






使用python面向对象实现感知器算法
在这里使用感知器实现 or 函数
or 函数的真值表如下
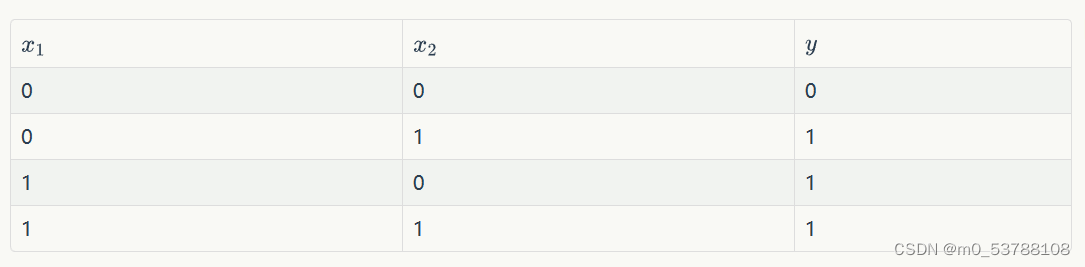
对应的要读入训练集为
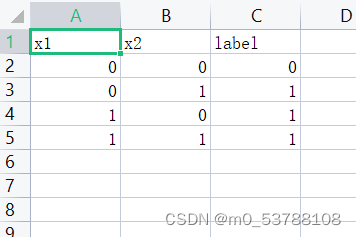
以下是对代码的解释:
首先导入包:
import pandas as pd
import numpy as np
创建感知器类,定义类属性,类属性包括学习率,训练集输入,训练集标签:
class Perceptron:
#学习率
l_rate = 0.1
#训练集输入
x = None
#训练集标签
label = None感知器类的构造方法,其中w_num为权重的个数,这里为2:
权值和偏置都初始化为0
#构造方法,创建对象时自动调用
def __init__(self, w_num):
# 权重向量初始化为0
self.weights = [0.0 for i in range(w_num)]
# 偏置项初始化为0
self.bias = 0.0读入训练集,使用pandas库读取csv文件:
#读入数据集,这里的函数可以根据数据集的情况进行修改
def get_dataset(self,filepath):
#读取数据集csv文件
# x为输入的特征值
x = pd.read_csv(filepath,usecols=['x1','x2'])
self.x = np.array(x)
#label为标签
label = pd.read_csv(filepath,usecols=['label'])
self.label = np.array(label)
#此时self.x为[[0 0],[0 1],[1 0],[1 1]]
#print('self.x:\n',self.x)
#此时self.label为[[0],[0],[0],[1]]
#print('self.label:\n',self.label)
激活函数,使用阶跃函数,该函数的图像为:
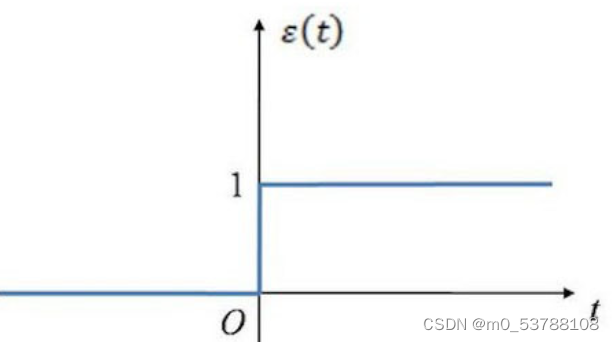
#激活函数,这里使用阶跃函数
def f(self,x):
return 1 if x>0 else 0感知器预测,求得预测值:
也就是对x进行乘以当前权值并相加,加上偏置,然后经过激活函数得到预测结果
# 根据先乘权值后求和,在经过激活函数的过程,得到感知器的预测结果
def predict(self,input):
sum = 0
#与权值相乘再求和
for i in range(len(input)):
wx = input[i] * self.weights[i]
sum += wx
sum = sum + self.bias
#调用激活函数得到预测结果
fx = self.f(sum)
return fx感知器训练,这里设置的迭代次数为5次:
#感知器训练,iteration为训练轮次
def train(self,iteration):
for i in range(iteration):
self.one_iteration()一次迭代过程,迭代次数取决于iteration(5次):
#一次迭代过程,把所有的训练数据过一遍
def one_iteration(self):
#计算当前权值下的感知器预测结果,对于每一个样本
for i in range(len(self.x)):
#print('self.x[i]',self.x[i])
fx = self.predict(self.x[i])
print('本次迭代第 %d 个样本预测值:%d' %(i+1 , fx))
# 对每个样本,按照感知器规则更新权重
self.update_weights(fx,i)
#print('本次迭代第'+ str(i+1) +'个样本更新后权值为',self.weights)
#print('本次迭代第' + str(i+1) + '个样本更新后偏置值为', self.bias)
print('本轮迭代后权值为', self.weights)
print('本轮迭代后偏置值为', self.bias)更新权重和偏置:
更新的方法为梯度下降算法
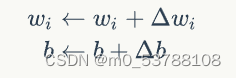 其中
其中
#更新权重
def update_weights(self,fx,i):
delta = self.label[i] - fx
#计算新的w值
self.weights[0] = self.weights[0] + self.l_rate * delta * self.x[i][0]
self.weights[1] = self.weights[1] + self.l_rate * delta * self.x[i][1]
# 更新bias
self.bias += self.l_rate * delta主函数:
if __name__ == '__main__':
# 训练or感知器
#创建感知器类对象
perception = Perceptron(2)
#读入数据集
perception.get_dataset('train.csv')
#训练 这里传入训练轮次5次
perception.train(5)
# # 测试
print('测试')
print('0 or 0 = %d' % perception.predict([0, 0]))
print('0 or 1 = %d' % perception.predict([0, 1]))
print('1 or 0 = %d' % perception.predict([1, 0]))
print('1 or 1 = %d' % perception.predict([1, 1]))进行测试:
运行结果:
C:\ProgramData\anaconda\python.exe D:/Python2/数据挖掘/perceptron.py
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:0
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.]), array([0.1])]
本轮迭代后偏置值为 [0.1]
本次迭代第 1 个样本预测值:1
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:0
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.1]), array([0.1])]
本轮迭代后偏置值为 [0.1]
本次迭代第 1 个样本预测值:1
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.1]), array([0.1])]
本轮迭代后偏置值为 [0.]
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.1]), array([0.1])]
本轮迭代后偏置值为 [0.]
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.1]), array([0.1])]
本轮迭代后偏置值为 [0.]
测试
0 or 0 = 0
0 or 1 = 1
1 or 0 = 1
1 or 1 = 1
Process finished with exit code 0
如果把读入的csv文件换成 and函数的训练集,进行测试:
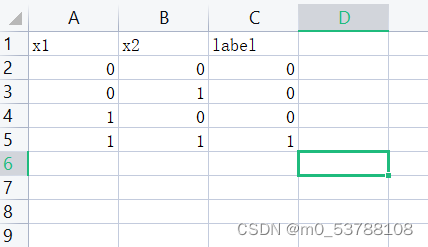
也可以实现预测,以下是and函数的测试结果:
C:\ProgramData\anaconda\python.exe D:/Python2/数据挖掘/perceptron.py
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:0
本次迭代第 3 个样本预测值:0
本次迭代第 4 个样本预测值:0
本轮迭代后权值为 [array([0.1]), array([0.1])]
本轮迭代后偏置值为 [0.1]
本次迭代第 1 个样本预测值:1
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:0
本次迭代第 4 个样本预测值:0
本轮迭代后权值为 [array([0.2]), array([0.1])]
本轮迭代后偏置值为 [0.]
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:0
本轮迭代后权值为 [array([0.2]), array([0.1])]
本轮迭代后偏置值为 [-0.1]
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:0
本次迭代第 3 个样本预测值:1
本次迭代第 4 个样本预测值:0
本轮迭代后权值为 [array([0.2]), array([0.2])]
本轮迭代后偏置值为 [-0.1]
本次迭代第 1 个样本预测值:0
本次迭代第 2 个样本预测值:1
本次迭代第 3 个样本预测值:0
本次迭代第 4 个样本预测值:1
本轮迭代后权值为 [array([0.2]), array([0.1])]
本轮迭代后偏置值为 [-0.2]
测试
0 or 0 = 0
0 or 1 = 0
1 or 0 = 0
1 or 1 = 1
Process finished with exit code 0















 210
210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









