结束才析构。
static int pointCount;
Point(int x,int y) :x(x),y(y){
cout << "调用了构造函数" << endl;
pointCount++;
}
~Point() {
pointCount--;
cout << "调用了析构函数" << endl;
}
};
int Point::pointCount = 0;
void test() {
Point(10, 17);//匿名对象
cout << Point::pointCount << endl;
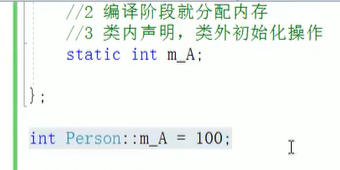
}6,static成员变量
类内声明,类外初始化
7,只有非静态成员变量在类的对象上,其他的都是和对象分开存储的。
8,对象直接访问不了私有成员变量,但是声明一个友元函数后,就可以通过友元函数直接访问到。还不用通过get()函数。
9,advance()
//68 55 47 44 29 8 5 3 1
list<int>::iterator it = L3.begin();
advance(it, 2);
L3.insert(it, 4);
printList(L3);
advance(it, 4);
cout << *it << endl;10,禁用类的默认拷贝和赋值运算符
struct NoCopy{
NoCopy()=default; //使用合成的默认构造函数
NoCopy(const NoCopy&)=delete; //阻止拷贝
NoCopy &operator=(const NoCopy&)=delete; //阻止赋值
~NoCopy()=default; //使用合成的析构函数
};11,引用的本质是一个指针常量
复习
1,sizeof(a) 获取 a 变量占用内存大小(内存占用的字节个数),但要用无符号long值,%lu来接收
unsigned long l2 = sizeof(int);
printf("l2=%lu \n",l2);//在内存占用4个字节2,我们直接书写的小数常量,如 6.23,系统默认看做 double 类型。如想指明为 float 类型,需加后缀 f,6.23f。
3,
//不够位数要求补0, %0m.nf表示一共展示m位,小数有n位,不够m位的整数前面补0
printf("f2=%020.16f \n",f2);//float整数部分+小数部分 超过6位就不精确了
printf("d2=%020.16lf \n",d2);//double 整数部分+小数部分 超过15位就不精确了4,
//2.转义符 C 语言提供了一类特殊的字符,是由 \ 和特定字符组合而成,称之为 转义字符。 \
/* 2.1 在特定情况下还原其本意 \ */
printf("\\ \n"); //反斜杠本身
printf("\' \n"); //单引号
printf("\" \n"); //双引号
printf("\n");//换行
printf("\t \n");//制表符
printf("-----\n");
printf("\b \n");//退格符 (Backspace键)
// \ddd 8进制,打印的结果ASCII对应的值
printf("\141 \n");//a 就是十进制的97 ASCII对应的值
// -'\xhh' 16进制,打印的结果ASCII对应的值
printf("\x41");//A 就是十进制的65 ASCII对应的值 5,

sizeof()
括号里可以放变量名或者数据类型,返回在内存中占用的字节数。通常用%lu做占位符接收。
数据类型
//带符号(有正负)
//1.1 short 短整型 范围:-32768 ~ 32767
short s1=-30000;
printf("short短整型:%hd\n",s1);
printf("short字节数:%lu\n",sizeof(short));//2个字节
//1.2 超出类型范围
//short s2=-40000;
//printf("short短整型:%hd\n",s2);
//2.int 整型,默认整数就是int
int i1=40000;
printf("int 整型:%d \n",i1);
printf("int字节数:%lu\n",sizeof(int));//4个字节
//3.long 长整型
long l1=3333333333;
printf("long 长整型:%ld \n",l1);
printf("long字节数:%lu\n",sizeof(long));//8个字节
//4.long long 长长整型
long long ll1=4333333333;
printf("long long 长长整型:%lld \n",ll1);
printf("long long字节数:%lu\n",sizeof(long long));//8个字节
//无符号 0~最大值(没有负数)
//5.unsigned short(无符号 短整型)
unsigned short s2=60000;
printf("unsigned short短整型:%hu\n",s2);
printf("unsigned short字节数:%lu\n",sizeof(unsigned short));//2个字节
//6.unsigned int(无符号 整型)
unsigned int i2=600000;
printf("unsigned int整型:%u\n",i2);
printf("unsigned int字节数:%lu\n",sizeof(unsigned int));//4个字节
//7.unsigned long(无符号 长整型)
unsigned long l2=6000000000000;
printf("unsigned long 长整型:%lu\n",l2);
printf("unsigned long字节数:%lu\n",sizeof(unsigned long));//8个字节
//8.unsigned long long(无符号 长长整型)
unsigned long long ll2=8000000000000;
printf("unsigned long long 长长整型:%llu\n",ll2);
printf("unsigned long long字节数:%lu\n",sizeof(unsigned long));//8个字节小点
字符数组与字符串数组
arr = {9,8,7,6,5,4}; // 整体赋值只允许在初始化中
ch3 = "Even" ; // 不可以, 只有在初始化的时候才能整体赋值
#include <stdio.h>
int main(int argc, char const *argv[])
{
char arr[4]={'a','b','c','e'};
char arr2[5]="hello";
printf("%d\n",arr[3]);//101
printf("%c\n",arr[3]);//e
printf("%s\n",arr);//abcehello--字符数组没有结束符,所以会读到arr2的值
printf("%d\n",arr2[1]);//101
printf("%c\n",arr2[1]);//e
printf("%s\n",arr2);//hello
return 0;
}数组的指针
()优先级高,说明p是指针,指向一个整型的一维数组。这个一维数组的长度是n,也可以说p的步长为n。当p+1时,p指针会跨过n个整型数据的长度。
int( * p)[n]; //定义了指向含有n个元素的一维数组的指针
int a[n]; //定义数组
p=a; //将一维数组首地址赋值给数组指针pvscode快捷键(linux)
上下移动代码行:Alt+↑或↓
选中当前行:ctrl+L
在多个光标位置编辑:Alt+shift+↑或↓
同时修改同一个文本:ctrl+D(需要先用鼠标选中需要同时操作的文本)
同时修改ctrl+d多选了一个:ctrl+U(取消上一步的选择)
直接跳到行首行尾:END/HOME(小键盘锁住情况下)
在当前行下方插入一空行:ctrl+enter
在当前行上方插入一空行:ctrl+shift+enter
删除一行:ctrl+shift+k
向右缩进的两种方式:选中内容 按tab键或者ctrl+}
向左缩进:选中内容 按shift+tab键或者ctrl+{
显示或隐藏终端:ctrl+j
标识符
以数字,字母,下划线组成
不能以数字开头
不能是关键字
区分大小写
最好是小写,单词之间用下划线隔开
实型

显示小数时,%f 和 %lf 默认保留 6 位小数,如需指定小数位数,使用格式符 %.nf ,n 为几,表示精确到小数点后几位,会对 n+1 位做 4 舍 5 入。
//%0m.nf,表示一共显示m位数,保留n位小数,不够的前面补0
printf("f=%030.16lf\n",d);实型常量小细节
- 小数点前后,如果只有0,可以省略不写
0.93 可以写成 .93
18.0 可以写成 18.
- 科学计数法是实型常量,但是要写E
12340000 可以写成 1.2340000E7
全局变量和局部变量
全局变量
全局变量没如果不赋值,会赋予初始值0,''等,一般都要赋值。
不赋初值,系统分配默认值
整型数据默认 0
实型数据默认 0.0
布尔默认 false
字符串默认 空
局部变量
C语言局部变量一定要初始化
栈内存是反复使用的(脏的,上次使用完没清零的内容)
就近原则
全局变量和局部变量同名。 函数内使用的是那个。遵循就近原则!
1 同一个范围变量是不能重复的。
2 在函数内部,找变量。先看局部有没有,如果有直接使用。否则找全局的。 找到就OK,找不到并且没有引入其他的就报错
静态类成员
静态类成员(包括静态数据成员和静态成员函数)与类本身关联,而不是类的任何对象实例。静态数据成员在类的所有对象之间共享其值,而静态成员函数则可以通过类名或对象来调用,并且它们只能访问类的静态成员(包括静态数据成员和静态成员函数)。在main函数内调用时加上类作用域才能调用。
指针
//定义一个指针变量,把变量地址赋值给指针,访问指针变量中可用的地址的值
int var =20;//实际变量的声明和初始化
double var_d =88.84;//实际变量的声明和初始化
int *ip;//有*这个符号,就是指针变量的声明
ip=&var;//&符号是指针变量中存储var的基地址
//%p打印内存地址(指针),以16进制的形式
printf("var 变量的地址为%p\n",&var);
//打印ip的值
printf("var 变量的地址为%p\n",ip);
//使用指针访问值,通过指针就能找到内存中保存的变量
printf("*ip变量的值%d\n",*ip); 指针的加减法
/*指针的加法:移动下一个变量,意味地址向下一个变量方向移动若干字节(字节数由当前变量的类型决定) */
//printf("加法:%p\n",ip+1);
//获取到的数据类型还是*ip原先的类型,所有前后是向相同的类型可以通过ip+1获取值,否则获取不到
printf("加法:%d\n",*(ip+1));//
/*指针的加法:移动上一个变量,意味地址向上一个变量方向移动若干字节(字节数由当前变量的类型决定) */
//printf("减法:%p\n",ip2-1);
//获取到的数据类型还是*ip2原先的类型,所有前后是向相同的类型可以通过ip2-1获取值,否则获取不到
printf("减法:%d\n",*(ip2-1));野指针和空指针
1.C语言:野指针
1.指针变量中的值是非法内存地址,进而形成野指针
2.野指针不是NULL指针,是指针不可用内存地址的指针
3.NULL指针并无危害,很好判断,也很好调试
4.C语言中无法判断一个指针所保存的地址是否合法
2.野指针由来
1.局部指针变量没有初始化;
2.指针所只想的变量在指针之前被销毁
3.使用用已经释放过的指针
4.进行了错误指针运算
5.继续错误强制类型转换
野指针危害:引用野指针的时候,很大概率我们会访问到一个非法的内存,通常会直接导致程序崩溃,
更严重的后沟,访问系统关键的数据可能导致系统崩溃(window蓝屏)
*/
//野指针
int *ip;
/*
C语言 空指针:
在变量声明的时候,如果没有确切的地址可以赋值,
为指针变量渎职一个NULL值是一个良好的编程习惯,
赋值NULL值的指针被称为空指针
NULL地址为 0x0~
在大多数的操作系统中,程序不允许访问地址为0x0内存,因为该内存是操作系统保留。
内存0有特别重要的意义,表明该指针不指向一个可访问的内存地址。
但按照惯例,如果指针包含空值(零值),则假定它不指向任何东西
*/数组指针和指针的数组
#include <stdio.h>
int main(int argc, char const *argv[])
{
/* 数组的指针 */
//声明了一个数组
int arr[] = {99,66,77,88,55};
/*
获取数组的指针,
1.数组指针类型:指针类型就是数组的元素类型
type (*指针变量名)[]
数组的指针和数组元素的第一个元素的指针是一样,
数组的指针地址就是数组第一个元素的指针
*/
int (*ap)[]=&arr;
printf("%p\n",ap);
int *p2=&arr[0];
printf("%p\n",p2);
//求数组的长度
unsigned int len =sizeof(arr)/sizeof(arr[0]);
//数组最后一个下标 len-1,因为下标从0开始
//遍历数组
for (int i = 0; i < len; i++)
{
//获取数组元素的指针
printf("直接获取%p ",&arr[i]);
//获取数组元素
printf("直接获取%d\n",arr[i]);
//(*指针变量名)[] 通过数组的指针获取到该数组,然后操作里面的元素
//获取数组元素指针
printf("直接获取%p ",&(*ap)[i]);
//获取数组元素的值
printf("直接获取%d\n",(*ap)[i]);
}
return 0;
}#include <stdio.h>
int main(int argc, char const *argv[])
{
int a=1;
int b=2;
//里面全是指针类型的 一个数组,存储的都是指针变量
int* p[]={&a,&b};
unsigned len=sizeof(p)/sizeof(p[0]);
for (int i = 0; i < len; i++)
{
//遍历,里面都是指针
printf("%p\n",p[i]);
}
return 0;
}delete关键字
delete只能释放堆上的对象,并且要把是释放后的指针置空。
获取内存大小
sizeof(a) 获取 a 变量占用内存大小(内存占用的字节个数)。
unsigned long l1 = sizeof(i);
printf("l1=%lu \n",l1);//在内存占用4个字节万能指针void*
void* 是一个特殊的指针类型,用来表示一个指向未知类型的指针。它可以存储任何类型的地址,但无法直接解引用或操作其指向的数据。
它可以用于在没有明确类型信息的情况下表示指针。例如,当你需要在函数中传递一个指针,但不确定指针所指向的数据类型时,可以使用 void* 作为参数类型。
使用 void* 类型时,需要注意的是,在使用 void* 指针进行操作之前,必须将其转换为适当的指针类型,以便进行正确的解引用和操作。这是因为 void* 指针在不确定指向的具体类型时无法进行类型推断。
#include <stdio.h>
int main()
{
void* p = NULL;
int a = 10;
// 指向变量时,最好转换为void *
p = (void*)&a;
//使用指针变量指向的内存时,转换为int *
*((int*)p) = 11;
printf("a = %d\n", a);
return 0;
}总而言之,void* 是一种特殊的指针类型,可以用于表示指向未知类型的指针。它在某些情况下非常有用,但需要小心使用,以避免类型不匹配或错误的操作。
值传递和址传递,引用传递
值传递
int a=22;
int *p=&a;
//在这里*p==a==22,所以如果使用交换函数交换时,值传递和引用传递都可以交换成功,因为他们都是改变的实参本身#include<stdio.h>
void swap1(int x, int y);
void swap2(int *m, int *n);
int main()
{
int a = 3, b = 8;
printf("调用函数前:实参a=%d 实参b=%d\n\n", a, b);
swap1(a, b);
printf("值传递调用函数后:实参a=%d 实参b=%d\n\n", a, b);
swap2(&a, &b);
printf("址传递调用函数后:实参a=%d 实参b=%d\n", a, b);
return 0;
}
void swap1(int x, int y)
{
int temp;
temp = x;
x = y;
y = temp;
printf("值传递调用函数中:形参x=%d 形参y=%d\n", x, y);
}
void swap2(int *m, int *n)
{
int temp=*m;
*m = *n;
*n = temp;
printf("址传递调用函数中:形参m=%d 形参n=%d\n", *m, *n);
}
字符串指针,字符串数组
int res1=my_function(1,9.9);
printf("res1=%d\n",res1);
// 1.2 函数名指向函数地址
char a[]="adaf";
char *c="adfsd";
char b='a';
char *d=&b;
int arr[]={1,2,3};
printf("my_function地址=%p\n",my_function);
printf("a=%c\n",a[1]);
printf("a地址=%p\n",a);
printf("c=%c\n",(*c+1));
printf("c地址=%p\n",c);
printf("b地址=%p\n",d);
printf("b=%c\n",*d);
printf("c地址=%p\n",c);
printf("arr地址=%p\n",arr);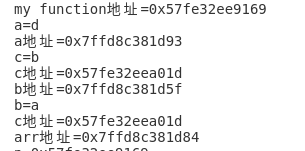
char a[]和char *a等价,字符串以数组形式存储,第一个字符地址就是字符串地址,只有字符串可以char *这样定义,其他类型需要先声明变量,在将指针指向变量。 char *e='r';//错误形式
当它们都是局部变量的时候:
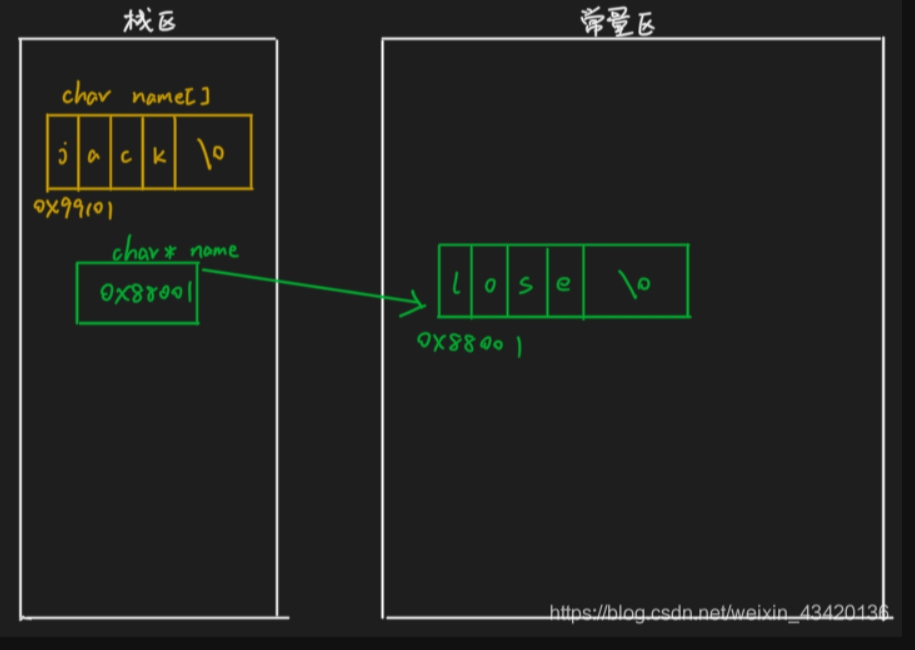
字符数组是申请在栈区,字符串的每一个字符存储在这个字符数组的每一个元素中;
指针变量是声明在栈区的,字符串数据是以字符数组的形式存储在常量区的,指针变量中存储的是字符串在常量区的地址
当它们作为全局变量的时候:
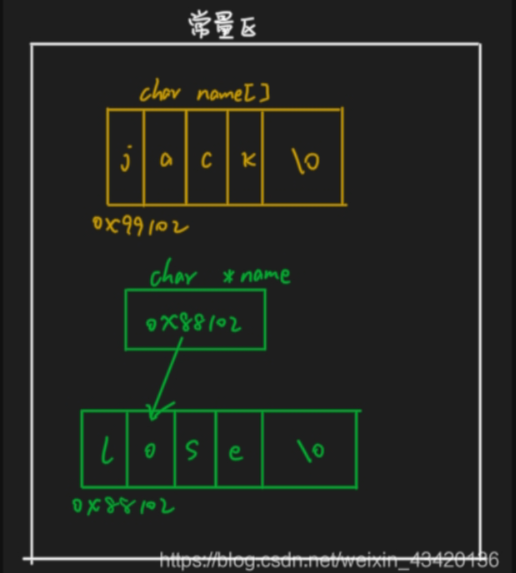
字符数组是存储在常量区的,字符串的每一个字符存储在这个字符数组的每一个元素中;
指针变量也是存储在常量区的,字符串数据是以字符数组的形式存储在常量区的,指针变量中存储的是字符串在常量区的地址
以字符数组的形式存储字符串数据,不管是全局的还是局部的,都可以使用下标去修改字符数组中的每一个元素;
以字符指针的形式存储字符串数据,不管是全局的还是局部的,都不能通过指针去修改指向的字符串数据
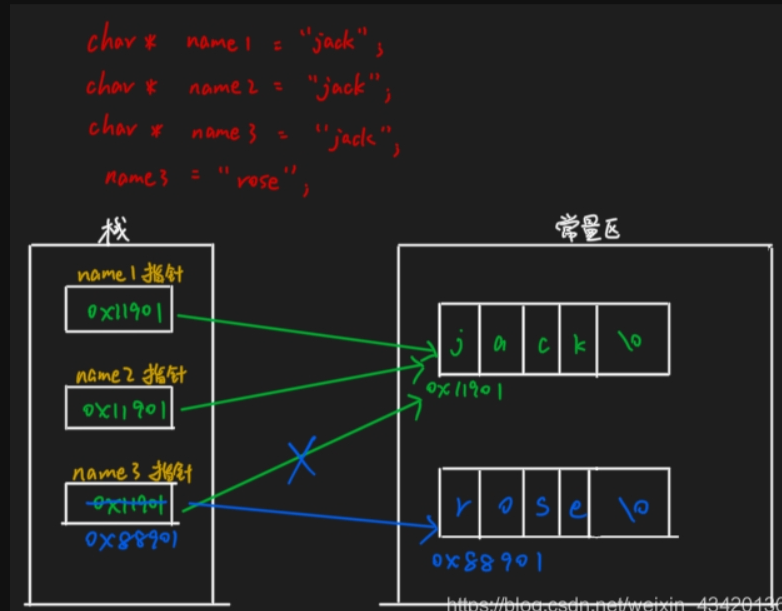
当我们以字符指针的形式要将字符串数据存储到常量区的时候,并不是直接将字符串存储到常量区,而是先检查常量区中是否有相同内容的字符串,如果有直接将这个字符串的地址拿过来返回,如果没有,才会将这个字符串数据存储在常量区中
当我们重新为字符指针初始化一个字符串的时候,并不是修改原来的字符串,而是重新的创建了一个字符串,把这个新的字符串的地址赋值给它
C语言深度理解结构体(内存对齐、位段、偏移量、柔性数组)
结构体中的偏移量、内存对齐
关于偏移量:是我们建立结构体时里面每一个成员的位置相对于结构体首地址的距离的长度,单位是字节数
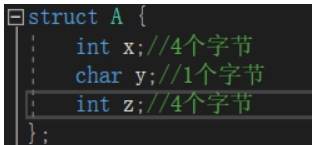
从测试结果可以看到,x距离结构体首地址是,也就说偏移量是0,说明x就是从首地址开始向后占据空间,也就是从0开始向后数4个字节,到达3,然后y的偏移量4,也就是说从首地址向后数5个字节数(0算一个字节),然后就是z偏移量是8,就是从第9个地址(相对于结构体首地址)开始向后数4个字节到达11,所以0到11总共12个字节,结构体A占12个字节数。
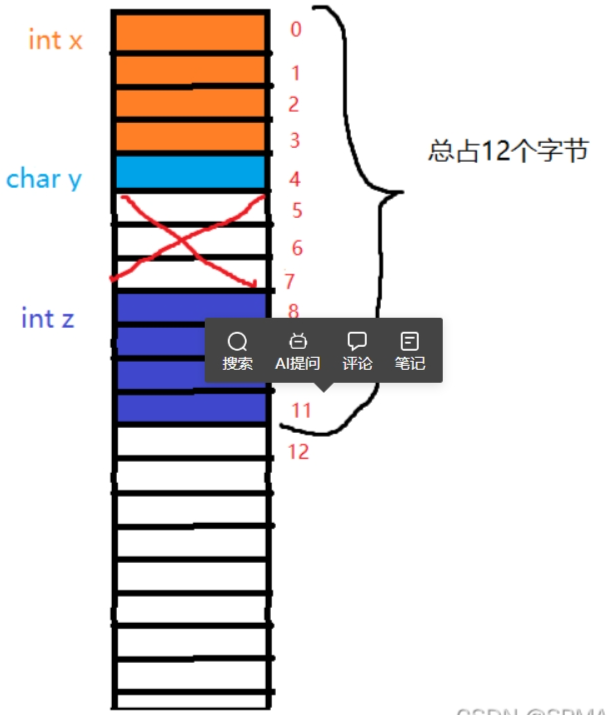
那么计算的方法是什么呢?
1:结构体第一个成员,存放结构体变量开始位置的0偏移处(也就是说,第一个成员一定在0偏移处开始存放)
2:从第二个成员开始,都要对齐到对齐数的整数倍地址处(对齐数:成员自身大小和默认对齐数两者的较小值)(vs环境下默认对齐数是8)
3:结构体总大小,必须是最大对齐数的整数倍
4:如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数整数倍处(是指所有成员当中的对齐数最大的那个)该结构体的大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
结构体里的位段
1位段成员必须是int,unsigned int,signed int
2位段成员后面是冒号
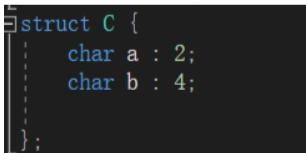
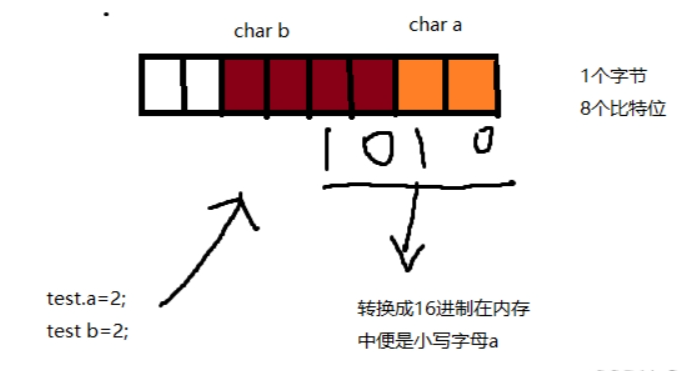
”char a:2“ 中的2其实代表的是2比特位,当建立char类型的变量将开辟1个字节也就是8个比特位来存放数据,但是位段设立为2,意思其实是该变量a只占用两个比特位来存放数据,若存放数据大于2个比特位则取2个比特位的二进制数据(会发生截断):
例如说我赋值2给结构体类型C的成员A,那2变成2进制便是”10“占两个比特位,然后再赋值成员b为2,则按照位段分配给b是4个比特位,而我只用了2个比特位,则在内存中便是:
柔性数组
结构体中最后一个元素允许是未知大小的数组,叫做柔性数组成员
1 柔性数组前面必须有成员
2 在计算结构体大小时,柔性数组大小不计入总大小,只记录前面成员所占内存
3 柔性数组的大小用动态内存开辟的方法进行开辟内存


malloc
说明:malloc向系统申请分配指定size个字节的内存空间。返回类型是void *类型。void *类型表示未确定类型的指针。C、C++规定,void *类型可以强制转换为任何其他类型的指针。
int * p;
p = (int *)malloc(sizeof(int));第一、malloc函数返回的是void *类型,如果你写成:p = malloc(sizeof(int));则程序无法通过编译,报错:“不能将void *赋值给int *类型变量”。所以必须通过(int *)来强制类型转换
第二、函数的实参为sizeof(int),用于指明一个整形数据需要的大小
常见的动态内存错误
对NULL指针进行解引用操作(忘记检查所请求的内存是否分配成功)
对分配的内存进行操作时越过了分配内存的边界
释放并非动态分配的内存(传递给free的指针必须是一个从malloc、calloc或realloc函数返回的指针)
试图释放一块动态分配的内存的一部分(释放一块内存的一部分是不允许的,动态分配的内存必须整块一起释放)
一块动态内存被释放之后被继续使用等。(不要访问已经被free函数释放了的内存,注意指针的复制)
排序算法
归并排序
#include<stdio.h>
#define TEMP_MAX_SIZE 100
void mergeSort(int *arr,int left,int right,int *temp){
//退出递归条件
if (left>=right)
{
return;
}
int mid = (left+right)/2;
mergeSort(arr,left,mid,temp);
mergeSort(arr,mid+1,right,temp);
//左边区间
int begin1=left,end1=mid;
//右边区间
int begin2=mid+1,end2=right;
//从最左边开始
int i=begin1;
//将排好的数据放入临时数组
while (begin1<=end1 && begin2<=end2)
{
if(arr[begin1]<=arr[begin2])
{
//先交换在++
temp[i]=arr[begin1++];
}
else
{
temp[i]=arr[begin2++];
}
i++;
}
while (begin1<=end1)
{
temp[i]=arr[begin1++];
i++;
}
while (begin2<=end2)
{
temp[i]=arr[begin2++];
i++;
}
//把临时数组元素内容放到原数组
for( i = left; i <=right; i++)
{
arr[i]=temp[i];
}
}
//打印数组
void printArr(int arr[],int n){
for (int i = 0; i < n; i++)
{
printf("%d ",arr[i]);
}
printf("\n");
}
int main(int argc, char const *argv[])
{
int arr[]={44,55,88,22,13,6,874,2563,0,13};
// 定义一个临时数组
int temp[TEMP_MAX_SIZE]={};
int n=sizeof(arr)/sizeof(arr[0]);
printf("打印前:\n");
printArr(arr,n);
printf("打印后:\n");
mergeSort(arr,0,n-1,temp);
printArr(arr,n);
return 0;
}堆排序
//交换数组函数
void Swap(int *pa,int *pb){
int tmp=*pa;
*pa=*pb;
*pb=tmp;
}
//构建大堆
void HeapAdjust(int *arr,int n,int node){
int parent=node;
//大的孩子下标默认为左孩子
int child=parent*2+1;
while (child<n)
{
//右孩子存在且大于左孩子,更新child
if (child+1<n && arr[child+1]>arr[child])
{
child=child+1;
}
//如果较大孩子大于双亲,交换
if (arr[child]>arr[parent])
{
Swap(&arr[child],&arr[parent]);
parent=child;
child=parent*2+1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int *arr,int n){
//循环从后面往前面对需要数组元素使用向下调整算法
int i=0;
for ( i = (n-1-1)/2; i >= 0; i--)
{
HeapAdjust(arr,n,i);
}
int end=n-1;
while (end>0)
{
Swap(&arr[0],&arr[end]);
HeapAdjust(arr,end,0);
--end;
}
}冒泡排序
void bubbleSort(int arr[],int n){
int i,j,temp;
//外循环负责比较轮数
for ( i = 0; i < n; i++)
{
for ( j = 0; j < n-i-1; j++)
{
if (arr[j]>arr[j+1])
{
//交换
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
}插入排序
void insertSort(int arr[],int n){
int i,j,key;
for ( i = 0; i < n; i++)
{
key=arr[i];
j=i-1;
while (j>=0 && arr[j]>key)
{
//需要插入,将元素后移一位
arr[j+1]=arr[j];
j--;
}
arr[j+1]=key;
}
}快速排序
void swap(int* a,int* b){
int t=*a;
*a=*b;
*b=t;
}
int partition(int arr[],int low,int hight){
//选择最右边的元素作为基准
int pivot=arr[hight];
//小于基准元素的最后一个元素的索引
int i=(low-1);
for (int j = low; j <hight; j++)
{
if (arr[j]<pivot){
i++;
swap(&arr[i],&arr[j]);
}
}
//交换:基准的下标值和比基准大的第一个下标交换
swap(&arr[i+1],&arr[hight]);
//返回基准的下标
return (i+1);
}
//快速排序
void quickSort(int arr[],int low,int hight){
if (low<hight)
{
//分区索引
int pivot_index=partition(arr,low,hight);
//对左子数组进行递归排序
quickSort(arr,low,pivot_index-1);
//对右子数组进行递归排序
quickSort(arr,pivot_index+1,hight);
}
}
选择排序
void selectionSort(int arr[],int n){
int i,j,min_index,temp;
for (i = 0; i < n-1; i++)
{
min_index=i;
for (j = i+1; j < n; j++)
{
if (arr[j]<arr[min_index])
{
min_index=j;
}
}
temp=arr[min_index];
arr[min_index]=arr[i];
arr[i]=temp;
}
}extern
#ifndef DEF
#define DEF
extern int a;
extern void fun01();
#endif#include<stdio.h>
#include "common.h"
int a=1;
void fun01(){
// extern void fun01(){函数可加可不加extern
printf("你调用了fun01\n");
}#include<stdio.h>
#include "common.h"
int main(int argc, char const *argv[])
{
printf("%d\n",a);
fun01();
return 0;
}数组初始化
模板中初始化,T()就是new一个模板T类型的数据对象
//初始化数组
Arrays() : array{} {
for (int i = 0; i < N; i++) {
array[i] = T();
}
}重写,重载与重定义
重载(Overload)
重载是指在同一个作用域内定义多个具有相同名称但参数列表不同的函数或运算符。编译器通过参数列表的不同来区分这些函数或运算符。
示例:
void print(int num) {
std::cout << "Integer: " << num << std::endl;
}
void print(double num) {
std::cout << "Double: " << num << std::endl;
}
void print(const std::string& str) {
std::cout << "String: " << str << std::endl;
}在上面的例子中,print 函数被重载了三次,分别用于处理 int、double 和 std::string 类型的参数。
重定义(Redefinition)
重定义通常指的是在派生类中重新定义一个与基类中同名的成员函数,但这个成员函数并不是虚函数(virtual function)。重定义的成员函数不会覆盖基类的成员函数,它们是独立的。
示例:
class Base {
public:
void display() {
std::cout << "Base display" << std::endl;
}
};
class Derived : public Base {
public:
void display() {
std::cout << "Derived display" << std::endl;
}
};在上面的例子中,Derived 类中的 display 函数是 Base 类中 display 函数的一个重定义。调用 Derived 对象的 display 函数时,会调用 Derived 类中的版本。
重写(Override)
重写是指在派生类中重新定义一个与基类中虚函数(virtual function)同名的成员函数,并且参数列表和返回类型也必须相同。重写用于实现多态,允许通过基类指针或引用来调用派生类的函数。
示例:
class Base {
public:
virtual void display() {
std::cout << "Base display" << std::endl;
}
};
class Derived : public Base {
public:
void display() override {
std::cout << "Derived display" << std::endl;
}
};在上面的例子中,Derived 类中的 display 函数重写了 Base 类中的 display 虚函数。通过基类指针或引用调用 display 函数时,会根据实际对象的类型调用相应的函数。
总结
- 重载:在同一个作用域内定义多个具有相同名称但参数列表不同的函数或运算符。
- 重定义:在派生类中重新定义一个与基类中同名的成员函数,但这个成员函数并不是虚函数。
- 重写:在派生类中重新定义一个与基类中虚函数同名的成员函数,并且参数列表和返回类型也必须相同,用于实现多态。
lambda表达式
深入浅出 C++ Lambda表达式:语法、特点和应用_c++ lamda函数作为函数参数-CSDN博客
shm,mmap,mencpy三者之间的区别
shm、mmap 和 memcpy 是操作系统中用于内存管理的不同机制和函数。它们之间的区别如下:
1. shm(共享内存)
- 定义:共享内存是一种进程间通信(IPC)机制,允许多个进程访问同一块物理内存。
- 用途:主要用于需要高效数据共享的场景,如数据库系统、实时数据处理等。
- 实现:通过系统调用(如
shmget、shmat、shmdt等)创建和管理共享内存段。 - 特点:
-
- 高效:数据直接在内存中共享,无需复制。
- 需要同步机制:由于多个进程可以同时访问共享内存,因此需要使用信号量等同步机制来避免数据冲突。
2. mmap(内存映射)
- 定义:
mmap是一种将文件或设备映射到进程地址空间的系统调用。 - 用途:用于文件的内存映射、共享内存、匿名内存映射等。
- 实现:通过
mmap系统调用将文件或设备映射到进程的虚拟地址空间。 - 特点:
-
- 灵活:可以映射文件、设备或匿名内存。
- 支持内存共享:多个进程可以映射同一个文件,实现内存共享。
- 文件操作:通过内存操作即可实现文件的读写,简化了文件操作。
3. memcpy
- 定义:
memcpy是一个C标准库函数,用于在内存之间复制数据。 - 用途:用于在不同内存区域之间复制数据,如数组、结构体等。
- 实现:通过指定源地址和目标地址以及复制的数据长度,实现内存数据的复制。
- 特点:
-
- 简单:适用于简单的内存复制操作。
- 不涉及共享:
memcpy只是将数据从一个内存区域复制到另一个内存区域,不涉及共享内存或文件映射。
#include <stdio.h>
#include <string.h>
int main() {
char src[] = "Hello, World!";
char dest[20];
// 使用 memcpy 复制 src 到 dest
memcpy(dest, src, strlen(src) + 1);
// 打印 dest 的内容
printf("dest: %s\n", dest);
return 0;
}需要注意的是,memcpy 不会自动添加 null 终止符,因此在使用字符串时,需要确保复制的长度包括 null 终止符。
此外,memcpy 适用于任何类型的数据,不仅仅是字符串。例如,可以用于复制整数数组、结构体等。
总结
shm:用于进程间共享内存,高效但需要同步机制。mmap:用于将文件或设备映射到进程地址空间,支持内存共享和文件操作。memcpy:用于在内存之间复制数据,简单且不涉及共享。
这些机制和函数在不同的场景下各有优势,选择合适的机制取决于具体的应用需求。
posix
网络通信
物理层:负责最后将信息编码成电流脉冲或其它信号用于网上传输
数据链路层:
数据链路层通过物理网络链路供数据传输。
规定了0和1的分包形式,确定了网络数据包的形式;
网络层:IP协议
网络层负责在源和终点之间建立连接;
此处需要确定计算机的位置,通过IPv4,IPv6格式的IP地址来找到对应的主机
传输层:TCP/UDP
传输层向高层提供可靠的端到端的网络数据流服务。
每一个应用程序都会在网卡注册一个端口号,该层就是端口与端口的通信
会话层
会话层建立、管理和终止表示层与实体之间的通信会话;
建立一个连接(自动的手机信息、自动的网络寻址);
表示层:
对应用层数据编码和转化, 确保以一个系统应用层发送的信息 可以被另一个系统应用层识别;
UDP通信流程
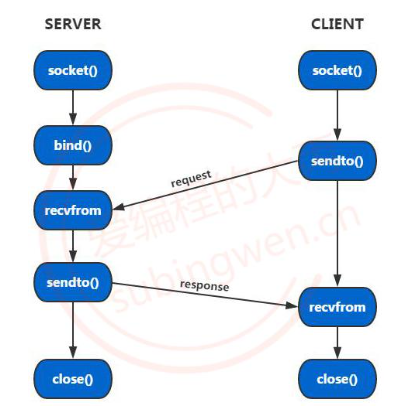
int socket(int domain, int type, int protocol);参数:
domain:地址族协议,AF_INET -> IPv4,AF_INET6-> IPv6
type:使用的传输协议类型,报式传输协议需要指定为 SOCK_DGRAM
protocol:指定为0,表示使用的默认报式传输协议为 UDP
返回值:函数调用成功返回一个可用的文件描述符(大于0),调用失败返回-1
// 接收数据, 如果没有数据,该函数阻塞
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);参数:
sockfd: 基于udp的通信的文件描述符
buf: 指针指向的地址用来存储接收的数据
len: buf指针指向的内存的容量, 最多能存储多少字节
flags: 设置套接字属性,一般使用默认属性,指定为0即可
src_addr: 发送数据的一端的地址信息,IP和端口都存储在这里边, 是大端存储的
如果这个参数中的信息对当前业务处理没有用处, 可以指定为NULL, 不保存这些信息
addrlen: 类似于accept() 函数的最后一个参数, 是一个传入传出参数
传入的是src_addr参数指向的内存的大小, 传出的也是这块内存的大小
如果src_addr参数指定为NULL, 这个参数也指定为NULL即可
返回值:成功返回接收的字节数,失败返回-1
// 发送数据函数
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);参数:
sockfd: 基于udp的通信的文件描述符
buf: 这个指针指向的内存中存储了要发送的数据
len: 要发送的数据的实际长度
flags: 设置套接字属性,一般使用默认属性,指定为0即可
dest_addr: 接收数据的一端对应的地址信息, 大端的IP和端口
addrlen: 参数 dest_addr 指向的内存大小
返回值:函数调用成功返回实际发送的字节数,调用失败返回-1
服务端
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main()
{
// 1. 创建通信的套接字
int fd = socket(AF_INET, SOCK_DGRAM, 0);
if(fd == -1)
{
perror("socket");
exit(0);
}
// 2. 通信的套接字和本地的IP与端口绑定
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(9999); // 大端
addr.sin_addr.s_addr = INADDR_ANY; // 0.0.0.0
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if(ret == -1)
{
perror("bind");
exit(0);
}
char buf[1024];
char ipbuf[64];
struct sockaddr_in cliaddr;
int len = sizeof(cliaddr);
// 3. 通信
while(1)
{
// 接收数据
memset(buf, 0, sizeof(buf));
int rlen = recvfrom(fd, buf, sizeof(buf), 0, (struct sockaddr*)&cliaddr, &len);
printf("客户端的IP地址: %s, 端口: %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr.s_addr, ipbuf, sizeof(ipbuf)),
ntohs(cliaddr.sin_port));
printf("客户端say: %s\n", buf);
// 回复数据
// 数据回复给了发送数据的客户端
sendto(fd, buf, rlen, 0, (struct sockaddr*)&cliaddr, sizeof(cliaddr));
}
close(fd);
return 0;
}客户端
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main()
{
// 1. 创建通信的套接字
int fd = socket(AF_INET, SOCK_DGRAM, 0);
if(fd == -1)
{
perror("socket");
exit(0);
}
// 初始化服务器地址信息
struct sockaddr_in seraddr;
seraddr.sin_family = AF_INET;
seraddr.sin_port = htons(9999); // 大端
inet_pton(AF_INET, "192.168.1.100", &seraddr.sin_addr.s_addr);
char buf[1024];
char ipbuf[64];
struct sockaddr_in cliaddr;
int len = sizeof(cliaddr);
int num = 0;
// 2. 通信
while(1)
{
sprintf(buf, "hello, udp %d....\n", num++);
// 发送数据, 数据发送给了服务器
sendto(fd, buf, strlen(buf)+1, 0, (struct sockaddr*)&seraddr, sizeof(seraddr));
// 接收数据
memset(buf, 0, sizeof(buf));
recvfrom(fd, buf, sizeof(buf), 0, NULL, NULL);
printf("服务器say: %s\n", buf);
sleep(1);
}
close(fd);
return 0;
}作为数据发送端,客户端不需要绑定固定端口,客户端使用的端口是随机绑定的(也可以调用bind()函数手动进行绑定)。客户端在接收服务器端回复的数据的时候需要调用recvfrom()函数,因为客户端在发送数据之前就已经知道服务器绑定的固定的IP和端口信息了,所以接收服务器数据的时候就可以不保存服务器端的地址信息,直接将函数的最后两个参数指定为NULL即可。
TCP通信流程
IP地址转换
// 这套api主要用于 网络通信过程中 IP 和 端口 的 转换
// 将一个短整形从主机字节序 -> 网络字节序
uint16_t htons(uint16_t hostshort);
// 将一个整形从主机字节序 -> 网络字节序
uint32_t htonl(uint32_t hostlong);
// 将一个短整形从网络字节序 -> 主机字节序
uint16_t ntohs(uint16_t netshort)
// 将一个整形从网络字节序 -> 主机字节序
uint32_t ntohl(uint32_t netlong);// 主机字节序的IP地址转换为网络字节序
// 主机字节序的IP地址是字符串, 网络字节序IP地址是整形
int inet_pton(int af, const char *src, void *dst); 参数:
af: 地址族(IP地址的家族包括ipv4和ipv6)协议
AF_INET: ipv4格式的ip地址
AF_INET6: ipv6格式的ip地址
src: 传入参数, 对应要转换的点分十进制的ip地址: 192.168.1.100
dst: 传出参数, 函数调用完成, 转换得到的大端整形IP被写入到这块内存中
返回值:成功返回1,失败返回0或者-1
#include <arpa/inet.h>
// 将大端的整形数, 转换为小端的点分十进制的IP地址
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);参数:
af: 地址族协议
AF_INET: ipv4格式的ip地址
AF_INET6: ipv6格式的ip地址
src: 传入参数, 这个指针指向的内存中存储了大端的整形IP地址
dst: 传出参数, 存储转换得到的小端的点分十进制的IP地址
size: 修饰dst参数的, 标记dst指向的内存中最多可以存储多少个字节
返回值:
成功: 指针指向第三个参数对应的内存地址, 通过返回值也可以直接取出转换得到的IP字符串
失败: NULL
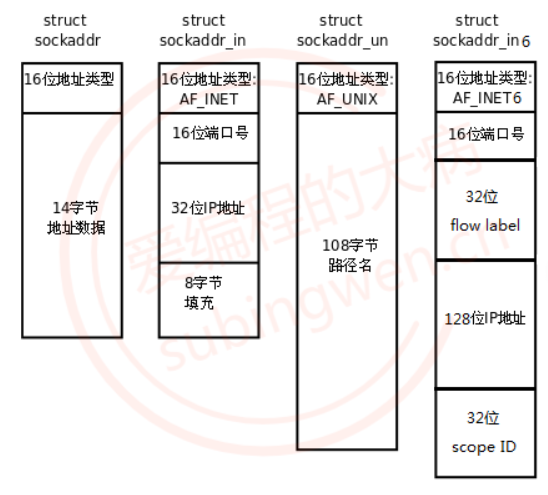
sockaddr数据结构
// 创建一个套接字
int socket(int domain, int type, int protocol);参数:
domain: 使用的地址族协议
AF_INET: 使用IPv4格式的ip地址
AF_INET6: 使用IPv4格式的ip地址
type:
SOCK_STREAM: 使用流式的传输协议
SOCK_DGRAM: 使用报式(报文)的传输协议
protocol: 一般写0即可, 使用默认的协议
SOCK_STREAM: 流式传输默认使用的是tcp
SOCK_DGRAM: 报式传输默认使用的udp
返回值:
成功: 可用于套接字通信的文件描述符
失败: -1
// 将文件描述符和本地的IP与端口进行绑定
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);参数:
sockfd: 监听的文件描述符, 通过socket()调用得到的返回值
addr: 传入参数, 要绑定的IP和端口信息需要初始化到这个结构体中,IP和端口要转换为网络字节序
addrlen: 参数addr指向的内存大小, sizeof(struct sockaddr)
返回值:成功返回0,失败返回-1
// 给监听的套接字设置监听
int listen(int sockfd, int backlog);参数:
sockfd: 文件描述符, 可以通过调用socket()得到,在监听之前必须要绑定 bind()
backlog: 同时能处理的最大连接要求,最大值为128
返回值:函数调用成功返回0,调用失败返回 -1
// 等待并接受客户端的连接请求, 建立新的连接, 会得到一个新的文件描述符(通信的)
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);参数:9
sockfd: 监听的文件描述符
addr: 传出参数, 里边存储了建立连接的客户端的地址信息
addrlen: 传入传出参数,用于存储addr指向的内存大小
返回值:函数调用成功,得到一个文件描述符, 用于和建立连接的这个客户端通信,调用失败返回 -1
// 接收数据
ssize_t read(int sockfd, void *buf, size_t size);
ssize_t recv(int sockfd, void *buf, size_t size, int flags);参数:
sockfd: 用于通信的文件描述符, accept() 函数的返回值
buf: 指向一块有效内存, 用于存储接收是数据
size: 参数buf指向的内存的容量
flags: 特殊的属性, 一般不使用, 指定为 0
返回值:
大于0:实际接收的字节数
等于0:对方断开了连接
-1:接收数据失败了
// 发送数据的函数
ssize_t write(int fd, const void *buf, size_t len);
ssize_t send(int fd, const void *buf, size_t len, int flags);参数:
fd: 通信的文件描述符, accept() 函数的返回值
buf: 传入参数, 要发送的字符串
len: 要发送的字符串的长度
flags: 特殊的属性, 一般不使用, 指定为 0
返回值:
大于0:实际发送的字节数,和参数len是相等的
-1:发送数据失败了
// 成功连接服务器之后, 客户端会自动随机绑定一个端口
// 服务器端调用accept()的函数, 第二个参数存储的就是客户端的IP和端口信息
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);参数:
sockfd: 通信的文件描述符, 通过调用socket()函数就得到了
addr: 存储了要连接的服务器端的地址信息: iP 和 端口,这个IP和端口也需要转换为大端然后再赋值
addrlen: addr指针指向的内存的大小 sizeof(struct sockaddr)
返回值:连接成功返回0,连接失败返回-1
TCP服务端
// server.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main()
{
// 1. 创建监听的套接字
int lfd = socket(AF_INET, SOCK_STREAM, 0);
if(lfd == -1)
{
perror("socket");
exit(0);
}
// 2. 将socket()返回值和本地的IP端口绑定到一起
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(10000); // 大端端口
// INADDR_ANY代表本机的所有IP, 假设有三个网卡就有三个IP地址
// 这个宏可以代表任意一个IP地址
// 这个宏一般用于本地的绑定操作
addr.sin_addr.s_addr = INADDR_ANY; // 这个宏的值为0 == 0.0.0.0
// inet_pton(AF_INET, "192.168.237.131", &addr.sin_addr.s_addr);
int ret = bind(lfd, (struct sockaddr*)&addr, sizeof(addr));
if(ret == -1)
{
perror("bind");
exit(0);
}
// 3. 设置监听
ret = listen(lfd, 128);
if(ret == -1)
{
perror("listen");
exit(0);
}
// 4. 阻塞等待并接受客户端连接
struct sockaddr_in cliaddr;
int clilen = sizeof(cliaddr);
int cfd = accept(lfd, (struct sockaddr*)&cliaddr, &clilen);
if(cfd == -1)
{
perror("accept");
exit(0);
}
// 打印客户端的地址信息
char ip[24] = {0};
printf("客户端的IP地址: %s, 端口: %d\n",
inet_ntop(AF_INET, &cliaddr.sin_addr.s_addr, ip, sizeof(ip)),
ntohs(cliaddr.sin_port));
// 5. 和客户端通信
while(1)
{
// 接收数据
char buf[1024];
memset(buf, 0, sizeof(buf));
int len = read(cfd, buf, sizeof(buf));
if(len > 0)
{
printf("客户端say: %s\n", buf);
write(cfd, buf, len);
}
else if(len == 0)
{
printf("客户端断开了连接...\n");
break;
}
else
{
perror("read");
break;
}
}
close(cfd);
close(lfd);
return 0;
}TCP客户端
// client.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <arpa/inet.h>
int main()
{
// 1. 创建通信的套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
if(fd == -1)
{
perror("socket");
exit(0);
}
// 2. 连接服务器
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_port = htons(10000); // 大端端口
inet_pton(AF_INET, "192.168.237.131", &addr.sin_addr.s_addr);
int ret = connect(fd, (struct sockaddr*)&addr, sizeof(addr));
if(ret == -1)
{
perror("connect");
exit(0);
}
// 3. 和服务器端通信
int number = 0;
while(1)
{
// 发送数据
char buf[1024];
sprintf(buf, "你好, 服务器...%d\n", number++);
write(fd, buf, strlen(buf)+1);
// 接收数据
memset(buf, 0, sizeof(buf));
int len = read(fd, buf, sizeof(buf));
if(len > 0)
{
printf("服务器say: %s\n", buf);
}
else if(len == 0)
{
printf("服务器断开了连接...\n");
break;
}
else
{
perror("read");
break;
}
sleep(1); // 每隔1s发送一条数据
}
close(fd);
return 0;
}端口复用
// 这个函数是一个多功能函数, 可以设置套接字选项
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);参数:
sockfd:用于监听的文件描述符
level:设置端口复用需要使用 SOL_SOCKET 宏
optname:要设置什么属性(下边的两个宏都可以设置端口复用)
SO_REUSEADDR
SO_REUSEPORT
optval:设置是去除端口复用属性还是设置端口复用属性,实际应该使用 int 型变量
0:不设置
1:设置
optlen:optval指针指向的内存大小 sizeof(int)
这个函数应该添加到服务器端代码中,具体应该放到什么位置呢?答:在绑定之前设置端口复用
1,创建监听的套接字
2,设置端口复用
3,绑定
4,设置监听
5,等待并接受客户端连接
6,通信
7,断开连接
Linux系统文件IO
文件IO的异同
- 系统调用 vs 标准库函数:
-
- 系统文件 I/O:通常指的是直接使用系统调用(如
open,read,write,close等)进行文件操作。这些系统调用直接与操作系统内核交互,提供了对文件的底层访问。 - 普通文件 I/O:通常指的是使用标准库函数(如
fopen,fread,fwrite,fclose等)进行文件操作。这些函数是对系统调用的封装,提供了更高层次的抽象和便利性。
- 系统文件 I/O:通常指的是直接使用系统调用(如
- 缓冲机制:
-
- 系统文件 I/O:通常不提供缓冲机制,每次读写操作都会直接与内核交互,效率相对较低。
- 普通文件 I/O:标准库函数通常提供缓冲机制(如全缓冲、行缓冲、无缓冲等),可以减少系统调用的次数,提高读写效率。
- 错误处理:
-
- 系统文件 I/O:错误处理通常通过返回值和全局变量(如
errno)来实现,需要程序员显式地检查和处理错误。 - 普通文件 I/O:标准库函数通常提供更友好的错误处理机制,如
ferror和perror等,简化了错误处理的代码。
- 系统文件 I/O:错误处理通常通过返回值和全局变量(如
- 功能和灵活性:
-
- 系统文件 I/O:提供了更多的控制选项和灵活性,如文件描述符、文件权限、文件锁等。
- 普通文件 I/O:提供了更高层次的抽象和便利性,如文件指针、格式化输入输出等,但相对缺乏底层控制。
总结来说,系统文件 I/O 提供了对文件的底层访问和更多的控制选项,适用于需要精细控制文件操作的场景;而普通文件 I/O 提供了更高层次的抽象和便利性,适用于大多数常规的文件操作场景。
open()
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
/*
open是一个系统函数, 只能在linux系统中使用, windows不支持
fopen 是标准c库函数, 一般都可以跨平台使用, 可以这样理解:
- 在linux中 fopen底层封装了Linux的系统API open
- 在window中, fopen底层封装的是 window 的 api
*/
// 打开一个已经存在的磁盘文件
int open(const char *pathname, int flags);
// 打开磁盘文件, 如果文件不存在, 就会自动创建
int open(const char *pathname, int flags, mode_t mode);参数介绍:
pathname: 被打开的文件的文件名
flags: 使用什么方式打开指定的文件,这个参数对应一些宏值,需要根据实际需求指定
必须要指定的属性, 以下三个属性不能同时使用, 只能任选其一
O_RDONLY: 以只读方式打开文件
O_WRONLY: 以只写方式打开文件
O_RDWR: 以读写方式打开文件
可选属性, 和上边的属性一起使用
O_APPEND: 新数据追加到文件尾部, 不会覆盖文件的原来内容
O_CREAT: 如果文件不存在, 创建该文件, 如果文件存在什么也不做
O_EXCL: 检测文件是否存在, 必须要和 O_CREAT 一起使用, 不能单独使用: O_CREAT | O_EXCL
检测到文件不存在, 创建新文件
检测到文件已经存在, 创建失败, 函数直接返回-1(如果不添加这个属性,不会返回-1)
mode: 在创建新文件的时候才需要指定这个参数的值,用于指定新文件的权限,这是一个八进制的整数
返回值:
成功: 返回内核分配的文件描述符, 这个值被记录在内核的文件描述符表中,这是一个大于0的整数
失败: -1
read()
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件
buf: 是一个传出参数, 指向一块有效的内存, 用于存储从文件中读出的数据
传出参数: 类似于返回值, 将变量地址传递给函数, 函数调用完毕, 地址中就有数据了
count: buf指针指向的内存的大小, 指定可以存储的最大字节数
返回值:
大于0: 从文件中读出的字节数,读文件成功
等于0: 代表文件读完了,读文件成功
-1: 读文件失败了
write()
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件
buf: 指向一块有效的内存地址, 里边有要写入到磁盘文件中的数据
count: 要往磁盘文件中写入的字节数, 一般情况下就是buf字符串的长度, strlen(buf)
返回值:
大于0: 成功写入到磁盘文件中的字节数
-1: 写文件失败了
lseek
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);参数:
fd: 文件描述符, open() 函数的返回值, 通过这个参数定位打开的磁盘文件
offset: 偏移量,需要和第三个参数配合使用
whence: 通过这个参数指定函数实现什么样的功能
SEEK_SET: 从文件头部开始偏移 offset 个字节
SEEK_CUR: 从当前文件指针的位置向后偏移offset个字节
SEEK_END: 从文件尾部向后偏移offset个字节
返回值:
成功: 文件指针从头部开始计算总的偏移量
失败: -1
文件指针移动到文件头部
lseek(fd, 0, SEEK_SET);得到当前文件指针的位置
lseek(fd, 0, SEEK_CUR); 得到文件总大小
lseek(fd, 0, SEEK_END);// 文件的拷贝
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
int main(int argc, char const *argv[])
{
//打开已存在的文件读取
int fd_read = open("./newfile.txt",O_RDONLY);
if(fd_read==-1){
printf("文件打开失败!fd_read: %d\n",fd_read);
}else{
printf("文件打开成功!fd_read: %d\n",fd_read);
}
//打开不存在的文件写入
// int fd_write = open("./writedfile.txt",O_RDWR | O_CREAT | O_EXCL,0664);
// if(fd_write==-1){
// printf("文件已存在,fd_write:%d\n",fd_write);
// }else{
// printf("文件创建成功,fd_write:%d\n",fd_write);
// }
// char buffer[1024];
// int len=-1;
// while ((len=read(fd_read,buffer,sizeof(buffer)))>0){
// write(fd_write,buffer,len);
// }
//打开已存在的文件追加
int fd_write = open("./cpread.txt",O_RDWR | O_CREAT | O_APPEND,0664);
if(fd_write==-1){
printf("文件打开失败,fd_write:%d\n",fd_write);
}else{
printf("文件打开成功,fd_write:%d\n",fd_write);
}
char buffer[1024];
int len=-1;
//一次性读的大小sizeof(buffer)
while ((len=read(fd_read,buffer,sizeof(buffer)))>0){
write(fd_write,buffer,len);
printf("LEN:%d\n",len);
}
close(fd_read);
close(fd_write);
return 0;
}
普通文件IO
fopen()
#include <stdio.h>
FILE *fopen(const char *filename, const char *mode);参数:
filename:指定要打开的文件名,需要加上路径(相对、绝对路径)
mode:指定文件的打开模式
返回值:
成功:返回指向打开文件的文件指针
失败:返回 NULL

fclose()
#include <stdio.h>
int fclose(FILE * stream);参数:接受一个文件指针 stream,用于指定要关闭的文件。它会将缓冲区中的数据写回到文件中,并释放与文件相关的资源。
返回值:返回一个整数值来指示关闭操作的成功与否。
成功:关闭文件,它会返回0;
失败:返回非零值
#include <stdio.h>
int main()
{
FILE* fp = fopen("hello1.txt", "r");
if (fp == NULL)
{
perror("fopen");
return -1;
}
else
{
printf("文件打开成功!\n");
flcose(fp);
}
return 0;
}按字符读写文件
fputc-写文件
#include <stdio.h>
int fputc(int character, FILE *stream);
int putc(int character, FILE *stream);参数:
character:要写入的字符,注意这个参数是整形
stream:文件指针,对应要写入字符的文件
返回值:
成功:返回写入的字符
失败:返回 EOF
在标准C库中,putc函数实际上是一个宏,而不是一个真正的函数。可以将其视为fputc函数的别名。因此,它们的功能是相同的。
fgetc-读文件
#include <stdio.h>
int fgetc(FILE *stream);
int getc(FILE *stream);按照行读取
fputs
#include <stdio.h>
int fputs(const char *string, FILE *stream);参数:
string:字符串的指针,表示要写入的内容
stream:文件指针,用于指定要写入字符的文件
返回值:
成功:返回一个非负值
失败:返回EOF
fgets
#include <stdio.h>
char *fgets(char *string, int size, FILE *stream);参数:
string:字符指针,用于存储读取的字符
size:指定要读取的最大字符数(包括终止符)
stream:文件指针,用于指定要从中读取字符的文件
返回值:
成功:返回参数string的首地址
失败:返回NULL
按块读写文件
fwrite
#include <stdio.h>
size_t fwrite(const void *ptr, size_t size, size_t count, FILE *stream);参数:
ptr:指向要写入数据的指针
size:要写入的每个元素的字节数
count:要写入的元素数量
stream:文件指针,用于指定要写入数据的文件
返回值:
成功:返回写入的元素数量,即count的值
失败:或者返回一个小于count的值
fwrite函数会将指针ptr指向的数据写入到文件中。写入的总字节数是size与count相乘的积。
fread
#include <stdio.h>
size_t fread(void *ptr, size_t size, size_t count, FILE *stream);参数:
ptr:指向用于存储读取数据的缓冲区的指针
size:每个元素的字节数
count:要读取的元素数量
stream:文件指针,用于指定要从中读取数据的文件
返回值:
成功:返回实际读取的元素数量
失败:返回的元素数量与count不相等
fread函数会从文件中读取指定数量的元素,每个元素占据size个字节,将它们存储在ptr指向的缓冲区中。
缓冲区
fflush
#include <stdio.h>
int fflush(FILE *stream);fflush函数接受一个文件指针 stream 作为参数,用于指定要刷新缓冲区的文件。它会将输出缓冲区中的内容强制写入文件,并清空缓冲区。
fflush函数返回一个整数值来指示刷新操作的成功与否。如果成功刷新缓冲区,它会返回0;否则,返回非零值。通常情况下,我们可以将其与0进行比较,以确定刷新是否成功。
mmu
MMU 通过分页机制将虚拟地址转换为物理地址,实现了高效的内存管理和保护。页表是存储虚拟页号到物理页号映射的数据结构,通过多级页表可以有效地管理大地址空间。掌握虚拟地址到物理地址的转换过程,对于理解现代操作系统的内存管理机制非常重要。
文件描述符
通过open()函数打开 /hello.txt,文件描述符 3 被分配给了这个文件,保持这个打开状态,再次通过open()函数打开 /hello.txt,文件描述符 4 被分配给了这个文件,也就是说一个进程中不同的文件描述符打开的磁盘文件可能是同一个。
通过open()函数打开 /hello.txt,文件描述符 3 被分配给了这个文件,将打开的文件关闭,此时文件描述符3就被释放了。再次通过open()函数打开 /hello.txt,文件描述符 3 被分配给了这个文件,也就是说打开的新文件会关联文件描述符表中最小的没有被占用的文件描述符。
dup()
#include <unistd.h>
int dup(int oldfd);参数: oldfd 是要被复制的文件描述符
返回值:函数调用成功返回被复制出的文件描述符,调用失败返回 -1
dup2()
#include <unistd.h>
// 1. 文件描述符的复制, 和dup是一样的
// 2. 能够重定向文件描述符
// - 重定向: 改变文件描述符和文件的关联关系, 和新的文件建立关联关系, 和原来的文件断开关联关系
// 1. 首先通过open()打开文件 a.txt , 得到文件描述符 fd
// 2. 然后通过open()打开文件 b.txt , 得到文件描述符 fd1
// 3. 将fd1从定向 到fd上:
// fd1和b.txt这磁盘文件断开关联, 关联到a.txt上, 以后fd和fd1都对用同一个磁盘文件 a.txt
int dup2(int oldfd, int newfd);参数: oldfd和``newfd` 都是文件描述符
返回值: 函数调用成功返回新的文件描述符, 调用失败返回 -1
#include <unistd.h>
#include <fcntl.h> // 主要的头文件
int fcntl(int fd, int cmd, ... /* arg */ );参数:
fd: 要操作的文件描述符
cmd: 通过该参数控制函数要实现什么功能
返回值:函数调用失败返回 -1,调用成功,返回正确的值:
参数 cmd = F_DUPFD:返回新的被分配的文件描述符
参数 cmd = F_GETFL:返回文件的flag属性信息
参数 cmd 的取值 功能描述
F_DUPFD 复制一个已经存在的文件描述符
F_GETFL 获取文件的状态标志
F_SETFL 设置文件的状态标志
// 如果不想将数据写到文件头部, 可以给文件描述符追加一个O_APPEND属性
// 通过fcntl获取文件描述符的 flag属性
int flag = fcntl(fd, F_GETFL);
// 给得到的flag追加 O_APPEND属性
flag = flag | O_APPEND; // flag |= O_APPEND;
// 重新将flag属性设置给文件描述符
fcntl(fd, F_SETFL, flag);cin
cin.ignore();忽略或清空控制台输入,可加参数
cin.fail(),cin.good();获取控制台输入状态
cin.clear();恢复错误状态
可变参数
请注意,函数 func() 最后一个参数写成省略号,即三个点号(...),省略号之前的那个参数是 int,代表了要传递的可变参数的总数。为了使用这个功能,您需要使用 stdarg.h 头文件,该文件提供了实现可变参数功能的函数和宏。具体步骤如下:
- 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数。
- 在函数定义中创建一个 va_list 类型变量,该类型是在 stdarg.h 头文件中定义的。
- 使用 int 参数和 va_start() 宏来初始化 va_list 变量为一个参数列表。宏 va_start() 是在 stdarg.h 头文件中定义的。
- 使用 va_arg() 宏和 va_list 变量来访问参数列表中的每个项。
- 使用宏 va_end() 来清理赋予 va_list 变量的内存。
常用的宏有:
va_start(ap, last_arg):初始化可变参数列表。ap是一个va_list类型的变量,last_arg是最后一个固定参数的名称(也就是可变参数列表之前的参数)。该宏将ap指向可变参数列表中的第一个参数。va_arg(ap, type):获取可变参数列表中的下一个参数。ap是一个va_list类型的变量,type是下一个参数的类型。该宏返回类型为type的值,并将ap指向下一个参数。va_end(ap):结束可变参数列表的访问。ap是一个va_list类型的变量。该宏将ap置为NULL。
现在让我们按照上面的步骤,来编写一个带有可变数量参数的函数,并返回它们的平均值:
#include <stdio.h>
#include <stdarg.h>
double average(int num,...)
{
va_list valist;
double sum = 0.0;
int i;
/* 为 num 个参数初始化 valist */
va_start(valist, num);
/* 访问所有赋给 valist 的参数 */
for (i = 0; i < num; i++)
{
sum += va_arg(valist, int);
}
/* 清理为 valist 保留的内存 */
va_end(valist);
return sum/num;
}
int main()
{
printf("Average of 2, 3, 4, 5 = %f\n", average(4, 2,3,4,5));
printf("Average of 5, 10, 15 = %f\n", average(3, 5,10,15));
}返回值是指针的函数
#include <stdio.h>
#include <stdlib.h>
// 定义一个返回指向包含5个整数的数组的指针的函数
int (*func())[5] {
static int array[5] = {1, 2, 3, 4, 5};
return &array;
}
int main() {
int (*ptrToArray)[5];
// 调用函数,获取数组指针
ptrToArray = func();
// 访问数组元素
for (int i = 0; i < 5; i++) {
printf("array[%d] = %d\n", i, (*ptrToArray)[i]);
}
return 0;
}
null和nullptr
优点
nullptr是类型安全的,不会引起重载解析问题。nullptr可以隐式转换为任何指针类型,避免了类型不匹配的问题。
总结
NULL是一个预处理器宏,通常定义为整数常量0,可能会引起类型不匹配和重载解析问题。nullptr是C++11引入的关键字,专门用于表示空指针,类型安全且不会引起重载解析问题。
在现代C++编程中,推荐使用 nullptr 来表示空指针,以避免潜在的问题并提高代码的可读性和安全性。
通过理解这些区别,你可以更好地选择合适的空指针表示方式,编写更健壮的C++代码。
C++遍历
void main() {
int array[5] = { 1,3,5,7,9 };
for (int element : array) {
std::cout << element << std::endl;
}
return;
}C++中的string类
#include<iostream>
#include<string.h>
using namespace std;
//void main() {
// int array[5] = { 1,3,5,7,9 };
// for (int element : array) {
// std::cout << element << std::endl;
// }
// return;
//}
void main() {
string str = "hello world!";
//赋值
str.assign("woshidsg");
//str.assign(8, 'a');
/*string arr = "adbchdj";
str.assign(arr, 3);*/
cout << str << endl;
char& c = str[4];
c = '!';
cout << str << endl;
//查看字符串内存分配的指针,c++的字符串超过16位后会重新分配地址,原来的引用就不能用了
cout << (int*)str.c_str() << endl;
str = "1234512345887966";
cout << (int*)str.c_str() << endl;
//字符串拼接
str = "hello";
string str1 = "world";
//方法1
str = str + "world";
//这种写法也是OK的
//str = str + str1;
cout << str << endl;
//方法二
str.append("c++ is the best lauguage");
cout << str << endl;
//字符串的查找
str="c++ is the best lauguage";
int res = str.find("best");
cout << res << endl;
//字符串的替换,第一个参数是从下标为几的开始替换,第二个是替换几个字符
str.replace(4, 2, "are");
cout << str << endl;
//字符串的比较,比较的是字典,compare函数,前大于后=1,后大于前=-1,相等=0
str = "abcd";
string str2 = "abd";//-1
string str3 = "aba";
string str4 = "abcd";
cout << str.compare(str2)<< endl;
cout << str.compare(str3) << endl;
cout << str.compare(str4) << endl;
//字符串的截取,注意第一个参数不要越界,第二个参数可以越界
//字符串截取返回的是新的字符串,不会影响原本的字符串
str = "helloworld";
cout << str.substr(5, 5) << endl;
//字符串的插入和删除
str = "hahahahahaha";
//从第几个下标开始插入
str.insert(4, "xiaogepi");
cout << str << endl;
//从第几个开始删除几个,不写第二个默认全部删除
str.erase(4, 8);
cout << str << endl;
return;
}C++容器
vector
#include<iostream>
#include<vector>
using namespace std;
template<typename E>
void print(vector<E> v) {
for (E& elemnet : v) {
cout << elemnet << ",";
}
cout<<endl;
}
void test() {
//构造一个空的vector对象
vector<int> v;
//插入
v.push_back(10);
v.push_back(20);
v.push_back(20);
//遍历,begin返回的是这个容器的第一个的指针,end返回的是最后一个元素的后一个指针
for (vector<int>::iterator it=v.begin(); it != v.end(); it++) {
cout << *it << endl;
}
//第二种遍历方式,但是这种遍历方式不能在内部改变v的元素值
//如果想要修改,用引用
for (int &element : v) {
cout << element << endl;
if(element == 20){
element = 200;
}
}
for (vector<int>::iterator it = v.begin(); it != v.end(); it++) {
cout << *it << endl;
}
//倒序便利
for (vector<int>::iterator it = v.end(); it != v.begin(); ) {
//因为不知道end()的指针,所以要先把it--
it--;
cout << *it << endl;
}
}
//容器的赋值操作
void test2() {
//方式一
vector<int> v1;
v1.assign(5, 10);
print(v1);
//方式二,重载后的=
vector<int> v2;
v2 = v1;
print(v2);
//swap函数用于交换两个容器的元素
vector<int> v3;
v3.assign(5, 9);
print(v3);
v3.swap(v2);
print(v3);
print(v2);
}
//vector的大小操作
void test03() {
vector<int> v(10, 9);
//获取容器的元素数量
cout << v.size() << endl;
//获取容器的容量,容量大于等于size
cout << v.capacity() << endl;
//判断容器是否为空
cout << v.empty() << endl;
//给容器指定长度
v.resize(5);
print(v);
//第二那个元素是指定多出来的元素用7来填充
v.resize(15, 7);
print(v);
return;
}
//容器的存取
void test04() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
vector<int> v(arr, arr+sizeof(arr) / sizeof(arr[1]));
//一
cout<<v.at(1)<<endl;
int& ele1 = v.at(2) = 30;
cout << v.at(2) << endl;
//用重载后的[]
cout << v[5] << endl;
//front和back
cout << v.front() << endl;
cout << v.back() << endl;
}
//容器的插入和删除
void test05() {
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
vector<int> v(arr, arr + sizeof(arr) / sizeof(arr[1]));
print(v);
//指定位置插入
v.insert(v.begin()+3, 5, 0);//插入5个0
print(v);
//尾插
v.push_back(20);
print(v);
//头删
v.pop_back();
print(v);
//指定位置删除
v.erase(v.begin() + 3, v.begin() + 8);
print(v);
//删除start,到end
v.erase(v.begin());
print(v);
//清空容器
v.clear();
print(v);
}
void main() {
test();
//构造对象,构造10个5
vector<int> v1(10, 5);
//其他构造方法
vector<int> v2(v1.begin(), v1.end());
print(v1);
print(v2);
cout << "test-----------" << endl;
test2();
cout << "test03-----------" << endl;
test03();
cout << "test04-----------" << endl;
test04();
cout << "test05-----------" << endl;
test05();
return;
}














 6467
6467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









