







文章行文思路:

注:本文为深度学习小白的学习记录,如有问题与建议,欢迎指正。纯小白,所以各位谨慎看待本文
目录
- 一、背景:
- 1.时间序列介绍:
- 2.LSTF介绍:
- 3.Transformer与Informer的关系:
- 二、Transformer:
- 1.Transformer简介:
- 2.Transformer整体架构:
- 3.模型输入:
- 3.1第一层Encoder输入:
- 3.11 细节说明:
- 3.111 “token”解释:
- 3.112 Embedding原理:
- 3.113 Positional Encoding原理:
- 3.114 “特征”解释:
- 3.2 第一层Decoder输入:
- 3.21 细节说明:
- 3.211 “标签列”解释:
- 4.Encoder:
- 4.1 Encoder组成与功能:
- 4.2 Self-Attention:
- 4.3 Multi-Head Attention:
- 4.4 Add残差连接:
- 4.5 Norm层归一化:
- 4.6 Feed-Forward Networks:
- 4.7 Encoder堆叠:
- 5.Decoder:
- 5.1 Decoder组成与功能:
- 5.2 Masked Multi-Head Attention:
- 5.3 Multi-Head Attention:
- 5.4 Decoder堆叠:
- 6.模型输出:
- 7.Transformer训练和预测过程总结:
- 三、Informer:
- 1.简介:
- 2.传统Transformer在时序预测方面缺点和Informer改进方法:
- 3.Informer整体架构:
- 4.Informer优化详解:
- 4.1 ProbSparse Self-attention:
- 4.2 Self-attention Distilling:
- 4.3 Generative Style Decoder:
- 4.4 Positional Encoding:
- 5.模型输入输出角度理解Informer训练和预测过程:
- 5.1 Encoder Embedding输入:
- 5.2 Decoder Embedding输入:
- 5.3 Embedding输入输出:
- 5.31 输入:
- 5.32 输出:
- 5.4 ProbSparse Self-attention输入输出:
- 5.41 输入:
- 5.42 Active输出:
- 5.43 Active+Lazy输出:
- 5.43 多头注意力合并:
- 5.5 Encoder输入输出:多个Encoder和蒸馏层的组合
- 5.51 输入:
- 5.52 输出:
- 5.6 Decoder输入输出:
- 5.61 输入:
- 5.62 输出:
- 四、Informer代码介绍:
- 1.项目结构:
- 2.参数讲解:
- 3.替换自己的数据集并调优:
- 3.1固定参数调整:
- 3.2数据字典中增加数据集信息:
- 3.3用于调优的参数:
- 4.代码讲解:
- 5.运行过程:
- 5.1 模型训练:
- 5.11 Informer架构输入:
- 5.12 Informer架构运行+输出:
- 5.2 模型预测:
- 6.代码优化:
- 6.1 len( )函数可能编写错误,导致控制台输出训练集测试集验证集长度时数目不对:
- 6.2 代码训练+测试+预测模块糅杂在一块,无法直接调用模型进行预测的问题:
- 6.3 采用了很多随机化操作导致同一组参数训练出的模型差异很大的问题(稳定性):
- 五、实验
- 1.数据集讲解:
- 1.1介绍:
- 1.2相关论文:
- 1.3各个字段详解:
- 1.3.1 metadata.csv记录了各建筑的信息。每行代表一栋建筑,列含义如下:
- 1.3.2 weather.csv记录了每小时site的天气状况。每行代表一个site在timestamp小时内的天气状况,列含义如下:
- 1.3.3 electricity.csv:
- 1.3.4 irrigation.csv:
- 1.3.5 chilledwater.csv:
- 1.3.6 gas.csv:
- 1.3.7 hotwater.csv:
- 1.3.8 water.csv:
- 1.3.9 solar.csv:
- 1.3.10 steam.csv:
- 2.实验流程:
- 2.1滑动窗口机制概述:
- (1)知识点回顾:
- (2)滑动窗口实现原理:
- (3)滑动窗口优势:
- 3.数据收集与分析:
- 4.数据预处理:
- 5.模型训练:
- 6.调用模型预测(对接前端版):
- 7.预测结果评估:
- 8.前端展示:
一、背景:
1.时间序列介绍:
时间序列是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。
时间序列分析的主要目的是根据已有的历史数据对未来数据进行预测。经济数据中大多数以时间序列的形式给出。根据观察时间的不同,时间序列中的时间可以是年份、季度、月份或其他任何时间形式。
2.LSTF介绍:
LSTF(Long Sequence Time-Series Forecasting)即长序列时间序列预测。
它是时间序列预测问题的一种特殊场景,要求模型具有很高的预测能力,即能够有效地捕捉输出和输入之间精确的长程相关性耦合。在实际应用中,如用电量使用规划等问题中,需要对长序列时间序列进行预测。
3.Transformer与Informer的关系:
Informer和Transformer都是神经网络架构。
Informer是在Transformer的基础上进行了改进和优化,旨在提高处理长序列的速度和效率。
因此学习Informer前提是掌握Transformer。故我们在本文中首先详细讲解Transformer,然后在讲解Informer时主要讲解其在Transformer上的改进。
二、Transformer:

论文地址:Transformer论文地址
1.Transformer简介:
目前,在NLP领域当中,主要存在三种特征处理器——CNN、RNN以及Transformer,当前Transformer的流行程度已经大过CNN和RNN,它抛弃了传统CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成。
BERT算法(进击的巨人)的最重要的部分便是Transformer的概念,它本质上是Transformer的编码器部分。自从Transformer使用了抛弃RNN、CNN的纯Attention机制之后,各种基于Transformer结构的预训练模型都如雨后春笋般雄起,本文中Informer便是其中一员。
2.Transformer整体架构:

Transformer的结构图,拆解开来,主要分为图上4个部分,接下来我将按照1,2,3,4的顺序逐步介绍上图中Transformer的网络结构,这样既能够弄清楚结构原理,又能够方便理解Transformer模型的工作流程。
3.模型输入:
3.1第一层Encoder输入:

第一步: 以用电量时间序列预测为例,Inputs为n个时间步长(实验中以96h为例)的用电量数据,经过Embedding后将每个小时的用电量数据升维成d维(实验中以512维为例)的向量,因此Embedding的输出是一个包含n个token的序列,每个token用一个d维(512)向量表示,可以用矩阵x表示(x的大小是d×n)

第二步: inputs执行embedding后需要给每个token添加位置编码positional encoding,因为时间序列的时间特征也很重要,例如用电量数据往往具有周期性(周一至周五家庭用电量少,周六至周日家庭用电量多),所以我们需要对每个token进行位置编码,生成矩阵y(y的大小是d×n)。

第三步: 矩阵x与y进行相加,作为Encoder的输入。

注:仅第一层Encoder输入同上,后续Encoder的输入不再同上,而是上一层Encoder的输出。
3.11 细节说明:
3.111 “token”解释:
在时间序列预测的上下文中,token通常指的是输入序列中的一个基本单元或元素,对于用电量时间序列数据,每个token代表一个时间步长(小时)的用电量数据。例如,如果你有一个按小时记录的用电量数据集,每个token可能就是一个小时的用电量值。
3.112 Embedding原理:
Embedding对低维数据进行升维时,会把一些特征给放大,或者把笼统的特征给分开。
原理就是矩阵乘法,其中被乘数是时间序列数据,乘数是嵌入矩阵Embedding Matrix,Embedding Matrix在训练过程中根据反向传播算法和优化器进行更新,使得时间序列数据在乘Embedding Matrix后能更好地放大其数据中的特征。
因此,这个Embedding层一直在学习优化,使得整个数据升维过程慢慢形成一个良好的观察点,即Embedding Matrix。
3.113 Positional Encoding原理:
Transformer使用的是正余弦位置编码。位置编码通过使用不同频率的正弦、余弦函数生成,然后和对应的位置的词向量相加,位置向量维度必须和词向量的维度一致。

3.114 “特征”解释:
特征即数据中有用的数据信息,例如每个时间步的用电量值…
3.2 第一层Decoder输入:

Decoder的输入与Encoder的输出处理方法步骤是一样的,区别是Encoder输入为特征数据,而Decoder输入为标签target数据。
注意Decoder在训练阶段target为真实值,并且用到了mask机制(详见Decoder层),而在预测阶段target为空,即模型不接收target输入。
对应到上面例子里面就是:在多变量预测单变量的用电量预测中,使用图书馆、办公楼的用电量数据预测信息楼的用电量数据。
- 模型训练阶段 Encoder输入的是图书馆、办公楼的用电量数据,Decoder输入的是执行mask机制后信息楼的用电量数据真实值(因为mask所以每层输入的真实值个数是递增的)。
- 模型预测阶段 Encoder输入的是图书馆、办公楼的用电量数据,第一层Decoder输入为Null。Decoder每次输入是上一时刻Transformer的输出。例如,输入"",输出"信息楼1/1用电量预测",输入"信息楼1/1用电量预测",输出"信息楼1/1与1/2用电量预测"…
3.21 细节说明:
3.211 “标签列”解释:
在多变量预测单变量的用电量预测中,使用图书馆、办公楼的用电量数据预测信息楼的用电量数据。特征列即为图书馆、办公楼的用电量数据,标签列即为被预测的数据列,即信息楼的用电量数据。
4.Encoder:

4.1 Encoder组成与功能:
Encoder由多头注意力机制Multi-Head Attention和前馈神经网络Feed Forward Network组成,用于捕捉输入序列中的上下文关系和特征表示。Encoder重复堆叠N层有助于提取输入序列中的深层特征表示。
举例来说:用269栋建筑的用电量数据预测第270栋建筑的用电量数据时,Encoder部分负责计算269栋建筑用电量的相关性信息,并通过跨注意力机制将这些信息(编码矩阵)传递给Decoder。
4.2 Self-Attention:
简单来说,注意力Attention就是:输入序列较重要点获得较高的权重(更多的注意力),不重要的点获得较低权重(更少的注意力)
注意力机制函数入参:查询向量 Q、键向量 K、值向量 V通过对输入序列的线性变换(矩阵乘法)得到,其中X为Encoder输入的矩阵,X的每行为一个token,X通过乘三个权值矩阵WQ,WK,WV ,转变成为计算Attention值所需的Query,Keys,Values向量。其中矩阵WQ,WK,WV 为三个超参数,在模型训练阶段不断更新。

Q,K,V第n行代表的是X第n行的token的数据信息。 得到Q,K,V之后,接下来就是计算Attention值了。


- QKT是为了计算查询矩阵Q中每个行向量q(代表之前的每个token)与键矩阵K中每个行向量k之间的相关性,获得每个查询向量q与每个键向量k之间的注意力分数。
- 除根号√dk是归一化操作,目的是确保注意力权重的分布更加均匀、训练时梯度能够稳定,其中dk就是K的维度。
- Softmax()回归将输入的向量转化为具有和为1的概率分布,用概率分布更好的体现查询向量q与每个键向量k之间的相关性。
- 乘值矩阵V做加权目的是得到最终的注意力,为了突出与每个查询向量q更相关的序列部分。
注意力机制的目的是:突出查询向量q与每个键向量k之间的相关性,从而强调输入序列中与该查询向量更相关的部分。
4.3 Multi-Head Attention:
单一的注意力机制能挖掘到的信息有限,通过多次自注意力计算来关注序列不同位置的子空间表示信息,同时不同的头可以关注序列的不同特征表示,从而更好地提取输入序列中的特征。
self-attention只使用了一组WQ,WK,WV来进行变换得到Query,Keys,Values。而Multi-Head Attention使用多组WQ,WK,WV得到多组Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接,合并输出全局特征Z。Transformer里面是使用了8组不同的WQ,WK,WV

- 每个头Head有单独的WQ,WK,WV,所有WQ,WK,WV在模型训练阶段都做为超参数不断更新。
4.4 Add残差连接:
防止在深度神经网络训练中发生退化问题,即深度神经网络通过增加网络的层数,Loss逐渐减小,然后趋于稳定达到饱和,然后再继续增加网络层数,Loss反而增大。
4.5 Norm层归一化:
能够加快训练的速度、提高训练的稳定性。归一化使得使每一行的概率和为1,归一化后的数据在进行梯度下降寻找最优参数时,更容易找到最优解。
4.6 Feed-Forward Networks:

这里的全连接层是一个两层的神经网络,先线性变换,然后ReLU非线性,再线性变换。
这两层网络就是为了将输入的Z映射到更加高维的空间中,然后通过非线性函数ReLU进行筛选,筛选完后再变回原来的维度。

通过这种前馈网络的设计,Transformer 模型能够学习到输入序列中的更复杂的特征和模式, 从而提高模型的表达能力和泛化能力。
4.7 Encoder堆叠:
Feed-Forward Networks输出经过Add&Normalize,输入下一个Encoder中,经过6个Encoder后最终输出的是每个输入token对应的上下文向量表示,也称为"编码矩阵"(encoding),其中包含了每个token与其余token的关系(全局相关性)信息,最后输入到decoder中。
5.Decoder:

5.1 Decoder组成与功能:
每个Decoder有两个Multi-Head Attention层和一个Feed Forward Network组成。第一个Multi-Head Attention层采用了Masked操作。第二个Multi-Head Attention层的K、V矩阵输入源来自Encoder的输出编码矩阵,而Q矩阵是由经过Add & Norm层之后的输出计算来的。Decoder在训练过程中通过Encoder的编码矩阵和带预测值的真实值来生成预测序列,并通过损失函数和优化算法来优化模型的预测能力。这样,模型就可以学会利用编码矩阵和上一时间步的标签来预测当前时间步的标签列。
举例来说:用269栋建筑的用电量数据预测第270栋建筑的用电量数据时,Decoder利用Encoder的编码矩阵以及第270栋建筑的真实用电量数据来生成预测序列,并通过损失函数和优化算法来优化模型的预测能力。这样,模型就可以学会利用其他建筑的用电量数据来预测第270栋建筑的用电量。
5.2 Masked Multi-Head Attention:
Masked Multi-Head Attention的功能是为了得到之前已经预测输出的真实值信息。
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。对于一个序列,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。实现思路为:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
这在训练的时候有效,因为训练的时候采用Teacher Forcing的训练方式,每次我们是将target真实数据 (答案) 完整输入进Decoder中的,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。

5.3 Multi-Head Attention:
Decoder中Multi-Head Attention的功能是通过当前的输入与经过Encoder提取过的编码矩阵来预测输出。
它的输入Query来自于Masked Multi-Head Attention的输出,Keys和Values来自于Encoder中最后一层的输出。为了让Decoder能够利用Encoder中的信息,学习到输入序列的全局依赖关系和重要特征,从而更好地生成输出序列。
5.4 Decoder堆叠:
经过第二个Multi-Head Attention之后的Feed Forward Network与Encoder中一样,然后就是输出作为下一个Decoder的输入,如此经过6层Decoder之后到达最后的输出层。
6.模型输出:

首先经过一次线性变换,然后Softmax得到输出的概率分布,然后通过词典,输出概率最大对应的值作为我们的预测输出。
7.Transformer训练和预测过程总结:
用269栋建筑的用电量数据预测第270栋建筑的用电量数据为例:
- 训练阶段:
- Encoder部分负责计算269栋建筑用电量的相关性信息,并通过跨注意力机制将这些信息(编码矩阵)传递给Decoder。
- Decoder利用Encoder的编码矩阵以及第270栋建筑的真实用电量数据(注意使用mask机制)来生成预测序列,并通过损失函数和优化算法来优化模型的预测能力,获取最优超参数。这样,模型就可以学会利用其他建筑的用电量数据来预测第270栋建筑的用电量。
- 预测阶段:
- 预测阶段所有超参数已经确定,且为已知常数值。
- Encoder部分负责计算269栋建筑用电量的相关性信息,并通过跨注意力机制将这些信息(编码矩阵)传递给Decoder。
- Decoder利用Encoder的编码矩阵以及模型来生成预测序列(例如模型为y=ax+b,ab为超参数已知,通过传入编码矩阵x到模型中计算第270栋建筑的预测值y),具体来说,预测值的生成不是一次完成的,而是一个一个的,首先会给Decoder输入开始标志(第一层Decoder输入为Null),然后经过Decoder会预测出第270栋建筑11/1日的用电量预测值,然后拿着第270栋建筑11/1日的用电量预测值作为Decoder输入去预测第270栋建筑11/2日的用电量预测值,但后拿着第270栋建筑11/1、11/2日的用电量预测值作为Decoder输入去预测第270栋建筑11/3日的用电量预测值,以此类推。
三、Informer:

1.简介:
Informer是一种专为 长序列时间序列预测(LSTF) 设计的Transformer模型。相较于传统的Transformer,Informer具备了三个独特特点。首先,他采用ProbSparse自注意力机制,具有O(LlogL)的时间复杂度和内存使用。能够有效捕获序列中的长期依赖关系。其次,通过自注意力蒸馏技术,Informer能够高效处理极长的输入序列。最后,Informer的生成式解码器可以一次性预测整个长时间序列,在预测过程中大幅提高了效率。经过大规模数据集的实验验证,Informer在LSTF问题上表现优秀,为长序列时间序列预测提供了一种高效准确的解决方案,克服了传统Transformer模型的限制。
2.传统Transformer在时序预测方面缺点和Informer改进方法:
| Transformer的缺点 | Informer的改进 |
|---|---|
| self-attention平方级的计算复杂度 | 提出ProbSparse Self-attention筛选出最重要的Q,降低计算复杂度 |
| 堆叠多层网络,内存占用瓶颈 | 提出Self-attention Distilling进行下采样操作,减少维度和网络参数的数量 |
| step-by-step解码预测,速度较慢 | 提出Generative Style Decoder,一步可以得到所有预测的 |
3.Informer整体架构:

4.Informer优化详解:
4.1 ProbSparse Self-attention:

通过以上图可以看到,并不是每个q与k之间都具有很高的相关性(内积),即不是所有q都具有很高的活跃度,我们不需要花很多时间在处理这些弱活跃度的q上,因为这些q提取不出数据间的相关性和好的特征。这就是该算法改进的突破口。
改进算法如下:
(1)输入序列长度为96,首先在K中进行采样,随机选取25个k。
(2)计算每个q与25个k的内积,现在一个q一共有25个得分。
(3)每个q在25个得分中,选取最高分的与均值算差异。
(4)这样我们输入的96个q都有对应的差异得分,我们将差异从大到小排列,选出差异前25大的q。
(5)其他淘汰掉的q使用V向量的平均来代替。
4.2 Self-attention Distilling:

在相邻的Attention Block之间加入卷积池化操作,来对特征进行降采样。对输入维度进行修剪,堆叠n层,每层输入序列长度减半,从而将空间复杂度降低到O(nlogn)
4.3 Generative Style Decoder:

源码中的decoder输入长度为72,其中前48是真实值,后24是预测值。我们可以理解为一段有效的标签值(48个真实值)带着一群预测值(24个待预测值)进行学习,这种方法可以一步到位生成目标序列,不需要再使用动态解码。
4.4 Positional Encoding:

Informer在Transformer位置编码(Local Time Stamp)的基础上,加入了Global Time Stamp,可以更好的提取输入序列中的时间特征。
Encoder输入改进如下:
- Scalar:Embedding升维
- Local Time Stamp:位置编码
- Global Time Stamp:提取时间特征
5.模型输入输出角度理解Informer训练和预测过程:
数据集:BDG2
(小时维度的数据) 数据规格:17420 * 320
Batch_size:32
5.1 Encoder Embedding输入:

Xenc = 32 × 96 × 320
- 32为batch大小,一个batch有32个样本,一个样本代表96个时间点的数据。
- 320为每个数据的维度,表示每个时间点数据(每行)有320列。
Xmark = 32 × 96 × 4
- 32 × 96同上,表示每个时间点的数据都要有一个位置编码,Xmark与Xenc每行一一对应。
- 4为时间戳,例如我们用小时维度的数据,那么4分别代表年、月、日、小时,
5.2 Decoder Embedding输入:

Xdec = 32 × 72 × 320
Xmark = 32 × 72 × 4
- 72=48+24,其中48为Encoder96的后48个时间点数据,用这些真实值来带一带预测值,24为待预测值。
- 48为绿色部分,24为白色部分填充0(mask机制)
5.3 Embedding输入输出:
将维度为320/7的一个时间点的数据投影成维度为512的数据。
5.31 输入:
32 × 96/72 × 320
32 × 96/72 × 4
5.32 输出:
32 × 96/72 × 512
5.4 ProbSparse Self-attention输入输出:
5.41 输入:
32 × 8 × 96 × 64 (8 × 64 = 512,这也是多头的原理,即8个头)
5.42 Active输出:
32 × 8 × 25 × 64 (只取25个活跃q)
5.43 Active+Lazy输出:
32 × 8 × 96 × 64 (除了25个活跃q,其余q用V向量的平均来代替)
5.43 多头注意力合并:
32 × 96 × 512
5.5 Encoder输入输出:多个Encoder和蒸馏层的组合
5.51 输入:
32 × 96 × 512(来自上面embedding 长度为96的部分)
5.52 输出:
32 × 51 × 512(这里的51应该是conv1d卷积取整导致的,因为源码要自行调整,所以是这样的)
5.6 Decoder输入输出:
5.61 输入:
32 × 51 × 512 & 32 × 72 × 512(32 × 51 × 512是Encoder输出,32 × 72 × 512是Decoder Embedding后的输入)
5.62 输出:
32 × 72 × 512
四、Informer代码介绍:
1.项目结构:

2.参数讲解:
| 参数名称 | 参数含义 |
|---|---|
| model | 使用的网络结构(方便对比实验) |
| data | 数据集名称 |
| root_path | 根路径 |
| data_path | 根路径下的文件名 |
| features | 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量 |
| target | 哪一列要当作是标签,如果features=M该值则没有意义 |
| freq | 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样) |
| checkpoints | 模型最后保存位置 |
| seq_len | 当前输入序列长度(可自定义),计算attention时每个batch以96行作为最小单位 |
| label_len | 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len |
| pred_len | 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值 |
| enc_in | 解码器输入维度,你数据有多少列,要减去时间那一列 |
| dec_in | 编码器输入维度,你数据有多少列,要减去时间那一列 |
| c_out | 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据 |
| d_model | 隐层特征,enc和dec输出维度,数据中列数不能大于该值,必须是偶数 |
| n_heads | 多头注意力机制,头越多注意力越好 |
| e_layers | 堆叠几层enc |
| d_layers | 堆叠几层dec |
| s_layers | 堆叠几层encoder layers |
| d_ff | 全连接层(多层感知机)输出维度 |
| factor | 对Q进行采样,对Q采样的因子数 |
| padding | 数据填充 |
| distil | 是否下采样操作pooling |
| dropout | 防止过拟合数据丢弃的概率 |
| attn | 注意力机制 |
| embed | 时间特征的编码方式 |
| activation | 激活函数 |
| output_attention | 是否在编码器中输出注意力 |
| do_predict | 是否执行predict函数 |
| mix | 在生成式解码器中是否使用混合注意力 |
| cols | 读数据列 |
| num_workers | windows用户只能给0 |
| itr | 实验运行次数 |
| train_epochs | 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练 |
| batch_size | 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size,越大梯度越准确 |
| patience | 停止策略,如果多少个epoch损失没有改变就停止训练 |
| learning_rate | 初始学习率 |
| des | 实验描述 |
| loss | 损失函数 |
| lradj | 学习率的调整方式 |
| use_amp | 是否为分布式 |
| inverse | 反归一化 |
| use_gpu | 是否使用gpu |
| gpu | gpu编号 |
| use_multi_gpu | 使用多个gpu |
| devices | 如果为分布式指定有几个显卡 |
| pred_path_only | 是否仅调用模型执行预测 |
3.替换自己的数据集并调优:
3.1固定参数调整:
# 读的数据是什么(类型 路径)
parser.add_argument('--data', type=str, default='ECL_Rat', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ECL_Rat.csv', help='data file')
# 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 哪一列要当作是标签,如果features=M该值则没有意义
parser.add_argument('--target', type=str, default='Rat_lodging_Christine', help='target feature in S or MS task')
# 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样)
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 编码器、解码器输入维度,你数据有多少列,要减去时间那一列。!!!注意!!!:数据中列数不能太多
parser.add_argument('--enc_in', type=int, default=269, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=269, help='decoder input size')
# 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据
parser.add_argument('--c_out', type=int, default=1, help='output size')
3.2数据字典中增加数据集信息:
#定义数据文件字典
data_parser = {
'ETTh1': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm1': {'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]},
'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]},
'electricity_cleaned': {'data': 'electricity_cleaned.csv', 'T': 'Hog_office_Denita', 'M': [270, 270, 270], 'S': [1, 1, 1], 'MS': [270, 270, 1]},#逗号不能去?
'ECL_Rat': {'data': 'ECL_Rat.csv', 'T': 'Rat_lodging_Christine', 'M': [269, 269, 269], 'S': [1, 1, 1], 'MS': [269, 269, 1]},
'ECL_Fox': {'data': 'ECL_Fox.csv', 'T': 'Fox_education_Jaclyn', 'M': [7, 7, 1], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
}
#配置每个文件处理数据的方式,有三种处理方式可选:data_loader类下{Dataset_ETT_hour,Dataset_ETT_minute,Dataset_Custom}
data_dict = {
'electricity_cleaned': Dataset_Custom,
'ETTh1':Dataset_ETT_hour,
'ETTh2':Dataset_ETT_hour,
'ETTm1':Dataset_ETT_minute,
'ETTm2':Dataset_ETT_minute,
'WTH':Dataset_Custom,
'ECL':Dataset_Custom,
'ECL_Rat': Dataset_Custom,
'ECL_Rat_UsePredict': Dataset_Custom,
'ECL_Fox': Dataset_Custom,
'ECL_Fox_UsePredict': Dataset_Custom,
}
3.3用于调优的参数:
在大概了解模型原理的基础上,采用控制变量法逐一对各个参数值调整+对比实验结果,找到一组最优参数。
# 当前输入序列长度(可自定义),计算attention时每个batch以96行作为最小单位
parser.add_argument('--seq_len', type=int, default=72, help='input sequence length of Informer encoder')
# 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值
parser.add_argument('--pred_len', type=int, default=168, help='prediction sequence length')
# 隐层特征,enc和dec输出维度,数据中列数不能大于该值,必须是偶数 初始512,最优912,但是内存占用过高,选择次优624
parser.add_argument('--d_model', type=int, default=624, help='dimension of model')
# 多头注意力机制,头越多注意力越好 初始8,最优14
parser.add_argument('--n_heads', type=int, default=10, help='num of heads')
# 堆叠几层enc和dec 初始2,1 ,整体最优2,1, 2,2在一开始拟合效果特别好,最差4,2
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 堆叠几层encoder
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
#全连接层(多层感知机)输出维度 初始2048(512*4),越大后面拟合度越小
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 对Q进行采样,对Q采样的因子数,factor=5最优
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
# 数据填充
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 防止过拟合数据丢弃的概率
parser.add_argument('--dropout', type=float, default=0, help='dropout')
# 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练 初始6,比8,10优,在训练集上过拟合
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size,越大梯度越准确 初始32,比24,48优
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 停止策略,如果多少个epoch损失没有改变就停止训练
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
4.代码讲解:
略…
5.运行过程:
5.1 模型训练:
5.11 Informer架构输入:
数据集.csv文件+参数值
5.12 Informer架构运行+输出:
- 调用train( )函数在70%训练集上训练并使用10%验证集进行验证,根据验证结果调整超参数。最终生成最优超参数的模型文件保存在checkpoint文件夹中。
exp.train(setting)
def train(self, setting):
#读数据制作训练集
train_data, train_loader = self._get_data(flag = 'train')
#读数据制作验证集(执行流程同训练集)
vali_data, vali_loader = self._get_data(flag = 'val')
#读数据制作测试集(执行流程同训练集)
test_data, test_loader = self._get_data(flag = 'test')
#判断checkpoint路径是否存在,若不存在自动新建
path = os.path.join(self.args.checkpoints, setting)
if not os.path.exists(path):
os.makedirs(path)
#指定单元时间
time_now = time.time()
#根据batch大小执行训练次数
train_steps = len(train_loader)
#提前停止策略
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
#优化器普遍使用ADM
model_optim = self._select_optimizer()
#损失函数
criterion = self._select_criterion()
#windows忽略
if self.args.use_amp:
scaler = torch.cuda.amp.GradScaler()
#执行train_epochs轮
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
self.model.train()
epoch_time = time.time()
#每轮执行train_loader调用data_loader中的__getitem__()函数取数据
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(train_loader):
iter_count += 1
#梯度清零
model_optim.zero_grad()
#对输入的一个batch数据(batch_x, batch_y, batch_x_mark, batch_y_mark)计算预测值pred和真实值true=(batch_x, batch_y)
pred, true = self._process_one_batch(
train_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
#计算损失
loss = criterion(pred, true)
train_loss.append(loss.item())
if (i+1) % 100==0:
print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time()-time_now)/iter_count
left_time = speed*((self.args.train_epochs - epoch)*train_steps - i)
print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
if self.args.use_amp:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss.backward()
model_optim.step()
print("Epoch: {} cost time: {}".format(epoch+1, time.time()-epoch_time))
train_loss = np.average(train_loss)
vali_loss = self.vali(vali_data, vali_loader, criterion)
test_loss = self.vali(test_data, test_loader, criterion)
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
#调整学习率,学习率变化都是固定的
adjust_learning_rate(model_optim, epoch+1, self.args)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
return self.model
- 最后调用test( )在20%测试集的前pred_len个时间步进行测试,生成pred.npy预测值、true.npy真实值和metric.npy误差。
exp.test(setting)
def test(self, setting):
test_data, test_loader = self._get_data(flag='test')
self.model.eval()
preds = []
trues = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(test_loader):
pred, true = self._process_one_batch(
test_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
preds.append(pred.detach().cpu().numpy())
trues.append(true.detach().cpu().numpy())
preds = np.array(preds)
trues = np.array(trues)
print('test shape:', preds.shape, trues.shape)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])
print('test shape:', preds.shape, trues.shape)
# result save
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
mae, mse, rmse, mape, mspe = metric(preds, trues)
print('mse:{}, mae:{}'.format(mse, mae))
np.save(folder_path+'metrics.npy', np.array([mae, mse, rmse, mape, mspe]))
np.save(folder_path+'pred.npy', preds)
np.save(folder_path+'true.npy', trues)
return
- 最后调用predict( )用测试集最后seq_len个时间步作为输入,预测未来pred_len个时间步的预测值,生成real_prediction.npy。
def predict(self, setting, load=False):
#获取用于预测的数据和数据加载器
pred_data, pred_loader = self._get_data(flag='pred')
if load:#
path = os.path.join(self.args.checkpoints, setting)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
#将模型设置为评估模式
self.model.eval()
#创建一个空列表用于存储预测结果
preds = []
#遍历预测数据加载器,对每个批次的数据进行预测
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(pred_loader):
#对一个批次的数据进行预测,并获取预测结果和真实值
pred, true = self._process_one_batch(
pred_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
#将预测结果添加到preds列表中
preds.append(pred.detach().cpu().numpy())
#将preds列表转换为NumPy数组
preds = np.array(preds)
#根据模型输出的形状重新整理预测结果的维度
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
# 设置保存结果的文件夹路径
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
#将预测结果保存为Numpy数组文件
np.save(folder_path+'real_prediction.npy', preds)
return
5.2 模型预测:
- 输入csv文件(包含seq_len个时间步作为输入),调用模型传入csv文件使用predic( )函数预测未来pred_len个时间步的预测值,生成real_prediction.npy。
def predict(self, setting, load=False):
#获取用于预测的数据和数据加载器
pred_data, pred_loader = self._get_data(flag='pred')
if load:#
path = os.path.join(self.args.checkpoints, setting)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
#将模型设置为评估模式
self.model.eval()
#创建一个空列表用于存储预测结果
preds = []
#遍历预测数据加载器,对每个批次的数据进行预测
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(pred_loader):
#对一个批次的数据进行预测,并获取预测结果和真实值
pred, true = self._process_one_batch(
pred_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
#将预测结果添加到preds列表中
preds.append(pred.detach().cpu().numpy())
#将preds列表转换为NumPy数组
preds = np.array(preds)
#根据模型输出的形状重新整理预测结果的维度
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
# 设置保存结果的文件夹路径
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
#将预测结果保存为Numpy数组文件
np.save(folder_path+'real_prediction.npy', preds)
return
6.代码优化:
(新手学习记录)
6.1 len( )函数可能编写错误,导致控制台输出训练集测试集验证集长度时数目不对:
def __len__(self):
return len(self.data_x) - self.seq_len- self.pred_len + 1
6.2 代码训练+测试+预测模块糅杂在一块,无法直接调用模型进行预测的问题:
修改代码如下:(如有问题请留言,看到会回复)
修改后指定调用checkpoints中的某个模型传入特征数据(seq_len个时间步的数据)即可完成预测
import argparse
import os
import pandas as pd
import torch
import numpy as np
from exp.exp_informer import Exp_Informer
from flask import Flask, request, send_file
from flask_cors import CORS
from datetime import datetime, timedelta
parser = argparse.ArgumentParser(description='[Informer] Long Sequences Forecasting')
# 使用的网络结构(方便对比实验),使用defalut更改网络结构
parser.add_argument('--model', type=str, default='informer',
help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
# 读的数据是什么(类型 路径)
parser.add_argument('--data', type=str, default='ECL_Fox', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ECL_Fox.csv', help='data file')
# 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量
parser.add_argument('--features', type=str, default='MS',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 哪一列要当作是标签,如果features=M该值则没有意义
parser.add_argument('--target', type=str, default='Fox_education_Jaclyn', help='target feature in S or MS task')
# 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样)
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型最后保存位置
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
'''
影响精度的三个参数
'''
# 当前输入序列长度(可自定义),计算attention时以96行作为最小单位
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
# 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
# 编码器、解码器输入输出维度,你数据有多少列,要减去时间那一列
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
# 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据
parser.add_argument('--c_out', type=int, default=1, help='output size')
# 隐层特征,enc和dec输出维度
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
# 要做几次多头注意力机制
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 堆叠几层encoder
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 对Q进行采样,对Q采样的因子数
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 是否下采样操作pooling
parser.add_argument('--distil', action='store_false',
help='whether to use distilling in encoder, using this argument means not using distilling',
default=True)
parser.add_argument('--dropout', type=float, default=0, help='dropout')
# 注意力机制
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data', default=True)
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
# 读数据
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
# windows用户只能给0
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 训练一个batch就是一次iteration迭代
parser.add_argument('--itr', type=int, default=1, help='experiments times')
# 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 停止策略
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
# 损失函数
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
# 是否为分布式
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
# 反归一化
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=True)
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
# 如果为分布式指定有几个显卡
parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus')
# 是否仅调用模型执行预测
parser.add_argument('--pred_path_only', type=str, default="data/ETT/ECL_Fox_UsePredict.csv", help='do_pred_only')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
# 定义数据文件字典
data_parser = {
'ECL_Rat': {'data': 'ECL_Rat.csv', 'T': 'Rat_lodging_Christine', 'M': [269, 269, 269], 'S': [1, 1, 1],
'MS': [269, 269, 1]},
'ECL_Fox': {'data': 'ECL_Fox.csv', 'T': 'Fox_education_Jaclyn', 'M': [7, 7, 7], 'S': [1, 1, 1],
'MS': [7, 7, 1]},
}
# 将data_parser中的信息通过args.data筛选读入data_info
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
# 指定循环多少个encoder
args.s_layers = [int(s_l) for s_l in args.s_layers.replace(' ', '').split(',')]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
print('Args in experiment:')
print(args)
# 创建训练类
Exp = Exp_Informer
# 模型文件夹
setting = 'informer_ECL_Fox_ftMS_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0'
exp = Exp(args)
exp.predict(setting, True) # 用ECL_Rat_UsePredict.csv文件前72个时间点序列数据预测未来168个时间点序列数据
torch.cuda.empty_cache()
#预测结果存放位置
file_path_npy = 'results/'+setting+'/real_prediction.npy'
file_path_csv = 'results/'+setting+'/real_prediction.csv'
#加载预测结果.npy文件,将预测结果转为一维数组
data = np.load(file_path_npy)[0,:,0]
#计算预测值所对应的时间
date = []
# 循环生成时间
start_time_str = pd.read_csv(args.pred_path_only)['date'].iloc[-1]
start_time = datetime.strptime(start_time_str, "%Y/%m/%d %H:%M")
for i in range(args.pred_len):
# 计算当前时间
current_time = start_time + timedelta(hours=i+1)
# 将时间转换为特定格式的字符串,并添加到列表中
date.append(current_time.strftime("%Y/%m/%d %H:%M"))
print(data)
print(date)
class Dataset_Pred(Dataset):#scale=True別乱改(纠错6.5h)
def __init__(self, root_path, flag='pred', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='15min', cols=None, pred_path_only = None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['pred']
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.cols=cols
self.root_path = root_path
self.data_path = data_path
self.pred_path_only = pred_path_only
self.__read_data__()
def __read_data__(self):
self.scaler = StandardScaler()
if self.pred_path_only == None:
df_raw = pd.read_csv(os.path.join(self.root_path,
self.data_path))
else:
df_old = pd.read_csv(os.path.join(self.root_path,
self.data_path))
df_pred = pd.read_csv(self.pred_path_only)
df_raw = pd.concat([df_old, df_pred], ignore_index=True)
6.3 采用了很多随机化操作导致同一组参数训练出的模型差异很大的问题(稳定性):
- 1.使用dropout在训练阶段防止过拟合。
# 防止过拟合数据丢弃的概率
parser.add_argument('--dropout', type=float, default=0, help='dropout')
- 2.使用shuffle在模型训练阶段防止过拟合。
#测试操作时参数配置
if flag == 'test':
shuffle_flag = False; drop_last = True; batch_size = args.batch_size; freq=args.freq
#预测操作时参数配置
elif flag=='pred':
shuffle_flag = False; drop_last = False; batch_size = 1; freq=args.detail_freq
Data = Dataset_Pred
#训练操作时参数配置
else:
shuffle_flag = False; #是否洗牌
drop_last = True; #是否将batch中多余的数据剔除,即最后不足组成一个batch的数据会被删除不要
batch_size = args.batch_size; #批处理数量
freq=args.freq #处理数据时以哪个时刻为单位(h||m||s)
- 3.Informer在Transformer基础上优化了注意力机制,每个向量调用rand()随机与该组(96个)中的25个向量计算注意力,我修改成每个向量与该组中最前面25个向量计算注意力,消除了随机性。
注:经过大佬指正,这一条可能存在问题,还在修改中。
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)
# Q [B, H, L, D]
B, H, L_K, E = K.shape
_, _, L_Q, _ = Q.shape
# calculate the sampled Q_K
#扩充一个维度
K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)
#随机选25个K,使得96个Q中每个Q只对这25个K进行采样,通过25个采样结果判断每个Q的区分度
#生成L_Q行sample_k列的张量,每个元素都是0~L_K - 1的随机数
#index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q
index_sample = torch.arange(sample_k).repeat(L_Q, 1)
K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]
#96个Q和25个K之间的关系
Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)
#96个Q中每一个Q选与其他K关系最大的值 在计算与均匀分布的差异
M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)
M_top = M.topk(n_top, sorted=False)[1]
#选出区分度最大的25个Q
Q_reduce = Q[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
M_top, :] # factor*ln(L_q)
#25个Q与96个K做Attention,获取25个K与96个Q的关系
Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k
return Q_K, M_top
- 4.使用ADAM算法。
def _select_optimizer(self):
model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)
return model_optim
- 5.对卷积权重初始化时使用Kaiming初始化方法,不同初始化值模型训练结果不同。
#权重初始化
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular')
for m in self.modules():
if isinstance(m, nn.Conv1d):
#使用Kaiming初始化(He初始化)对卷积的权重进行初始化,这是一种专门为ReLU及其变种激活函数设计的权重初始化方法。Kaiming初始化的核心思想是,对于每一层的输出,其方差应该保持在一个合适的范围内,这样网络在反向传播时不会因为梯度消失或梯度爆炸而导致训练困难。
nn.init.kaiming_normal_(m.weight,mode='fan_in',nonlinearity='leaky_relu')
def forward(self, x):
#permute对输入张量x的维度进行重新排列,从[batch_size, input_channels, sequence_length]变为[batch_size, sequence_length, input_channels]
#transpose对输入张量转置
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1,2)
return x
五、实验
1.数据集讲解:
1.1介绍:
BDG2数据集是包含3,053个能源表的开放数据集,这些表来自1,636栋非居住建筑,覆盖了为期两年(2016年和2017年)的数据,采集频率为每小时一次(每个表共有17,544个测量值,总共约有5360万个测量值)。这些表来自北美和欧洲的19个地点,每栋建筑有一个或多个表,用于测量整栋建筑的电能、供暖和冷却水、蒸汽、太阳能,以及水和灌溉表。
1.2相关论文:

1.3各个字段详解:
1.3.1 metadata.csv记录了各建筑的信息。每行代表一栋建筑,列含义如下:
- building_id:建筑物名称(建筑名称均以site_B_C形式命名)
- site表示区域的唯一标识,以动物名称命名。不同区域site均不同,同一区域不同建筑site相同。
- B表示建筑,以建筑物用途命名。education, office,dormitory, etc.
- C表示每栋建筑的唯一标识,以人名命名。
- 例如:Bobcat_education_Dylan表示在Bobcat区域中建筑物Dylan用作education,且该数据集中Dylan命名的建筑只有一个。
- site_id:建筑所在区域(site)
- site_id_kaggle:区域(site)的kaggle标识

- primaryspaceusage:建筑物(site_B_C)主要功能。
- sub_primaryspaceusage:建筑物(site_B_C)次要功能。
- sqm:总建筑面积。单位:m^2
- sqft:建筑物的平方英尺楼层面积。单位:m^2
- lat:建筑物所在城市的纬度。
- lng:建筑物所在城市的经度。
- timezone:时区(同一时区经纬度相同)。
- electricity:该建筑物是否存在测量电能的仪表。取值:YES/NaN
- hotwater:该建筑物是否存在测量热水的仪表。取值:YES/NaN
- chilledwater:该建筑物是否存在测量冷却水的仪表。取值:YES/NaN
- steam:该建筑物是否存在测量蒸汽的仪表。取值:YES/NaN
- water:该建筑物是否存在测量水的仪表。取值:YES/NaN
- irrigation:该建筑物是否存在测量灌溉的仪表。取值:YES/NaN
- solar:该建筑物是否存在测量太阳能的仪表。取值:YES/NaN
- gas:该建筑物是否存在测量供暖的仪表。取值:YES/NaN
- industry:建筑物的主行业类型。
- subindustry:建筑物的次行业类型。
- heatingtype:建筑物的供暖方式。取值:Gas、Oil、Electricity、Biomass、Heat network、Stream、Heat network but not ours、Heat network and steam
- yearbuilt:建筑物建造年份。数据格式:YYYY
- date_opened:建筑开放使用的时间。数据格式:D/M/YYYY
- numberoffloors:建筑物对应的楼层数。
- occupants:建筑物内住户人数。
- energystarscore:建筑物的能源之星评分(评分是根据建筑物的能源效率和节能性能来评定的)。
- eui:建筑物的能源使用强度。单位:kWh/year/m2
- site_eui:建筑物的场地能源使用强度。单位:kWh/year/m2
- source_eui:建筑物的源能源使用强度。单位:kWh/year/m2
- leed_level:建筑物的LEED等级。
- rating:建筑物的其他能源评级。
1.3.2 weather.csv记录了每小时site的天气状况。每行代表一个site在timestamp小时内的天气状况,列含义如下:
- timestamp:时间标识。
- site_id:site标识。
- airTemperature:摄氏度。单位:℃
- cloudCoverage:云层覆盖比例。
- dewTemperature:露点。单位:℃
- precipDepth1HR:1h内降水深度。单位:mm
- precipDepth6HR:6h内降水深度。单位:mm
- seaLvlPressure:相对于平均海平面(MSL)的气压。单位:mbar或hPa
- windDirection:相对于正北方顺时针风向。单位:°
- windSpeed:风速。单位:m/s
1.3.3 electricity.csv:
建筑物电能的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
不同site单位不同,具体如下

1.3.4 irrigation.csv:
建筑物灌溉的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.5 chilledwater.csv:
建筑物冷却水的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.6 gas.csv:
建筑物供暖的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.7 hotwater.csv:
建筑物热水的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.8 water.csv:
建筑物水的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.9 solar.csv:
建筑物太阳能的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
1.3.10 steam.csv:
建筑物蒸汽的测量数据。横坐标为时间,纵坐标为建筑物(site_B_C)
2.实验流程:
步骤1:数据收集与分析。首先收集历史负荷数据,以及协变量,其中协变量是指影响负荷变化的因素。其中影响负荷变化的因素可能有很多,包括气象,电价等方面。如果想要使用这些协变量辅助预测,则需要对影响因素进行数据分析,判断其对负荷预测的影响是否正相关,再考虑是否将其引入。
步骤2:对收集到的数据进行处理,其中包括:数据归一化处理等。另外,还必须涉及的一种常用于时序数据的处理方式是:使用滑动窗口的形式构造数据样本和标签。其次,将数据集切分得到训练样本和测试样本。
步骤3:搭建短期负荷预测模型。
步骤4:模型训练。
步骤5:最终预测结果由测试样本输入到步骤4 的模型并进行反归一化得到。
步骤6:模型评估,使用特定评价指标评价模型性能的好坏。
2.1滑动窗口机制概述:
(1)知识点回顾:
首先介绍Informer如何使用滑动窗口前,先回顾一些模型中的基础参数: batch_size:batch中样本的数量,模型训练过程每次以一个batch为输入单位来进行训练。
seq_len:Encoder接收的输入序列长度,也是滑动窗口中的窗口长度。
label_len:Decoder开始阶段接收的已知序列的长度(即“标签”用于引导解码器的预测)。
pred_len:Decoder预测未来时间点的长度。回顾模型训练时数据的输入过程: Informer在训练时Encoder输入的是batch_size个大小的规范样本,其中每个规范样本都是通过滑动窗口技术从原始数据集样本中提取出来的,每个规范样本都包含seq_len个时间步长的数据点(即每个规范样本都包含训练集中seq_len行连续数据)。
(2)滑动窗口实现原理:
- 滑动窗口介绍: 在Informer模型中使用滑动窗口的主要原因是确保模型输入的数据格式符合其要求。滑动窗口就是在模型训练阶段、数据集输入模型进行训练前对数据集进行构造,形成满足模型输入数据格式要求的数据样本和标签。
- 滑动窗口实现原理: 举个例子,假设我们有一组时间序列数据,这些数据记录了1000h的气温(1000行),设定seq_len=72(窗口长度),label_len=48,pred_len=24,batch_size=12。
初始:从第1h开始,放置一个72h的滑动窗口,窗口内样本包含第1h—72h气温,这时batch中的一个规范样本就是当前窗口内的72h样本,该规范样本对应的标签为25h—72h气温,该规范样本对应的预测样本为73h—96h气温。
如此batch中的一个规范样本就构建完毕了,此时还需构建11个规范样本,接下来就用到滑动窗口了,将窗口向右滑动1h,形成新的窗口包含第2h—73h的气温,并相应的生成这个窗口的标签和预测样本,至此就构建完成了第二个规范样本。
循环12次直至构建batch_size个规范样本后形成一个batch,可以把batch输入模型进行训练了。(3)滑动窗口优势:
- 高效处理长序列数据。
- 滑动窗口方式构建数据可以让模型能够逐步积累历史信息,提高模型学习能力。


3.数据收集与分析:

使用电量数据集,包括269栋建筑从2016/1/1至2017/12/28的用电量负荷
4.数据预处理:
- Z-Score法处理异常值
- 删除缺失值超过10%的列
- NaN值使用KNN算法填补
- 划分70%训练集10%验证集20%测试集
import pandas as pd
import numpy as np
from sklearn.impute import KNNImputer
#数据集位置
path = "data/ETT/electricity_cleaned.csv"
# 读取csv文件
df = pd.read_csv(path)
# 1.修改第一列列名为"date"
df.columns = ['date'] + list(df.columns)[1:]
# 2.对每一列,缺失值超过30%则删除该列
for col in df.columns[1:]:
if df[col].isnull().mean() > 0.3:
df = df.drop(columns=[col])
# 3.将NaN值使用KNN算法填补
'''
对于每个缺失值,KNNImputer会查找与该缺失值所在行最接近的K个样本,然后利用这些样本中对应列的非缺失值来进行填补。
这意味着KNNImputer会考虑样本之间的相似性,而不是特征之间的相似性。
'''
KI = KNNImputer(n_neighbors=3,weights="uniform")
filled_data = KI.fit_transform(df.iloc[:, 1:])
df_cleaned= pd.DataFrame(filled_data, columns=df.columns[1:])
# 将日期列添加回新的DataFrame
df_cleaned.insert(0, "date", df["date"])
# 4.对第二列到最后一列进行取整操作
for col in df_cleaned.iloc[:, 1:].columns:
df_cleaned[col] = df_cleaned[col].astype(int).round()
# 5.检查数据框是否包含任何缺失值,然后写入CSV文件
if df_cleaned.isnull().sum().sum() > 0:
print("There are missing values in the DataFrame!")
else:
df_cleaned.to_csv(path, index=False)
print(len(df_cleaned.columns))
5.模型训练:
使用Informer架构,训练阶段:
- 传入数据集:ECL_Rat.csv
- 调用train( )函数在70%训练集上训练并使用10%验证集进行验证,根据训练结果调整超参数。最终生成最优超参数的模型文件保存在checkpoint文件夹中。
- 最后调用test( )在20%测试集的前pred_len个时间步进行测试,生成pred.npy预测值、true.npy真实值和metric.npy误差。
import argparse
import os
import torch
from exp.exp_informer import Exp_Informer
parser = argparse.ArgumentParser(description='[Informer] Long Sequences Forecasting')
# 使用的网络结构(方便对比实验),使用defalut更改网络结构
parser.add_argument('--model', type=str, default='informer',help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
# 读的数据是什么(类型 路径)
parser.add_argument('--data', type=str, default='ECL_Rat', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ECL_Rat.csv', help='data file')
# 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 哪一列要当作是标签,如果features=M该值则没有意义
parser.add_argument('--target', type=str, default='Rat_lodging_Christine', help='target feature in S or MS task')
# 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样)
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型最后保存位置
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
'''
影响精度的三个参数
'''
# 当前输入序列长度(可自定义),计算attention时每个batch以96行作为最小单位
parser.add_argument('--seq_len', type=int, default=72, help='input sequence length of Informer encoder')
# 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值
parser.add_argument('--pred_len', type=int, default=168, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
# 编码器、解码器输入维度,你数据有多少列,要减去时间那一列。!!!注意!!!:数据中列数不能太多
parser.add_argument('--enc_in', type=int, default=269, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=269, help='decoder input size')
# 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据
parser.add_argument('--c_out', type=int, default=1, help='output size')
# 隐层特征,enc和dec输出维度,数据中列数不能大于该值,必须是偶数 初始512,最优912,但是内存占用过高,选择次优624
parser.add_argument('--d_model', type=int, default=624, help='dimension of model')
# 多头注意力机制,头越多注意力越好 初始8,最优14
parser.add_argument('--n_heads', type=int, default=10, help='num of heads')
# 堆叠几层enc和dec 初始2,1 ,整体最优2,1, 2,2在一开始拟合效果特别好,最差4,2
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 堆叠几层encoder
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
#全连接层(多层感知机)输出维度 初始2048(512*4),越大后面拟合度越小
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 对Q进行采样,对Q采样的因子数,factor=5最优
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
# 数据填充
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 是否下采样操作pooling
parser.add_argument('--distil', action='store_false', help='whether to use distilling in encoder, using this argument means not using distilling', default=True)
# 防止过拟合数据丢弃的概率
parser.add_argument('--dropout', type=float, default=0, help='dropout')
# 注意力机制
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
# 时间特征的编码方式
parser.add_argument('--embed', type=str, default='timeF', help='time features encoding, options:[timeF, fixed, learned]')
# 激活函数
parser.add_argument('--activation', type=str, default='gelu',help='activation')
# 是否在编码器中输出注意力
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
# 是否执行predict函数
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data', default=True)
# 在生成式解码器中是否使用混合注意力
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
# 读数据列
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
# windows用户只能给0
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 实验运行次数
parser.add_argument('--itr', type=int, default=1, help='experiments times')
# 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练 初始6,比8,10优,在训练集上过拟合
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size,越大梯度越准确 初始32,比24,48优
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 停止策略,如果多少个epoch损失没有改变就停止训练
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
# 实验描述
parser.add_argument('--des', type=str, default='test',help='exp description')
# 损失函数
parser.add_argument('--loss', type=str, default='mse',help='loss function')
# 学习率的调整方式
parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')
# 是否为分布式
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
#反归一化
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=True)
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
# 如果为分布式指定有几个显卡
parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus')
#是否仅调用模型执行预测
parser.add_argument('--pred_path_only', type=str, default=None,help='do_pred_only')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ','')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
#定义数据文件字典
data_parser = {
'ETTh1': {'data': 'ETTh1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTh2': {'data': 'ETTh2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm1': {'data': 'ETTm1.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'ETTm2': {'data': 'ETTm2.csv', 'T': 'OT', 'M': [7, 7, 7], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
'WTH': {'data': 'WTH.csv', 'T': 'WetBulbCelsius', 'M': [12, 12, 12], 'S': [1, 1, 1], 'MS': [12, 12, 1]},
'ECL': {'data': 'ECL.csv', 'T': 'MT_320', 'M': [321, 321, 321], 'S': [1, 1, 1], 'MS': [321, 321, 1]},
'electricity_cleaned': {'data': 'electricity_cleaned.csv', 'T': 'Hog_office_Denita', 'M': [270, 270, 270], 'S': [1, 1, 1], 'MS': [270, 270, 1]},#逗号不能去?
'ECL_Rat': {'data': 'ECL_Rat.csv', 'T': 'Rat_lodging_Christine', 'M': [269, 269, 269], 'S': [1, 1, 1], 'MS': [269, 269, 1]},
'ECL_Fox': {'data': 'ECL_Fox.csv', 'T': 'Fox_education_Jaclyn', 'M': [7, 7, 1], 'S': [1, 1, 1], 'MS': [7, 7, 1]},
}
#将data_parser中的信息通过args.data筛选读入data_info
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
#指定循环多少个encoder
args.s_layers = [int(s_l) for s_l in args.s_layers.replace(' ','').split(',')]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
print('Args in experiment:')
print(args)
#创建训练类
Exp = Exp_Informer
#将我们的数据储存进去开始训练,for循环迭代我们的训练以及预测的过程
for ii in range(args.itr):
# setting record of experiments
setting = '{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_at{}_fc{}_eb{}_dt{}_mx{}_{}_{}'.format(args.model, args.data, args.features,
args.seq_len, args.label_len, args.pred_len,
args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.factor,
args.embed, args.distil, args.mix, args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
#训练函数,70%用于训练,10%用于验证在训练过程不断调整模型
exp.train(setting)
#测试,对最后20%测试集进行测试,生成测试集最开始pred_len时间序列内对target标签列的真实值true.npy和预测值pred.npy和误差metrics.npy
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
#预测,对target标签列的预测值real_prediction.npy
if args.do_predict:
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.predict(setting, True)
torch.cuda.empty_cache()
6.调用模型预测(对接前端版):
多变量预测单变量,使用268栋建筑72h的用电量(ECL_Rat_UsePredict.csv)预测72h紧邻的后168h建筑Rat_lodging_Christine的用电量。
import argparse
import os
import pandas as pd
import torch
import numpy as np
from exp.exp_informer import Exp_Informer
from flask import Flask, request, send_file
from flask_cors import CORS
from datetime import datetime, timedelta
app = Flask(__name__)
CORS(app) # 添加这一行以启用 CORS,解决跨域问题
@app.route('/upload', methods=['POST'])
def upload_file():
file = request.files['file']
# 保存文件到指定文件夹
file.save(os.path.join('data/ETT', file.filename))
parser = argparse.ArgumentParser(description='[Informer] Long Sequences Forecasting')
# 使用的网络结构(方便对比实验),使用defalut更改网络结构
parser.add_argument('--model', type=str, default='informer',
help='model of experiment, options: [informer, informerstack, informerlight(TBD)]')
# 读的数据是什么(类型 路径)
parser.add_argument('--data', type=str, default='ECL_Fox', help='data')
parser.add_argument('--root_path', type=str, default='./data/ETT/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='ECL_Fox.csv', help='data file')
# 预测的种类及方法,M多变量预测多变量,MS多变量预测单变量,S单变量预测单变量
parser.add_argument('--features', type=str, default='MS',
help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 哪一列要当作是标签,如果features=M该值则没有意义
parser.add_argument('--target', type=str, default='Fox_education_Jaclyn', help='target feature in S or MS task')
# 数据中存在时间 时间是以什么为单位(属于数据挖掘中的重采样)
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型最后保存位置
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')
'''
影响精度的三个参数
'''
# 当前输入序列长度(可自定义),计算attention时以96行作为最小单位
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
# 标签(带预测值的那个东西)长度(可自定义),有标签预测序列长度,label_len小于seq_len
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
# 预测未来序列长度 (可自定义),预测未来多少个时间点的数据,无标签预测序列长度,通过前label_len个真实值辅助decoder进行预测pred_len个预测值
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
# 编码器、解码器输入输出维度,你数据有多少列,要减去时间那一列
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=7, help='decoder input size')
# 输出预测未来多少个值,如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据
parser.add_argument('--c_out', type=int, default=1, help='output size')
# 隐层特征,enc和dec输出维度
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
# 要做几次多头注意力机制
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# 堆叠几层encoder
parser.add_argument('--s_layers', type=str, default='3,2,1', help='num of stack encoder layers')
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 对Q进行采样,对Q采样的因子数
parser.add_argument('--factor', type=int, default=5, help='probsparse attn factor')
parser.add_argument('--padding', type=int, default=0, help='padding type')
# 是否下采样操作pooling
parser.add_argument('--distil', action='store_false',
help='whether to use distilling in encoder, using this argument means not using distilling',
default=True)
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
# 注意力机制
parser.add_argument('--attn', type=str, default='prob', help='attention used in encoder, options:[prob, full]')
parser.add_argument('--embed', type=str, default='timeF',
help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--activation', type=str, default='gelu', help='activation')
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data', default=True)
parser.add_argument('--mix', action='store_false', help='use mix attention in generative decoder', default=True)
# 读数据
parser.add_argument('--cols', type=str, nargs='+', help='certain cols from the data files as the input features')
# windows用户只能给0
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 训练一个batch就是一次iteration迭代
parser.add_argument('--itr', type=int, default=1, help='experiments times')
# 训练轮数epoch,一次epoch即为完整的数据集通过一次神经网络训练
parser.add_argument('--train_epochs', type=int, default=6, help='train epochs')
# 将完整的数据集分成若干个batch,一次输入样本的数量就是batch_size
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
# 停止策略
parser.add_argument('--patience', type=int, default=3, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
# 损失函数
parser.add_argument('--loss', type=str, default='mse', help='loss function')
parser.add_argument('--lradj', type=str, default='type1', help='adjust learning rate')
# 是否为分布式
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)
# 反归一化
parser.add_argument('--inverse', action='store_true', help='inverse output data', default=True)
parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
# 如果为分布式指定有几个显卡
parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus')
# 是否仅调用模型执行预测
parser.add_argument('--pred_path_only', type=str, default="data/ETT/"+file.filename, help='do_pred_only')
#parser.add_argument('--pred_path_only', type=str, default="data/ETT/ECL_Rat_UsePredict.csv", help='do_pred_only')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
# 定义数据文件字典
data_parser = {
'ECL_Rat': {'data': 'ECL_Rat.csv', 'T': 'Rat_lodging_Christine', 'M': [269, 269, 269], 'S': [1, 1, 1],
'MS': [269, 269, 1]},
'ECL_Fox': {'data': 'ECL_Fox.csv', 'T': 'Fox_education_Jaclyn', 'M': [7, 7, 7], 'S': [1, 1, 1],
'MS': [7, 7, 1]},
}
# 将data_parser中的信息通过args.data筛选读入data_info
if args.data in data_parser.keys():
data_info = data_parser[args.data]
args.data_path = data_info['data']
args.target = data_info['T']
args.enc_in, args.dec_in, args.c_out = data_info[args.features]
# 指定循环多少个encoder
args.s_layers = [int(s_l) for s_l in args.s_layers.replace(' ', '').split(',')]
args.detail_freq = args.freq
args.freq = args.freq[-1:]
print('Args in experiment:')
print(args)
# 创建训练类
Exp = Exp_Informer
# 模型文件夹
setting = 'informer_ECL_Rat_ftMS_sl72_ll48_pl168_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0'
exp = Exp(args)
exp.predict(setting, True) # 用ECL_Rat_UsePredict.csv文件前72个时间点序列数据预测未来168个时间点序列数据
torch.cuda.empty_cache()
#预测结果存放位置
file_path_npy = 'results/'+setting+'/real_prediction.npy'
file_path_csv = 'results/'+setting+'/real_prediction.csv'
#加载预测结果.npy文件,将预测结果转为一维数组
data = np.load(file_path_npy)[0,:,0]
#计算预测值所对应的时间
date = []
# 循环生成时间
start_time_str = pd.read_csv(args.pred_path_only)['date'].iloc[-1]
start_time = datetime.strptime(start_time_str, "%Y/%m/%d %H:%M")
for i in range(args.pred_len):
# 计算当前时间
current_time = start_time + timedelta(hours=i+1)
# 将时间转换为特定格式的字符串,并添加到列表中
date.append(current_time.strftime("%Y/%m/%d %H:%M"))
df = pd.DataFrame({
'date':date,
"data":data
})
# 将数据保存为CSV文件
df.to_csv(file_path_csv,index=False)
print("预测完成,返回前端")
return send_file(file_path_csv, as_attachment=True)
if __name__ == '__main__':
print("后端开始运行")
app.run()
7.预测结果评估:
# 画二维坐标图
# 读取csv并作图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# When we finished exp.train(setting) and exp.test(setting), we will get a trained model and the results of test experiment
# The results of test experiment will be saved in ./results/{setting}/pred.npy (prediction of test dataset) and ./results/{setting}/true.npy (groundtruth of test dataset)
setting = "informer_ECL_Rat_ftMS_sl72_ll48_pl168_dm624_nh14_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0"
pred = np.load('./results/'+setting+'/pred.npy')
true = np.load('./results/'+setting+'/true.npy')
real_prediction = np.load('./results/'+setting+'/real_prediction.npy')
metrics = np.load('./results/'+setting+'/metrics.npy')
#[samples, pred_len, dimensions]
print(pred.shape)
print(true.shape)
print(real_prediction.shape)
print(metrics)
print(real_prediction[0,:,0])
#print(true[0,:,-1])
# draw prediction
plt.figure()
plt.plot(true[0,:,-1], label='true')
plt.plot(pred[0,:,-1], label='pred')
plt.ylim(0,true[0,:,-1].max())
plt.legend()
plt.show()

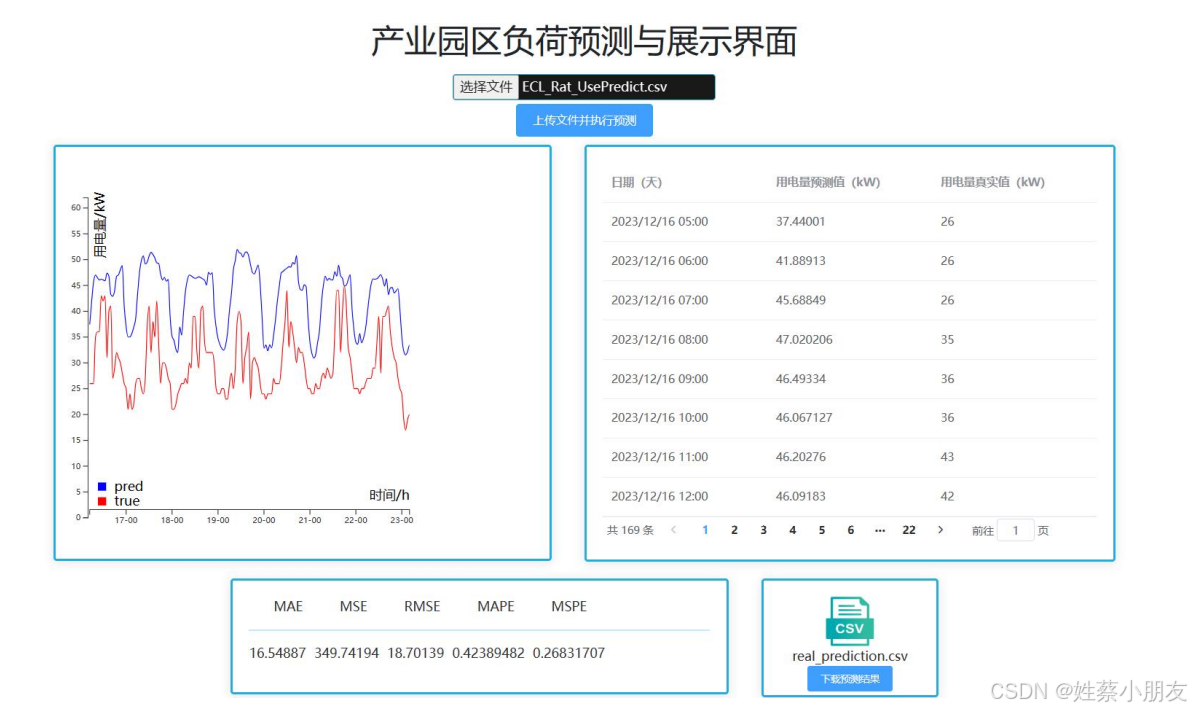
8.前端展示:



















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











