







题目描述:
给你一个链表数组,每个链表都已经按升序排列。请你将所有链表合并到一个升序链表中,返回合并后的链表。
学习记录:
第一想法,脑子里的思路和合并两个链表是一样的,每次找到最小值的链表连接。想不到更好的方法了,写了一下,是OK的,但用时还是很长的。
这里用到了一个flag来判断是否结束,当所有指针都变为nullptr的时候,也就结束了。如果有不为空的指针,那就继续找最小值并连接指针。为什么执行这么慢,因为对空指针其实是重复判断的,有一个方法是,当空指针后就将指针移出vector, 但我记得之前做删除的时候vector其实还是存在问题,这里就没有这样,但是如果做了可能会提升执行速度。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
int n=lists.size();
if(n==0) return nullptr;
if(n==1) return lists[0];
int flag=0;
int temp=find(lists,flag);
if(flag==n) return nullptr;//这里不要忘记判断!
ListNode* result=lists[temp];
ListNode* c=result;
lists[temp]=lists[temp]->next;
while( 1 )
{
flag=0;
temp=find(lists,flag);
if(flag!=n)
{
c->next=lists[temp];
c=c->next;
lists[temp]=lists[temp]->next;
}
else
{
break;
}
}
return result;
}
int find(vector<ListNode*>& lists,int& flag)
{
int n=lists.size();
int min=1e7;
int min_index;
for(int i=0;i<n;i++)
{
if(lists[i]!=nullptr)
{
if( lists[i]->val<min )
{
min=lists[i]->val;
min_index=i;
}
}
else
{
flag++;
}
}
return min_index;
}
};题解:
首先考虑合并两个链表,之前已经写过了,在贴贴题解的代码
ListNode* mergeTwoLists(ListNode *a, ListNode *b) {
if ((!a) || (!b)) return a ? a : b;
ListNode head, *tail = &head, *aPtr = a, *bPtr = b;
while (aPtr && bPtr) {
if (aPtr->val < bPtr->val) {
tail->next = aPtr; aPtr = aPtr->next;
} else {
tail->next = bPtr; bPtr = bPtr->next;
}
tail = tail->next;
}
tail->next = (aPtr ? aPtr : bPtr);
return head.next;
}
作者:LeetCode-Solution
链接:https://leetcode.cn/problems/merge-k-sorted-lists/solution/he-bing-kge-pai-xu-lian-biao-by-leetcode-solutio-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。方法一:顺序合并
思路:我们可以想到一种最朴素的方法:用一个变量ans来维护以及合并的链表,第i次循环把第i个链表和ans合并,答案保存到ans 中。
ListNode* mergeKLists(vector<ListNode*>& lists) {
ListNode *ans = nullptr;
for (size_t i = 0; i < lists.size(); ++i) {
ans = mergeTwoLists(ans, lists[i]);
}
return ans;
}方法二:分治合并
思路:考虑优化方法一,用分治的方法进行合并。将k个链表配对并将同一对中的链表合并;重复这一过程,直到我们得到了最终的有序链表。

ListNode* merge(vector <ListNode*> &lists, int l, int r) {
if (l == r) return lists[l];
if (l > r) return nullptr;
int mid = (l + r) >> 1;
return mergeTwoLists(merge(lists, l, mid), merge(lists, mid + 1, r));
}
ListNode* mergeKLists(vector<ListNode*>& lists) {
return merge(lists, 0, lists.size() - 1);
}方法三:使用优先队列合并
思路:这个方法和前两种方法的思路有所不同,我们需要维护当前每个链表没有被合并的元素的最前面一个,k 个链表就最多有 k 个满足这样条件的元素,每次在这些元素里面选取 val 属性最小的元素合并到答案中。在选取最小元素的时候,我们可以用优先队列来优化这个过程。
学习:
vector中元素的删除。在leetcode上试了一下,如下,是可行的,也就是说如果等于nullptr,其实在刚刚的步骤中,我们是可以删除来避免重复执行提高效率的。
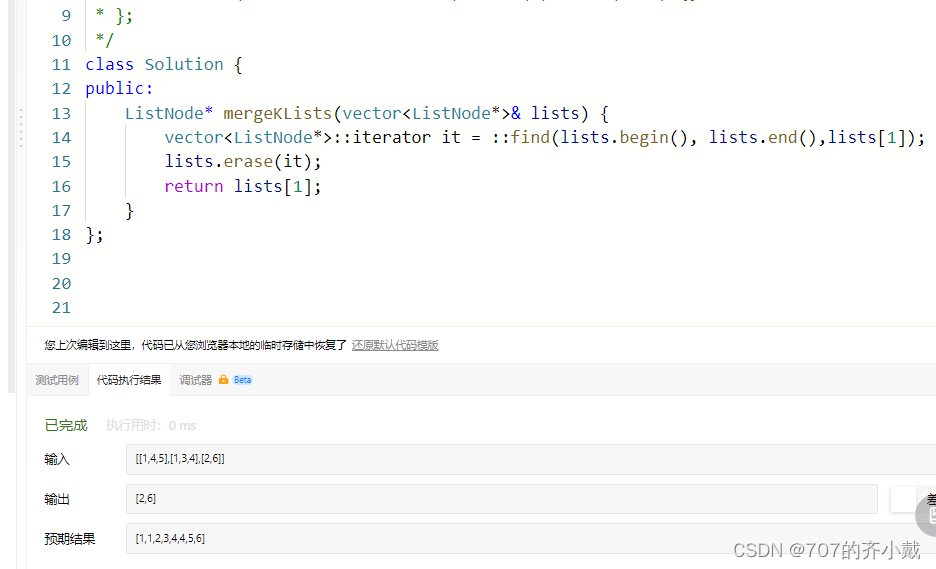
ListNode* mergeKLists(vector<ListNode*>& lists) {
vector<ListNode*>::iterator it = ::find(lists.begin(), lists.end(),lists[1]);
lists.erase(it);
return lists[1];
} 然后由于leetcode是提供了接口,而正如文章中所说find函数不是vector自带的,而是algorithm提供的,所以在执行的时候需要在find前面加上两个冒号 “ :: ” 。可以参考的连接:















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









