






1. 索引(index)
索引本质上好比书的目录, 其作用就是如其名加快查找的速率
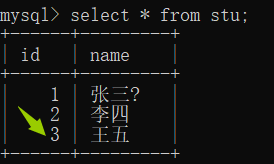
我们想要查询id为3的学生记录, 如果没有索引,那么我们需要遍历整个表, 相当于顺序查找, 那么时间复杂度是O(N). 这对于关系型数据库来说是致命
如果我们建立索引, 直接能查找到 id=3 的学生的信息在哪里, 那么就能很快的查询到数据
这里说明一下在mysql中索引是存储在内存中的, 实际的记录是存储在磁盘中的. 我们查询记录是根据索引去查询然后再在磁盘中快速的找到位置.
2. 索引适合的数据结构
我们先说一下一般的查找数据结构有什么 ?
比如哈希表, AVL数, 红黑树, 跳跃表等等 ?
那么什么是最适合mysql的呢?
2.1哈希表(不适合)
哈希表查询的效率是O(1)非常好了. 但是哈希表有一个致命的问题
那么就是不能处理范围查询
比如我们来一个这样的查询语句
select * from student where id > 3 and id < 6
| 哈希只能处理相等的情况,不能处理 >,<,>=,<=,between and… 的情况 |
2.2 二叉搜索树(不适合)
如果使用二叉搜索树, 其中序遍历是有序的, 这一点适合范围查找
例如查询id < 6 并且 id > 3 的学生信息
select * from student where id > 6 and id < 3
先找到id = 6的学生, 再找到 id = 3的学生
那么中间的部分就是我们想要的数据
但是中序遍历的效率是O(N)
相比于哈希表解决了查询范围问题, 但是效率还是很低的不适合
有以下两个原因
- 是二叉的数, 当我们数据过多时, 那么树的高度也会很高, 对于递归是有调用栈的. 当树的高度过高时, 直接把递归调用栈挤爆了. 那么程序就崩了.
- 中序遍历的效率是O(N), 不高效
2.3 B树(前提引入)
前面说了想要解决范围查找, 那么我们应该是需要使用树类型的结构.
mysql中实际的索引结构是B+树, 想要学习B+树, 我们需要先了解B树
这里我们先引入B树的概念
B树就是N叉树

B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。
相比于二叉搜索树的优点有 :
- 不再是二叉的而是N叉的, 树的高度就降低了很多, 栈溢出的风险就小了很多
- 叶子节点,非叶子节点,都可以存储数据,且可以存储多个数据
2. 4 B+树

如果所示 :
14,55,87是索引. 不存储实际的数据, 只存储索引- 实际的数据存储在叶子节点中.
- 实际的数据之间用链表连接在了一起, 比较容易的进行范围查找
- 叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的索引(primary key),用于查询加速,适合内存存储
B树,叶子节点和非叶子节点,都用来存储数据,且都存放在磁盘上,在查找的过程就会反复进行磁盘 IO 操作 B+树,叶子节点放到磁盘上,非叶子节点放到内存里,减少了磁盘的 IO 操作,查找效率就高了
使用B+树的目的是 加快查询效率, 但是会减慢增加删除和修改的效率
因为, 我们修改数据之后, 也会调整相应的索引结构
所以实际上是空间换时间了
经常使用的场景
应用在经常查询但是很少修改的场景上
















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











