







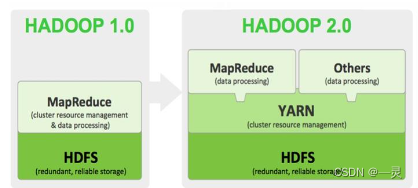
Hadoop主要由两部分组成:分布式文件系统HDFS和分布式计算框架MapReduce,分布式文件系统主要是用于海量数据的存储,而MapReduce则是基于此分布式文件系统对存储在分布式文件系统中的数据进行分布式计算,接下来对Hadoop的两个组成部分的架构特点进行深入的了解。
hdfs架构
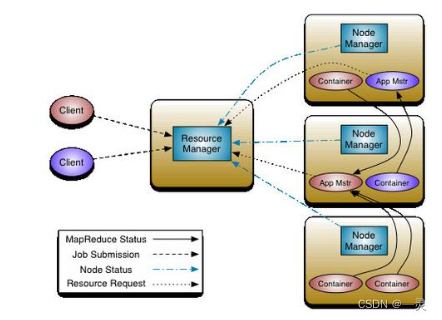
MapReduce架构
Hadoop的三大核心组件分别是:
Hadoop hdfs:hadoop的数据存储工具。
Hadoop yarn:Hadoop 的资源管理器。
Hadoop MapReduce:分布式计算框架
4.3 Hadoop的核心组件
Hadoop是Apache软件基金会旗下的一个分布式系统基础架构。Hadoop2的框架最核心的设计就是HDFS、MapReduce和YARN,为海量的数据提供了存储和计算。
HDFS主要是Hadoop的存储,用于海量数据的存储;
MapReduce主要运用于分布式计算;
YARN是Hadoop2中的资源管理系统。
hdfs:当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对数据进行分区并存储到若干台单独的计算机上。管理网络中跨多台计算机存储的文件系统称为分布式文件系统(DistributedFileSystem)。Hadoop有一个称为HDFS的分布式文件系统,即:Hadoop DistributedFileSvstem。在非正式文档或旧文档以及配置文件中,有时也简称DFS。
HDFS作为Hadoop的两大核心组件之一,就像Hadoop的基石,为分布式计算框架MapReduce提供底层的分布式存储支撑。
hdfs优势特点:
1、大数据处理
2、流式数据访问
3、商用硬件
局限性:
1、低时间延迟数据的访问
2、大量的小文件
hdfs的特性:
1、高容错性、可扩展性和可配置性强
2、跨平台
3、shell命令接口
4、web平台管理
5、文件权限管理
6、机架感知功能
7、安全模式
8、Rebalancer功能
9、允许升级或回滚
hdfs的设计目标:
1、检测和快速恢复硬件故障
2、流式数据访问
3、大规模数据集
4、简化致的模型
5、移动计算的代价比移动数据的代价低
6、在不同的软硬件平台间的可移植性
7、健壮性。在出错时也要保证数据存储的可靠性
8、标准的通信协议
Hadoop生态系统:
一般来说,狭义的Hadoop仅仅是指Common、HDFS和MapReduce模块。但是作为开源项目,围绕Hadoop有越来越多的软件蓬勃出现,方兴未艾,构成了一个生机勃勃的Hadoop生圈。有时我们说Hadoop往往是指Hadoop生态圈中的软件所组成的生态系统。
CDH3系列核心主要由HDFS和MapReduce组成,HDFS是用于存储数据的,MapReduce是用于计算处理数据的。
CDH4、CDH5系列,其核心组件除了原有的HDFS、MapReduce以外又增加了YARN资源管理系统YARN负责整个集群资源的管理和调度,而原有的MapReduce则运行在YARN上面。














 1567
1567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









