









【spark sedona k8s】spark(sedona) on kubernetes(k8s) 搭建,使用spark-operator提交任务
引言
成功搭建
spark on yarn后,总是觉得它与我们的服务之间不好联动。之前我们的服务都运行在docker之中,spark又运行在hadoop中,我们要想通过服务控制集群执行任务,结合现在的情况,已有的解决方案十分麻烦,要么就是部署一个服务在hadoop的master节点上,通过系统命令来控制,要么就是安装第三方工具。总之不管哪种办法我都觉得不够好,于是便想到在k8s上跑spark。
一、架构介绍
相较于之前的
spark由yarn调度,使用k8s调度最大的好处是可以弹性伸缩,整个k8s集群中除了跑其他服务以外还能跑spark任务,其他服务不忙的时候,可以给spark的任务多一点资源。又因为k8s是自带REST Api的,所以我们在k8s上跑的服务可以通过访问ApiServer接口的方式直接向k8s提交spark任务。它的流程看起来像这样:
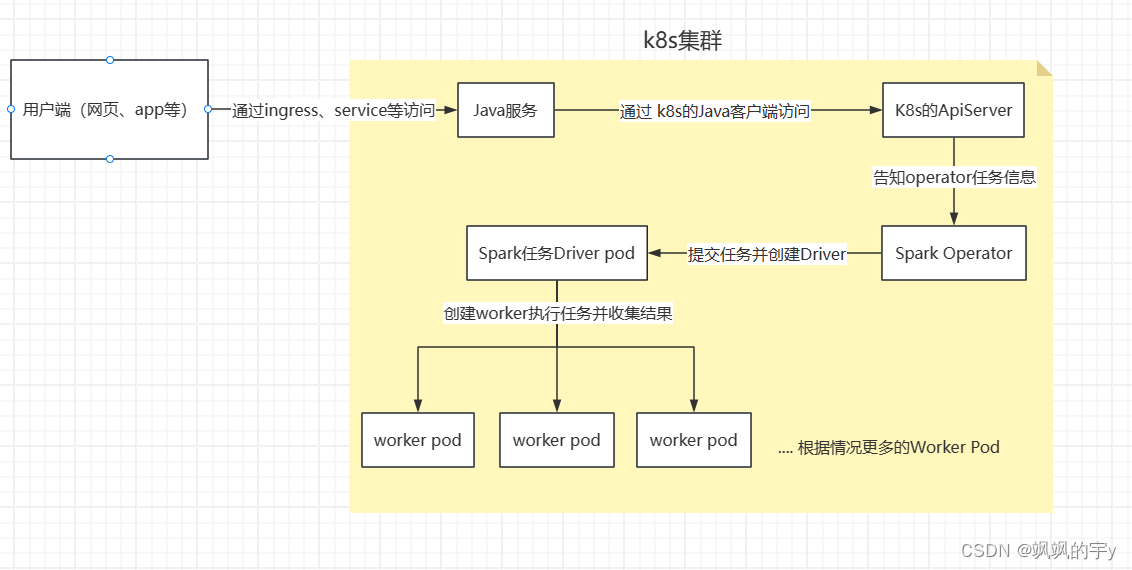
这样看起来就很优雅了,将
spark的调度交给k8s,k8s能动态管理我们的任务所需资源,我们与spark的交互也可以挪到java服务上,k8s的健壮性、容错性我就不多提了,集群搭建起来也挺简单的。接下来我们就开始搭建spark on k8s并且开启spark operator管理任务。
二、搭建
在正式开始之前,你得有一个能正常运行的
k8s集群,接下来的操作默认你有了一个能正常运行的k8s集群。如果你的集群还没搭建起来,参考我的 另外一篇帖子,先搭建集群。
1、安装 helm
我们可以通过很多方式将
Spark Operator引入到集群中,可以手动下载源代码来安装,也可以使用kustomize来安装,哪种方式都可以,Spark Operator官方 GitHub地址
我们用
helm,所以得先安装一个helm,执行:
sudo apt update
sudo apt install -y curl apt-transport-https
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
2、添加 helm 仓库,安装 Spark Operator
需要将
Spark Operator所在的仓库地址添加进去。Bitnami提供了Spark Operator的Helm chart。使用以下命令添加Bitnami仓库:
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
安装
Spark Operator:
kubectl create namespace spark-operator # 创建一个命名空间
helm install spark-operator spark-operator/spark-operator \
--namespace spark-operator \
--set image.repository=docker.io/kubeflow/spark-operator \ # 在这里指定镜像所在的仓库
--set image.tag=v1beta2-1.4.6-3.5.0 \ # 可以在这里指定要安装的版本,但是前提是镜像仓库要存在
--set sparkJobNamespace=default
如果安装报错最后一句是这句:
ensure CRDs are installed first
执行这个安装
CRDs:
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/spark-on-k8s-operator/master/manifest/crds/sparkoperator.k8s.io_sparkapplications.yaml
kubectl create -f https://raw.githubusercontent.com/GoogleCloudPlatform/spark-on-k8s-operator/master/manifest/crds/sparkoperator.k8s.io_scheduledsparkapplications.yaml
这是一个在线地址,你也可以将源代码拉下来执行:
git clone https://github.com/GoogleCloudPlatform/spark-on-k8s-operator.git
cd spark-on-k8s-operator
kubectl apply -f manifest/crds/sparkoperator.k8s.io_sparkapplications.yaml
kubectl apply -f manifest/crds/sparkoperator.k8s.io_scheduledsparkapplications.yaml
在线地址执行和拉下来执行的效果是一样的,安装好
CRDs后再执行上面的安装
执行完后去看看
Pod的状态,要没有报错:
kubectl get pods -n spark-operator

3、配置账户信息
要想执行
Spark任务,我们在提交任务的时候必需得指定一个k8s账户,它得绑定一个有权限的角色,才能有权限向k8s集群申请资源,创建一个账户:
vi spark-account.yaml
加入内容:
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark-account
namespace: spark-operator
创建一个角色绑定,我们将刚创建的账户绑定到集群管理员角色:
vi spark-role-binding.yaml
加入内容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-cluster-role-binding
subjects:
- kind: ServiceAccount
name: spark-account
namespace: spark-operator
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
分别执行两个文件,注意先后顺序:
kubectl apply -f spark-account.yaml
kubectl apply -f spark-role-binding.yaml
如果你觉得绑定管理员角色不妥,那么可以自定义一个角色,加入内容大概像:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: my-role
rules:
- apiGroups: [""]
resources: ["pods", "pods/log", "services", "configmaps", "secrets", "persistentvolumeclaims"]
verbs: ["get", "list", "create", "delete", "watch"]
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["get", "list", "create", "delete", "watch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "create", "delete", "watch"]
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "create", "delete", "watch"]
4、测试
编写一个定义
Spark on K8s任务的yaml文件,加入内容:
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: docker.io/spark:3.5.1 # 这里与我们安装的spark operator版本不一样,但是我使用没问题
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.5.1.jar"
sparkVersion: "3.5.1"
restartPolicy:
type: Never
driver:
cores: 2
memory: "2G"
labels:
version: 3.5.1
serviceAccount: spark-account # 这里指定我们刚才创建的有权限的账户
env:
- name: SPARK_MODE
value: "driver"
executor:
cores: 1
instances: 4
memory: "1G"
labels:
version: 3.5.1
arguments:
- "10000"
***特别注意的是,一定要指定有权限的账户来运行任务,不然会报各种各样的错,我就是报了很多错,干脆直接用集群管理员的角色来运行任务,就没再报错了。
查看是否开启了任务,执行:
kubectl get sparkapplications
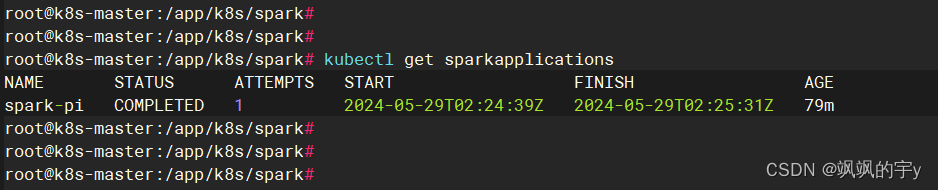
我的已经执行完了,你的应该看到提交或者执行中
想看具体的日志,可以去看
Pod的日志:
kubectl logs spark-pi-driver
我们在开启任务后,会发现多了一个
driver的pod和worker的pod,worker的pod数量取决于我们之前提交任务的配置文件中指定了几个,当然它也能动态的分配。例如我们的spark-pi.yaml任务就指定了四个worker pod,我们查看一下:
kubectl get pods # 不加 -n default 的话默认就是 -n default
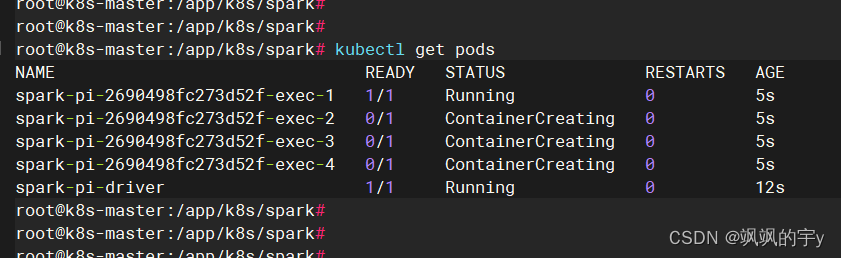
果然就是启动了四个
pod来运行任务,等它执行完,我们再看driver的日志:
kubectl logs spark-pi-driver
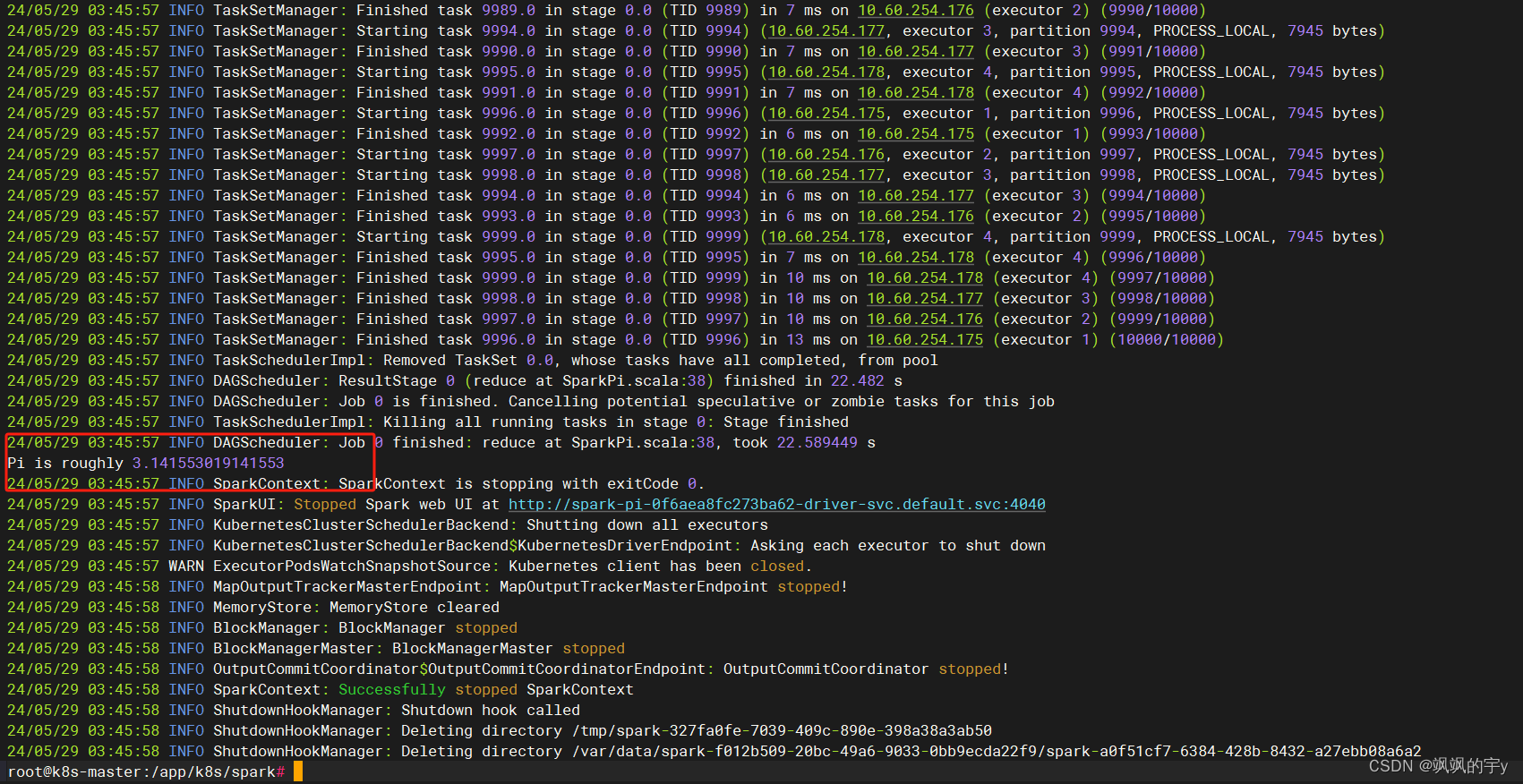
得到了结果,搭建成功
三、关于 Sedona
搭建
Sedona就更简单了,我们只需要将上面用的Spark的镜像拉下来,写一个Dockerfile,将Sedona的插件jar包丢到对应的文件夹中去,重新构建镜像并上传到私有仓库或者公共仓库,只要k8s能拉取到就行,然后在任务.yaml中改一下镜像地址就行了,这里就不演示了,因为我也没弄,这个不难。
四、关于历史服务器
如果想用历史服务器,得将日志写到一个公共的持久化存储空间中,然后在
k8s中跑一个历史服务器去读取日志文件,暴露一个service或ingress就能访问。
五、测试
我弄了四台机器,一台是
12C 64G,其他三台是12C 16G,测试上面的spark-pi示例,计算五十万次,开启8个worker pod,结果是:
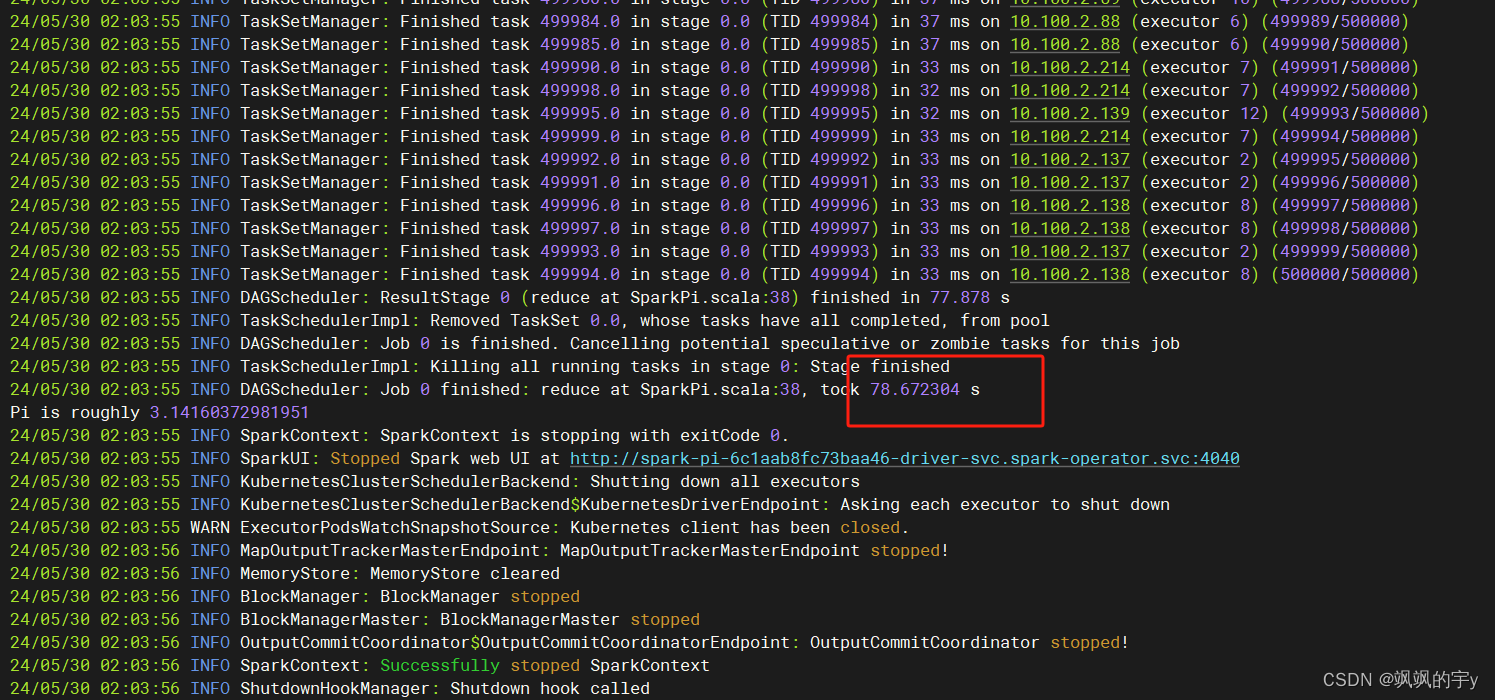
耗时
78s,将计算次数换为一百万次,开启16个worker pod,结果为:
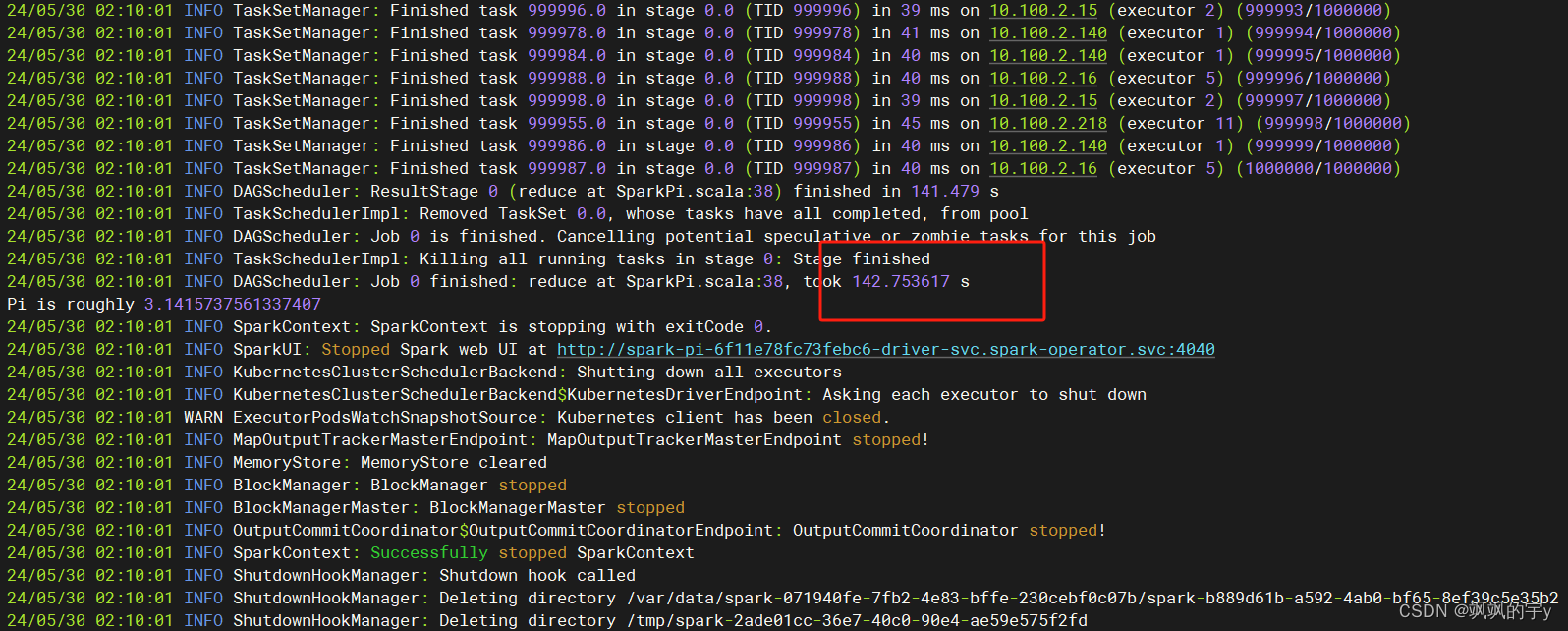
耗时
142s,我记得之前使用Spark on Yarn的时候也是计算五十万次,结果是两分钟多一点,计算一百万次失败了,半个小时没结果。现在使用Spark on Kubernetes,效率有所提升,不知道是我的实验变量没控制好还是怎么的,有点意外,不过除了效率之外,在k8s上跑Spark的优点我觉得还是灵活性强,跑任务的时候一堆worker pod就创建出来跑任务了,任务结束后worker pod就都没了,不会占用集群中其他服务的资源,这点挺好的。此外由于k8s是自带REST Api的,所以和我们自己写的服务交互起来就比较方便,我们可以通过REST Api提交任务,查看任务等等
写在最后
当然,我上面的这些办法可能不是最好的,我也在探索最好的实践,写到此处只是自己查找时方便,如果能顺道帮助你解决一些问题那再好不过。
学无止尽,瑞斯拜!















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









