







目录
一、线性模型定义:

-
线性模型可以看做单层神经网络。
-
一个最基础的线性回归模型可以看做一个全连接层或单层感知机。
-
训练阶段的目的是根据训练集中的输入input和真实标签值output计算出最拟合训练集的参数值组合。
显然上述定义存在一些盲点需要解决: #引出两个重要的原理
1.如何判断参数值组合是否更拟合训练集?使用损失函数(二)
2.如何更新参数值组合?使用梯度下降算法(三)
- 预测阶段的目的是根据测试集中的输入input计算预测值y^。
标准定义如下:
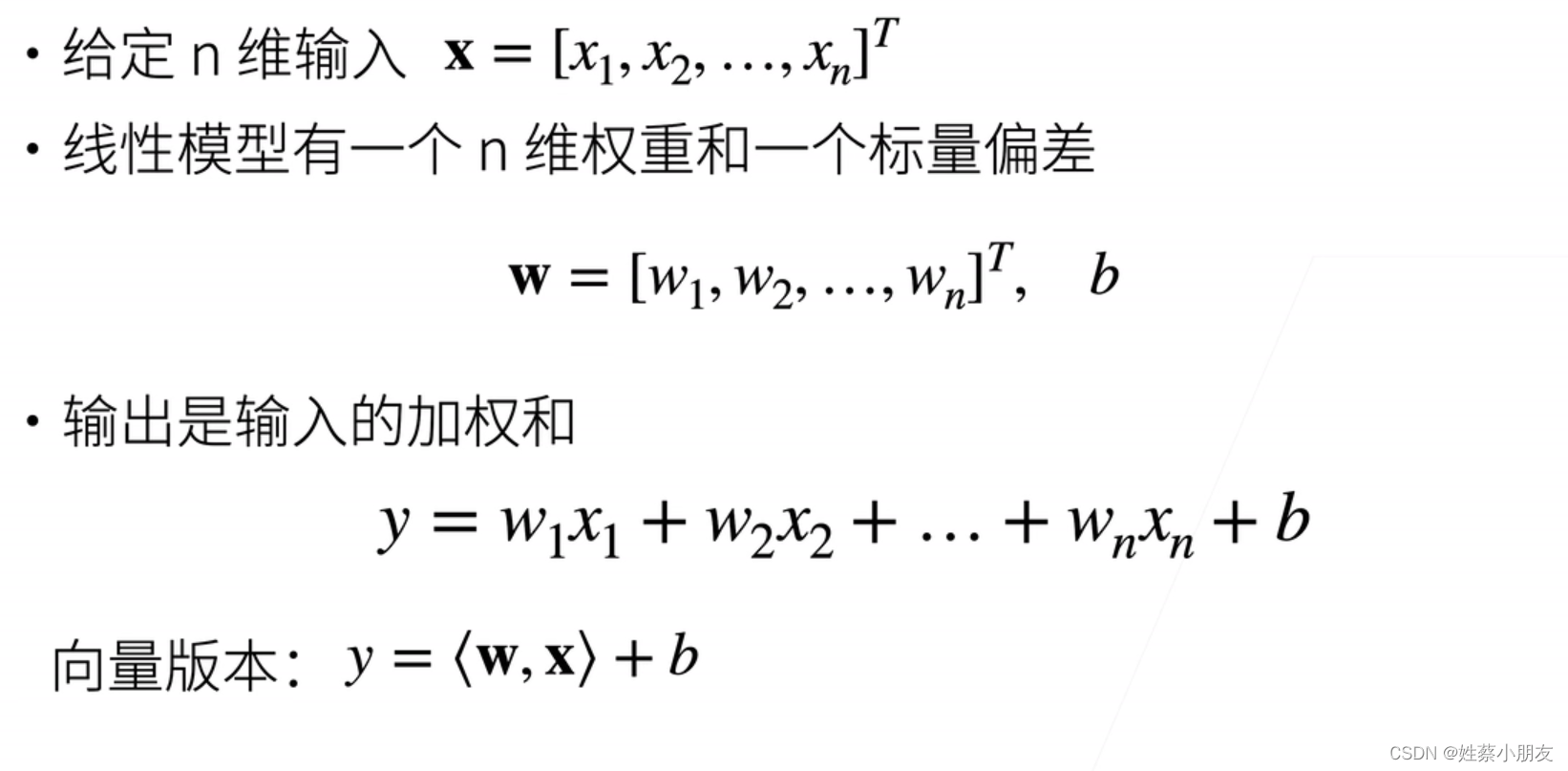
- x为一个样本输入数据input一维向量,即input中的一条数据。
- w为权重一维向量,值表示x对应位置所占的权重,属于模型的未知参数,训练开始前会赋初值。
- b为偏差值,属于模型的未知参数未知参数,训练开始前会赋初值。
- y为预测值,即加权平均值。
- 在预测阶段使用线性模型可以对每个样本数据x计算其预测值y。
二、训练阶段使用均方损失函数:

- 模型训练阶段,平方损失函数可以计算训练集中每个样本x(一维向量)的真实值y和预测值y^之间的差值L,来计算当前参数组合下的损失值。
- y为预测值
- y^为真实值
- L为当前参数组合下一条输入数据的损失
三、基础优化算法:梯度下降

- 使用梯度下降算法每次采取当前最优策略改变参数值以降低损失值,目的是调整参数寻找使得损失不断接近最小值的参数值组合。
- 等高线损失图中每个圈是一个固定数值,其中w0为初始参数值。
- 黄线方向是负梯度:参数值w沿负梯度方向下降最快。
- 学习率η:沿梯度个方向走多远距离,太大太小都影响参数收敛。
- 负梯度×学习率即沿负梯度方向走η距离。
- 接下来的时刻不断更新wt使其不断接近最优解,即w带入平方损失函数后损失值L最小。
四、线性回归模型训练过程:
1.数据描述:

- X为input
- y为output
- xi为每个样本数据,为一维向量
- yi为真实值,为数
2.损失函数:
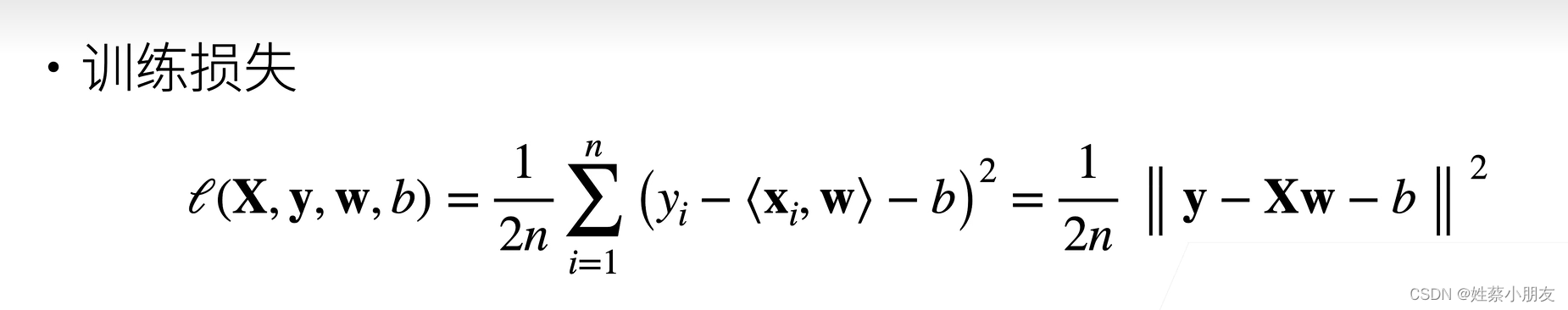
3.梯度下降算法:

4.训练目标:

- 训练数据的目的是根据梯度下降算法不断更新参数w、b,根据平方损失函数与真实值y和预测值y^不断计算L,得到的使得L最小的w、b即为w*、b*。
- 1/2来自损失函数
- 1/n求均值
- 对每个样本真实值y减每个样本预测值y^与偏差值b
五、线性回归实现:
%matplotlib inline
import random
import torch
from d2l import torch as d2l
#函数功能:根据“y=Xw+b+噪声”这个线性模型生成一个人造数据集
def synthetic_data(w, b, num_examples):
#X是均值为0,方差为1的大小为(num_examples, len(w))的向量
X = torch.normal(0, 1, (num_examples, len(w)))
#y=Xw+b+噪声
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
#真实值w
true_w = torch.tensor([2, -3.4])
#真实值b
true_b = 4.2
#根据函数计算特征矩阵和标签向量
features, labels = synthetic_data(true_w, true_b, 1000)
#函数功能:特征矩阵、标签向量作为输入,生成多个大小为batch_size大小的小批量batch_indices
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 打乱样本顺序,保证随机存取
random.shuffle(indices)
#每次循环从i----i+batch_size的下标中获取batch_size个样本,赋值给batch_indices作为一个小批量
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
#对每个小批量batch_indices计算其特征矩阵、标签向量
yield features[batch_indices], labels[batch_indices]
#定义初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
#定义模型
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
#定义损失函数
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
#定义优化算法:在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
#训练过程
lr = 0.03#lr是学习率
num_epochs = 3#num_epochs是训练过程的迭代次数
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
l.sum().backward() # l中的所有元素被加到一起,并以此函数计算关于[w,b]的梯度
sgd([w, b], lr, batch_size) # 使用参数w、b的梯度更新参数w、b
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
#输出损失值
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
六、为什么代码中不用指定参数个数:

在代码中我们需要指定输入的单个样本的维度in_feature和输出的单个样本的维度out_feature,这样实际上由矩阵乘法我们就能得到权重w和偏置值b的维度:

七、线性回归总结:
- 1.给定n个一维向量x和n个数y^作为训练集。
- 2训练阶段:
- 2.1.给定参数的初始值,其中每个特征xi对应一个权重参数wi。
- 2.2.训练过程中使用小批量梯度下降算法不断更新w、b的值。
- 2.3.对于当前w、b,不断使用线性模型计算预测值y。
- 2.4.对于当前y,不断使用平方损失函数计算损失L。
- 2.5.重复步骤345,其中每次循环都是一次在训练集batch上的迭代iteration。(Batch:每次梯度下降都使用整个训练集计算)
- 2.6.当参数收敛时3计算结果为0,不再更新参数值,输出最小L,此时w、b即为w*、b*。
- 2.7.此时我们就得到了最终的模型y=wx+b。

- 3.预测阶段:
- 3.1将输入x带入模型即可得到预测结果。

















 3677
3677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











